⚠️ 들어가기 앞서
경북대학교 컴퓨터학부 COMP0414-001 컴퓨터망 과목을 공부하며 정리한 글입니다.
1. Router architecture
대략적인 라우터의 구조는 다음 사진과 같다.
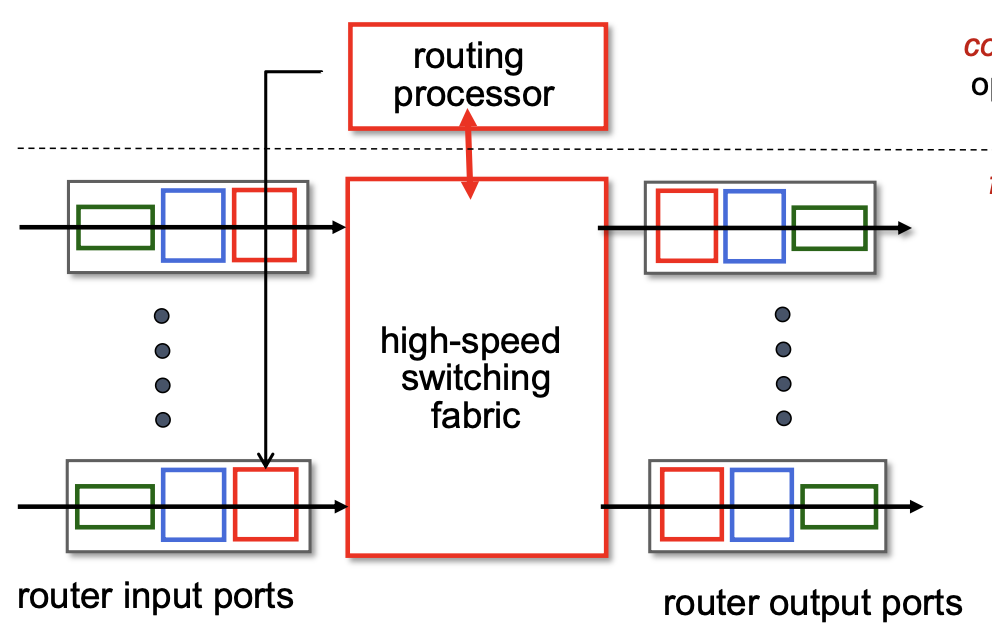
routing processor가 존재하고, 링크와 라우터를 연결해 주는 input port와 output port가 존재한다. 그 내부에는 high-speed switching fabric을 통과하여 패킷을 이동시킨다.
각 부분에 대해서 자세히 살펴보자!
2. Input Port
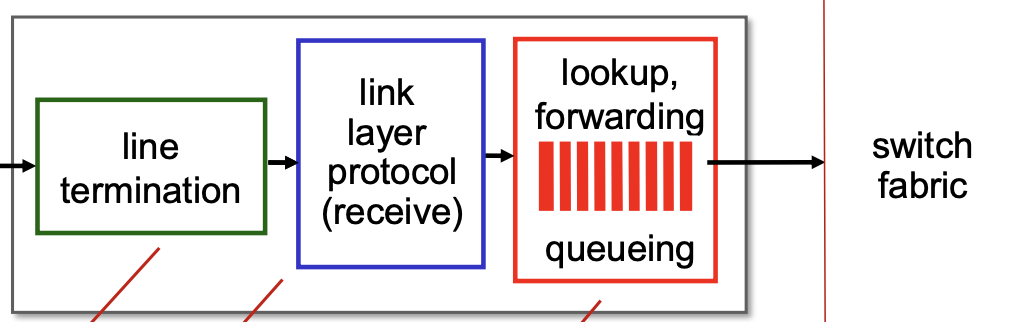
- line termination : 라우터로 들어오는 물리적 링크를 종료하는 물리적 계층 기능
- link layer protocol : 들어오는 링크의 다른 쪽에서 데이터 링크 계층 기능(5장 참조)과 상호 운용하는 데 필요한 데이터 링크 계층 기능
lookup, forwarding: 헤더를 확인하고 output port를 forwarding table(routing table)에서 찾는다. 그리고 datagram이 처리되는 속도보다 들어오는 속도가 빠를 경우 queue를 사용하여 대기시킨다. 그리고 이렇게 forwarding하는 방법에는 두 가지가 존재한다.- destination IP address만을 보고 forwarding 하는
destination-based forwarding - SDN의 등장과 함께 도착지의 주소 뿐만 아니라 네트워크의 혼잡 상태 등 여러 가지를 고려하여 forwarding하는
generalized forwarding
- destination IP address만을 보고 forwarding 하는
destination-based forwarding
라우터는 forwarding table (또는 routing table)을 보고 datagram의 헤더에 명시되어 있는 도착 IP 주소를 확인하고 어느 link로 이 datagram을 내보내야 할지 결정한다.
포워딩 테이블은 다음과 같은 구조를 가지고 있으며, 목적지 주소의 구간과 output link가 짝지어져 표 형태로 나타난다.

예를 들어 주소가 11001000 00010111 00010000 00000000 에서 11001000 00010111 00010111 11111111 까지는 0번 link로 가야한다.
IPv4 체계에서 IP 주소는 32비트로 나타내어지며, 따라서 2^32 개의 주소를 표시할 수 있다. 그런데 이 주소들을 모두 한 테이블에 표현하려면 테이블이 너무 방대해지고, 실제로 그럴 필요도 없다. 우편을 배달하는 상황에 비유하여 생각해 볼 수 있다.
우편물 주소 : 대구광역시 북구 AA로 12길 34건물 56호
서울 우체국에 다음과 같은 우편물을 부쳤다. 그럴 때 서울 우체국에서 바로 저 건물로 배달해주지는 않는다.
- 먼저 대구광역시의 모든 우편물을 취급하는 대구 우체국으로 보낸다.
- 대구 우체국에서 북구의 우편물을 취급하는 북구 우체국으로 다시 보낸다.
- 북구 우체국에서 'AA로 12길' 을 담당하는 부서에 보낸다.
이렇게 여러 차례를 거칠 것이다. 그러면 굳이 서울 우체국에서는 북구 ~~~ 에 해당하는 주소는 읽을 필요 없다.
즉, 라우팅 테이블에서도 전체 주소를 읽지 않고 네트워크 단위로 부분 부분만 읽고 처리한다.
Longest prefix matching
다음과 같은 테이블을 보자.

link interface 1과 2로 향하는 prefix가 서로 중복된다.
11001000 00010111 0001100010 이라는 주소가 들어오면, 얘는 어디로 가야할까...?
forwarding table에서 주소를 찾을 때, 해당하는 prefix가 여러 개가 있다면, 이 중 가장 길게 일치하는 쪽의 prefix를 따른다.
즉 11001000 00010111 00011 까지 매칭되는 2번 link 보다 11001000 00010111 00011000 까지 매칭되는 1번 link가 더 길기 때문에, 이 패킷은 1번 link로 output 된다.
3. Switching fabrics
input link로 들어온 패킷을 적절한 output link로 출력해 주는 과정을 말한다.
forwarding 해주는 중간 구조이며, 당연히 라우터의 가장 중요한 부분이다.
여담 : fabric(직물) 이라는 이름이 붙은 이유는 여러 링크들이 서로 얼기설기 얽혀 있는 모습이 마치 직물 같아서 생긴 이름이라고 한다.
패킷이 input link로 들어와서 output link로 내보내지는 rate를 switchig rate 라고 하며 라우터의 성능의 척도이다.
switching fabric에는 대표적으로 3가지 구조가 있다.
3-1. memory 구조
1세대 라우터가 이 구조를 가지고 있다. 각 입력 포트로 들어오는 모든 패킷들은 메모리로 복사되었다가 선택된 출력 포트로 내보내어진다.
즉 입력 포트에서 메모리로, 메모리에서 출력 포트로 총 2번 메모리 접근이 발생하게 되며, 따라서 메모리의 대역폭(Bandwidth)에 따라 속도가 좌우된다.
그러나 보편적으로 메모리에 엑세스하는 데에는 상당한 시간이 소요되며, 따라서 고속화하는 데에는 한계가 있는 구조라고 할 수 있다.
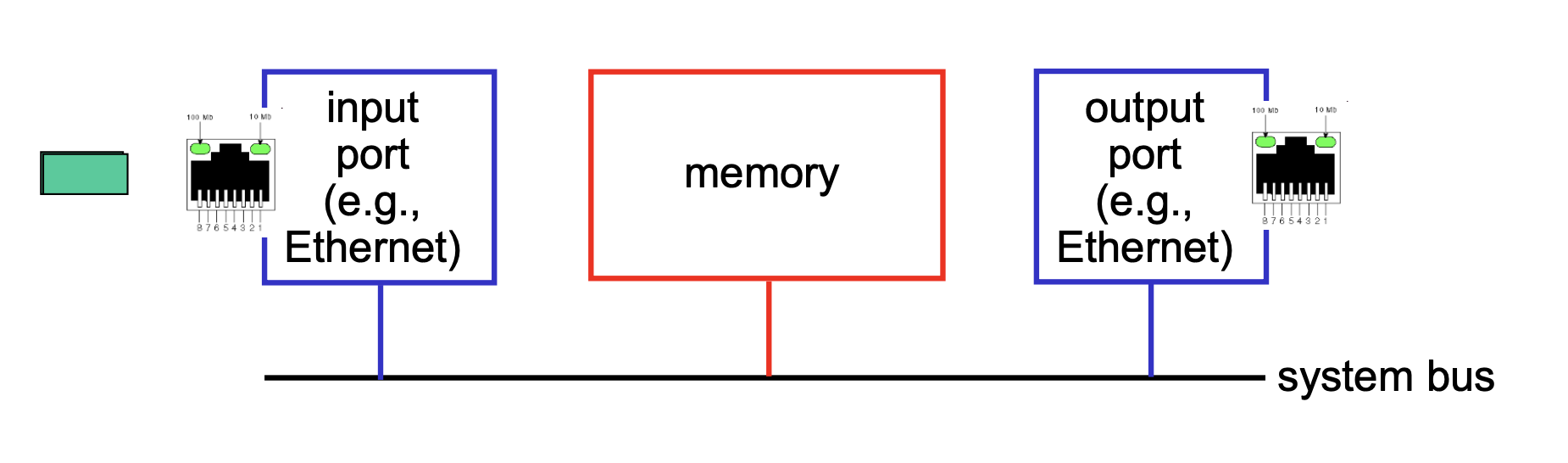
3-2. bus 구조
입력 포트로 들어온 패킷이 출력 포트로 나가는 데 공유 버스 회선를 사용한다.
하나의 회선을 모든 패킷이 공유하기 때문에, 이 버스 회선의 대역폭만큼으로 성능이 제한되며, 한 회선 안에 많은 패킷이 존재하면 서로 충돌(bus contention)할 우려가 있기 때문에 한 사이클 당 하나의 패킷만 처리할 수 있다는 단점이 있다.
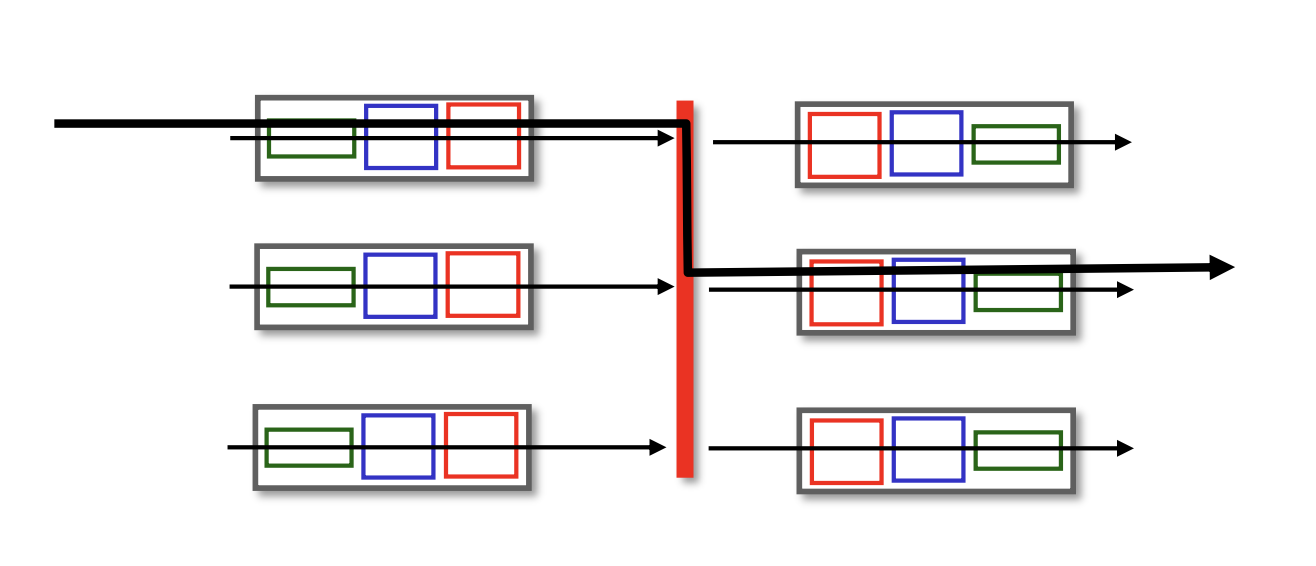
3-3. interconnection network 구조
crossbar(크로스바) 형태라고도 하며, 여러 개의 노선들이 서로 교차로처럼 얽혀 있다.
교차점에서는 마치 기차 철로처럼 신호에 따라 다른 길을 가도록 설계할 수 있으며, 이러한 신호들의 조합을 통해 경로를 설정한다. 한 출력 포트로 갈 수 있는 경로가 여러 개이기 때문에 여러 개의 패킷이 빠르게 이동할 수 있다는 장점이 있다.
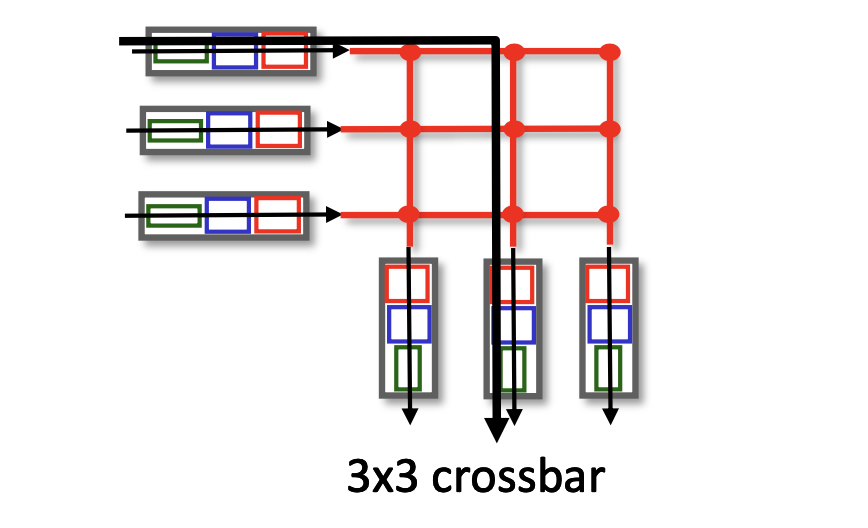
그러나 입, 출력 포트가 많아지면 이러한 교차점들이 매우 많아지게 되는 문제점이 생긴다.
서울에서 부산까지 고속도로를 연결할 때 중간중간 합류하거나 빠져나갈 수 있는 IC가 너무 많으면 전체 고속도로를 관리하기 매우 힘들다. 따라서 고속도로를 구간별로 나누어서 서울에서 대전까지는 A 고속도로, 대전에서 대구까지는 B 고속도로, 대구에서 부산까지는 C 고속도로로 분리한다면, 각 고속도로가 관리해야 하는 도로의 양이 줄어드므로 관리에 용이할 것이다.
이러한 방식을 기반으로 제시된 대안이 multi-stage switch 이다.
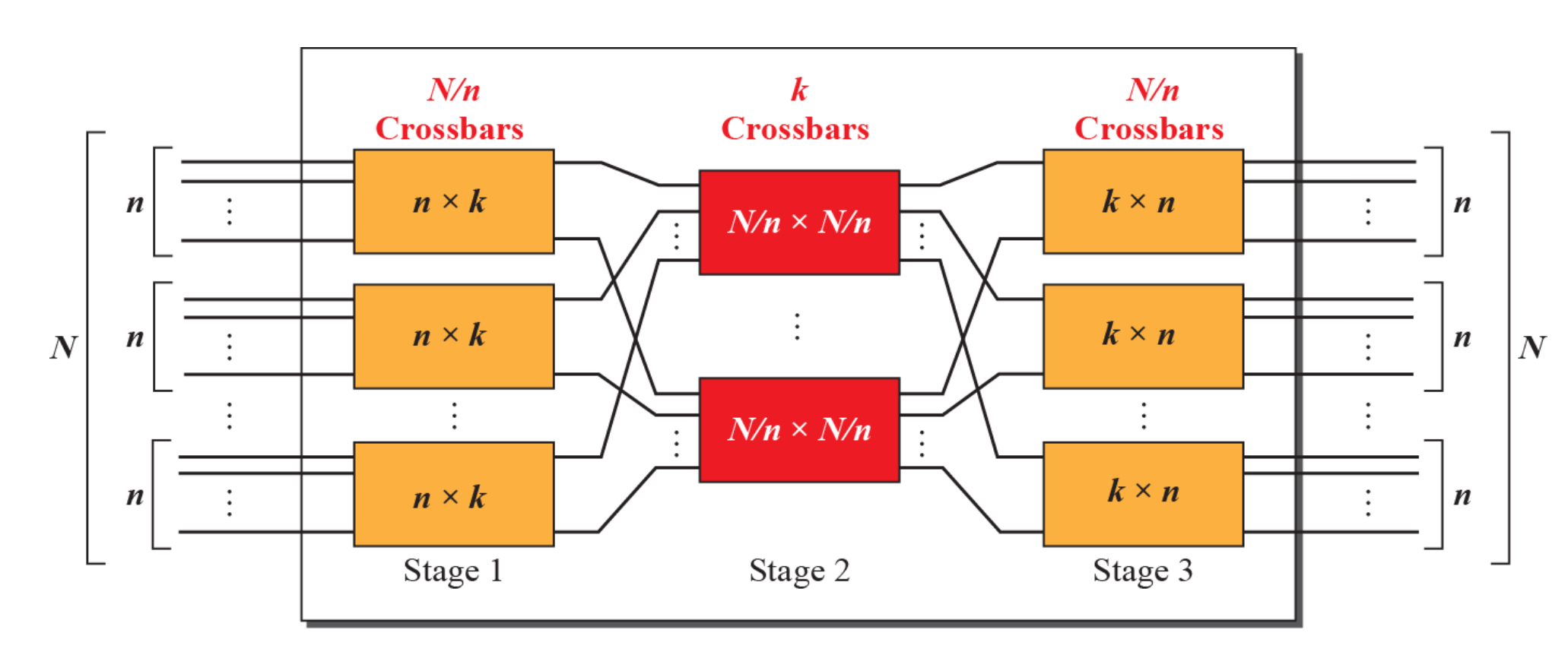
전체 N, N개의 입, 출력 포트를 n*k, N/n*N/n, k*n 의 세 스테이지로 나눈 구조로 회로를 구성한 모습이다.
그리고 이러한 fabric plane을 여러 개 병렬로 구성하면서 scale up 할 수 있다.
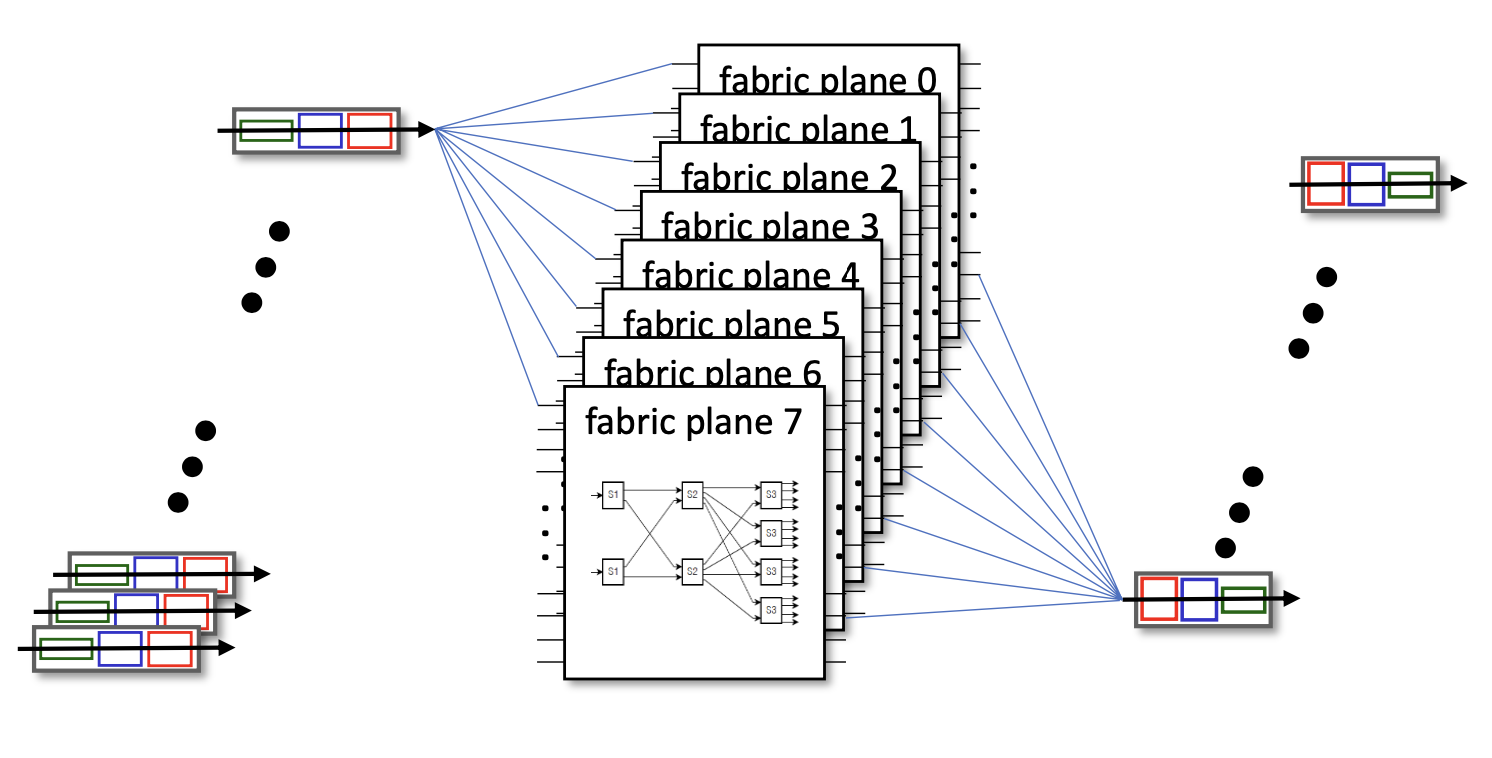
위 그림은 Cisco 에서 개발한 CRS 라우터의 내부 모습이며 3-stage interconnection network plane 8개가 병렬 형태로 구성되어 있는 것을 볼 수 있다.
4. Input port queueing
switch fabric이 패킷들을 처리하는 정도보다 입력 포트들로부터 패킷이 들어오는 정도가 더 빠르다면 queueing delay가 발생한다. 이럴 때는 어떻게 버퍼링을 관리할 것인지 buffering management policy가 필요하다.
큐의 맨 앞에 있는 패킷 때문에 큐의 뒤에 있는 패킷이 처리되지 못하고 대기하는 상황을 HOL(Head of line) blocking 이라고 한다.
만약 버퍼에 더 이상 공간이 없다면?
congestion 부분에서도 이미 다루었듯, 버퍼의 공간 부족으로 인해 패킷이 loss 될 수 있다. 어떤 패킷이 drop될 것인지 결정하는 정책 drop policy 가 있어야 할 것이다.
5. Buffer management
drop
버퍼가 꽉 차있는 상황에서, 새로운 패킷이 들어왔을 때, 어떤 패킷은 drop이 되어야 할 것이다. 어떤 패킷이 drop될 것인지는 두 가지 정책이 있다.
-
tail drop: 말 그대로 큐의 꼬리 부분, 즉 새로 들어오려는 패킷을 들여보내지 않고 drop 하는 정책이다. -
priority: 각 패킷들에우선순위(priority)개념을 부여한다. 즉 우선순위가 낮은, 상대적으로 덜 중요한 패킷을 내보내는 방식이다.
Packet scheduling
버퍼에 들어가 있는 패킷들 중에서 어떤 패킷들을 먼저 처리할 것인지에 대한 스케줄링 기법은 여러가지가 있다.
FCFS
FCFS (First Come, First Served) 방식은 말 그대로 들어오는 순서대로 처리하는 것이다. '큐' 의 동작 방식(FIFO, First In, First Out)과 동일하다.
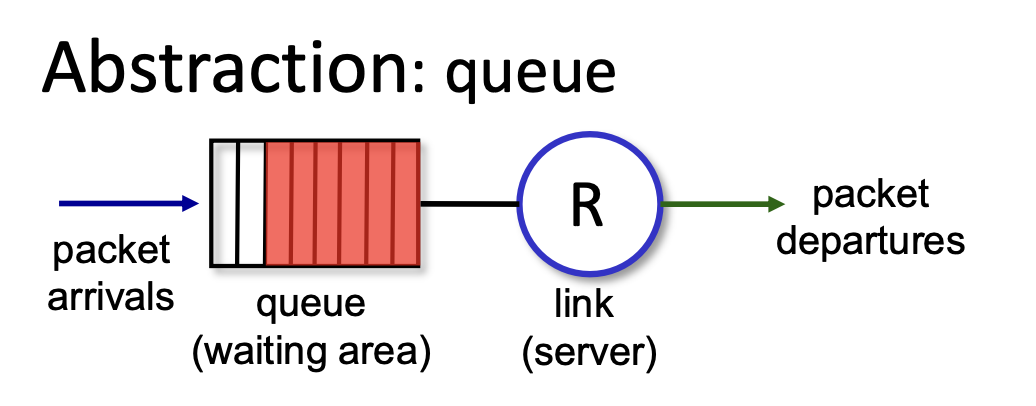
별다른 특기사항 없이 정직하게 처리하는 스케줄링 방식이다.
Priority
여러 개의 큐가 있다고 할 때, 각 큐에 우선순위를 부여하여 우선순위가 높은 큐에 속해 있는 패킷을 우선적으로 처리하는 정책이다.
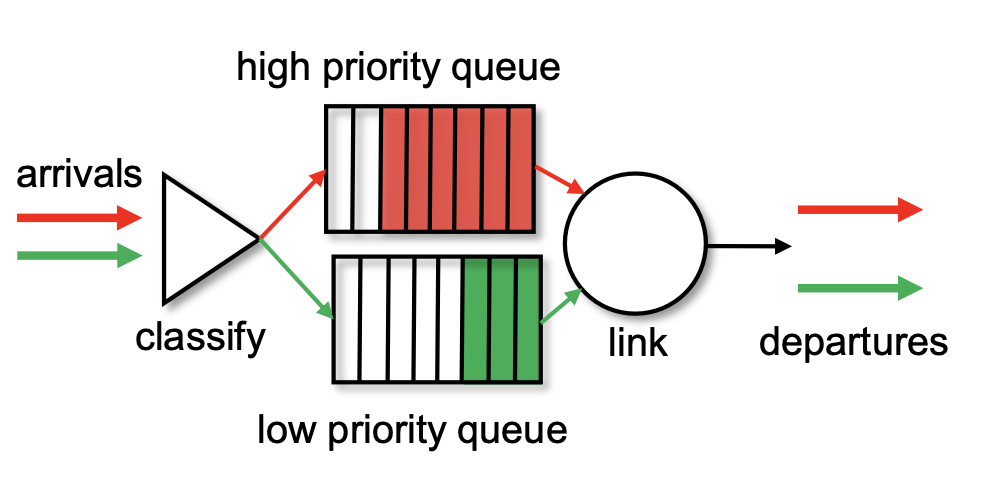
빨간 큐가 초록색 큐보다 우선순위가 더 높은 큐라고 가정했을 때 빨간색 큐에 존재하는 패킷이 먼저 처리될 때까지 초록색 큐는 처리되지 않는다.
이 때, 초록색 큐에 존재하는 패킷들은 오랜 시간이 지나도 빨간 큐가 비어지지 않는 한 처리되지 못할 수가 있는데, 이러한 문제점을 '기아 현상' starvation 이라고 한다.
Round-Robin
적절한 기준에 따라 큐를 여러 큐에 나누어서 분배해 놓고, 일정 시간 단위를 두고 큐를 번갈아 가면서 처리한다.
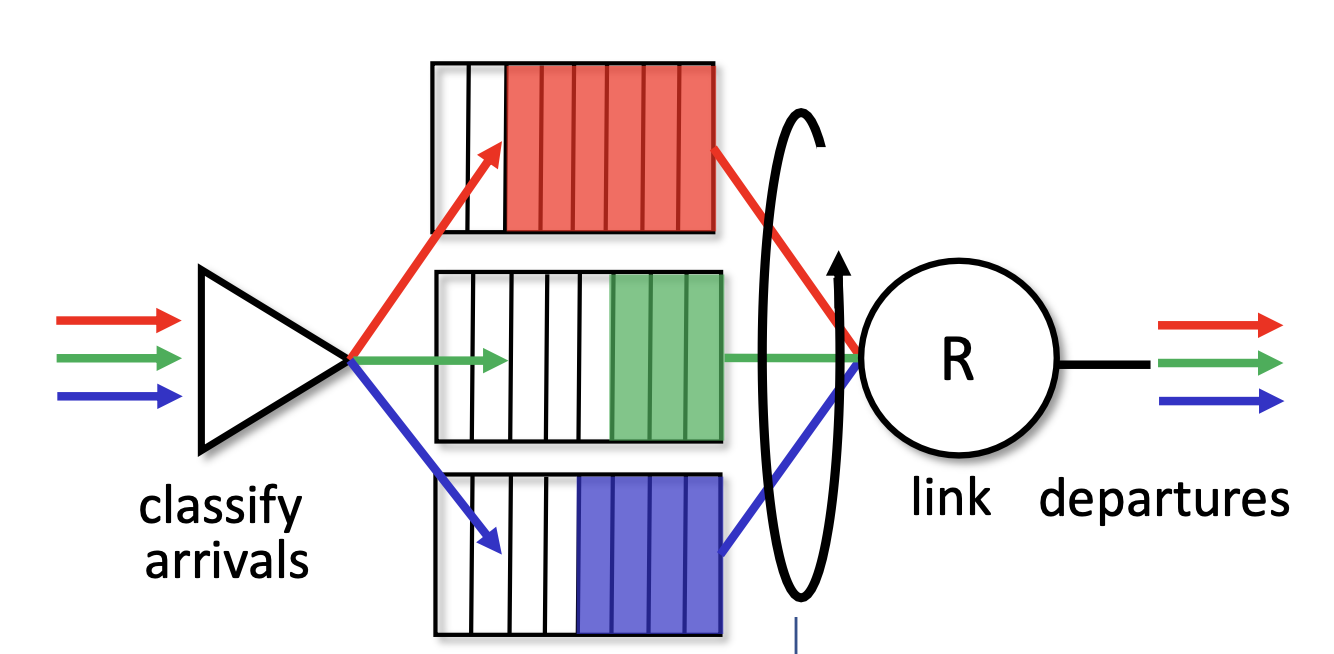
모든 큐에 동일한 기준을 적용하기 때문에 공평한 방식이다.
이 때, 우리는 패킷 단위로 패킷을 처리해야 한다. 시간 단위로 큐 사용시간을 할당한다고 하면 어떤 패킷은 전송 중간에 끊겨버리게 되는데 이러면 안 되기 때문이다.
그런데 패킷은 또 크기가 제각각이다. 즉 패킷 단위로 큐의 순서를 돌린다는 것은 생각보다 구현 과정이 까다로울 수 있다.
만약 큐 간에 우선순위가 있다면, 모든 큐가 평등하게 분배받는 것은 비효율적일 수 있다. 따라서 큐 간에 가중치를 부여하는 round robin 방식도 존재한다.
weighted fair queueing
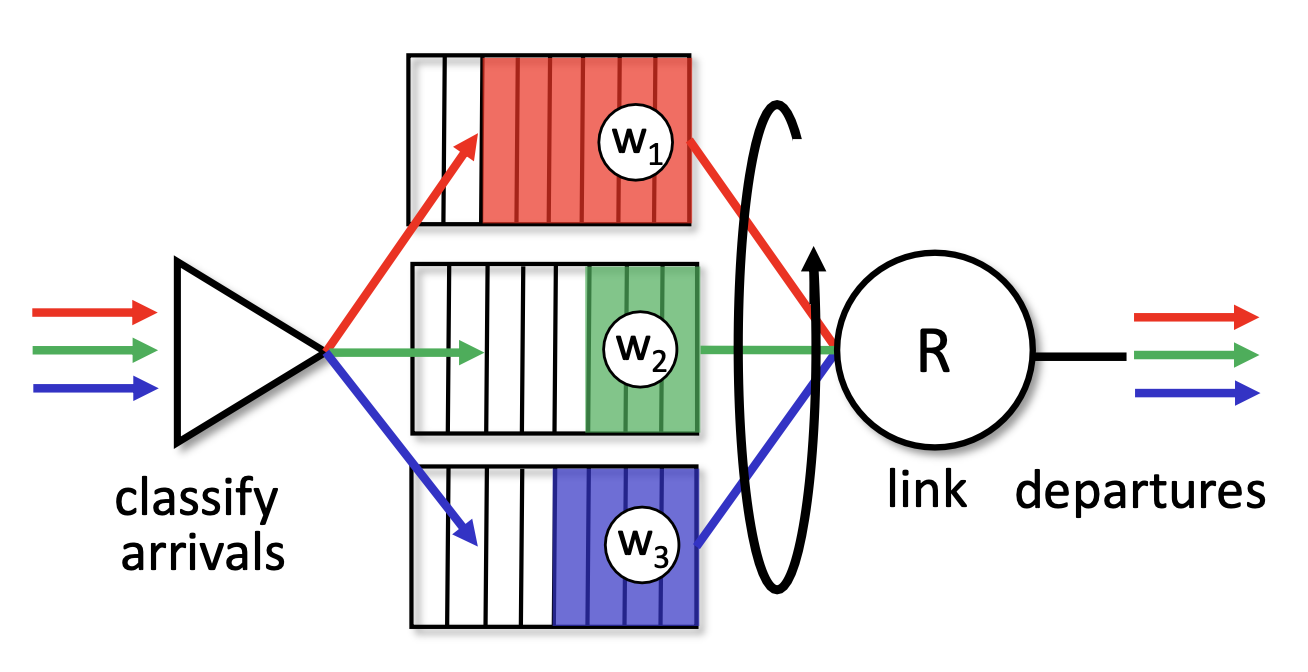
각 큐에 우선순위 가중치를 할당하고, 그 큐의 가중치만큼 큐 사용시간 분배에 차등을 두는 방식이다. weighted fair queueing(WFQ) 방식은 round-robin 방식을 일반화한 방식이다.
round-robin은 각 큐 간의 우선순위가 없어 가중치가 동일한 사례라고 생각할 수 있으므로 WFQ 방식이 보다 일반화된 방식이라고 할 수 있다.
빨강, 초록, 파랑 큐의 가중치가 각각 w1, w2, w3이라고 했을 때 빨강 큐의 가중치는 w1/w1+w2+w3 이다.
