⚠️ 들어가기 앞서
경북대학교 컴퓨터학부 COMP0414-001 컴퓨터망 과목을 공부하며 정리한 글입니다.
네트워크 계층에서 가장 중요한 구성 요소인 라우터의 기능은 크게 두 가지이다.
forwarding: router의 input link로 들어온 패킷들을 적절한 output link로 이동시키는 것 (내보내는 것)routing: 어떤 패킷이 출발지로부터 도착지까지 이동하는 경로(path)를 결정하는 것
라우팅 기능은 라우터의 control plane 에서 이루어지고, 경로를 결정하는 routing algorithm 을 이용해 data plane에서 포워딩을 할 때 참조되는 routing table 을 만든다.
각각의 라우터의 control plane에는 routing algorithm component가 있으며 이들이 서로 interact하여 경로를 결정한다.
이번 글에서는 어떤 식으로 routing이 이루어지는지, routing protocol에 대해서 알아보자
1. Routing Protocol
Routing Protocol은 네트워크의 라우터를 통해 전송자로부터 수신자까지 이동하는 "좋은" 경로를 결정하는 프로토콜이다.
여기서 어떤 경로가 "좋다"라는 것은 여러 가지 조건이 있을 수 있다. 비용이 가장 적은 경로일 수도 있고, 가장 빠르거나 congestion이 가장 덜한 경로일 수도 있다.
어떻게 "좋은" 경로를 결정할 것인가는 곧 전체 네트워크의 성능을 좌지우지하므로 매우 중요하다.
라우팅 알고리즘을 구현함에 있어 이를 단순화하기 위해 주로 그래프 형태로 표현하곤 한다.
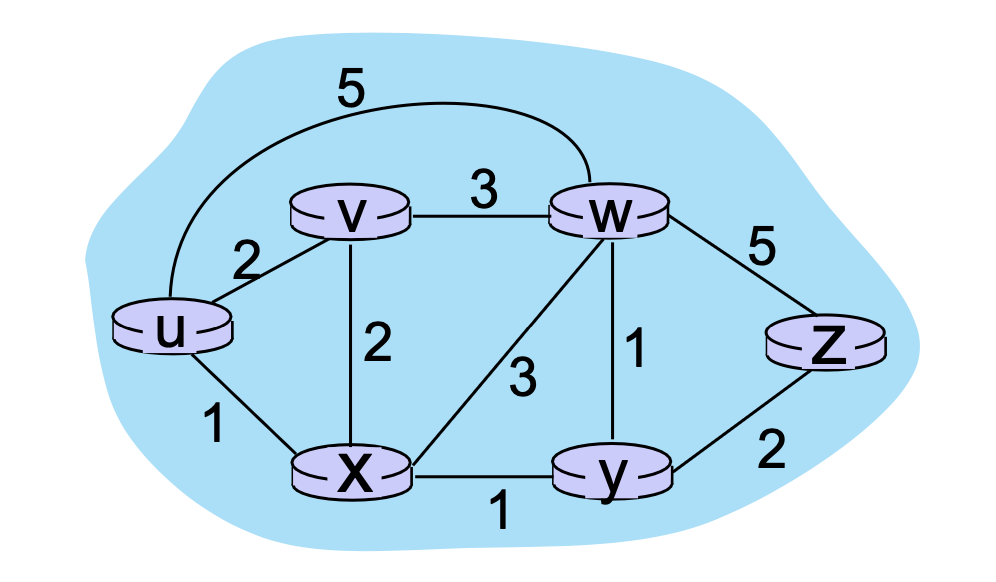
이런 식으로 각각의 라우터를 노드로, 라우터들을 연결하는 link들을 간선으로 단순화하여 표현할 수 있다.
라우팅을 수행하는 라우팅 알고리즘을 두 가지로 분류할 수 있다.
global or decentralized information:global이란 모든 라우터가 전체 네트워크의 topology와 link cost에 대한 정보를 모두 가지고 있는 형태를 의미한다. 반대로decentralized이란, 각각의 라우터가 자신과 이웃한 라우터까지의 link cost 정보만을 가지고 있고, 라우터들간의 정보 교환을 통해 점차 link cost 정보를 확장, 갱신해 나가는 형태를 의미한다.
여기서 global한 구조에서는 link state 알고리즘을 사용하고, decentralized한 구조에서는 distance vector 알고리즘을 사용한다.
2. Link State Algorithm
모든 라우터들이 network topology와 link cost들을 모두 알고 있다.
그래프 탐색 알고리즘 중 다익스트라 알고리즘을 이용한다.
[알고리즘] 다익스트라(Dijkstra) 알고리즘 (파이썬)
[알고리즘] 개선된 다익스트라(Dijkstra) 알고리즘 (파이썬)
다익스트라 알고리즘은 그래프에서 특정 노드부터 다른 모든 노드들까지의 최단거리를 구할 수 있는 알고리즘이다.
다익스트라 알고리즘에 대해서는 위의 글을 참고하면 좋다. (제가 씀) 다익스트라 알고리즘은 다음과 같은 순서로 동작한다.
- 출발 노드를 정하고, 다른 모든 노드들까지의 거리 정보를 저장한다. (처음에는 직접 연결된 노드들만 거리 정보가 들어있고 나머지는 무한대이다). 그리고 최단 거리를 발견한 노드들의 집합을 만든다.
- 모든 노드가 집합에 속할 때까지 다음을 반복한다.
- 집합에 속하지 않은 노드들 중에서 거리 정보가 가장 작은 노드를 선택한다.
- 그 노드를 집합에 추가하고, 그 노드에서 이웃한 노드들에 대한 거리 정보를 이용하여 거리 정보를 갱신한다.
다익스트라 알고리즘은 n번의 iteration마다 추가한 노드의 이웃 간선 정보를 추가하는 과정을 거치므로 O(n^2)의 시간 복잡도로 알려져 있고, 개선을 통해 O(nlogn) 만에 수행 가능하다.
3. Distance Vector Algorithm
각 노드는 자신에게 연결된 이웃의 링크의 비용만 알고 있기 때문에 이웃 노드들끼리 반복적으로 정보를 교환해 최적의 경로를 갱신한다.
벨만-포드 알고리즘을 주로 이용한다.
각 노드가 인접한 노드들의 routing table을 보고 자신이 가진 routing table을 갱신하는 과정을 거친다. 다익스트라 알고리즘이 이웃들 간의 '간선 정보'만을 참조한다면 벨만 포드 알고리즘은 routing table 전체를 교환한다고 볼 수 있다.
만약 내가 갖고 있는 노드 간의 경로보다, 나의 이웃으로부터 새롭게 받은 정보의 경로가 더 좋은 경로라면 이를 수정한다. 그리고 수정 사항이 생겼으면 나의 이웃들이 내가 알고 있는 경로를 참조하고 있을 수 있으므로, 나의 이웃들에게 또다시 수정본 routing table 정보를 보내준다. 만약 수정사항이 생기지 않았으면 정보를 보내지 않는다.
위와 같은 작업을 거치기 때문에, Distance vector 알고리즘은 반복적이고 (iterative) 비 동기적(asynchronous)이라고 할 수 있다.
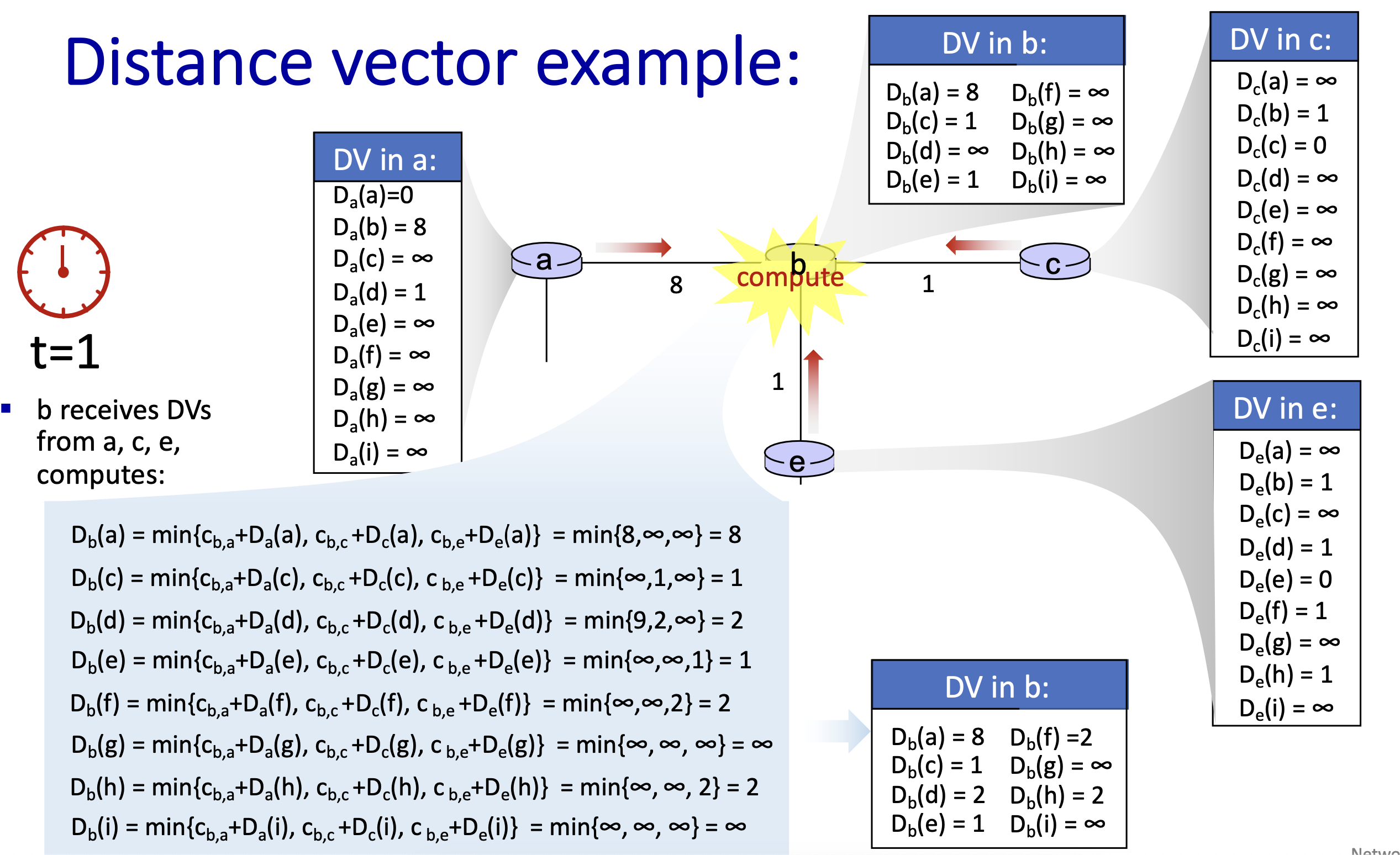
노드 b가 자신과 인접한 노드 a, c, e에게서 받은 Distance Vector 정보를 이용하여 자신의 Distance Vector를 갱신하고 있는 과정이다. min 연산을 이용하는 것을 볼 수 있다.
Count to Infinity Problem
count to infinity란 distance vector 알고리즘에서 나타날 수 있는 문제점이다.
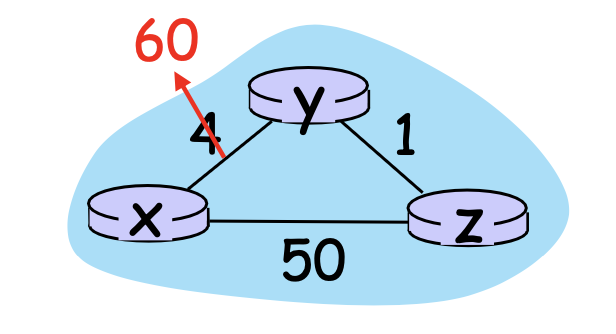
만약 위 사진과 같은 구조로 간선 정보가 존재하고, 각 노드들은 자신의 distance vector를 완성하여 가지고 있다고 가정할 때, 간선 (x, y)의 비용이 4에서 60으로 증가했다고 가정해 보자.
- y는 z의 distance vector를 이용하여 x까지의 비용을 수정한다. (z의 DV에는 간선 비용 변경 전의
z->y->x경로, 즉 비용 5짜리의 경로가 존재한다.) y->z까지의 거리가 1이고, z의 DV에 따르면z->x까지의 거리가 5이므로 y는 x까지의 비용을6으로 수정한다. (y->z->x경로)- 변경사항이 발생했으므로 y는 자신의 DV를 x와 z에게 전달한다.
- 이를 받은 z는 거리를 재연산한다. z에서 x까지 직접 가는
z->x경로보다 y를 경유하여z->y->x가 더 비용이 적다. y의 DV에 따르면y->z경로 비용은 6이므로, 여기에다가z->y경로를 더하여7을 x까지의 경로로 수정한다. (z->y->x)
위의 작업이 계속 반복되어 y->x 정보가 8로, z->x 정보가 9로... 불필요한 연산이 많이 수행되고 나서야 y에서 x로 가는 비용이 51이라고 알 수 있게 된다. 그리고 z도 그제서야 y를 거치는 것보다 x로 곧장 가는 것이 더 좋음을 알 수 있다.
이는, 어떤 간선의 정보가 이웃 간의 DV가 아닌 외부에 의해 변경 되었을 때, 노드들끼리 갖고 있는 예전 정보를 반복적으로 참조하면서 발생한다.
4. LS vs DV algorithm
| 분류 | Link State | Distance Vector |
|---|---|---|
| 정보 | 모든 정보를 인식하고 있음 | 이웃한 라우터의 정보만을 인식 |
| 사용 알고리즘 | 다익스트라 알고리즘 | 벨만-포드 알고리즘 |
| 교환 방식 | 링크 정보만을 교환 | 전체 라우팅 테이블을 교환 |
| 성능 및 시간복잡도 | N^2개의 메시지가 교환 | 그래프의 지름에 따라 동적 |
| 라우팅 테이블 | 내 라우팅 테이블을 다른 노드가 참조하지 않음 | 내 라우팅 테이블을 다른 노드가 참조함 |
