👉 해시 테이블(Hash table)
 출처: https://ko.wikipedia.org/wiki/해시_테이블
출처: https://ko.wikipedia.org/wiki/해시_테이블
해시 테이블은 1953년 IBM에 근무하던 한스 피터 룬(Hans Peter Luhn)이 사내 메모에서 해싱과 체이닝을 결합하여 처음 사용한 것으로 알려져 있다.
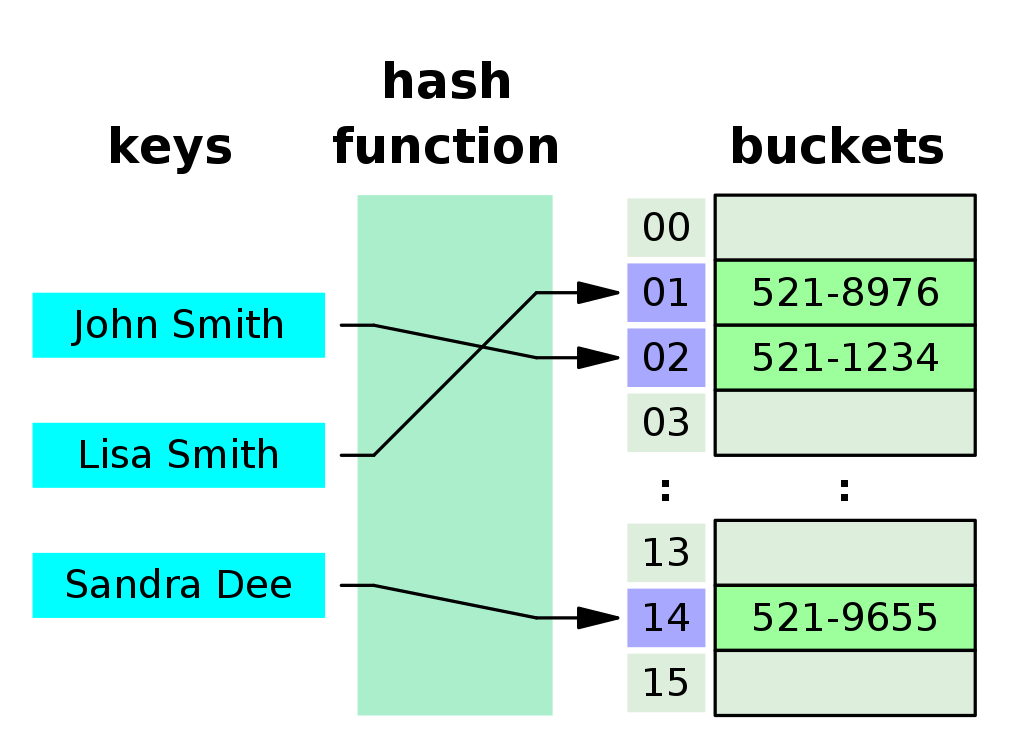
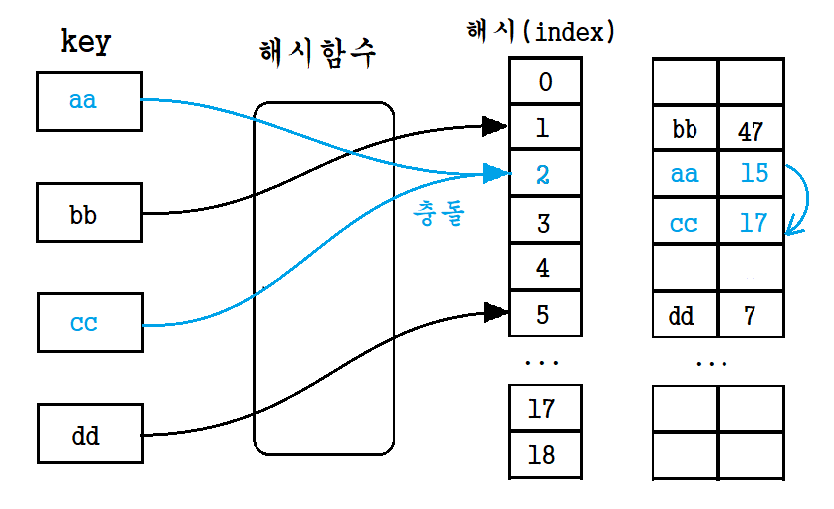
해시 테이블(hash table)은 해시 함수를 사용하여 키(key)를 해시로 변환하고 이 해시를 인덱스(index) 데이터를 저장하는 자료구조 이다.
데이터가 저장되는 곳을 테이블(table), 버킷(bucket) 또는 슬롯(slot)이라고 히며 해시 테이블의 기본 연산은 삽입, 삭제, 탐색이다.
해시 테이블은 대부분의 연산이 분할 상환 분석에 따른 최적의 경우 O(1) 시간복잡도를 가진다.
(배열과 같이 index(해시)를 통해 버킷(bucket)에 접근하여 데이터를 저장, 삭제, 탐색을 한다.)
따라서 데이터 양에 관계없이 빠른 성능을 기대할 수 있다.
(분할 상환 분석에 따른 최적의 경우로 최악의 경우(모든 값 충돌)는 O(n)이 된다.)
👉 해시 함수
해시 함수(hash function) 혹은 해시 알고리즘(hash algorithm)은 임의 크기 데이터를 고정된 크기 값으로 변환하는 함수이다.
변환 전 원래의 데이터를 키(key), 변환 후 (해시 함수 처리 후) 값은 해시 값(hash value), 해시 코드 또는 간단하게 해시, 해시 테이블을 인덱싱하기 위해 이처럼 해시 함수를 사용하는 것을 해싱(hashing)이라 한다.
해싱은 정보를 가능한 빠르게 저장하고 검색하기 위해 사용하는 중요한 기법 중 하나이며 최적의 검색이 필요한 분야에 사용되고, 심볼테이블 등의 자료 구조를 구현하기에도 적합하다.
이외에도 해시함수는 체크섬(Checksum), 손실 압축, 무작위화 함수(Randomization Function), 암호 등과도 관련이 깊다.
✍️ 성능 좋은 해시 함수들의 특징
- 해시 값 충돌의 최소화
- 쉽고 빠른 연산
- 해시 테이블 전체에 해시 값이 균일하게 분포
- 사용할 키의 모든 정보를 이용하여 해싱
- 해시 테이블의 사용효율이 높을 것
✍️ 해시 테이블에 사용되는 대표적인 해시 함수(알고리즘)
-
나눗셈 방식(Division Method)
주소 = 입력값 % 테이블의 크기
나눗셈을 이용한 방법으로 입력값을 테이블의 크기로 나누어 계산한다.
테이블의 크기를 2의 제곱수에 가깝지 않은 소수를 택하는 것이 효과가 좋다고 알려져 있다.
- 자리수 접기(Digit Folding)
key의 문자열을 ASCII 코드로 변환하고 변환한 모든 값을 합한 데이터를 테이블 내 주소로 사용하는 방법이다.
-
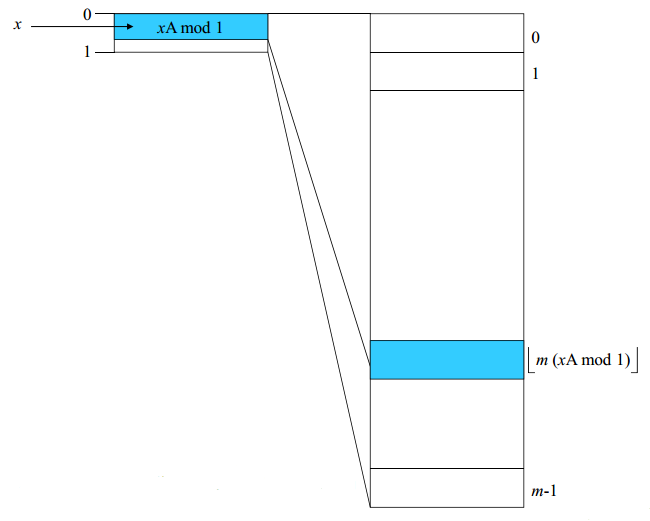
곱하기 방법(Multiplication Method)
입력값을 0 ~1 사이의 소수로 대응시킨 다음 해시 테이블 크기 m을 곱하여 0 ~ m-1 사이로 팽창시킨다.0<A<1의 범위의 상수A를 만들고 입력값(x)에 A를 곱한 다음 소수부분만 취하고 테이블 크기(m)을 곱하여 그 정수부분을 취하여 주소값(인덱스)으로 설정한다.
h(x) = [m(xA mod 1)]
- Univeral Hashing
다수의 해시함수를 만들어 집합 H에 넣어두고, 무작위로 해시 함수를 선택해 해시값을 만드는 기법이다
👉 해시
위에서 언급했듯이 임의 크기의 데이터가 해시함수를 통해 변환된 고정된 길이의 데이터이며 다양한 목적으로 사용된다.
-
해시 테이블
-
암호화
해시는 입력받은 데이터를 완전히 새로운 데이터로 만든다.
변환된 데이터는 원본의 모습을 알아볼 수 없을 정도로 완전히 달라진다.
이러한 단방향 암호화는 암호화 영역에서 아주 주요하게 사용되고 있다.
SHA(Secure Hash Algorithm) 이 그 대표적 예이다. -
데이터 축약
해시는 길이가 서로 다른 입력 데이터를 일정한 길이의 출력 값으로 만든 것이다. 이 특성을 이용하면 크기가 큰 데이터를 '해싱'하여 짧은 길이의 해시로 축약이 가능하다. 이렇게 축약된 해시끼리 비교하는 것이 원본 데이터를 비교하는 것에 비해 엄청난 효율을 낸다.
👉 충돌
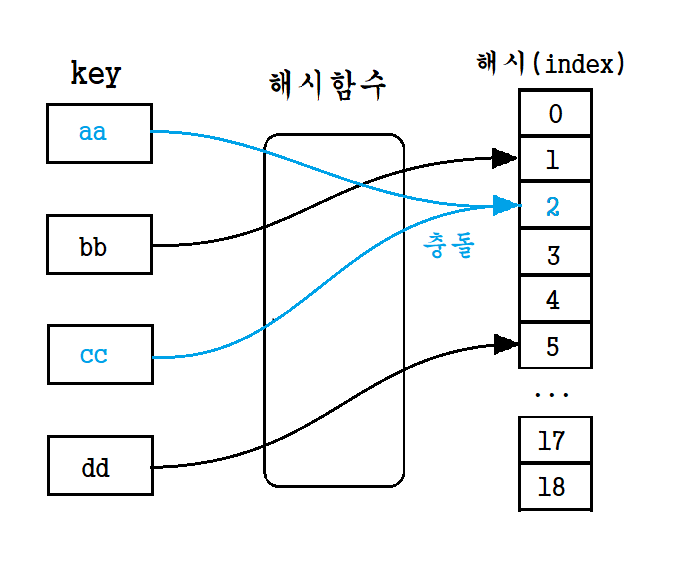
위에 설명했듯이 해시테이블은 해시함수를 통해 나온 해시값을 인덱스로 table에 데이터를 저장하는 자료구조이다. 그렇다면 해시함수를 통해 나온 해시값이 동일한 경우는 어떠한가? 해시값이 동일한 경우 1개의 테이블에 2개(혹은 그 이상)의 데이터가 할당되어 충돌이 발생한다. 그렇다면 이러한 충돌 현상을 해결하는 방법은 무엇인가?
해결 방법으로 개별 체이닝(Separate Chaining)과 오픈 어드레싱(Open Addressing) 방식이 있다.
✍️ 개별 체이닝
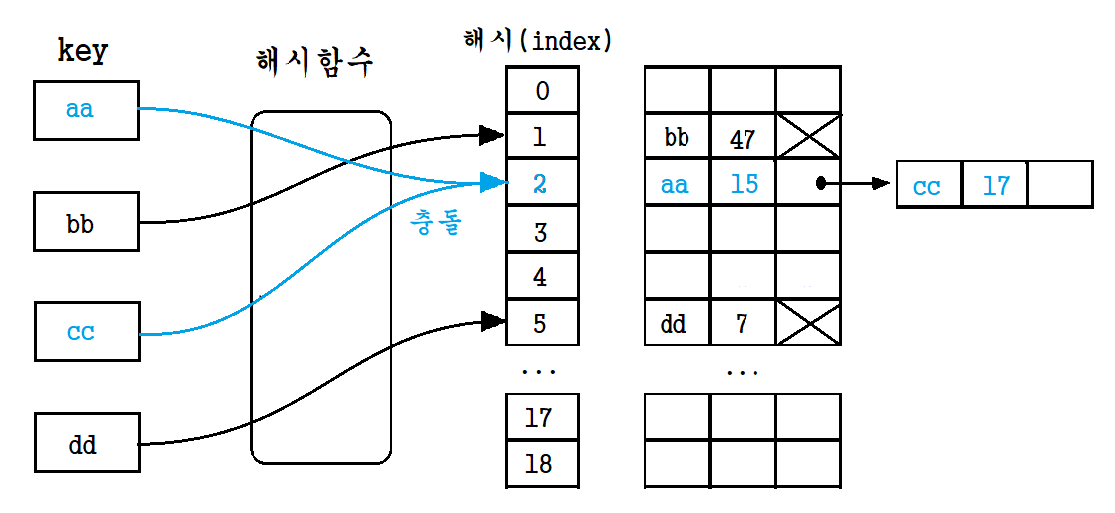
개별 체이닝(Separate Chaining)은 충돌 발생 시 그림과 같이 연결리스트로 연결하는 방식이다.
가장 처음에 사용된 전통적인 방식으로 기본적인 자료구조와 임의로 정한 간단한 알고리즘만 있으면 되므로, 사용성이 높다.
잘 구현한 경우 대부분의 탐색은 O(1)이지만 최악의 경우, 즉 모든 해시 충돌이 발생한 경우 O(n)의 시간복잡도를 가진다.
✍️ 오픈 어드레싱
오픈 어드레싱(Open Addressing)은 충돌 발싱 시 탐사를 통해 빈 공간을 찾아나가는 방식이다.
충돌이 일어나면 테이블 공간 내에서 탐사(Probing)를 통해 빈 공간을 찾아 저장하기 때문에 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장이 없다.
오픈 어드레싱 방식 중 가장 간단한 방식인 선형 탐사(Linear Probing) 방식은 충돌이 발생할 경우 해당 위치부터 순차적으로 탐사를 진행한다
구현 방법이 간단하면서 의외로 전체적인 성능이 좋은 편이긴 하지만 해시 테이블에 저장되는 데이터들이 고르게 분포되지 않고 뭉치는 경향이 있다. (이렇게 뭉치는 형상을 클러스터링(Clustering)이라한다.)
이러한 현상은 탐사 시간을 오래 걸리게 하며, 전체적으로 해싱 효율을 떨어뜨리는 원인이 된다.
또한 사실상 무한정 저장할 수 있는 체이닝 방식과 달리, 오픈 어드레싱 방식은 전체 테이블(슬롯, 버킷)의 개수 이상은 저장할 수 없다.
따라서 일정 이상 데이터가 채워지면, 즉 기준이 되는 로드 팩터 비율을 넘어서게 되면, 더 큰 크기의 또 다른 버킷을 생성 후 복사하는 리해싱(Rehashing)작업이 일어난다. (동적배열에서 공간이 가득 찰 경우, 더블링으로 새롭게 복사하는 과정과 유사)
🤔 로드 팩터(Load Factor)
해시 테이블에 저장된 데이터 개수(n)를 테이블의 개수(m)로 나눈 것이다.
load factor = n/m로드 팩터(load factor)의 비율에 따라 해시 함수를 재작성해야 할지, 해시 테이블의 크기를 조정 할지를 정한다. 또한 이 값은 해시 함수가 키들을 잘 분산해 주는지를 말하는 효율성 측정에도 사용된다. 로드 팩터가 증가 할수록 해시 테이블의 성능은 점점 감소하며, 자바 10의 경우 0.75를 넘어설 경우 동적 배열처럼 테이블의 공간을 재할당한다.
파이썬에서 딕셔너리는 해시테이블 - 오픈어드레싱 방식으로 구현되었다.
오픈 어드레싱 방식을 채택한 이유로 CPython 구현 주석에서 "체이닝 시 malloc으로 메모리를 할당하는 오버헤드가 높아 오픈 어드레싱을 택했다."라고 설명한다.
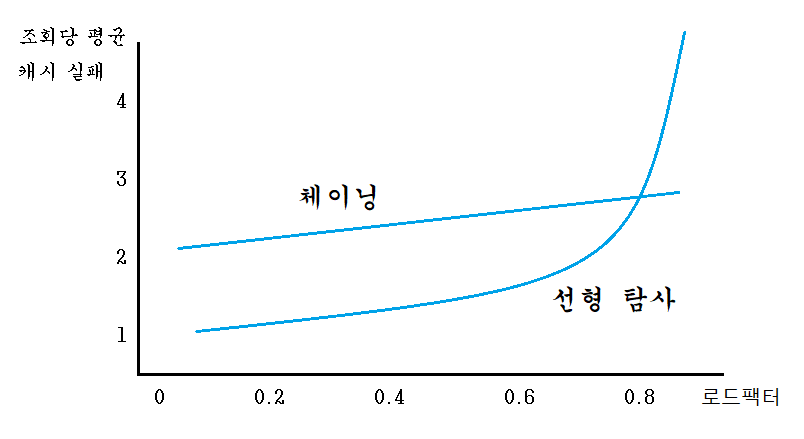
위 그래프에서 볼 수 있듯이 일반적으로 선형 탐사 방식이 체이닝에 비해 성능적으로 더 좋다.
그러나 슬롯 80% 이상이 차게 되면 급격한 성능 저하가 일어나며 체이닝과 달리 전체 슬롯의 개수 이상(로드팩터 1 이상)은 저장할 수 없다.(빈 공간을 탐사하기 때문에 공간이 찰 수록 탐사 시간이 더 오래걸리며 가득차게 될 경우 빈 공간을 찾을 수 없다.)
따라서 파이썬과 루비와 같이 언어들은 오픈어드레싱 방식을 택하여 성능을 높이는 대신, 기준이 되는 로드 팩터를 크기를 작게 잡아 리해싱(Rehashing)작업을 빠르게 발생시켜 선형 탐사 방식의 단점을 해결 하였다.
✍️ 구현
파이썬 구현
class ListNode:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
class MyHashMap:
def __init__(self):
self.size = 1000
self.hash_table = [None] * self.size
def put(self, key: int, value: int) -> None:
index = key % self.size
if self.hash_table[index] == None:
# We do not have anything in this bin, just create a new node
self.hash_table[index] = ListNode(key, value)
else:
# We do have something in this bin, traverse it checking to see if we have a matching key. If not just append a node to the end of the bin
curr_node = self.hash_table[index]
while True:
if curr_node.key == key:
curr_node.value = value
return
if curr_node.next == None: break
curr_node = curr_node.next
# Did not find a matching key here, so append a key, value pair in this bin
curr_node.next = ListNode(key, value)
def get(self, key: int) -> int:
index = key % self.size
curr_node = self.hash_table[index]
while curr_node:
if curr_node.key == key:
return curr_node.value
else:
curr_node = curr_node.next
return -1
def remove(self, key: int) -> None:
index = key % self.size
curr_node = prev_node = self.hash_table[index]
# Removing from empty bin just return
if not curr_node: return
if curr_node.key == key:
# We found the node to delete immediately, we can now skip over it
self.hash_table[index] = curr_node.next
else:
# We did not find the node to delete we must now traverse the bin
curr_node = curr_node.next
while curr_node:
if curr_node.key == key:
prev_node.next = curr_node.next
break
else:
prev_node, curr_node = prev_node.next, curr_node.next
# Your MyHashMap object will be instantiated and called as such:
# obj = MyHashMap()
# obj.put(key,value)
# param_2 = obj.get(key)
# obj.remove(key)자바스크립트 구현
class hashTable{
constructor(size){
this.storage = [];
if(size){
this.size = size;
}
else{
this.size = 100;
}
}
insert = (key,value) => {
let index = this.hash(key);
if(this.storage[index] === undefined){
this.storage[index] = [[key, value]];
}
else{
let storageFlag = false;
for(let i = 0; i < this.storage[index].length; i++){
if(this.storage[index][i][0] === key){
this.storage[index][i][1] = value;
storageFlag = true;
}
}
if(!storageFlag){
this.storage[index].push([key,value]);
}
}
}
delete = (key) => {
let index = this.hash(key);
if(this.storage[index] === undefined){
return false;
}
else if(this.storage[index].length === 1 && this.storage[index][0][0] === key){
this.storage.splice(index,1);
return true;
}
else{
for(let i = 0; i < this.storage[index].length; i++){
if(this.storage[index][i][0] === key){
this.storage[index].splice(i,1)
return true;
}
}
return false;
}
}
search = (key) => {
let index = this.hash(key);
if(this.storage[index] === undefined){
return false;
}
else if(this.storage[index].length === 1 && this.storage[index][0][0] === key){
return this.storage[index][0][1];
}
else{
for(let i = 0; i < this.storage[index].length; i++){
if(this.storage[index][i][0] === key){
return this.storage[index][i][1];
}
}
return false;
}
}
hash = (key) => {
let hash = 0;
for(let i = 0; i < key.length; i++){
hash += key.charCodeAt(i);
}
return hash % this.size;
}
getTable(){
return this.storage;
}
}
let data = new hashTable(100);
data.insert(1,5);
data.insert('asd', 12);
data.insert(213,14);
data.insert('a', 'b');
data.insert('213', '12');
console.log(data.search(1));
console.log(data.search(213));
data.delete(1);
console.log(data.search(1));
data.insert(1,10)
data.delete('a');
console.log(data.search(1));
console.log(data.getTable())Reference)
파이썬 알고리즘 인터뷰
https://ko.wikipedia.org/wiki/해시_테이블
http://wiki.hash.kr/index.php/%ED%95%B4%EC%8B%9C%ED%85%8C%EC%9D%B4%EB%B8%94
https://mangkyu.tistory.com/102
https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/
https://itstory.tk/entry/%ED%95%B4%EC%8A%81Hashing-%ED%95%B4%EC%89%AC-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%ED%95%B4%EC%89%AC-%ED%95%A8%EC%88%98
https://medium.com/@clgh0331/javascript-node-js-hash-table%EC%9D%84-%EA%B5%AC%ED%98%84-f1442b24571c - JS구현코드
