알고리즘을 처음 배웠을 때 빅오 다음으로 배웠던 내용이다.
데이터를 구조체로 묶어서 포인터로 연결한다는 개념을 코드로 구현하는데 있어서 비전공자인 나에게 이해를 하는데 많은 어려움이 있었다.(youtube에 존재하는 연결리스트 영상은 다 본 듯 하다...)
이 포인터의 개념을 이해하고 나니 스택, 큐 ... 등 이후의 자료구조들이 순차적으로 이해가 되었다.
👉 연결리스트(Linked List)
연결리스트는 컴퓨터 과학에서 배열과 함께 가장 기본이 되는 대표적인 선형 자료구조 중 하나로 다양한 추상 자료형(Abstract Data Type) 구현의 기반이 된다.
새로운 노드(데이터)를 삽입 및 삭제하기 간편하며 물리적메모리를 연속적으로 사용하지 않아 관리도 쉽다.
따라서 시작이나 끝 지점에 아이템(데이터)을 삽입 및 삭제 작업은 O(1)에 가능하다.
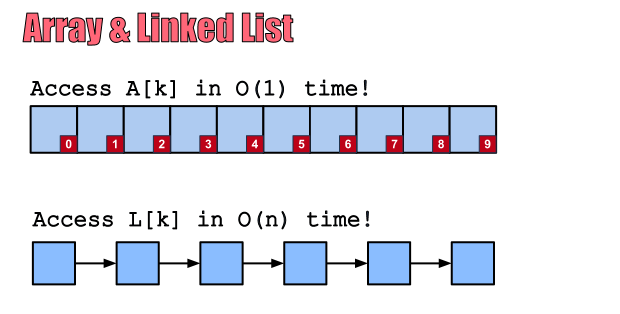
반면, 탐색은 물리적메모리를 연속적으로 사용하지 않기 때문에 특정 인덱스에 접근하기 위해서는 배열과 달리 전체를 순서대로 읽어야 하므로 O(n)의 시간 복잡도를 가진다
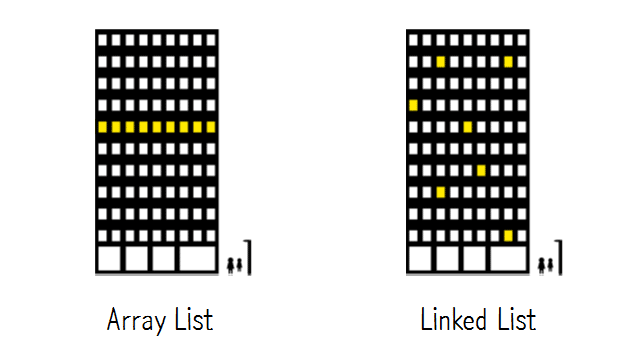
🤚 배열(Array) vs 연결리스트(Linked List)
구조
메모리
참조) 생활코딩-linked list
탐색
- Array
시간복잡도: O(1)
물리적메모리에 연속적으로 저장되기 때문에 인덱스를 통해서 쉽게 접근 가능하다.-Linked List
시간복잡도: O(n)
물리적메모리에 연속적으로 저장되지 않기 때문에 특정 인덱스에 접근하기 위해서는 전체를 순서대로 읽어야한다.
삽입, 삭제
-Array
시간복잡도: O(n)
물리적 메모리에 연속적으로 저장되어 있기 때문에 데이터의 삭제 및 삽입 시 메모리 공간을 한 칸씩 당기거나 미루는 과정이 필요하다. 또한 모든 공간이 다 차버렸다면 새로운 메모리 공간을 만들어야한다.-Linked List
시작, 끝: 시간복잡도 O(1)
중간 -> 조회 후 추가 및 삭제, O(n)
- 결론
데이터의 삽입/삭제가 자주 일어난다면 -> 연결리스트(Liked List)
데이터 접근(탐색)이 자주 일어난다면 -> 배열(Array)
✍️ 연결리스트 구현
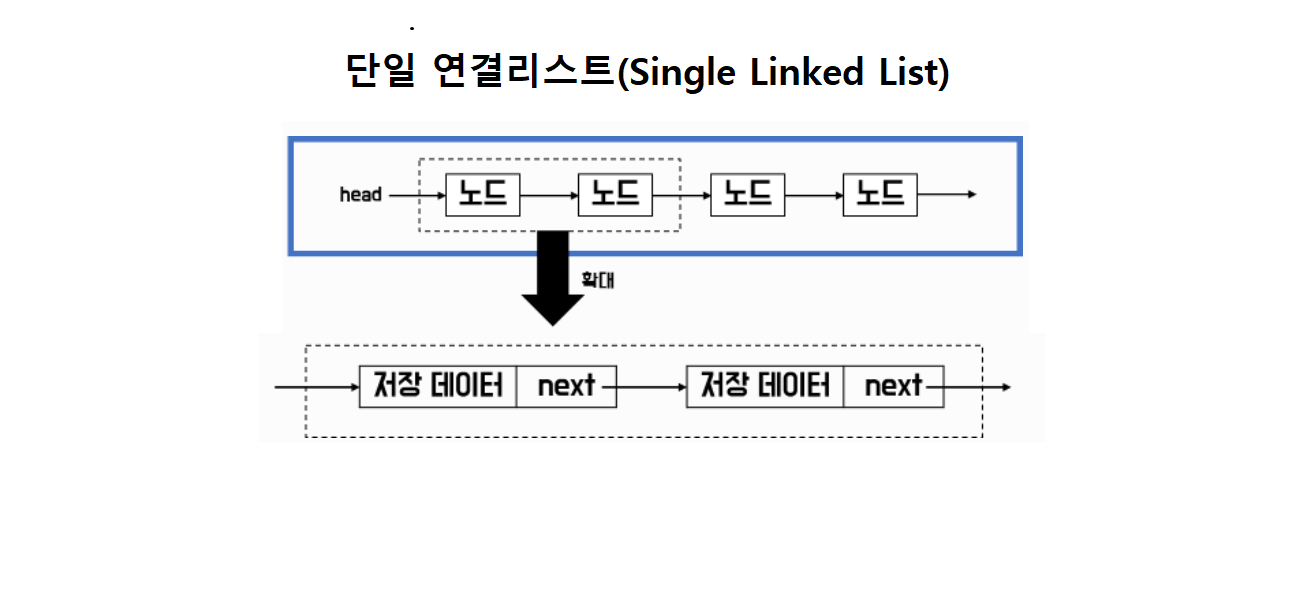
👉 단일 연결리스트
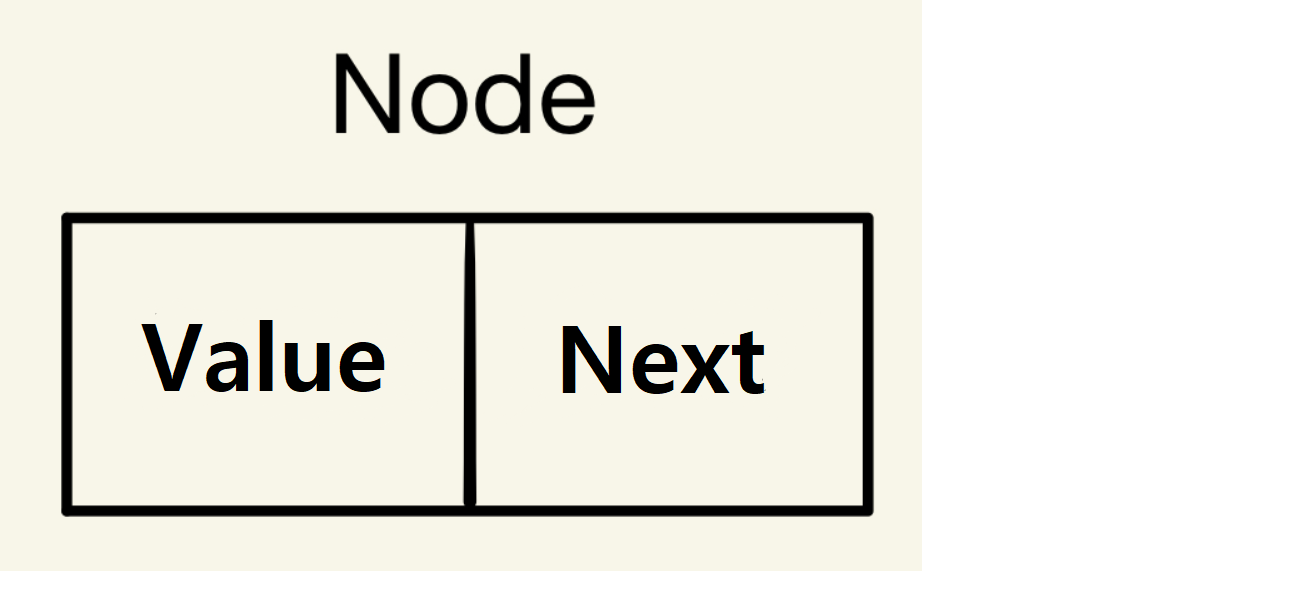
노드라는 구조체를 만들어next라는 변수를 통해 다음 노드의 메모리 주소를 가리키는 포인터로 노드를 연결시켜 구현한다.
1. 노드 만들기
노드라는 구조체를 만든다.
class Node:
# 노드초기화
def __init__(self, value, next):
self.value = value
self.next = next 2. 삽입(추가)
삽입(추가)은 self.head 라는 초기 변수(헤드)를 만들어 노드를 연결시켜 나간다.
저장된 노드 유뮤에 따라 2가지 경우로 구분하여 구현한다.
- 1) 저장된 노드가 없는 경우
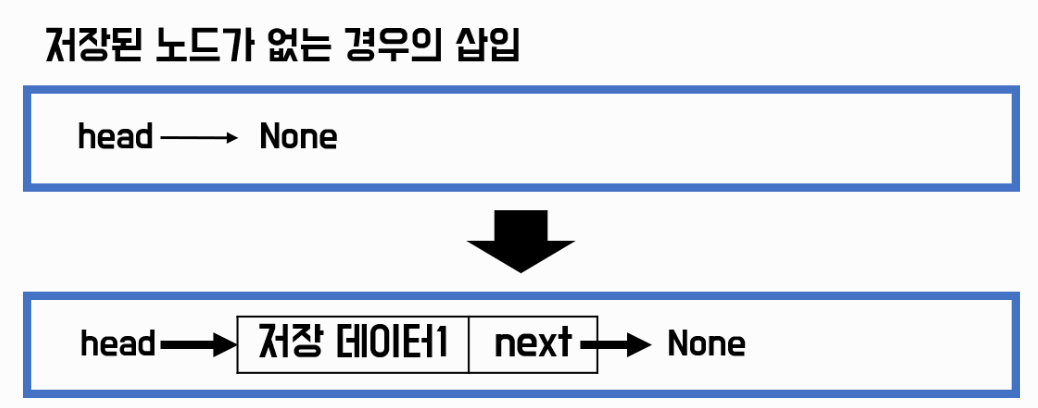
저장된 노드가 없는 경우 self.head = None 이다.
self.head에 노드를 만들어 연결하면 된다.
# 1) 노드가 없는 경우
if not self.head:
self.head = Node(value, None)
return-
2) 저장된 노드가 있는 경우
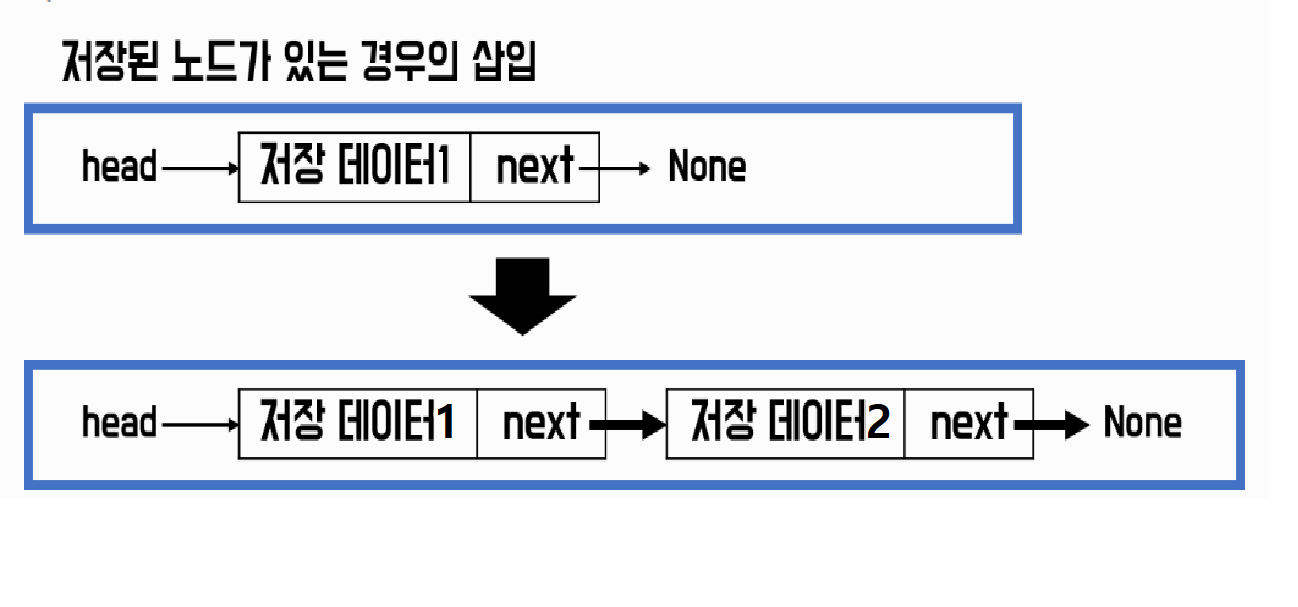
위 예시 그림의 구현 코드 결과이다.
self.head = {value:저장데이터1, next={value:저장데이터2, next=None}}
self.head에 node를 만들어 연결하고 node의 next에 새로운 노드를 만들어 연결한다.
따라서 새로운 노드 추가 시 가장 안쪽의 노드(객체)의 next에 접근하여 새로운 노드를 연결(할당)하면 된다.
self.head를 node변수에 할당하고 node.next가 None일때까지 while문을 반복하여 가장 안쪽 노드에 접근한다.
(가장 안쪽 노드는 다음 노드가 없으므로 next는 None값이다.)
# 2) 노드가 있는 경우
node = self.head
while node.next:
node = node.next
node.next = Node(value, None) 3. 삭제
C언어의 경우 메모리 할당 및 해체를 직접 코드에 적어줘야 하지만 JAVA나 Python은 관리에서 벗어난 데이터를 알아서 처리해주는 가비지 컬렉션(Garbage Collection)이 있기 때문에 관리 체계만 신경 쓰면 된다.
🤚 가비지 컬랙션(Garbage Collection)이란?
메모리 관리 기법 중 하나로, 프로그램이 동적으로 할당했던 메모리 영역을 해제하는 기능이다.
1995년 무렵 리스프의 문제를 해결하기 위해 존 매카시가 개발했다. -위키 참조
-
1) 저장된 노드가 없는 경우
저장된 노드가 없는 경우 삭제할 노드가 없기 때문에 예외 처리를 해준다.
# 1) 노드가 없는 경우
if not self.head:
return print("삭제할 노드가 없습니다.")- 2) 저장된 노드가 있는 경우

삽입(추가)의 경우와 같이 맨끝의 노드에 접근하여 value라는 변수를 만들어 node.value 값을 가져오고 node를 Node 값으로 재할당하면 메모리에 남아있는 포인터를 해체한 Node는 가비지 컬렉션이 알아서 처리한다.
# 2) 노드가 있는 경우
node = self.head
while node.next:
node = node.next
value = node.value
node = None
return value4. 조회
-
1) 인덱스 조회
Index라는 변수를 만들어 조회하려는 value 값과 node.valu 값을 비교하면서 같을 때까지 카운트하고 return 한다.def index(self, value): # 데이터가 없는 경우 if not self.head: return print("저장된 데이터가 없음") node = self.head Index = 0 while node: if node.value == value: return print(Index) node = node.next Index += 1 # 조회하는 value가 존재하지 않을 경우 return("해당하는 value가 없음") -
2) value(값) 조회
curIndex라는 변수를 만들어 인자로 받은 index와 비교하면서 같을때 해당 노드의 value값을 return 시킨다.def get(self, index): #데이터가 없는 경우 if not self.head: return print("데이터가 없음") if index == 0: return self.haed.value curIndex = 1 node = self.head while node: if curIndex == index: return node.value node = node.next curIndex += 1 # 조회 index가 node의 개수를 초과한경우 return print("해당하는 index의 값이 존재하지 않음")5. 전체 코드
class Node:
# 노드초기화
def __init__(self, value, next):
self.value = value
self.next = next
class SLinkedList:
# 헤드초기화
def __init__(self):
self.head = None
# 추가
def push(self, value):
# 1) 노드가 없는 경우
if not self.head:
self.head = Node(value, None)
return
# 2) 노드가 있는 경우
node = self.head
while node.next:
node = node.next
node.next = Node(value, None)
# 삭제
def pop(self):
# 1) 노드가 없는 경우
if not self.head:
return print("삭제할 노드가 없습니다.")
# 2) 노드가 있는 경우
node = self.head
while node:
if not node.next:
value = node.value
node = None
return value
node = node.next
# 인덱스 조회
def index(self, value):
# 데이터가 없는 경우
if not self.head:
return print("저장된 데이터가 없음")
node = self.head
Index = 0
while node:
if node.value == value:
return Index
node = node.next
Index += 1
# 조회하는 value가 존재하지 않을 경우
return("해당하는 value가 없음")
# 값 조회
def get(self, index):
#데이터가 없는 경우
if not self.head:
return print("저장된 데이터가 없음")
if index == 0:
return self.head.value
curIndex = 1
node = self.head.next
while node:
if curIndex == index:
return node.value
node = node.next
curIndex += 1
# 조회 index가 node의 개수를 초과한경우
return print("해당하는 index의 값이 존재하지 않음")-
이중 연결리스트
-
원형(환형) 연결리스트
참조)
파이썬 알고리즘 인터뷰
https://wikidocs.net/34224
https://www.youtube.com/watch?v=u65F4ECaKaY
