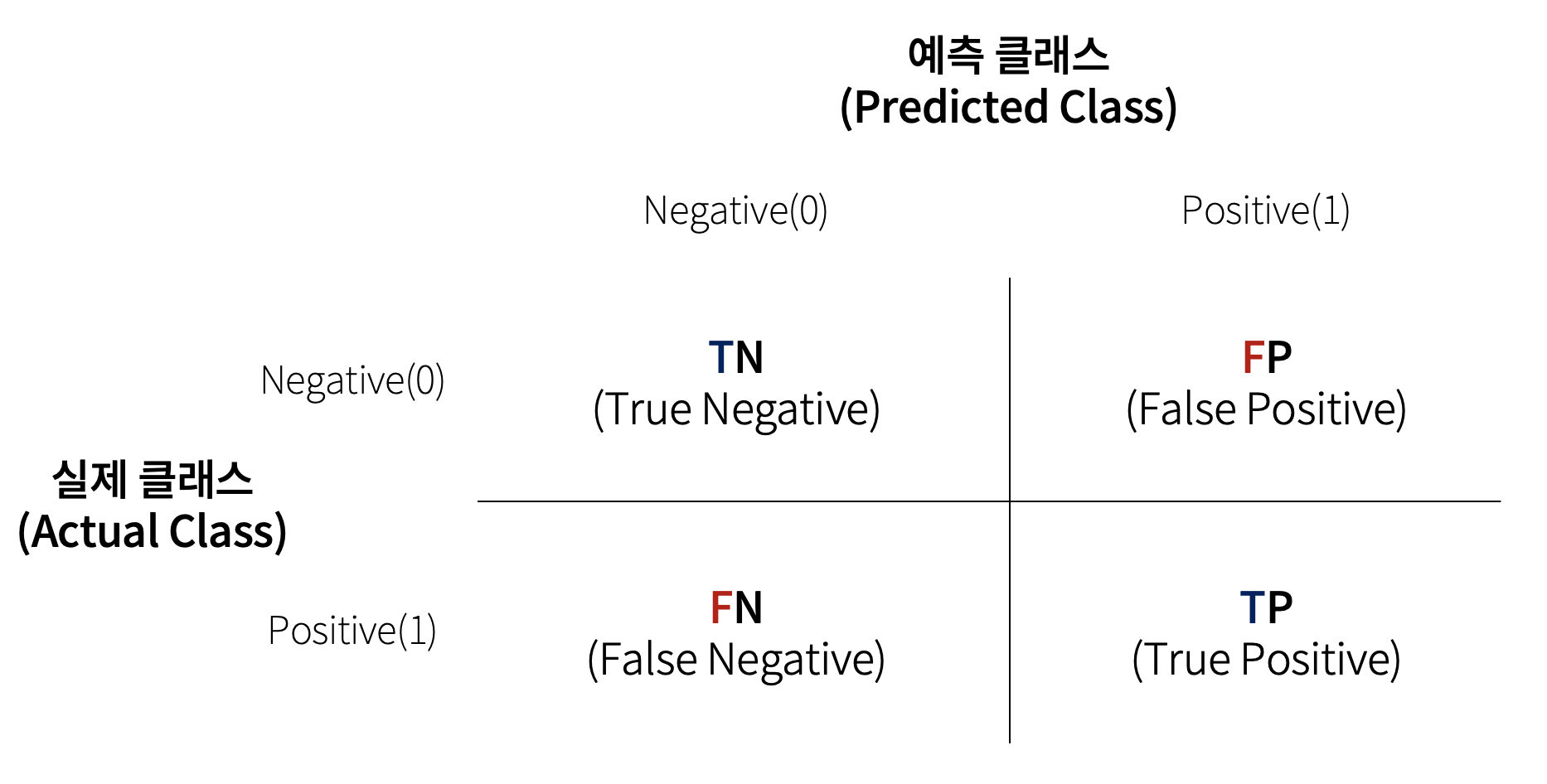
혼동 행렬
- 실제 값(정답)과 예측 한 것을 표로 만든 평가표
- 분류의 예측 결과가 몇개나 맞고 틀렸는지를 확인할 때 사용한다.
- 분류의 평가 지표로 사용된다.
sklearn.metrics모듈의confusion_matrix(정답, 모델예측값)함수 이용- 결과의 0번축: 실제 class, 1번 축: 예측 class
- 모델이 예측한 결과와 실제 정답간의 개수를 표로 제공
- 결과 ndarray 구조
-axis=0의 index: 정답(실제)의 class (행, row 가 정답)
-axis=1의 index: 예측결과의 class (열, column이 모델 추정값)
-value: 개수(각 class별 정답/예측한 개수)
오차 행렬이라고도 한다.
result = confusion_matrix(y_test, pred) # (정답, 모델 추정값)
result.shape, type(result)
# Output : ((3, 3), numpy.ndarray)
result
# Ouput : array([[10, 0, 0],
[ 0, 10, 0],
[ 0, 1, 9]], dtype=int64)
위의 코드는
iris데이터셋을DecisionTreeClassifier모델링한 추정값을y_test값과 함께confusion marix를 그린 예시입니다.
마지막 Output을 보면 :
대각의 값들은 모델 추정값과 정답이 일치하는 것들의 개수이고,
1 있는 것은idx2 인 값을 모델 추정값이 idx1로 잘못 추정하여 틀렸기 때문입니다.
따라서, 해당 학습-모델링의 결과와 동일하게 정확도가 0.966666667 이 나왔습니다.
이렇게 간단하게 혼동 행렬(Confusion Matrix)가 무엇인지 알아보았습니다.
🚀 axis에 대해...
파이썬에서 axis는 배열이나 행렬의 차원을 나타내는 개념입니다.
예를 들어, [1, 2, 3, 4, 5] 배열은 1차원 배열로 하나의 축을 가지고 있습니다. 축을 나타내는 방식은 일반적으로 0으로 표현됩니다. 따라서 이 배열의 축(axis)는 0입니다.
axis=0[ [1, 2, 3], [4, 5, 6] ]배열은 2차원 배열로 2개의 축을 가지고 있습니다.
첫 번째 축은 행(row) 을 나타내고, 두 번째 축은 열(column) 을 나타냅니다. 따라서 첫 번째 축은 0으로, 두 번째 축은 1로 표현됩니다.
axis=0: 행(row)
axis=1: 열(column)
간단하게 설명하자면, axis는 배열의 차원을 나타내며, 연산을 수행할 때 어떤 축을 기준으로 할지를 결정하는 역할을 합니다.
🚩 그러나, 이대로 이해하면 axis=0 은 행으로, axis=1은 열로 고정되어 이해할 수 있습니다.
이것은 틀린 내용이기때문에
마지막으로 3차원 배열을 예시로 axis 가 접근하는 방식을 이해하시면 될 것 같습니다.
[
[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]],
[[13, 14, 15], [16, 17, 18]]
]위와 같은 3차원 배열은 3개의 축을 가지고 있습니다.
첫 번째 축은 괄호 []를 따라 이동하며, 이는 배열의 깊이(depth) 를 나타냅니다. 두 번째 축은 대괄호 [[]]를 따라 이동하며, 이는 배열의 행(row) 을 나타냅니다. 세 번째 축은 대괄호 안의 숫자를 따라 이동하며, 이는 배열의 열(column) 을 나타냅니다.
따라서, 3차원 배열에서 축은 0부터 시작하여 1씩 증가하는 인덱스로 표현되기 때문에 첫 번째 축은 0으로, 두 번째 축은 1로, 세 번째 축은 2로 표현됩니다.
axis=0 : 깊이(depth)
axis=1 : 행(row)
axis=2 : 열(column)
👉 이렇게 2차원 배열에서 axis=0 이 행이었던 것이 3차원 배열에서는 깊이(depth)를 나타내고 있습니다. 이는 axis 의 값들이 고정으로 무언가를 대표하는 것이 아닌 차원에 따라 달라지고,
배열에서 사용된[](대괄호)의 흐름을 따라간다고 생각하시면 됩니다.
- 배열들을 감싸고 있는
[]을 제외한 제일 바깥쪽[]부터 axis가 이동하며, 마지막[]안의 요소들끼리 가리키는 것 까지axis의index가 증가한다고 생각하면 됩니다.
