Deep Learning - 이미지 처리 전이학습(Transfer Learning) 이용한 이미지 분류 모델 구현 실습

전이학습을 이용한 이미지 분류
전이학습(Transfer Learning)이란, 기존에 사전학습된(pre trained) 모델을 가져와, 사용하고자 하는 학습 데이터를 학습시켜 이용하는 방법으로, 기존에 비슷한 도메인의 데이터를 학습한 모델이라면 현재 갖고있는 데이터가 다소 적더라도 좋은 성능을 보여줄 수 있다.
ResNet50
이번 실습에선 ResNet50을 이용해 분류를 진행해보도록 한다.
진행하기에 앞서 ResNet50을 간략히 파악하자면 Residual Net이라고 하여 각각의 Conv-> BatchNormalization->ReLU 로 묶인 블럭 별로 Residual 값을 추가적으로 더해줌으로써 Gradient Vanishing/Exploding 문제를 해결할 수 있다.
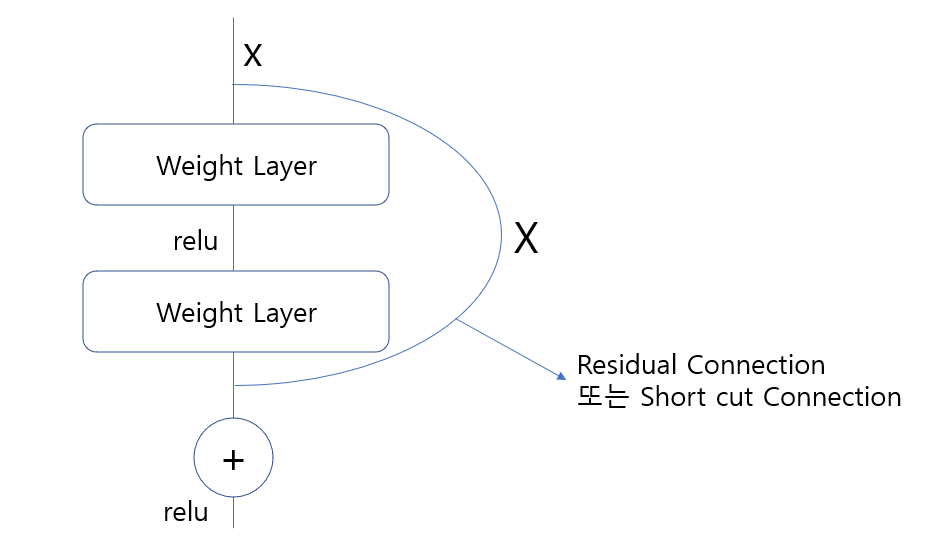
총 176개의 깊은 레이어로 구성되어 수많은 Conv 레이어를 통과함에도 이러한 Residuel 덕분에 학습이 잘 되는 것이다.
이러한 수많은 구조들로 학습을 해둔 'imagenet' 가중치를 사용해도 되며, 사용하지 않고 해당 구조만 사용할 수 있다.
ResNet50은 2015년에 나온 모델로, 이후에 v2, 152 등 여러가지 층을 늘린 버젼이나 개선된 버전이 많지만 가장 인용이 많이 된 50을 이용해 아래에서 사용하도록 해본다.
전이학습(Transfer Learning)의 활용
전이학습을 활용한다면 아래와 같이 활용해볼 수 있겠다.
-
모델(ResNet, MobileNet 등)을 불러와 그대로 분류할 데이터 입력 후 분류 진행(학습 x)
-
모델을 불러온 뒤, 최상위 층(분류기)만 용도대로 재 설정하여 학습시키는 방법. 이 때 불러온 전이학습 모델은 가중치를 동결해 학습시키지 않고, 분류기, 또는 이후 추가한 Fully-connected layer의 가중치만 학습하여 이용한다.
-
Fine Tuning - 2번과 동일하게 진행한 뒤, 동결해 두었던 전이학습 모델의 가중치를 (일부 또는 전부) 학습 가능상태로 만들고 학습시키도록 한다. (일부 또는 전체) 부분은 정해진 답이 없어 딱 잘라 말할 수 없다. 구현하면서 설명하도록 한다.
1. 전이학습(Transfer Learning)을 이용한 분류작업
데이터 불러오기
이번 포스팅에서는 전부 cifar10 데이터를 이용해 작업을 해보겠다. 이유는 같은 데이터를 통해 성능 평가를 해보기 위함이고, 라벨링이 되어있어 편한것도 있다.
cifar10데이터로 작업을 할 것이며, 구글링 또는 케라스 Doc 등에서 코드 구현을 위해 참고해보면 모두 img_load, image_data_from_directory 등 편리한 라이브러리를 사용하고 있어, 이를 사용하지 않는 방식으로 학습해본다.
from tensorflow.keras import datasets
# 케라스 데이터셋을 다운받아 변수에 각각 넣어준다.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
--------------------------------------- 여기부터 안해도됨
# 라벨 설정
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# 이미지 불러보기
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(test_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[test_labels[i][0]])
plt.show()

해당 데이터는 train 셋에 50000개, test 셋에 10000개의 샘플을 갖고있는 데이터이고, test 셋의 25개 이미지에 대해서만 출력해봤다. 이미지는 32 * 32 사이즈로 이뤄져있다.
모델 설계 (Functional API)
가장 먼저 미리 학습된(pre-trained) 모델을 가져와서 아무 변화주지 않고 데이터를 넣어 분류를 할 수 있는지 확인해보도록 한다.
from tensorflow.keras.applications.resnet50 import ResNet50
base_model = ResNet50(include_top=True, input_shape = (224, 224 ,3), weights = 'imagenet')우선 사전학습된 Resnet50 모델을 가져와봤다.
- include_top = True로 설정해 분류기를 그대로 가져온다. 기존 ResNet이 갖고 있던 1000개 class를 분류하는 분류기에서 이미지 데이터를 입력받아 분류한다.
- weights = 'imagenet'을 통해 imagenet에 사용된 사전학습시의 weights를 가져온다.
- input_shape은 이번 모델링이 최종 ResNet 모델만을 사용하는 것이기 때문에 ResNet의 Input 사이즈인 224x224와 3개 채널로 맞춰논다.
base_model.summary()로 모델의 끝이 어떻게 이뤄져있는지를 확인한다.
conv5_block3_add (Add) (None, 7, 7, 2048) 0 ['conv5_block2_out[0][0]',
'conv5_block3_3_bn[0][0]']
conv5_block3_out (Activation) (None, 7, 7, 2048) 0 ['conv5_block3_add[0][0]']
avg_pool (GlobalAveragePooling (None, 2048) 0 ['conv5_block3_out[0][0]']
2D)
predictions (Dense) (None, 1000) 2049000 ['avg_pool[0][0]']
==================================================================================================
Total params: 25,636,712
Trainable params: 25,583,592
Non-trainable params: 53,120
__________________________________________________________________________________________________176개의 레이어로 이뤄져있어 맨 뒷부분만 보면 최종 avg_pool layer 이후 predictions layer에서 1000개의 클래스로 분류하는 모델임을 확인할 수 있다.
모델 컴파일
base_model.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy',metrics = 'accuracy')
for i in range(5):
inputs = test_images[i] # Test_images의 i번째 이미지에 대한 평가
inputs = tf.expand_dims(inputs, axis=0) # ResNet이 원하는 이미지 차원은 (None, 224, 224, 3)이므로 차원 하나를 더 추가해준다.
x = tf.keras.layers.experimental.preprocessing.Resizing(224, 224)(inputs) # ResNet의 인풋사이즈에 맞춰준다. > 안맞춰도 돌아가지만 성능을 위해
x = tf.keras.applications.resnet50.preprocess_input(x) # 이전단계에서 안맞춰도 돌아가는 이유 > 바로 이 전처리 모듈이 있어서 알아서 맞춰주긴함
base_model.evaluate(x, test_labels[i]) # 모델의 성능을 파악해본다.
[output]
1/1 [==============================] - 0s 29ms/step - loss: 14.2147 - accuracy: 0.0000e+00
1/1 [==============================] - 0s 27ms/step - loss: 16.8900 - accuracy: 0.0000e+00
1/1 [==============================] - 0s 29ms/step - loss: 15.0634 - accuracy: 0.0000e+00
1/1 [==============================] - 0s 36ms/step - loss: 11.8624 - accuracy: 0.0000e+00
1/1 [==============================] - 0s 30ms/step - loss: 12.2392 - accuracy: 0.0000e+00모델의 분류기능, 예측기능을 사용하기 위해 컴파일을 우선 진행한다.
이후 테스트 셋의 5개 데이터만 확인을 성능검사를 해본 결과는 아주 형편없게 나왔다.
accuracy는 측정을 할 수 없게 나왔는데, 이미지가 원래 32x32임에도 억지로 ResNet input shape에 맞게 224x224로 키웠기 때문일 수 있다.
이미지 분류 모델이니 한번 이미지 분류를 어떻게 하는지 보도록 한다.
이미지 분류 실행해보기
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import decode_predictions
for i in range(5):
inputs = test_images[i]
inputs = tf.expand_dims(inputs, axis=0)
x = tf.keras.layers.experimental.preprocessing.Resizing(224, 224)(inputs)
x = tf.keras.applications.resnet50.preprocess_input(x)
preds = base_model.predict(x) # ResNet Model의 예측진행
# 예측 실행
fig= plt.figure(figsize=(3,3))
plt.title(decode_predictions(preds, top=1)[0][0][1])# 타이틀에 예측 명 1순위를 넣는다.
plt.imshow(test_images[i]) # 이미지는
plt.show();
나름대로 2번째 ship은 비슷하게 맞춘것 같은데, 나머지는 다 다르게 분류된것 같다. 그도 그럴것이 ResNet의 imagenet 가중치는 나의 이미지 데이터를 학습한 적이 없는데, 나도 알아보기 힘들정도로 작은 이미지를 억지로 키워서 넣은 것이 문제가 된 것도 같다.
2. 전이학습을 이용해 최종 분류기를 목적에 맞게 바꾸기
모델 설계(Functional API)
이번에 작성해볼 모델은 전이학습을 이용하되 분류기는 우리의 목적에 맞게 바꾸어 분류를 하는것이다.
전이학습은 수많은 이미지를 학습해 1000개의 클래스로 분류를 하는 모델이었다면, 이렇게 적당히 분류를 할줄 아는 녀석에게 우리의 분류 방법과 데이터를 주어 가르쳐준 뒤, 이용하는 방법이라고 볼 수 있다.
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, MaxPooling2D
from tensorflow.keras import datasets
from tensorflow.keras.applications.resnet50 import preprocess_input
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras import Input
from tensorflow.keras.layers import Dropout, BatchNormalization
# 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# ResNet50 불러오기 -> include_top = False로 바꾸는 것이 포인트
base_model = ResNet50(include_top=False, pooling = 'avg' , input_shape = (32,32 ,3), weights = 'imagenet')
base_model.trainable = False
# label(target) 데이터를 수치화 해준다. -> 안해줘도 loss 방법을 (sparse)로하면 되긴한다.
input_y = tf.keras.utils.to_categorical(train_labels, 10)
test_y = tf.keras.utils.to_categorical(test_labels, 10)
# 모델 layer 설계
inputs = Input(shape=(32,32,3))
x = tf.keras.layers.experimental.preprocessing.Resizing(32, 32)(inputs)
x = tf.keras.applications.resnet50.preprocess_input(inputs)
x = base_model(x, training = False)
x = Flatten()(x) # Fully Connected에 온전하게 학습을 위해 펼쳐준다
outputs = Dense(10, activation = 'softmax')(x) # Softmax 함수로 10개 분류하는 분류기
model_res = tf.keras.Model(inputs, outputs) # model_res 란 이름의 인풋과 아웃풋이 정해진 모델 생성위와 같이 모델을 설계 했다. 모델 설계는 정답이 없지만, 전이학습의 분류기 변경 관련 포인트가 있다.
-
ResNet50 불러오기에서 include_top=을 True가 아닌 False로 둠으로써 사전학습된 모델의 최상층 분류기를 사용하지 않겠다고 설정해야한다.
-
base_model.trainable = False를 통해 사전학습된 resnet이 기존에 기억하던 weights를 손상주지 않기 위해 동결시킨다.
아래 모델 layer 설계에 있는 training = False와는 다른 개념인데, 이와 관련해서는 다음 포스팅에 설명한다. False로 두고 진행한다. -
모델 layer 설계 부분에서 base_model 다음에 Flatten으로 펼쳐준 뒤, Dense layer로 최종 은닉층을 우리가 원하는 10개 클래스 분류기로 설정해주는 것.
ResNet50 모델(우리의 커스텀이 제외된)의 summary를 보면 다음과 같다.
conv5_block3_add (Add) (None, 1, 1, 2048) 0 ['conv5_block2_out[0][0]',
'conv5_block3_3_bn[0][0]']
conv5_block3_out (Activation) (None, 1, 1, 2048) 0 ['conv5_block3_add[0][0]']
avg_pool (GlobalAveragePooling (None, 2048) 0 ['conv5_block3_out[0][0]']
2D)
==================================================================================================
Total params: 23,587,712
Trainable params: 23,534,592
Non-trainable params: 53,120
__________________________________________________________________________________________________이전과 같이 ResNet 모델의 맨 마지막 부분만 뽑아보면, avg_pool layer까지만 있는 것을 볼 수 있다. avg_pool layer는 모델을 불러올 때 pooling='avg'를 해주어 가져올 수 있다.
다음으로는 우리가 커스텀한 model_res에 대해 summary()를 해본 결과다.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 32, 32, 3)] 0
tf.__operators__.getitem_1 (None, 32, 32, 3) 0
(SlicingOpLambda)
tf.nn.bias_add_1 (TFOpLambd (None, 32, 32, 3) 0
a)
resnet50 (Functional) (None, 2048) 23587712
flatten (Flatten) (None, 2048) 0
dense (Dense) (None, 10) 20490
=================================================================
Total params: 23,608,202
Trainable params: 23,555,082
Non-trainable params: 53,120
_________________________________________________________________resnet50층 아래로 flatten layer와 dense (None, 10) layer가 최종으로 들어간 것을 볼 수 있다. 우리가 원하는대로 10개를 분류할 수 있는 모델이 구성이 된 것이다.
이제 이녀석을 우리가 원하는 데이터와 라벨(타겟)으로 학습(fit)을 시켜주면 된다.
컴파일 및 학습진행
# 모델 컴파일 진행 - 아까와 달리 categorical_crossentropy 사용 > label이 숫자형 데이터이므로
model_res.compile(optimizer = tf.keras.optimizers.Adam(learning_rate= 0.001),
loss = 'categorical_crossentropy',
metrics=['accuracy'])
# early stopping 설정
early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
# 모델 fitting
model_res.fit(train_images, input_y, epochs = 10, validation_data=(test_images, test_y), batch_size= 256, callbacks=[early])Epoch 10/10
196/196 [==============================] - 6s 28ms/step - loss: 0.7872 - accuracy: 0.7271 - val_loss: 1.0913 - val_accuracy: 0.6475epochs = 10으로 설정해 진행해보니 val_accuracy 0.64까지 오른것을 볼 수 있다. 제법 올랐는데, 과연이게 최상의 성능일까? 다양한 파라미터 조정과 모델 위에 여러 층을 더 쌓으면 더 나아질 수도 있다.
3. 전이학습 미세조정(fine tuning)
2번과 같이 학습을 한 뒤 사용해도 괜찮지만, 미세조정을 통해 모델을 좀 더 발전시킬 수 있다.
미세 조정은 이러한 모델 상태에서 base_model(ResNet50)모델의 일부 레이어의 학습 동결을 해제하여 좀 더 모델이 학습에 녹아들 수 있도록 한다.
미세조정을 진행하기 위해 위와 똑같은 과정을 진행하되, fit 진행시 이를 변수에 넣어 기억하도록 한다.
save = model_res.fit(train_images, input_y, epochs = 10, validation_data=(test_images, test_y), batch_size= 256, callbacks=[early])Epoch 10/10
196/196 [==============================] - 6s 31ms/step - loss: 0.7967 - accuracy: 0.7222 - val_loss: 1.0960 - val_accuracy: 0.6476save라는 변수에 이를 넣고 10 epochs로 학습을 진행했다. val_accruacy가 0.64, val_loss는 1.0960이다.
미세조정을 위한 resnet 모델 일부 동결 해제
base_model.trainable = True # resnet 모델 학습동결을 해제한다
for i in base_model.layers[:143]: # 143층부터의 학습은 해제상태로 두고,
i.trainable = False # 이전까지의 학습은 동결한다.
for i in base_model.layers[140:]: # 동결이 제대로 해제됐는지 약간 이전층부터 출력해본다.
print(i.name, i.trainable)conv4_block6_3_bn False
conv4_block6_add False
conv4_block6_out False
conv5_block1_1_conv True
conv5_block1_1_bn True
...
conv5_block3_add True
conv5_block3_out True
avg_pool Truebase_model의 동결을 전체 해제한 뒤, 다시 최종 모델의 근처에 있는 블록의 학습은 해제로 두고 그 이전까지는 재 동결한다.
(중요) 미세조정의 동결을 푸는 방법 부분은 정답이 없다는 것을 알아둬야 한다.
많은 글들이 '맨 마지막 블록만 해제한다', '전체를 모두 해제한다' 등 일반화해서 이야기 하지만, 결론적으로는 어떤 모델에 어떤 데이터를 어떻게 사용하는가에 따라 이는 모두 달라지며 그때그때 조절해보며 최적의 방법을 이용하는것이 Best이다.
위 내용과 관련 실험한 Posting은 다음 글에서 다뤄보도록 할 것이다.
어찌됐든 conv5블록 내에도 3개의 블록이 있는데, 해당 3개의 블록에 대한 학습 동결을 해제한 뒤 위와 같이 base_model의 학습 가능여부 관련 print를 해본 것을 볼 수 있다.
이전블록에서 딱 142번 레이어(conv4_block6_out)까지만 False로 표기되고 이후는 모두 True인 것을 볼 수 있다.
동결 해제 후 재 컴파일진행
이것도 중요한 포인트인데, 동결 해제 후에 컴파일을 다시 하지않으면 base_model.trainable = True 등의 변화들이 적용이 되지 않는다.
컴파일을 반드시 해주어야 하며, 미세조정인 만큼 큰폭의 변화보단 조금이라도 성능을 높이고자 하는 것이기 때문에 learning rate(학습률)을 낮추어서 조금씩조금씩 학습이 튀지 않도록 조절해서 학습을 진행해본다.
model_res.compile(optimizer = tf.keras.optimizers.Adam( learning_rate= 0.0001),
loss = 'categorical_crossentropy',
metrics=['accuracy'])
early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
model_res.summary()odel: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 32, 32, 3)] 0
tf.__operators__.getitem (S (None, 32, 32, 3) 0
licingOpLambda)
tf.nn.bias_add (TFOpLambda) (None, 32, 32, 3) 0
resnet50 (Functional) (None, 2048) 23587712
flatten (Flatten) (None, 2048) 0
dense (Dense) (None, 10) 20490
=================================================================
Total params: 23,608,202
Trainable params: 14,996,490
Non-trainable params: 8,611,712
_________________________________________________________________컴파일 진행 후 모델에 적용됐는지 확인하기 위해 다시 model_res.summary()를 해보았다.
맨 아래쪽 Trainable params의 수치가 눈에 띄게 늘어난 것을 볼 수 있다.
기존에 20490개였던 학습 가능 파라미터 수가 resnet50의 마지막 conv5 블록의 파라미터의 학습 동결을 해제 해줌으로써 많은 수로 늘어난 것을 확인할 수 있다.
이를 아까 학습해 둔 save변수의 epoch에 이어서 진행해보도록 한다.
컴파일완료 후 미세조정모델 학습 진행하기
# 143부터 전체 열고 간다. 마지막 블록을 열고 진행
save_fine = model_res.fit(train_images, input_y, epochs = 50, initial_epoch = save.epoch[-1],validation_data=(test_images, test_y), batch_size= 256, callbacks = [early])Epoch 9/50
196/196 [==============================] - 12s 44ms/step - loss: 0.8043 - accuracy: 0.7166 - val_loss: 0.9110 - val_accuracy: 0.6957
Epoch 10/50
196/196 [==============================] - 8s 38ms/step - loss: 0.5131 - accuracy: 0.8239 - val_loss: 0.9075 - val_accuracy: 0.7038
Epoch 11/50
196/196 [==============================] - 8s 38ms/step - loss: 0.3167 - accuracy: 0.8962 - val_loss: 0.9283 - val_accuracy: 0.7105
Epoch 12/50
196/196 [==============================] - 8s 38ms/step - loss: 0.1727 - accuracy: 0.9531 - val_loss: 0.9826 - val_accuracy: 0.7125
Epoch 13/50
196/196 [==============================] - 8s 39ms/step - loss: 0.0804 - accuracy: 0.9855 - val_loss: 1.0778 - val_accuracy: 0.7116
Epoch 14/50
196/196 [==============================] - 8s 41ms/step - loss: 0.0354 - accuracy: 0.9968 - val_loss: 1.1135 - val_accuracy: 0.7207
Epoch 15/50
196/196 [==============================] - 8s 39ms/step - loss: 0.0132 - accuracy: 0.9996 - val_loss: 1.2001 - val_accuracy: 0.7247야심차게 epochs를 50까지 넣은것에 비해 몇번 못 돌린 것을 확인했다. 두번째 10/50 epoch에서 loss가 눈에띄게 떨어진 후 지속적으로 오르면서 과적합이 되었다. 미리 세이브포인트를 지정하면 원하는 loss의 가중치를 사용할 수 있다.
확실한 것은 val_loss가 1.08대에서 0.9대까지 떨어졌고, val_accuracy가 0.72까지 상승한 것은 상당히 고무적인 성능 개선이라고 볼 수 있다.
추가 성능 개선
전이학습을 하고 미세조정을 했는데도 아쉬운 부분이 있을 수는 있다. 개선할 수 있는 방법은 여러모로 많은데, 이번 실습에선 이전과 성능비교를 위해 추가적인 방법을 일부러 사용하지 않았다.
- 옵티마이저의 변경
- BatchNormalization 추가
- Dropout 추가
- resnet50 모델까지 전체 학습 -> 구조만 가져오고 전부 학습하는 것을 의미
- Data 전처리 및 증강을 통한 학습데이터 개선
- Fully Connected Layer 은닉층 추가 및 노드 추가
- learning decay를 이용해 유동적인 학습 진행
위 사항 외에도 개선할 방법은 무궁무진하지만, 무작정 복잡도만 높이지 않기 위해 Dropout이나 Decay를 이용할 수도 있다. 또한 데이터의 도메인과 모델의 도메인 유사성도 중요하며, 데이터의 수도 성능 개선의 요인이 될 수 있으니 추후 이를 참고하면 좋을 것이다.
전체 레이어를 모두 학습시키는 방법도 있다. weight='imagenet'의 가중치를 토대로 학습을 하기에 크게 발전될 수도 있으나, 시간이 오래걸릴 수 있으며 데이터의 종류에 따라 학습이 잘 안될 수 있으므로 데이터 수, 도메인에 따라 잘 결정하면 좋을 것이다.
4. 전이학습 모델의 구조만 가져와 학습하기
위 내용까지는 전이학습의 fine tuning으로 적은 데이터로 확실한 학습을 시키기에 좋은 내용이지만, 해당 모델의 176개의 레이어를 가진 구조를 이용하는 방법도 있다.
이 경우, 전체 파라미터를 모두 학습하는 것이기 때문에 모델을 불러올 때부터 weights를 None으로 설정한다.
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, MaxPooling2D
from tensorflow.keras import datasets
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
from tensorflow.keras.applications.resnet50 import ResNet50
base_model = ResNet50(include_top=False, pooling = 'avg' , input_shape = (32,32 ,3), weights = None)
base_model.trainable =True
input_y = tf.keras.utils.to_categorical(train_labels, 10)
test_y = tf.keras.utils.to_categorical(test_labels, 10)
from tensorflow.keras import Input
inputs = Input(shape=(32,32,3))
x = tf.keras.applications.resnet50.preprocess_input(inputs)
x = base_model(x, training=False)
x = Flatten()(x)
outputs = Dense(10, activation = 'softmax')(x)
model_res = tf.keras.Model(inputs, outputs빈 내용에 구조만 갖다 쓰는 것이기 때문에 resnet50 불러오는 과정에서 weights=None으로 설정하여 사전학습 가중치를 가져오지 않는다.
이후 base_model.trainable =True로 모든 resnet50 모델의 가중치를 열어놓아 학습하면 된다.
model_res.compile(optimizer = 'adam', loss= 'categorical_crossentropy', metrics=['accuracy'])
early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience= 5)
model_res.fit(train_images, input_y, epochs=30, batch_size=256, validation_data=(test_images, test_y), callbacks=[early])Epoch 1/30
196/196 [==============================] - 27s 93ms/step - loss: 2.3396 - accuracy: 0.3382 - val_loss: 1.5183 - val_accuracy: 0.4276
Epoch 2/30
196/196 [==============================] - 17s 86ms/step - loss: 1.3293 - accuracy: 0.5157 - val_loss: 1.2987 - val_accuracy: 0.5414
Epoch 3/30
196/196 [==============================] - 16s 84ms/step - loss: 1.1496 - accuracy: 0.5870 - val_loss: 1.1885 - val_accuracy: 0.5703
Epoch 4/30
196/196 [==============================] - 16s 84ms/step - loss: 1.0095 - accuracy: 0.6405 - val_loss: 1.0345 - val_accuracy: 0.6310
Epoch 5/30
196/196 [==============================] - 16s 84ms/step - loss: 0.8914 - accuracy: 0.6841 - val_loss: 0.9703 - val_accuracy: 0.6551
Epoch 6/30
196/196 [==============================] - 17s 86ms/step - loss: 0.7891 - accuracy: 0.7199 - val_loss: 0.9764 - val_accuracy: 0.6653
Epoch 7/30
196/196 [==============================] - 16s 84ms/step - loss: 0.7046 - accuracy: 0.7489 - val_loss: 0.9262 - val_accuracy: 0.6817
Epoch 8/30
196/196 [==============================] - 16s 84ms/step - loss: 0.6254 - accuracy: 0.7785 - val_loss: 0.9651 - val_accuracy: 0.6768
Epoch 9/30
196/196 [==============================] - 17s 86ms/step - loss: 0.5530 - accuracy: 0.8029 - val_loss: 0.9840 - val_accuracy: 0.6915
Epoch 10/30
196/196 [==============================] - 17s 85ms/step - loss: 0.4881 - accuracy: 0.8263 - val_loss: 1.0052 - val_accuracy: 0.6973
Epoch 11/30
196/196 [==============================] - 17s 86ms/step - loss: 0.4315 - accuracy: 0.8466 - val_loss: 0.9950 - val_accuracy: 0.7003
Epoch 12/30
196/196 [==============================] - 16s 84ms/step - loss: 0.3872 - accuracy: 0.8619 - val_loss: 1.0107 - val_accuracy: 0.7018나름대로 깊은 층의 구조를 갖고있으며, residual connection이 있기 때문에 학습이 잘되는 모습을 볼 수 있다. 여기서도 위에서 언급한것 또는 이외의 개선방법을 적용하면 성능이 더 좋아질 수 있다.
이상 사전학습된 모델의 전이학습 이용에 대한 실습을 마무리 하고,
전이학습을 공부하는 과정에서 헷갈렸던 여러가지 부분들에 대해 다음 포스팅에서 정리해본다.
