다익스트라 알고리즘
다익스트라 알고리즘은 가중치가 존재하는 그래프 내에서 시작점으로부터 어느 한 목표지점까지의 최단경로를 구하고자 할 때 사용할 수 있는 알고리즘이다.
다익스트라 알고리즘 로직의 구동 방식은 다음 방문할 정점을 고르는 매 순간의 선택에서 가장 가까운 곳을 선택하여(시작점으로부터 전체 가중치의 합을 계산했을 때 합이 가장 작은 곳을 먼저 선택) 방문하는 그리디한 방식으로 돌아간다.
최단거리를 나타내는 어떠한 경로가 있을 때, 해당 경로의 부분경로들도 결국 모두 최단거리로 구성되어 있다는 것을 생각하여 매 순간 그리디하게 최단거리만을 고르는 방식이다.
사실 다익스트라의 탐색 방식은 직관적인 면이 있어서 글로 받아들이기 전에 그 과정을 머릿속에서 한번 상상해보는 것이 더 쉽게 와닿는 것 같다.
그래프의 시작점에서부터 시간의 흐름대로 물길이 흘러가며 정점들을 탐색한다고 상상해보면 다익스트라의 과정을 쉽게 이해할 수 있다.
물길이 먼저 도착했다는 것은 해당 경로가 최단이라는 소리이므로 이후에 다른 경로로 들어오는 경로는 무시해도 된다.
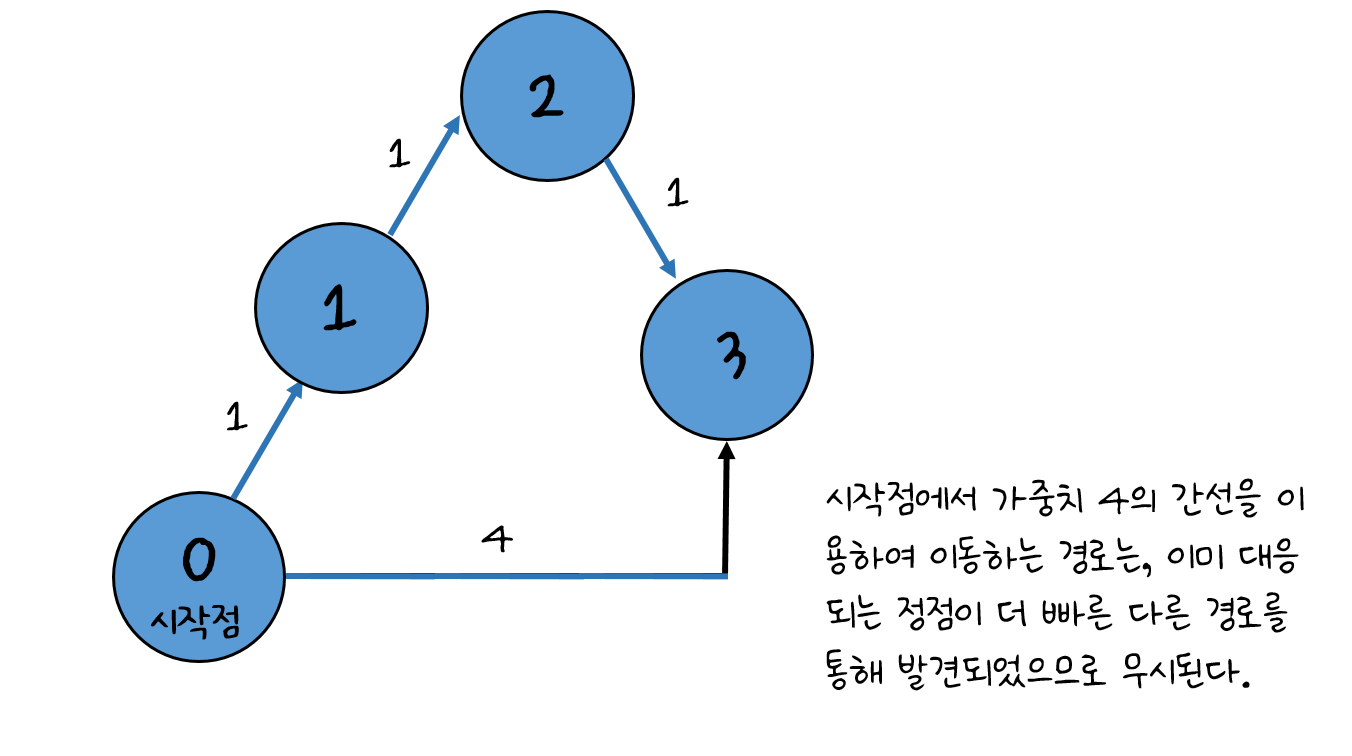
그림으로 한번 예를 들면,

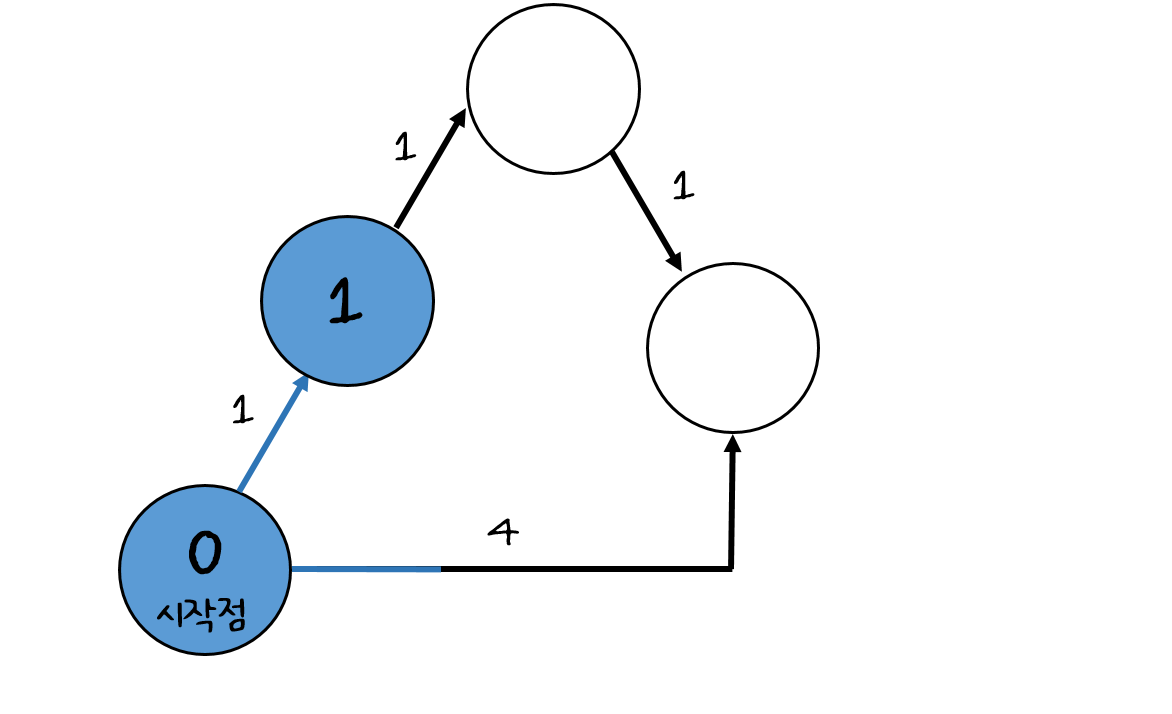


위 그림에서 그래프의 가중치가 물길이 이동하는데 걸리는 총 시간을 의미한다고 생각해 본다면, 어떤 정점에 물길이 최초로 도착하는 매 순간은 당연하게도 가장 시간이 짧게 소요되는(시작점으로부터 가장 가중치의 합이 적은) 경로를 타고 온 물길들로 구성된다는 것을 알 수 있다.
이런 식으로 다익스트라의 탐색 과정을 그림을 통해 상상해 본다면 직관적으로 쉽게 이해되지만 실제로 이 과정을 코드 위에서 동작하게 만들려면 물길이 여러 경로로 나눠져 동기적으로 움직이며 나아가는 그 과정을 구현한다는 게 마냥 쉽지만은 않을 것이다.
따라서 물길이 시작점으로부터 시간의 흐름대로 점차 이동해간다는 이 동기적이고 추상적인 과정을 실제 코드로 구현하기 위하여 다익스트라는 우선순위 큐라는 자료구조를 이용한다.
우선순위 큐에 다음 물길이 향할 경로를 저장해놓고(새로운 정점에 도착하는 매 순간마다 인접한 다음 정점을 목표로 하여 가중치의 합을 계산해 큐에 보관한다), 이후 큐에서 가장 가중치의 합이 낮은 경로를 채택해 해당 정점을 향해 다음 물길을 방문시키는 방식이다.
(이때 물길이 도착한 정점이 이미 다른 물길로 인하여 방문된 상태라면 해당 경로는 이미 최단경로보다 긴 경로이므로 그냥 무시하여 큐에서 버리면 된다.)
즉 굳이 동기적으로 물길의 흐름을 구현할 필요 없이 우선순위 큐를 이용하여 물길의 흐름을 관리하고 계산하며 탐색을 진행하는 것이다.
우선순위 큐
우선순위 큐는 보관하고 있는 자료들에 우선순위를 매겨 우선순위 순으로 자료들을 바로바로 꺼내 쓸 수 있도록 설계된 자료구조이다.
우선순위라는 것은 자료들이 갖는 순번같은 것으로, 어떤 자료의 우선순위가 가장 높다는 것은 해당 자료의 밸류가 가장 낮거나 혹은 가장 높다는 것을 의미한다.
사실 자료들의 정렬을 유지한 채로 데이터를 쌓아나가는 이진탐색트리를 이용해서도 우선순위 큐가 원하는 기능은 충분히 구현할 수 있을 것이다.
하지만 우선순위 큐를 이진탐색트리를 이용하여 구현해 버린다면, 우선순위가 가장 높은 값을 찾는 과정에서 O(log N)이라는 시간복잡도가 필요하게 된다. (N은 노드의 개수)
이진탐색트리의 경우 루트 노드에 어떠한 수가 오든 딱히 제약이 정해져 있지 않기 때문에 (물론 자료의 가장 중간값이 루트로 가는 것이 안정적인 형태이다), 우선순위가 가장 높은 수를 탐색하기 위해서는 결국 루트 노드에서부터 트리를 하나씩 타고 들어가야 하는 작업을 처리해야 하기 때문이다.
따라서 이러한 과정을 효율적으로 처리하기 위해서 우선순위 큐는 일반적으로 힙이라는 자료구조를 이용하여 구현하고 있다.
힙은 반드시 루트 노드에 가장 높은 우선순위를 갖는 수가 위치하고 있는 구조이기 때문에 단 O(1)의 시간복잡도면 곧바로 원하는 자료에 접근할 수 있다.
(힙은 다시 Max 힙과 Min 힙, 2가지 종류로 나눠지긴 하지만 이것은 우선순위를 오름차순으로 정할 것인지 내림차순으로 정할 것인지의 단순한 차이일 뿐이다.)
(C++의 Priority_Queue의 경우 Max 힙으로 구현되어 있다)
이 힙이라는 것이 가지고 있는 특성에 대해서 간단히 나열해보자면, 힙에서의 부모노드는 자식노드보다 반드시 더 높은 우선순위를 가져야 한다는 규칙이 존재한다.
(Max 힙이라면 부모노드가 자식노드 보다 반드시 커야할 것이고, Min 힙이라면 부모노드가 자식노드 보다 반드시 작아야 할 것이다.)
이 규칙은 앞에서 언급한 것과 같이 우선순위가 가장 높은 자료를 힙 트리의 루트에 위치 시키기 위해서 존재한다.
또한 힙은 트리의 형태가 엄격하게 제한되어 있는 완전이진트리 형태를 기본으로 한다.
(힙이 반드시 이진트리인 것은 아니지만 대부분의 경우 이진힙을 이용한다.)
즉 힙 트리의 노드들은 반드시 왼쪽부터 차례대로 채워져야 한다는 규칙성이 존재한다.
이같은 규칙은 힙의 트리에 존재하는 노드의 개수에 따라 트리의 모양이 항상 일정하게 정해져 있다는 것을 의미하기도 하는데, 이러한 힙의 엄격한 형태의 제한은 힙 트리의 노드들이 밑의 그림과 같은 특정한 인덱싱 규칙을 갖게 만든다.
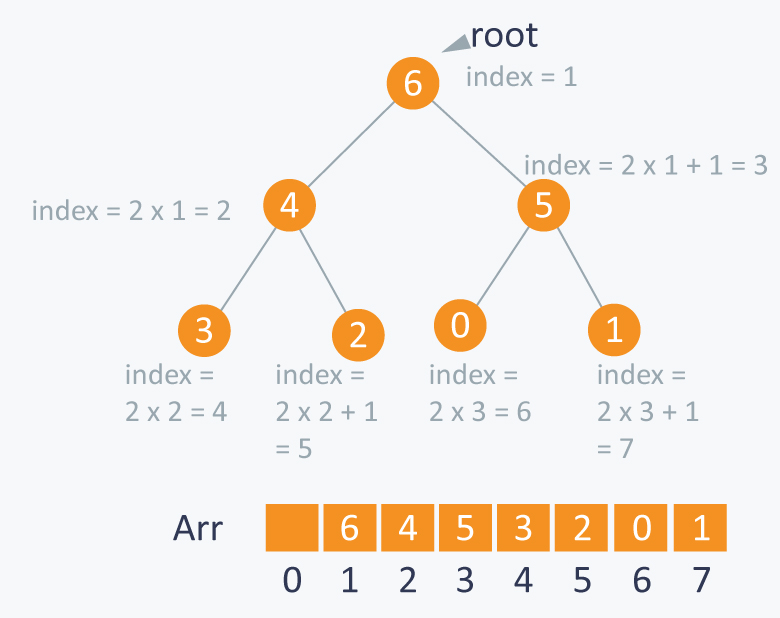
위 그림과 같이 루트노드의 인덱스를 1이라고 했을 때 각 노드들은 아래와 같은 인덱싱 규칙을 갖는다.
- Arr[i] 의 노드의 왼쪽 자손 인덱스는 Arr[2 * i] 이다.
- Arr[i] 의 노드의 오른쪽 자손 인덱스는 Arr[(2 * i) + 1] 이다.
- Arr[i] 의 부모 노드 인덱스는 Arr[i / 2] 이다. (나머지는 내림)
힙에 존재하는 모든 노드들이 각각 자식노드와 부모노드에 대해서 정해진 인덱스 패턴을 가지고 있다는 이 특성으로 인해 힙은 단순한 배열을 이용하더라도 굉장히 쉽게 구현할 수 있다.
하나의 배열에 힙의 노드들을 일렬로 저장하고 나중에 정해진 인덱스 규칙에 맞게 노드를 해석하여 사용하면 되기 때문이다.
그럼 마지막으로 힙에서 원소를 탐색하고 삽입 및 삭제하는 과정도 한번 간단하게 언급해보면, 먼저 힙에서 우선순위가 가장 높은 원소를 꺼내오는 것은 단순히 트리의 루트에 접근하기만 하면 되므로 O(1) 이다.
힙에 새로운 원소를 삽입하는 과정은, 반드시 특정한 순서대로 원소를 채워나가야 한다는 완전이진트리라는 형태의 제약으로 인해, 우선은 힙의 가장 마지막 자리에 새로운 원소를 넣고 다시 알맞게 자리를 재배치 하는식으로 진행되게 된다. (형태를 먼저 만들고 그 후 자리를 재배치한다)
새로운 원소를 넣은 자리에서부터 부모노드를 하나씩 거슬러 올라가면서 알맞은 자리를 찾을 때까지 계속 자리를 바꿔가는 식으로 진행하는 것이다.
이 과정의 시간복잡도는 결국 최대 트리의 높이만큼 비교 과정이 진행될 수 있으므로 O(log N) 이 된다. (N은 노드의 개수)
이어서 힙에서 원소를 삭제하는 과정인데, 힙에서 원소의 삭제란 루트노드가 사용되고 난 뒤 Pop되는 과정이라고 볼 수 있다.
해당 과정은 루트노드를 힙의 가장 마지막 자리의 노드와 자리를 바꾼 뒤 삭제하는 방식으로 진행하게 된다. (완전이진트리의 형태를 깨지 않고 노드를 삭제시키기 위해서, 삭제할 노드를 미리 힙의 가장 마지막 자리로 위치시킨다)
삭제할 루트노드를 가장 마지막 자리로 이동시킨 뒤 삭제를 진행하였다면, 이후는 새롭게 루트노드로 올라가버린 원소의 자리를 알맞게 재배치 시켜주면 된다.
삭제 시 일어나는 재배치 과정 또한 원소를 삽입하는 과정과 완벽하게 동일하다고 볼 수 있다.
단지 삽입 시에는 재배치 과정이 밑에서부터 위로 올라가는 방식이었기 때문에 비교 대상이 매번 부모노드 단 하나였다면, 삭제 시에는 역으로 위에서부터 아래로 내려가는 방식이기 때문에 매 비교대상이 2개의 자식노드로 늘어났다는 차이가 존재한다.
이 2개의 자식노드 중에 어떠한 자식과 자리를 바꿔야 하는지에 대한 고민은 사실 딱히 어려운 것이 아니다.
자식노드 2개 모두가 현재 자리를 찾고 있는 노드보다 우선순위가 낮다면, 노드를 해당 위치에 고정시키면 된다.
자식노드 2개 모두가 현재 자리를 찾고 있는 노드보다 우선순위가 더 높다면, 2개의 자식 중에 더 우선순위가 높은 자식과 자리를 바꾸면 된다.
만약 둘 중 하나의 자식만 우선순위가 높은 상황이라면 당연하게 그 자식과 자리를 바꾸면 된다.
삭제 시 일어나는 시간복잡도 또한 결국 삽입과 동일하게 최대 트리의 높이만큼 비교과정이 진행될 수 있기때문에 O(log N)이 된다.
출처:
https://www.hackerearth.com/practice/notes/heaps-and-priority-queues/
https://ko.wikipedia.org/wiki/%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84_%ED%81%90
