&arr과 arr의 차이
char arr [Z][Y][X] 라는 3차원 배열 arr이 존재한다고 할 때, &arr과 arr의 차이는 무엇일까?
컴파일러는 &arr과 arr이라는 코드를 어떻게 받아들이며 해당 코드를 어떤 값으로 처리하는 것 일까?
위와 같은 물음에 답하며 C에서 배열 자료형을 올바르게 다루기 위해서는 우선 다음과 같은 특성을 이해할 필요가 있다.
1. 배열은 단순히 포인터(주소)와 원소크기정보를 이용하여 다루어지는 자료구조이다
- -컴파일러는 배열의 포인터와 원소크기정보를 이용하여 배열 Data를 다룬다 (접근 및 수정, Data의 관리)
- -주소는 연산이 가능한 Data형이며 포인터 자료형을 이용하여 주로 다뤄진다
2. 배열의 이름(배열 변수의 이름)은 특수한 경우를 제외하면 해당 배열의 가장 첫 번째 원소의 주소를 나타낸다
배열과 포인터
배열(Array)이란 동일한 Type의 Data들을 하나로 묶어 관리할 수 있게끔 설계되어진 자료형이다. 사실 배열이라는 개념은 Data를 관리하기위해 추상적으로 설계된 자료구조일뿐이며, CPU단에서보자면 배열이란 존재가 명확하게 정의된 것이 아니고 물론 그러 할 필요도 없다. (이것은 배열 뿐만이 아니라 최하단 로우레벨의 Data를 제외한 모든 자료형 체계가 그러하겠지만)
즉 배열은 사람의 기준에서 Data를 쉽게 다룰 수 있도록 만들어진 선형 형태의 Data 저장기법(순차적 저장) 일뿐이며, 해당 Data 모음집을 컴파일러가 총괄적으로 접근-관리하여 코드가 사람이 의도한대로 작동되도록 컴파일시 CPU에게 올바른 위치에, 적절한 순서로, 정확한 값을 재가공하여 전해 주고 있을 뿐이다.
심지어 동적할당으로 생성된 일부 다차원 배열(2차원 이상의 배열)의 경우, 배열 원소들의 저장이 완벽한 순차성을 지니고 있지 않기도 한다. 이 대신, 순차성을 띠는 개별적인 배열들로 쪼개져 메모리의 이곳 저곳에 독립적으로 저장된다. 그리고 이렇게 독립적으로 떨어진 개별배열들을 참조하고 있는 포인터들을 모두 모아서 하나의 배열에 담아놓음으로써 논리적인 순차연결을 이루어놓는다. 뿐만 아니라 지역변수에 선언된 일차원 배열들조차도 컴파일시 순서가 뒤바껴 순차성이 유지되지 않기도 한다. 이러한 부분을 본다면 배열이라는 개념이 물리적으로 확정되어 있는 느낌이 아니라 상당히 논리적이고 추상적인 개념임을 느끼게 된다
컴파일러는 배열을 포인터와 배열 원소 크기 정보를 이용하여 다루고 있다. 배열의 특성자체가 배열에 포함되어있는 원소들을 순차적으로(선형적으로) 메모리에 저장하고 있다는 점에 있기때문에, 기점이 되는 원소의 주소(보통 첫번째 원소의 주소)와 데이터들이 얼마만큼의 간격으로 떨어져 있는지(원소크기정보)에 대한 정보만 있다면 하나의 배열을 어느정도 통제할 수 있다.

배열을 나타내고 관리하는데 있어서 거의 대부분의 것들이 포인터를 기반으로 이루어지고 있고, 포인터라는 자료형 자체가 데이터에 대한 순차적 접근을 가능케 하는 주소연산기능을 지니고 있다는 점에서 배열이라는 개념을 구현하는데 굉장히 최적화 되어있다. 따라서 배열을 이해하는데 있어서 포인터는 매우 중요하다.
배열변수의 이름
특수한 경우를 제외하면 코드상에서 배열의 이름은 해당 배열의 가장 첫번째 원소를 가르키는 포인터로 치환된다. 즉 배열 char arr[Z][Y][X]에서, 배열변수의 이름 arr은 컴파일러에게 &arr[0]과 완전히 동일하게 해석된다.
&arr[0] vs &arr
char arr [Z][Y][X]에서 배열변수 이름 arr이 &arr[0]과 완벽히 동일하게 해석된다면 최초의 물음은 결국 다음으로 바뀌어진다.
&arr[0] 과 &arr의 차이는 무엇일까?
직관적으로 생각해 단순히 대답한다면 &arr[0] 은 배열의 가장 첫번째 원소의 주소이고, &arr 은 배열의 주소라고 대답하게 될 것이다. 물론 printf("%x, &arr[0]) 와 printf("%x, &arr) 로 두 값의 주소를 출력시킨다면 출력되는 주소는 당연하게도 완전히 동일하다.
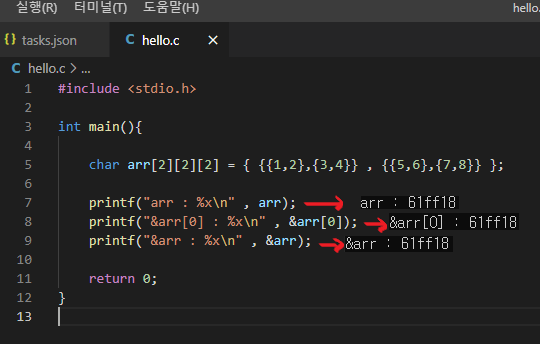
두 코드는 완벽히 동일한 주소를 출력한다. 그렇다면 결국 두 코드는 차이점이 없는 동일한 데이터라고 말할 수 있는 것일까? 대답은 당연히 아니다.
이렇게 단순히 주소의 개념만을 생각해 겉모습만을 가지고 판단을 한다면 두 코드의 차이점을 발견할 수 없다. 두 코드의 차이를 확실히 느끼기위해선 겉으로 드러나는 주소에 대한 정보 뿐만이아니라 해당 주소가 나타내고 있는 Data의 타입이 정확히 무엇인지를 파악하는 것이 중요하다.
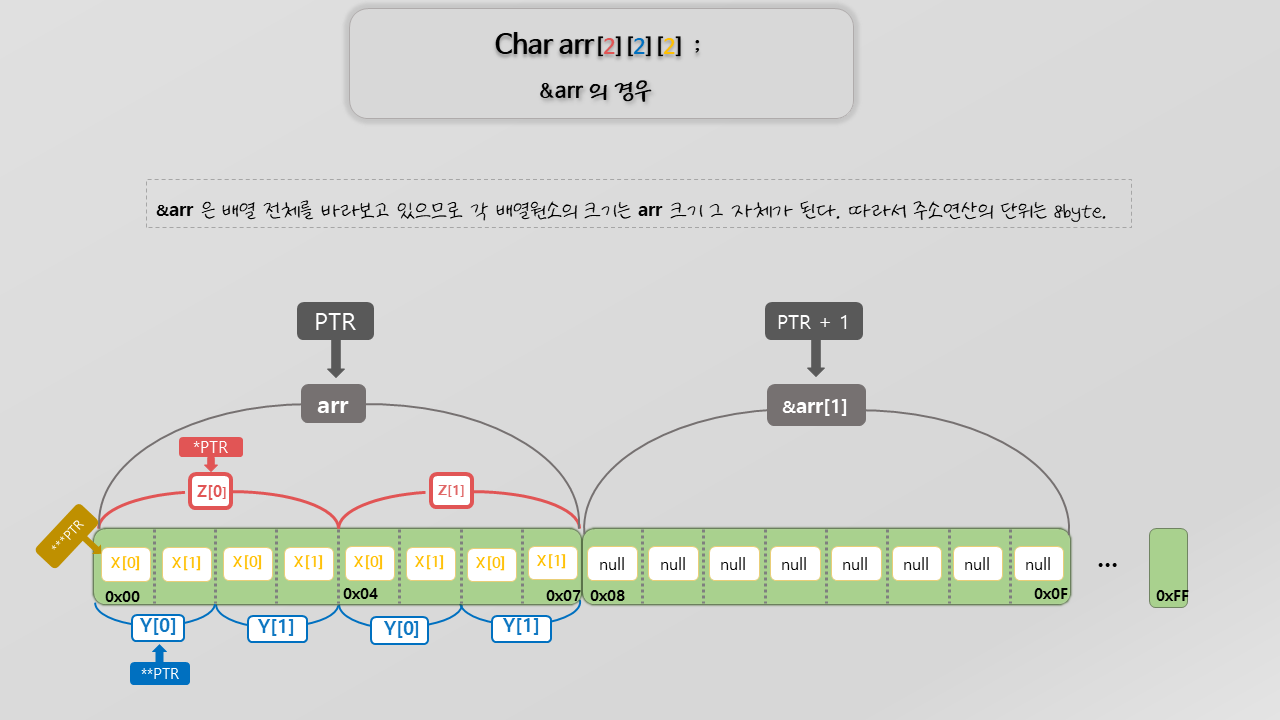
그렇다면 이번엔 Data 타입에 주목하여 두 코드를 바라봐보자. &arr[0] 과 &arr 은 서로 다른 Data 타입을 가르키고 있는 값의 주소들이다. 만약 포인터 변수를 선언하여 두 코드의 주소를 각각 할당할려고 한다면,
&arr[0] 은 char ∗ [Y][X] 포인터로 가르켜야하며,
&arr은 char ∗ [Z][Y][X]로 가르켜야한다.
두 코드가 가리키고 있는 Data의 주소 시작점은 같을지라도 실질적인 Data의 타입이 다르기 때문에 결국 선언해줘야하는 포인터의 자료형도 달라진다.
포인터 자료형이 서로 다르다는 말은 두 코드의 포인터가 서로 다른 주소연산의 단위를 가지고 있다는 것을 뜻하고, 이 말은 두 배열이 바라보고 있는 개별 원소의 크기가 서로 다르다는 말이며, 최종적으로 배열원소의 구분 단위가 다르다는 말로 귀결된다.
결론적으로 두 코드는 같은 시작주소위치를 가지고 있는 배열이지만 배열원소의 구분 단위가 다른 배열이다라는 말로 귀결되는 것이다.

코드 예시

