지금까지는 여러 소설 사이트에서 소설 제목, 작가 이름, 소개글, 장르를 가지고 왔다.
현재까지 내가 가지고온 소설 사이트들은
이렇게 4가지가 있다.
노벨피아는 기본적으로 f12를 막아놨기 때문에 따로 글을 작성하지 않았다.
카카오 또한 기존의 방식에서 다른 방식으로 크롤링하여 4만개의 데이터를 모두 모았다.
총 데이터는 159,596개다.

이제 이 데이터들을 가지고 본격적으로 장르 분류기를 만들어보려고 한다.
데이터 전처리
데이터 모으기
- csv 파일 가져오기
- 각 파일에서 제목과, 작가이름만 가져오기
- 제목에서 필요한 부분만 가져오기(특수문자 및 필요없는 단어 제거)
for t_list, g_list in zip(title_list, genre_list):
title = []
genre = []
for i, j in zip(t_list, g_list):
if type(i) == str:
i = re.sub(r"\s*\[.*?\]", "", i) # 대괄호 제거(안에 있는 문자까지)
i = re.sub(r'\([^)]*\)', '', i) # 소괄호 제거(안에 있는 문자까지)
i = re.sub(r"[^\uAC00-\uD7A30-9a-zA-Z\s]", "", i) # 특수문자 제거
title.append(i.strip()) # 양 끝에 엔터(\n) 제거
# 각 장르를 숫자로 변환하여 추가
if j == '로맨스':
genre.append([0])
elif j == '판타지':
genre.append([1])
elif j == '로판':
genre.append([2])
elif j == '현판':
genre.append([3])
elif j == '무협':
genre.append([4])
elif j == '패러디':
genre.append([5])
X_data.extend(title)
Y_data.extend(genre)데이터 확인
print(X_data[:10])
print(Y_data[:10])X_data
['너만 유일한 가이드가 아니었다', '육아를 던전에서 하게 될 줄이야', '태고신왕', '아빠가 힘을 숨김', '무림맹주 막내제자', '주인공의 먼치킨 동생이 되었다', '망겜 속 엑스트라가 됨', '피할 수 없으면 도망쳐라', '장야여화', '빙의물을 보다 빙의되어버린 소설에 빙의되어버렸다']
Y_data
[[2][1] [4][2] [4][1] [1][0] [1][2]]
토큰화 하기
이번 모델에는 keras의 preprocessing.text.Tokenizer를 사용해보려고 한다.
지금 하는 방식은 각 문장에서 단어별로 분류한 뒤, 그 단어에 숫자를 부여해 하나의 사전을 만든다.
그리고 나중에 예측 문장이 들어왔을 때, 똑같이 사전에 있는 단어에 해당하는 숫자를 출력한다.
tokenizer = keras.preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(X_data)
word_indexs = tokenizer.word_index
print(len(word_indexs)) # 66116word_indexs를 출력해보면 이런식으로 구성되어있다.
되었다 1
내 2
게임 3
나는 4
속 5
그 6이 방식의 단점은, 분석에 필요없는 부분까지 학습해야되기 때문에 오히려 학습에 방해가 될 수 있다. 하지만 여러방식으로 시도해 볼꺼기 때문에 그대로 진행하겠다.
sequences = tokenizer.texts_to_sequences(X_data) # 해당 단어를 가리키는 숫자를 단어 사전(tokenizer)에서 가져온다.
input_sequence = np.array(sequences) # numpy 배열 형식으로 변경각 변수를 출력해보면 이런식으로 나온다.
[[1413, 625, 4145, 1847], [23114, 987, 3818, 572, 23115], [33409], [584, 482, 245], [8100, 6076]]
[list([1413, 625, 4145, 1847]) list([23114, 987, 3818, 572, 23115]) list([33409]) list([584, 482, 245]) list([8100, 6076])]
사전의 벨류값이 해당 단어를 대체한다.
그리고 Y_data도 원 핫 인코딩(one-hot-encoding)을 하여 준비를 마친다.
Y_data = keras.utils.to_categorical(Y_data, num_classes=6)[[0. 0. 1. 0. 0. 0.][0. 1. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0.][0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 1. 0.]]
각 문장마다 길이가 다르기 때문에 문장의 길이를 통일시켜야 한다.
최대 길이로 문장을 padding 해준다.
# 가장 긴 문장의 길이 확인
max_length = max(len(sequence) for sequence in sequences)
# 패딩 적용
padded_sequences = pad_sequences(sequences, maxlen=max_length)데이터 분리하기
학습하고 결과 확인을 위해, train과 test로 분리한다.
x_train, x_test, y_train, y_test = train_test_split(padded_sequences, Y_data,test_size=0.2, random_state=0)모델 설계
간단하게 모델을 설계해 보았다.
batch_size = 100 # 데이터 묶음 크기
num_epochs = 1000 # 반복 수
vocab_size = len(tokenizer.word_index)+1 # 단어 사전의 크기
emb_size = 120 # 단어를 밀집 벡터로 변환할 때 백터의 차원 크기를 결정
hidden_dim = 256 # 은닉층의 개수
output_dim = 6 # 출력되는 백터의 크기(장르가 6개이므로 6)class genre_division_model(keras.Model):
def __init__(self, vocab_size, emb_size, hidden_dim, output_dim):
super(genre_division_model, self).__init__(name = 'subclassing')
self.embedding = keras.layers.Embedding(vocab_size, emb_size, name = 'embedding')
self.hidden = keras.layers.Dense(hidden_dim, 'relu', name='hidden')
self.outputs = keras.layers.Dense(output_dim, 'sigmoid', name = 'outputs')
def call(self, inputs):
x = self.embedding(inputs)
x = tf.reduce_mean(x, axis=1)
x = self.hidden(x)
x = self.outputs(x)
return x
division = genre_division_model(vocab_size, emb_size, hidden_dim, output_dim)
division.build(input_shape=(1, 17, ))
division.summary()그리고 시간을 아끼기 위해 callback으로 EarlyStopping도 추가했다.
earlystop_callback = EarlyStopping(
monitor='val_loss', # 모니터링할 지표
min_delta=0.0001, # 개선되는 것으로 판단하기 위한 최소 변화량
patience=3, # 개선이 없는 에포크를 얼마나 기다릴 것인가
verbose=1, # 로그를 출력
restore_best_weights=True # 가장 좋은 가중치를 복원
)division.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = division.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=num_epochs,
batch_size=batch_size,
callbacks=[earlystop_callback])결과 확인
학습을 완료했다.
이제 결과를 확인해 보자.
먼저 evaluate를 확인해 보았다.
print(f'{division.evaluate(x_test, y_test)[1]:.4f}')0.7707
77%의 확률로 문장이 주어졌을 때, 장르를 맞출 수 있다.
이번에는 그래프를 그려 보았다.
hist_df = pd.DataFrame(history.history)
y_vloss = hist_df['val_loss'] # 검증셋 오차
y_loss = hist_df ['loss'] # 학습셋 오차
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, c='red', label='Testest_loss')
plt.plot(x_len, y_loss, c='blue', label='Trainest_loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()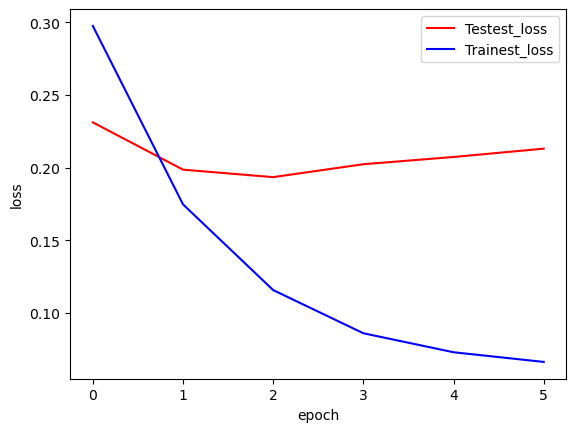
간단하게 만들어서 그런지 결과가 처참하다.
테스트
이제 모델을 만들었으니 테스트를 한 번 해보자.
내가 테스트 해볼 문장은 총 4개다.
- '소드마스터는 평화롭게 살고 싶다' # 판타지
- '천재 아이돌의 연예계 공략법' # 현판
- '가상 아이돌이 우리 집에 떨어졌다' # 로맨스
- '아기 악당님은 세계 정복을 꿈꾼다' # 로판
# 테스트
inputs = ['소드마스터는 평화롭게 살고 싶다', # 판타지
'천재 아이돌의 연예계 공략법', # 현판
'가상 아이돌이 우리 집에 떨어졌다', # 로맨스
'아기 악당님은 세계 정복을 꿈꾼다'] # 로판
# 토큰화 적용
sequences = tokenizer.texts_to_sequences(inputs)
input_sequence = np.array(sequences)
# 패딩 적용
padded_sequences = pad_sequences(sequences, maxlen=17)
# 예측
preds = model.predict(padded_sequences)
outs = []
for pred in preds:
outs.append(np.argmax(pred))
print(outs)
genre_list = ['로맨스', '판타지', '로판', '현판', '무협', '패러디']
for out in outs:
print(genre_list[out])예측 결과를 봤는데, 생각보다 잘 맞추는거 같다?
그래서 문장을 2배 더 늘려보았다.
'구룡전기', # 무협 -> 무협
'북해무신', # 무협 -> 판타지
'무관심의 역방향', # 로판 -> 로판
'흑표 가문의 설표 아기님', # 로판 -> 로판
'흑수저가 회귀하면 금수저가 된다', # 현판 -> 판타지
'나는 스파이 아이돌이다', # 현판 -> 판타지
'퇴사한 게임 개발자가 너무 유능함', # 현판 -> 판타지
'달 그늘 아래 부서진 각인', # 로맨스 -> 로맨스
'개같은 연애', # 로맨스 -> 로맨스
'두 개의 별이 뜨는 밤' # 로맨스 -> 로맨스판타지와 현판을 잘 구분하지 못하는거 같다.

크롤링 데이터 모으는 방법이 점점 발전하는 게 제가 직접 프로젝트 하는 기분이 드네요ㅎㅎ 이거 바탕으로 키워드 있는 데이터셋 가져다 처리하면 재밌을 거 같습니다. 너무 재밌게 잘 보고 갑니다!