현재까지 카카오페이지, 네이버 소설 목록을 크롤링 했다.
이제 문피아를 크롤링 할 차례다.
(사실 크롤링은 1주일 전 쯤 다 끝냈는데 이것 저것 한답시고 글 쓰는게 좀 늦어졌다.)
먼저 문피아 홈페이지를 살펴보자
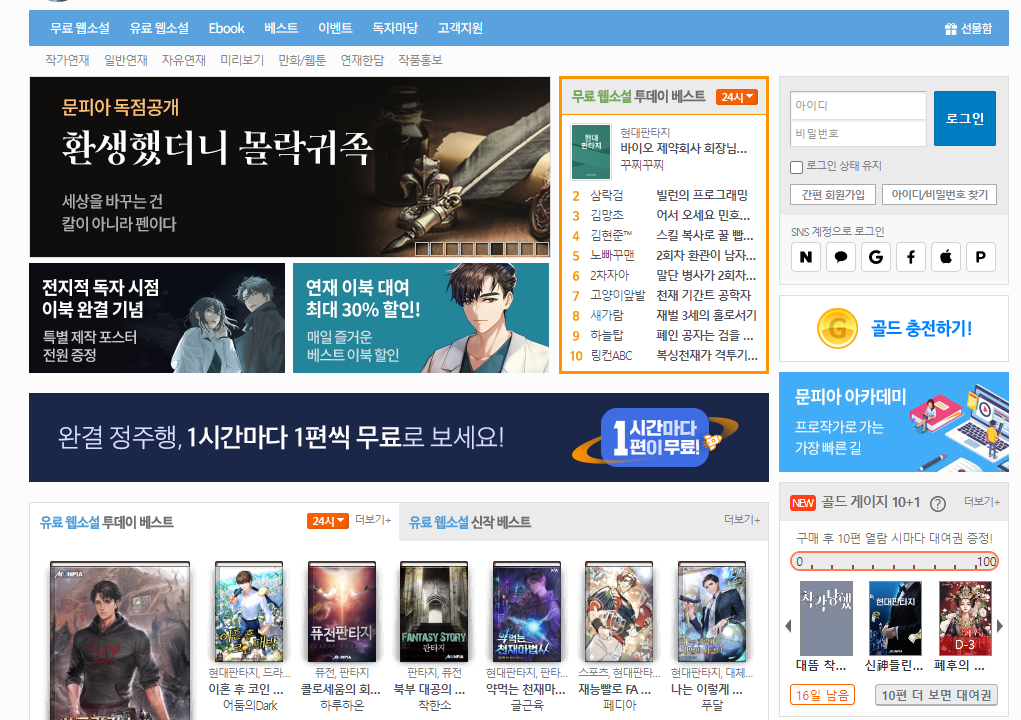
문피아는 다른 사이트 들과 다르게 전체 소설 목록 보는게 힘들게 되어있다.
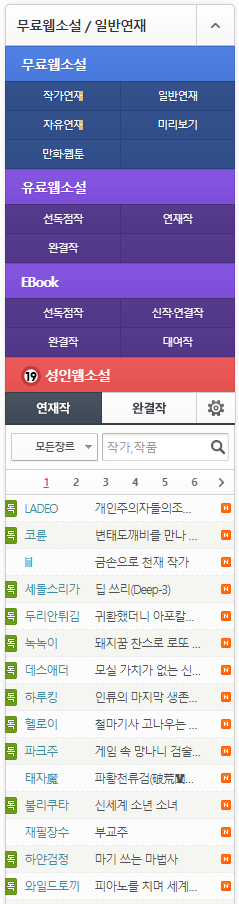
이런 식으로 왼쪽에 왼쪽에 페이지 목록, 소설 목록이 모여있다.
여기서도 마찬가지로 두 단계로 나눠서 했다.
- 페이지 별(작가 연재, 일반 연재, 무료 연재, 선 독점작, 연재작, 완결작) 이상 총 6개의 페이지에 들어간다.
- 각 페이지의 끝 페이지 번호를 알아낸다.
- BeautifulSoup을 통해 크롤링 한다.
그리고 이번에는 더욱 빠른 크롤링을 위해 Multiprocessing을 이용할 예정이다.
관련 내용은 BeautifulSoup 크롤링 속도 높이기에 있다.
페이지 별 끝 페이지 번호 알아내기
페이지로 들어가면
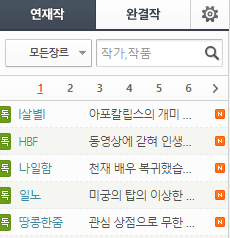
이런식으로 목록이 있는데 6쪽 오른쪽에 있는 꺽세를 눌러보면
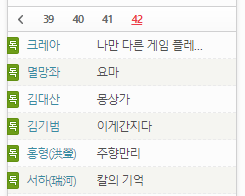
이렇게 맨 끝 페이지로 가는 것을 알 수 있다.
이것을 이용하여 크롤링할 페이지들의 끝 페이지를 알아낸다.
driver = webdriver.Chrome('./chromedriver')
# 페이지 로딩을 10초까지 기다림
driver.implicitly_wait(10)
# 가지고 올 페이지 리스트
novel_list = ['https://novel.munpia.com/page/hd.novel/group/nv.pro',
'https://novel.munpia.com/page/hd.novel/group/nv.regular',
'https://novel.munpia.com/page/hd.novel/group/nv.free',
'https://novel.munpia.com/page/hd.platinum/group/pl.serial/exclusive/true/view/allend',
'https://novel.munpia.com/page/hd.platinum/group/pl.serial/view/serial',
'https://novel.munpia.com/page/hd.platinum/group/pl.serial/finish/true/view/allend',
]
f = open('문피아 소설 페이지 리스트.txt', 'w')
novel_url_list = []
for url in novel_list:
# 페이지 접속
driver.get(url)
# 미완, 완
for n in ['','/finish/1']:
try:
# 끝쪽 버튼누르고 링크 가져오기
end_page = driver.find_element(By.CSS_SELECTOR, '#NOVELOUS-CONTENTS > section:nth-child(6) > ul > li.mi.col-next > a').get_attribute('href')
# 링크에서 끝에서 10번째 글자까지만 가져오고
end_page = end_page[-10:]
# 페이지만 뽑아냄
end_page = end_page[end_page.index('e')+2:]
# 끝쪽 버튼이 없으면(총 페이지 7쪽 미만)
except NoSuchElementException:
# 페이지 링크 다 가져옴
end_page = driver.find_elements(By.CSS_SELECTOR,'#NOVELOUS-CONTENTS > section:nth-child(6) > ul > li > a')
# 마지막 페이지 링크 가져오고
end_page = end_page[-1].get_attribute('href')
# 끝에서 10번째 글자까지만 뽑아냄
end_page = end_page[-10:]
# 페이지 번호만 뽑아냄
end_page = end_page[end_page.index('e')+2:]
# 1페이지부터 끝 페이지 까지
for i in range(1, int(end_page)+1):
print(url,n,i,'페이지')
# url 구성은 링크+완/미완+gpage+페이지 번호
# 미완(연재)인 경우 아무것도 없고, 완결인 경우 finish/1이 추가됨
driver.get(f'{url}{n}/gpage/{i}')
# 소설 목록 페이지 가져옴
novel_list = driver.find_elements(By.CLASS_NAME,'title.col-xs-6')
# 돌면서 링크만 가져오고 파일에 저장
for novel in novel_list:
href = novel.get_attribute('href')
novel_url_list.append(href)
print(href, file=f)
f.close()사실 이것도 BeautifulSoup으로 크롤링 할 수 있지만 정신 차리고 보니 셀레니움으로 크롤링을 하고 있었다. (어차피 점심도 먹고 올겸 얼마 안걸려서 그냥 냅뒀다.)
마치고 파일을 열어보니 잘 되어있었다.
소설 정보 크롤링
페이지 리스트를 가져왔으니 이제 소설 정보들을 가져올 차례다.
앞서 말했다시피, 이번 크롤링에는 Multiprocessing을 이용해볼 예정이다.
간단히 말하면, 하나의 작업을 여러개의 프로세서가 실행하는 것이다.
단순 계산으로 봐도, 기존 크롤링 속도보다 최소 2배 이상 빠른 것이다.
그리고, 여러개의 프로세서로 빠르게 크롤링을 하기 때문에 트레픽이 높아서 홈페이지에서 차단을 할 수도 있으니 fake-agent를 통해 크롤링 할 때마다 다른 Agent를 부여해 준다.
먼저 Multiprocessing부터 작업 해준다.
if __name__ == '__main__':
m = Manager()
# Multiprocessing에서 global로 사용할 리스트 변수
novel_df_list = m.list()
# 링크 목록 가져오기
f = open(f'문피아 소설 페이지 리스트.txt', 'r')
lines = f.readlines()
link_list = []
for line in lines:
link_list.append(line.strip())
f.close()
freeze_support()
# Multiprocessing 사용
pool = Pool(processes=5)
pool.starmap(crawl_link, zip(link_list,repeat(novel_df_list)))
pool.close()
print(novel_df_list)
pool.join()
munpia_novel_list = pd.concat(novel_df_list)
munpia_novel_list.to_csv('munpia_novel_data.csv', encoding='utf-8-sig')- 기존의 리스트를 저장한 파일에서 내용들을 가져온다.
- freeze_support()를 실행한다.
자세한 내용은 Windows 환경 python multiprocessing 시 freeze_support() - 사용할 프로세스 개수 부여(보통 4개)
- pool.starmap(함수 이름, 매개변수)
- 저장
그 다음 크롤링 하는 함수를 만든다.
def crawl_link(link, novel_df_list):
try:
ua = UserAgent()
headers = {'User-Agent': str(ua.random)}
rq = requests.get(link, headers=headers)
soup = BeautifulSoup(rq.content, 'html.parser')
try:
title = soup.select_one('#board > div.novel-info.dl-horizontal.zoom > div.dd.detail-box > h2 > a').text
try:
end = title[1:].index('\n')
title = title[end+2:]
except:
title = title
except:
title = None
try:
author = soup.select_one('#board > div.novel-info.dl-horizontal.zoom > div.dd.detail-box > dl.meta-author.meta > dd').text.replace('\n','')
except:
author = None
try:
intro = soup.select_one('#STORY-BOX > p.story').text.replace('\n','').replace('\r','')
except:
intro = None
tags = soup.select_one('#board > div.novel-info.dl-horizontal.zoom > div.dd.detail-box > p.meta-path > strong').text
tag_list = []
# 소설의 태그 목록
tag_list = tags.replace('#','').replace(',','').split()
rofan = [
['판타지', '로맨스'], ['현대', '로맨스'],
['현대판타지', '로맨스'], ['SF', '로맨스'],
['스포츠', '로맨스'], ['대체역사', '로맨스'],
['라이트노벨', '로맨스'], ['전쟁·밀리터리', '로맨스']]
# 로판
if any([i == tag_list for i in rofan]):
genre_a = '로판'
# 패러디
elif '패러디' in tag_list:
genre_a = '패러디'
# 판타지
elif '판타지' or '무협' or '현대' or '현대판타지' or 'SF' or '스포츠' or '대체역사' or '라이트노벨' or '전쟁·밀리터리' in tag_list:
genre_a = '판타지'
else:
genre_a = '기타'
# print(genre_a)
print(title, author, genre_a)
novel_data = {
'title': title,
'author': author,
'intro': intro,
'genre': genre_a
}
df = pd.DataFrame(novel_data, index=[0])
novel_df_list.append(df)
except:
passrequestsheader에 랜덤 Agent를 부여한다.- 링크를 넣고 제목, 작가이름, 장르와 소개글을 가져온다.
- 각 정보들이 없거나 잘못 되어있을 경우를 대비해
try: except:로 묶는다. - 태그에서 정보를 가져와 4가지 장르로 분류한다.
Manager()리스트에 저장한다.- 마지막까지 오고 끝났음에서 나머지 코어에서 돌아가는 경우가 있다.
try: except: pass로 끝내준다.
약 4만개 정도 크롤링 하는데 3시간 정도 걸렸다.
이전에 네이버 크롤링하는데에 비해 크롤링 시간이 확연히 줄어들었다.
이게 크롤링하고 다음에 볼 때 수정하고, 추가하고 다음꺼 하고 하다가 지금 글 쓰려니 기억이 안나는 부분이 조금씩 있다.
그리고 코드도 조금씩 수정하느라 틀린 부분이 있을 수 있다.
