장르 자동 분류기 만들기
소설 정보 크롤링
먼저 글쓰기에 앞서, 이 프로젝트는 순전히 개인 사용용도로 크롤링 하는 것을 알립니다. 상업용도 및 유출은 하지 않습니다. (여러분들도 조심하세요)
카카오 페이지
카카오페이지에 가면 이렇게 장르별로 분류가 되어있는데
원래 계획은 전체에서 한 번에 긁어와 분류를 하려고 했지만, 일정 이상 스크롤을 내리면 페이지가 다운되는 문제가 발생했습니다.
그래서 장르별로 크롤링해서 합치기로 했다.
(판타지만 해도 8천개에 가깝고, 로판은 18000개가 넘는다. ㄷㄷ 로판은 너무 많아서 스크롤을 끝까지 내릴수가 없어서 중간에 8천개 언저리에서 끊었다.)
순서는 이렇다.
1. 스크롤을 끝까지 내린다.
2. 해당 페이지를 가져온다.
3. 해당 페이지에서 소설 링크를 가져온다.
4. 파일로 저장한다.
5. 파일에서 링크를 가져와 페이지에 들어간다.
6. 소설 페이지에서 제목, 작가 이름, 작품 소개, 장르를 가져온다.
7. 데이터프레임으로 만든다.
일단 순서를 이렇게 한 이유는
1. 소설 이름, 작가이름, 장르를 가져오려면 해당 소설 페이지로 들어가야 한다.
2. 그래서 소설 링크를 가져와야 한다. 근대 그 링크를 한 번에 가져와야 한다.
3. 카카오페이지는 동적 페이지라 직접 페이지를 움직여야 페이지 내용이 늘어난다.
4. 그래서 페이지를 제일 밑까지 스크롤 다운을 해야한다.
5. 근대 저 상태에서 소설 페이지 하나하나 들어가서 정보 가져오고 하면 시간이 너무 오래걸린다.
6. 그래서 중간에 링크만 한 번 저장함으로서, 끊어가면서 하려고 함
먼저 페이지에 접속해준다.
카카오페이지는 동적이기 때문에 request로 하면 안되고 seleium을 써야 한다.
소설 페이지 링크 저장하기
크롬 드라이버 실행
# 셀레니움 관련 모듈
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.select import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import StaleElementReferenceException
# 크롬 열기
driver = webdriver.Chrome(ChromeDriverManager().install())
# 페이지 로딩을 10초까지 기다림
driver.implicitly_wait(10)참고로 셀레니움을 사용하기 위해 크롬 드라이버를 사용하는데, 저렇게 하면 굳이 프로그램을 설치해서 사용하지 않아도 자동으로 최신 프로그램으로 찾아서 열어준다.(설치 x)
소설 페이지 링크 저장
# 소설 링크들 가져와서 텍스트 파일로 저장
url_list = [
'https://page.kakao.com/menu/11/screen/37?subcategory_uid=86', # 판타지
'https://page.kakao.com/menu/11/screen/37?subcategory_uid=120', # 현판
'https://page.kakao.com/menu/11/screen/37?subcategory_uid=89', # 로맨스
'https://page.kakao.com/menu/11/screen/37?subcategory_uid=117', # 로판
'https://page.kakao.com/menu/11/screen/37?subcategory_uid=87', # 무협
]
# kakao_url = 'https://page.kakao.com/menu/11/screen/37?subcategory_uid=0'
f = open('해당 장르 이름.txt', 'w')
for url in url_list:
driver.get(url)
time.sleep(.5)파일은 나중에 링크를 모두 저장하고 f.close()로 닫아준다.
페이지를 끝까지 내려보자
페이지 끝까지 내리기
# 자동 스크롤 다운
def scroll_down():
#스크롤 내리기 이동 전 위치
scroll_location = driver.execute_script("return document.body.scrollHeight")
while True:
#현재 스크롤의 가장 아래로 내림
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
#전체 스크롤이 늘어날 때까지 대기
time.sleep(1)
#늘어난 스크롤 높이
croll_height = driver.execute_script("return document.body.scrollHeight")
#늘어난 스크롤 위치와 이동 전 위치 같으면(더 이상 스크롤이 늘어나지 않으면) 종료
if scroll_location == scroll_height:
break
#같지 않으면 스크롤 위치 값을 수정하여 같아질 때까지 반복
else:
#스크롤 위치값을 수정
scroll_location = driver.execute_script("return document.body.scrollHeight")그리고 해당 페이지를 가져와서 BeautifulSoup으로 만져준다.
페이지 정보 가져오기
scroll_down()
time.sleep(10)
source = driver.page_source
time.sleep(120)
soup = BeautifulSoup(source, 'html.parser')
# 소설 전체 목록
novel_list = soup.select('#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div > div.flex.grow.flex-col > div.flex.grow.flex-col > div > div.flex.grow.flex-col.py-10pxr.px-15pxr > div > div > div > div')
time.sleep(120)이것을 driver를 통해 바로 가져오지 않고 BeautifulSoup으로 한 번 거치는 이유는 현재 스크롤을 끝까지 내림으로서 한 페이지에 너무 많은 양의 내용이 들어가 있다.
언제 잘못될지 몰라 무서워서 일단 html형식으로 가지고 있어야 하는게 안전할것 같아서 페이지 정보를 가져오고 BeautifulSoup을 이용하기로 결정했다.
소설 페이지 링크 파일로 저장
cnt = 0
# 소설 페이지 링크 가져오기
for novel in novel_list:
href_url = novel.find('a')['href']
novel_href.append(href_url)
print(href_url, file=f)
cnt += 1
print(cnt)
f.close()이제 소설 하나 하나에서 해당 소설 페이지로 들어가는 링크를 가져온다.

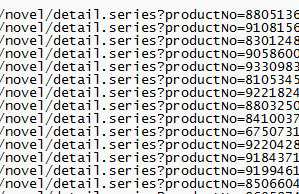
이런식으로 잘 가져와졌다.(로맨스는 너무 많아서 그런지 스크롤 내리다가 중간에 페이지가 터져서 40% 정도인 8천개 정도만 구했다.)
이제 소설 정보들을 가져와보자
소설 페이지에 들어가서 정보 가져오기
파일을 읽어 소설 페이지를 배열에 저장
# 카카오 페이지 들어가서 정보 가져오기
kakao = 'https://page.kakao.com'
kakao_url_list = []
novel_name = []
novel_genre = []
novel_author = []
novel_intro = []
# 리스트 파일 위치
f = open('D:\download\카카오 소설 페이지 리스트\로맨스.txt', 'r')
lines = f.readlines()
for line in lines:
line = line.strip()
kakao_url_list.append(kakao+line)
f.close()이렇게 배열에 소설 url들을 저장하고 하나씩 뽑아서 사용한다.
하나씩 뽑아서 소설 정보 가져오기
# 파일에서 링크 읽어서 정보 가져오기
for novel_href in kakao_url_list:
# 소설 하나 페이지 들어가기
driver.get(novel_href)
time.sleep(.5)
pass_novel = driver.find_element(By.CSS_SELECTOR,'#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div > div').text
# 소설 제목
novel_name.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.flex.w-320pxr.flex-col > div:nth-child(1) > div.w-320pxr.css-0 > div > div.css-0 > div.relative.text-center.mx-32pxr.py-24pxr > span').text)
# 소설 장르
novel_genre.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.flex.w-320pxr.flex-col > div:nth-child(1) > div.w-320pxr.css-0 > div > div.css-0 > div.relative.text-center.mx-32pxr.py-24pxr > div.all-child\:font-small2.mt-16pxr.flex.items-center.justify-center.text-el-60 > span:nth-child(9)').text)
# 소설 작가
novel_author.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.flex.w-320pxr.flex-col > div:nth-child(1) > div.w-320pxr.css-0 > div > div.css-0 > div.relative.text-center.mx-32pxr.py-24pxr > div.flex.items-center.justify-center.all-child\:font-small2.mt-4pxr.flex-col.text-el-50.opacity-100 > div.mt-4pxr').text)
# 작품 소개 버튼
driver.find_element(By.CSS_SELECTOR,'#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.ml-4px.flex.w-632pxr.flex-col > div.relative.flex.w-full.flex-col.my-0.bg-bg-a-20.px-15pxr.pt-28pxr.pb-12pxr > div > div > div:nth-child(2) > a > div > div > span').click()
# 작품 소개
novel_intro.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.ml-4px.flex.w-632pxr.flex-col > div.flex-1.bg-bg-a-20 > div.text-el-60.break-keep.py-20pxr.pt-31pxr.pb-32pxr > span').text.replace('\n', ' ').replace(' ',' '))
random_time_sleep = random.randint(2,10)
time.sleep(random_time_sleep)
novel_data = {
'title': novel_name,
'author': novel_author,
'intro': novel_intro,
'genre': novel_genre
}하지만 여기서 문제가 하나 발생한다.
바로 15세 이상 이용가 소설은 로그인을 해야한다는 점이다.
해당 페이지로 들어가면

이런 창이 뜨고 여기서는 소설 정보 태그들을 가져올 수 없기 때문에 NoSuchElementException에러가 발생한다.
여기서 해결 방법은 크게 3가지가 있다.
try: except:try: except NoSuchElementException:- 로그인 페이지가 나오면 넘기기
1번은 정보를 가져오는데 생긴 문제 전부 예외처리하는 방법이고,
2번은 NoSuchElementException에러가 뜨면 예외처리 하는 방법이고,
3번은 로그인 페이지가 나오면 확인하고 다른 소설 페이지로 넘가는 방법이다.
여기서 3번 방법을 추천하는데, 이유는
1, 2번 방법은 해당 코드에서 태그가 없다면(NoSuchElementException) 태그를 찾고, 에러를 출력하는데 시간이 약 10초정도 걸린다.
하지만 우리가 누구인가? 빨리빨리 민족이다.
이 10초도 참을 수 없다.
한 개는 10초지만 이게 8천개가 되면 8만초를 기다리게 되는 셈이다.
그렇기에 최적화를 위해 3번 방법을 사용했다.
최적화 하기
pass_novel = driver.find_element(By.CSS_SELECTOR,'#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div > div').text
if '로그인 후 이용해 주세요' in pass_novel:
pass
else:
# 소설 제목
novel_name.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.flex.w-320pxr.flex-col > div:nth-child(1) > div.w-320pxr.css-0 > div > div.css-0 > div.relative.text-center.mx-32pxr.py-24pxr > span').text)
# 소설 장르
novel_genre.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.flex.w-320pxr.flex-col > div:nth-child(1) > div.w-320pxr.css-0 > div > div.css-0 > div.relative.text-center.mx-32pxr.py-24pxr > div.all-child\:font-small2.mt-16pxr.flex.items-center.justify-center.text-el-60 > span:nth-child(9)').text)
# 소설 작가
novel_author.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.flex.w-320pxr.flex-col > div:nth-child(1) > div.w-320pxr.css-0 > div > div.css-0 > div.relative.text-center.mx-32pxr.py-24pxr > div.flex.items-center.justify-center.all-child\:font-small2.mt-4pxr.flex-col.text-el-50.opacity-100 > div.mt-4pxr').text)
# 작품 소개 버튼
driver.find_element(By.CSS_SELECTOR,'#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.ml-4px.flex.w-632pxr.flex-col > div.relative.flex.w-full.flex-col.my-0.bg-bg-a-20.px-15pxr.pt-28pxr.pb-12pxr > div > div > div:nth-child(2) > a > div > div > span').click()
# 작품 소개
novel_intro.append(driver.find_element(By.CSS_SELECTOR, '#__next > div > div.flex.w-full.grow.flex-col.px-122pxr > div.flex.h-full.flex-1 > div.mb-28pxr.ml-4px.flex.w-632pxr.flex-col > div.flex-1.bg-bg-a-20 > div.text-el-60.break-keep.py-20pxr.pt-31pxr.pb-32pxr > span').text.replace('\n', ' ').replace(' ',' '))
random_time_sleep = random.randint(2,10)
time.sleep(random_time_sleep)페이지의 div를 가져오고 그 div 텍스트에 '로그인 후 이용해 주세요'라는 문구가 있으면 다음 페이지로 넘어간다.
밑에 랜덤 시간으로 멈추는 이유는 너무 빨리 많은 크롤링을 하면 차단하는 경우가 있어서 시간 텀을 두고 크롤링을 했다.
데이터 프레임으로 저장하기
novel_data = {
'title': novel_name,
'author': novel_author,
'intro': novel_intro,
'genre': novel_genre
}
kakao_novel_list = pd.DataFrame(novel_data)
kakao_novel_list.to_csv('kakao_novel_list.csv', encoding='utf-8-sig')
kakao_novel_list
대충 20개만 가져와 봤는데, 그중 13개가 15세 이상이다... ㄷㄷ
