1. 패키지 설치
pip install selenium webdriver-manager2. 기본 데이터 모으기
2-1. 홈페이지 접속
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
# Service 객체를 명시적으로 설정
service = Service(ChromeDriverManager().install())
# Chrome WebDriver 실행
driver = webdriver.Chrome(service=service)
# 웹페이지 접속
driver.get('https://www.koreabaseball.com/Record/Player/HitterBasic/BasicOld.aspx')2-2. 연도, 팀 목록 가져오기
# KBO 홈페이지 연도
kbo_years = [i for i in range(1982, 2025)]
# KBO 팀들 딕셔너리
kbo_teams = {}
for kbo_year in kbo_years:
# 연도 드롭다운 선택
Select(driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlSeason_ddlSeason')).select_by_visible_text(kbo_year)
time.sleep(.5)
# 각 연도에서 팀들 추출해서 합치기
dropdown_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlTeam_ddlTeam')))
kbo_teams.update({option.text:option.get_attribute("value") for option in Select(dropdown_element).options[1:]})출력시
{'OB': 'OB',
'삼성': 'SS',
'MBC': 'LG',
'해태': 'HT',
'롯데': 'LT',
'삼미': 'HD',
'청보': 'HD',
'빙그레': 'HH',
'태평양': 'HD',
'LG': 'LG',
'쌍방울': 'SB',
'한화': 'HH',
'현대': 'HD',
'두산': 'OB',
'SK': 'SK',
'KIA': 'HT',
'우리': 'WO',
'넥센': 'WO',
'NC': 'NC',
'KT': 'KT',
'키움': 'WO',
'SSG': 'SK'}2-3. 테이블 가져오기
pandas의 read_html()를 이용해서 가져오려고 한다.
- 테이블을 가져온다.
- 테이블의 내용을 판다스로 변환한다.
- 배열에 추가한다.
- 배열에 있는 테이블을 하나로 합친다.
# 페이지에서 테이블 가져오기
table_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_udpContent > div.record_result > table')))
# 테이블의 HTML을 문자열로 변환 후, pandas로 읽기
table_html = table_element.get_attribute("outerHTML")
data_df.append(pd.read_html(table_html)[0]) # 첫 번째 테이블 가져오기그리고 나중에 2페이지까지 있는 경우가 있기 때문에 2페이지가 있으면 2페이지로 가서 같은 작업을 반복하도록 한다.
# 2페이지 찾기
second_page = driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ucPager_btnNo2')
if second_page:
second_page.click()
time.sleep(.5)
# 페이지에서 테이블 가져오기
table_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_udpContent > div.record_result > table')))
# 테이블의 HTML을 문자열로 변환 후, pandas로 읽기
table_html = table_element.get_attribute("outerHTML")
data_df.append(pd.read_html(table_html)[0]) # 첫 번째 테이블 가져오기이제 하나로 합친다.
pd.concat(data_df, ignore_index=False)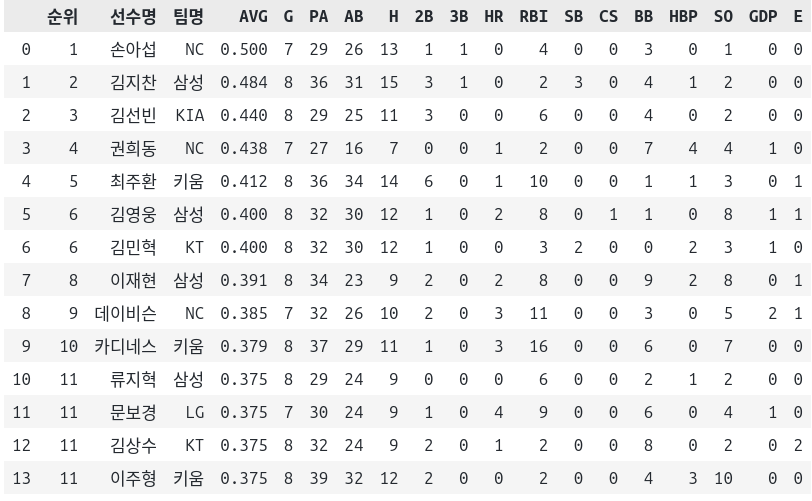
잘려서 나오지 않았지만 순위 59번인 2페이지가 정상적으로 추출되었다.
이제 이 작업을 연도 - 팀별로 진행해 주어야 한다.
하지만 그 전에 이 데이터를 그냥 csv로 저장하지 않고, mysql과 연동하여 진행하려고 한다.
3. MYSQL에 데이터 넣기
3-1. 데이터베이스만들기
CREATE DATABASE KBODATA;
SHOW DATABASES;
USE KBODATA;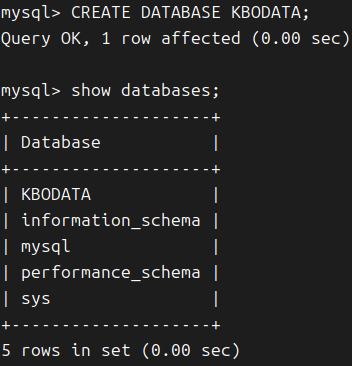
3-2. 파이썬과 mysql 연동하기
3-2-1. 패키지 설치하기
pip install pymysql3-2-2. 파이썬과 데이터베이스 연결하기
import pymysql
conn = pymysql.connect(host='127.0.0.1′, user=’계정이름’, password=’비밀번호′, db=’soloDB’, charset=‘utf8’)3-2-2-1. ERROR
RuntimeError: 'cryptography' package is required for sha256_password or caching_sha2_password auth methods
이런 오류가 뜬다면pip install cryptography이것을 이용해서 해결한다.
OperationalError: (1044, "Access denied for user 'apic'@'localhost' to database 'KBODATA'")
이런 오류가 뜬다면 권한이 잘못 되어있다는 뜻이다.-- '사용자에게 KBODATA 데이터베이스에 대한 모든 권한 부여 GRANT ALL PRIVILEGES ON 데이터베이스.* TO '사용자명'@'localhost'; -- 변경 사항 적용 FLUSH PRIVILEGES;이렇게 해서 해결한다.
3-2-3. 테이블 만들기
이후 cur = conn.cursor()를 통해 통로를 만들어주고 cur.execute()를 이용해서 명령어를 사용한다.
그 다음 테이블을 만들어 준다.
# 테이블 만들기
cur.execute("""
CREATE TABLE KBO_TABLE(
id INT AUTO_INCREMENT PRIMARY KEY, -- 고유 ID
year INT, -- 연도
player_name VARCHAR(50), -- 선수명
team_name VARCHAR(50), -- 팀명
AVG FLOAT, -- 타율 (AVG)
G INT, -- 경기 수 (G)
PA INT, -- 타석 (PA)
AB INT, -- 타수 (AB)
H INT, -- 안타 (H)
`2B` INT, -- 2루타 (2B)
`3B` INT, -- 3루타 (3B)
HR INT, -- 홈런 (HR)
RBI INT, -- 타점 (RBI)
SB INT, -- 도루 (SB)
CS INT, -- 도루 실패 (CS)
BB INT, -- 볼넷 (BB)
HBP INT, -- 몸에 맞는 공 (HBP)
SO INT, -- 삼진 (SO)
GDP INT, -- 병살타 (GDP)
E INT, -- 실책 (E)
TB INT, -- 총루타 (TB)
SAC INT, -- 희생타 (SAC)
SF INT, -- 희생플라이 (SF)
IBB INT, -- 고의사구 (IBB)
SLG FLOAT, -- 장타율 (SLG)
OBP FLOAT, -- 출루율 (OBP)
OPS FLOAT, -- OPS (출루율 + 장타율)
MH INT, -- 멀티히트 (MH)
RISP FLOAT, -- 득점권 타율 (RISP)
PH_BA FLOAT, -- 대타 타율 (PH-BA)
XBH INT, -- 장타 (XBH)
GO INT, -- 땅볼 (GO)
AO INT, -- 뜬공 (AO)
GO_AO FLOAT, -- 땅볼/뜬공 비율 (GO/AO)
GW_RBI INT, -- 결승타점 (GW RBI)
BB_K FLOAT, -- 볼넷/삼진 비율 (BB/K)
P_PA FLOAT, -- 타석당 투구 수 (P/PA)
ISOP FLOAT, -- 순수 장타율 (ISO Power)
XR FLOAT, -- 예상 득점 생산력 (XR)
GPA FLOAT -- 타격 생산력 지수 (GPA)
);
""")이제 mysql에 가서 show KBO_TABLE;를 해보면 테이블이 생성 된 것을 볼 수 있고
DESC KBO_TABLE;를 통해 생성된 테이블의 구조를 확인할 수 있다.
-------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| player_name | varchar(50) | YES | | NULL | |
| team_name | varchar(50) | YES | | NULL | |
| AVG | float | YES | | NULL | |
| G | int | YES | | NULL | |
| PA | int | YES | | NULL | |
| AB | int | YES | | NULL | |
| H | int | YES | | NULL | |
| 2B | int | YES | | NULL | |
| 3B | int | YES | | NULL | |
| HR | int | YES | | NULL | |
| RBI | int | YES | | NULL | |
| SB | int | YES | | NULL | |
| CS | int | YES | | NULL | |
| BB | int | YES | | NULL | |
| HBP | int | YES | | NULL | |
| SO | int | YES | | NULL | |
| GDP | int | YES | | NULL | |
| E | int | YES | | NULL | |
| TB | int | YES | | NULL | |
| SAC | int | YES | | NULL | |
| SF | int | YES | | NULL | |
| IBB | int | YES | | NULL | |
| SLG | float | YES | | NULL | |
| OBP | float | YES | | NULL | |
| OPS | float | YES | | NULL | |
| MH | int | YES | | NULL | |
| RISP | float | YES | | NULL | |
| PH-BA | float | YES | | NULL | |
| XBH | int | YES | | NULL | |
| GO | int | YES | | NULL | |
| AO | int | YES | | NULL | |
| GO/AO | float | YES | | NULL | |
| GW RBI | int | YES | | NULL | |
| BB/K | float | YES | | NULL | |
| P/PA | float | YES | | NULL | |
| ISOP | float | YES | | NULL | |
| XR | float | YES | | NULL | |
| GPA | float | YES | | NULL | |
+-------------+-------------+------+-----+---------+----------------+이렇게 정상적으로 입력된 것을 확인할 수 있다.
3-3. 모든 연도별 팀 데이터 추출하기
이제 연도를 선택하고, 그 연도에 존재했던 팀을 선택하고 테이블을 가져오면 된다.
kbo_year = '1982'
Select(driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlSeason_ddlSeason')).select_by_visible_text(kbo_year)
time.sleep(.5)
# 팀 드롭다운 선택
dropdown_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlTeam_ddlTeam')))
kbo_teams = [option.get_attribute("value") for option in Select(dropdown_element).options[1:]]
# 팀 선택하기
Select(dropdown_element).select_by_value(kbo_teams[0])하지만 막상 작성하고 보니까 위에서 굳이 팀명 딕셔너리를 만들 필요가 없었다.
이제 대충 하나로 합쳐주면 된다.
for kbo_year in kbo_years:
# 연도 드롭다운 선택
Select(driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlSeason_ddlSeason')).select_by_visible_text(kbo_year)
time.sleep(.5)
# 팀 드롭다운 선택
dropdown_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlTeam_ddlTeam')))
kbo_teams = [option.get_attribute("value") for option in Select(dropdown_element).options[1:]]
for kbo_team in kbo_teams:
# 팀 선택하기
Select(dropdown_element).select_by_value(kbo_team)
#페이지에서 테이블 가져오기
table_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_udpContent > div.record_result > table')))
# 테이블의 HTML을 문자열로 변환 후, pandas로 읽기
table_html = table_element.get_attribute("outerHTML")
data_df.append(pd.read_html(table_html)[0]) # 첫 번째 테이블 가져오기
# 2페이지 찾기
second_page = driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ucPager_btnNo2')
if second_page:
second_page.click()
time.sleep(.5)
# 페이지에서 테이블 가져오기
table_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_udpContent > div.record_result > table')))
# 테이블의 HTML을 문자열로 변환 후, pandas로 읽기
table_html = table_element.get_attribute("outerHTML")
data_df.append(pd.read_html(table_html)[0]) # 첫 번째 테이블 가져오기시도해보니 2페이지가 없을 때 그냥 넘어가는게 아니라 NoSuchElementException 오류가 발생했다.
try-except로 해결한다.
try:
# 2페이지 찾기
second_page = driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ucPager_btnNo2')
second_page.click()
time.sleep(.5)
# 페이지에서 테이블 가져오기
table_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_udpContent > div.record_result > table')))
# 테이블의 HTML을 문자열로 변환 후, pandas로 읽기
table_html = table_element.get_attribute("outerHTML")
data_df.append(pd.read_html(table_html)[0]) # 첫 번째 테이블 가져오기
except NoSuchElementException:
pass3-4. MYSQL에 데이터 넣기
위에 있는 코드는 mysql에 넣지 않고 가지고만 있다.
저 코드를 조금 수정해서 바로 mysql에 넣도록 한다.
wait, driver = start_driver()
driver.get('https://www.koreabaseball.com/Record/Player/HitterBasic/BasicOld.aspx')
# KBO 홈페이지 연도
kbo_years = [str(i) for i in range(2020, 2022)]
# 데이터베이스 연결하기
conn = pymysql.connect(host='127.0.0.1', user='apic', password='', db='KBODATA', charset='utf8')
# 통로 만들기
cur = conn.cursor()
for kbo_year in kbo_years:
# 연도 드롭다운 선택
dropdown = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlSeason_ddlSeason'))
)
Select(dropdown).select_by_visible_text(kbo_year)
time.sleep(.5)
# 팀 드롭다운 선택
dropdown_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlTeam_ddlTeam')))
kbo_teams = [option.get_attribute("value") for option in Select(dropdown_element).options[1:]]
for kbo_team in kbo_teams:
time.sleep(.5)
# 팀 선택하기
dropdown_element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ddlTeam_ddlTeam')))
Select(dropdown_element).select_by_value(kbo_team)
time.sleep(.5)
# 페이지에서 테이블 가져오기
table_element = wait.until(EC.presence_of_element_located((By.TAG_NAME, 'table')))
# 테이블의 HTML을 문자열로 변환 후, pandas로 읽기
table_html = table_element.get_attribute("outerHTML")
df = pd.read_html(StringIO(table_html))[0]
df['year'] = kbo_year
# mysql에 있는 컬럼명으로 바꾸기
df.rename(columns={"선수명": "player_name"}, inplace=True)
df.rename(columns={"팀명": "team_name"}, inplace=True)
# - 문자 0으로 바꾸기
df.replace('-', '0', inplace=True)
for _, data in df.iterrows():
columns = ", ".join(df.columns[1:]) # 컬럼 리스트를 문자열로 변환
values_placeholder = ", ".join(["%s"] * len(data.iloc[1:])) # 플레이스홀더 생성
sql = f"INSERT INTO KBO_TABLE ({columns}) VALUES ({values_placeholder})"
cur.execute(sql, tuple(data.iloc[1:])) # 데이터를 튜플로 변환하여 실행
try:
# 2페이지 찾기
second_page = driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ucPager_btnNo2')
if not second_page:
continue
second_page.click()
time.sleep(.5)
time.sleep(.5)
# 페이지에서 테이블 가져오기
table_element = wait.until(EC.presence_of_element_located((By.TAG_NAME, 'table')))
# 테이블의 HTML을 문자열로 변환 후, pandas로 읽기
table_html = table_element.get_attribute("outerHTML")
df = pd.read_html(StringIO(table_html))[0]
df['year'] = kbo_year
df.rename(columns={"선수명": "player_name"}, inplace=True)
df.rename(columns={"팀명": "team_name"}, inplace=True)
df.replace('-', '0', inplace=True)
for _, data in df.iterrows():
columns = ", ".join(df.columns[1:]) # 컬럼 리스트를 문자열로 변환
values_placeholder = ", ".join(["%s"] * len(data.iloc[1:])) # 플레이스홀더 생성
sql = f"INSERT INTO KBO_TABLE ({columns}) VALUES ({values_placeholder})"
cur.execute(sql, tuple(data.iloc[1:])) # 데이터를 튜플로 변환하여 실행
# 첫 번째 페이지로 돌아가기
first_page = driver.find_element(By.CSS_SELECTOR, '#cphContents_cphContents_cphContents_ucPager_btnNo1').click()
time.sleep(.5)
except NoSuchElementException:
pass
conn.commit()
# 작동 종료
driver.quit()몇가지 수정했다.
- 드롭박스에서 값을 지정하는데 wait으로 태그를 불러오고 나서 작동하게 했음에도 계속 태그가 불러와지기 전에 찾으려고 시도하는 바람에 오류가 발생했다. -> time.sleep(.5)을 중간에 넣어주었다.
- 테이블을 불러오고 그것을 데이터프레임으로 변환한 후 그 내용을 mysql에 insert문으로 넣었다.
- 2번 페이지가 있을 때 1번 페이지로 돌아오지 않으면 계속 2번 페이지에서 머무는 문제가 있었다. (그러면 다음 팀으로 갔을 때, 1번으로 돌아오지 않고 2번 페이지가 없는 팀은 그냥 빈칸이 나온다.) -> 다시 1번 페이지로 돌아오게 하였다.
- 데이터의 컬럼과 mysql 테이블의 컬럼이 달라서 맞춰주었다.
- avg(타율)은 숫자로 들어가야 하는데 데이터에는 '-'으로 표기되는 경우가 있었다. -> 모두 0으로 바꿔주었다.
- driver, wait은 따로 함수로 만들어주었다.
- 세부사항이나 다음 기록 같은 경우에는 아예 페이지가 달라서 따로 추출하고 나중에 합치는 방식으로 하려고 한다.
