- AWS Lambda
- 레이어 → AWS Lambda가 실행될 때 Lambda가 내장하고 있는 파이썬 모듈을 제외한 나머지 외부 모듈들은 따로 설치를 해야한다.
- Lambda는 amazon linux 기반의 리눅스에서 작동하므로 파이썬 모듈들을 amazon linux에 맞게 설치해야 한다.
- 도커 내의 amazon linux 컨테이너에서 docker volume을 이용해 로컬 디렉토리와 연결하고 사용할 외부 모듈들을 설치한다
$ docker run -it --rm -v /Users/ihyeonmin/Desktop/lambda/python:/app onema/amazonlinux4lambda bash $ cd /app $ mkdir -p python $ pip3 install --ignore-installed --target=python [사용할 패키지 명] $ rm -rf [Lambda에 내장되어 있는 패키지] $ zip -r ../python.zip . - 컨테이너와 연결한 로컬 디렉토리로 가서 python.zip 파일을 학인하고 Lambda Layer를 생성해주고 업로드하면 됨!
- aws lambda 페이지에서 계층 탭으로 이동
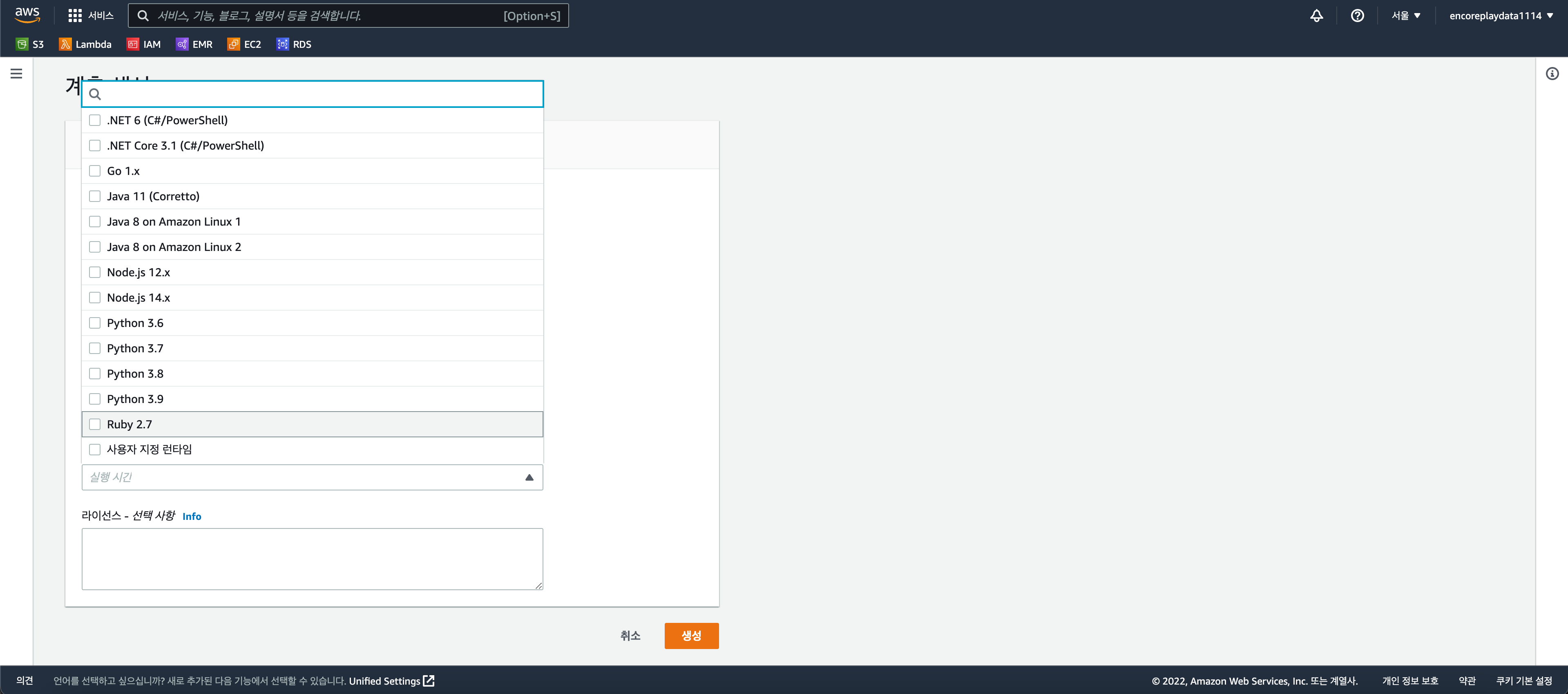
2. 계층 생성 - 아까 만든 Zip 파일 업로드 및 런타임 선택 후 생성
- 사용할 Lambda 함수 생성
- 코드 탭 밑에 있는 계층에서 Add a Layer 선택
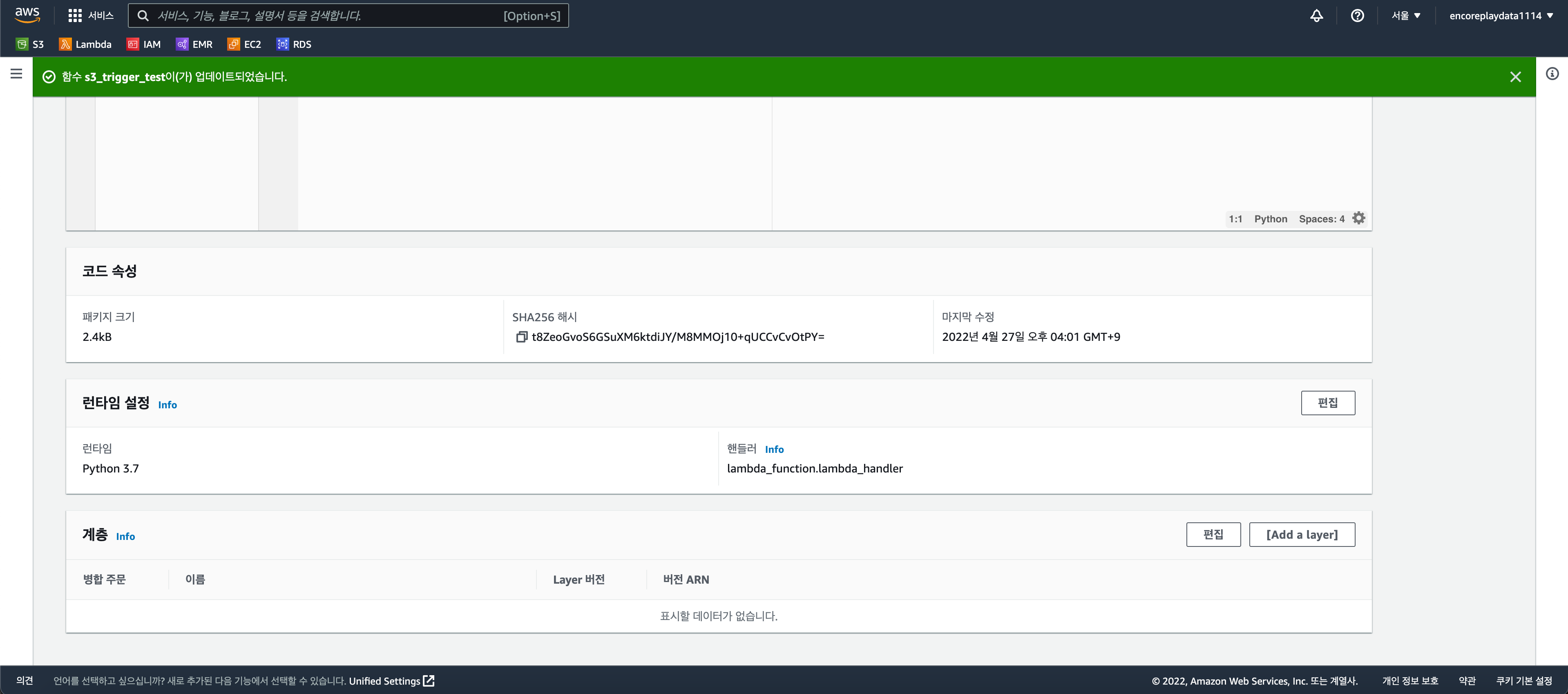
- 사용자 지정 계층 선택 - 생성한 계층 및 버젼 선택 - 추가
- 람다 함수에서 main 함수의 역할은
def lambda_handler(event, context):가 한다.
- aws lambda 페이지에서 계층 탭으로 이동
- S3 Trigger
- 전제 조건 : S3 bucket 접속 권한 필요
- Lambda 함수에서 트리거 추가 클릭
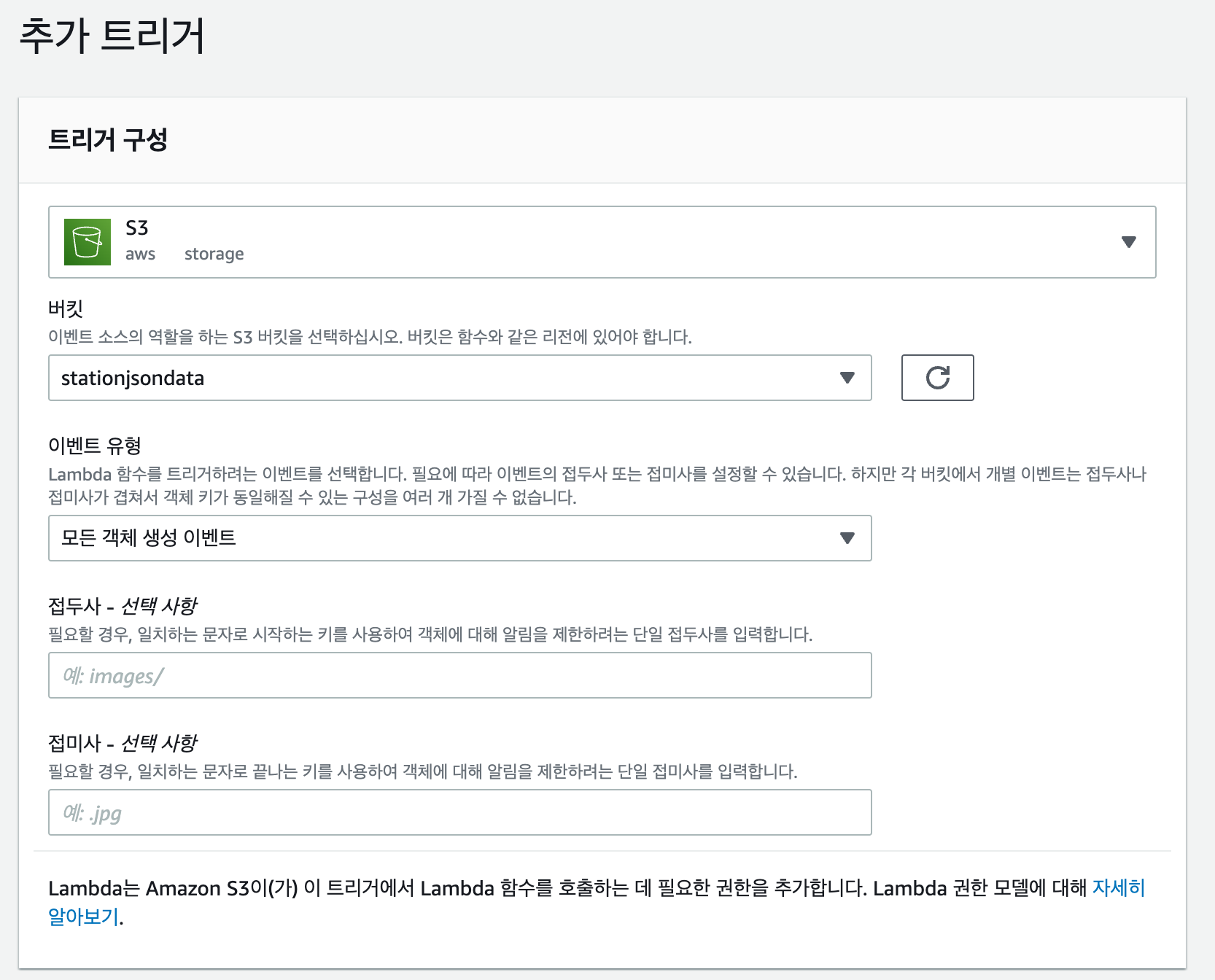
트리거를 사용할 버킷 선택 및 업로드할 파일명이나 형식을 지정해서 이벤트가 발생시 트리거가 실행되어서 Lambda 함수를 사용할 수 있다.
- 레이어 → AWS Lambda가 실행될 때 Lambda가 내장하고 있는 파이썬 모듈을 제외한 나머지 외부 모듈들은 따로 설치를 해야한다.
- AWS EMR
- EMR 구성 - 고급 옵션 사용
- 1단계
- 우선 스파크를 사용하고 주피터 노트북 환경을 사용하기 위해 Jupyter와 관련된 소프트웨어들과 연결을 관리해주는 Livy라는 소프트웨어도 추가해주었다.
- 사용한 소프트웨어 리스트
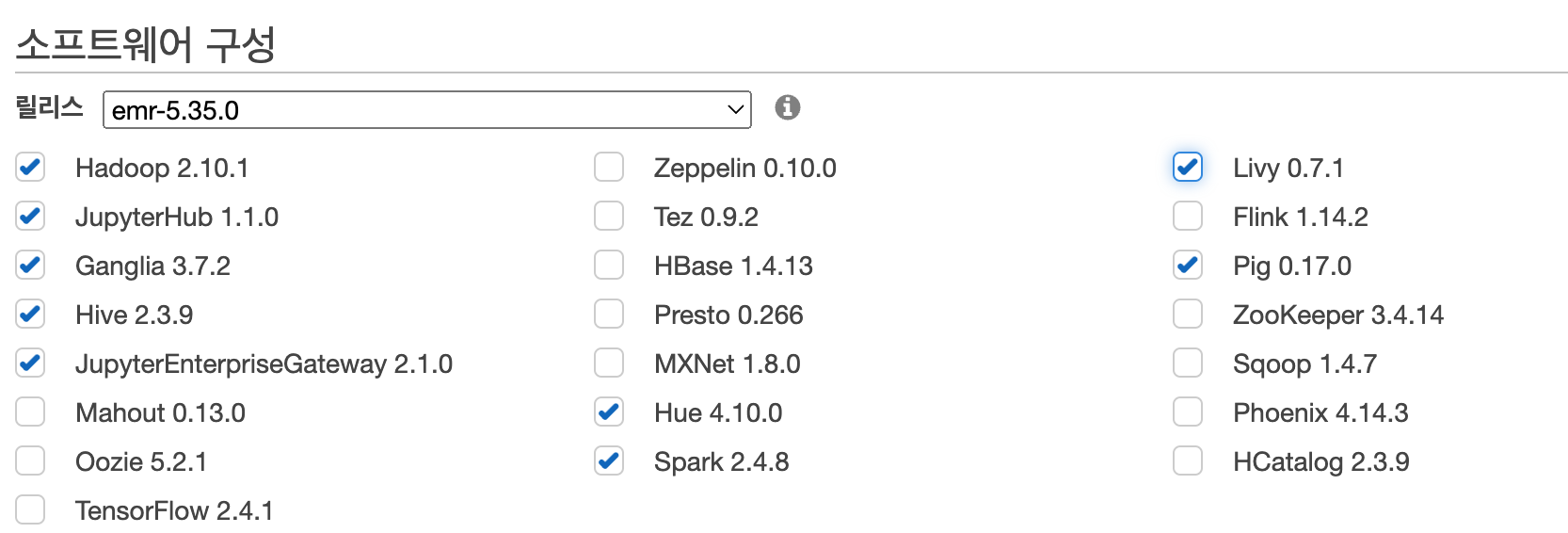
EMR에서 주피터 노트북을 사용하려면 ami 사용자로 로그인해서 접속해야한다.(원래 계정으론 접속 불가(마스터 역할))
- 사용한 소프트웨어 리스트
- 우선 스파크를 사용하고 주피터 노트북 환경을 사용하기 위해 Jupyter와 관련된 소프트웨어들과 연결을 관리해주는 Livy라는 소프트웨어도 추가해주었다.
- 2단계
- 자동 종료 비활성화 및 auto-scaling 활성화
- 3단계
- 부트스트랩 작업
- Spark 작업을 코어 노드에서 수행하는데 외부 모듈 및 jar 파일 사용시 코어 노드에 외부 모듈을 설치해야 한다. 이때 자동으로 설치하는 방법이 바로 부트스트랩 작업이다.
- 쉘 스크립트로 작성해야 하며 작성한 쉘 파일을 s3에 업로드해야한다.
-
프로젝트 중 사용한 쉘 스크립트
#!/bin/bash aws s3 cp s3://projectsparkcode/tools/mysql-connector-java-8.0.28.jar /home/hadoop sudo pip3 install pandas==1.2.5 sudo pip3 install sklearn sudo pip3 install requests sudo pip3 install html_table_parser sudo pip3 install pymysql -
aws s3 cp s3://projectsparkcode/tools/mysql-connector-java-8.0.28.jar /home/hadoop : spark와 RDS 내의 mysql java connector
-
- 쉘 스크립트로 작성해야 하며 작성한 쉘 파일을 s3에 업로드해야한다.
- Spark 작업을 코어 노드에서 수행하는데 외부 모듈 및 jar 파일 사용시 코어 노드에 외부 모듈을 설치해야 한다. 이때 자동으로 설치하는 방법이 바로 부트스트랩 작업이다.
- 부트스트랩 작업
- 4단계
- pem 키 지정
- 1단계
- Spark-submit
$ spark-submit --master yarn --deploy-mode cluster --jars mysql-connector-java-8.0.28.jar \ --driver-class-path mysql-connector-java-8.0.28.jar --conf spark.executor.extraClassPath=mysql-connector-java-8.0.28.jar \ --conf spark.yarn.appMasterEnv.LANG=ko_KR.UTF-8 --executor-memory 12G --executor-cores 4 --driver-memory 7G --driver-cores 1 play.py- --master : yarn(스파크 자원 관리)
- --deploy-mode : 클러스터 모드
- --jars --driver-class-path : 외부 jar 파일
- --conf : spark property 설정
- spark.yarn.appMasterEnv.LANG=ko_KR.UTF-8 : yarn cluster 모드 시 한글 깨짐 현상 방지
- 메모리 설정 및 코어 설정
- 1개의 Executor는 하나의 JVM(Java Virtual Machine)을 가짐
- Cluster는 Driver가 YARN에 관리되는 어플리케이션 마스터 프로세스 내에서 실행되므로 효율적인 자원 관리가 가능하여 서비스에 배포할 때 주로 사용
- EMR 구성 - 고급 옵션 사용

BI 관련 솔루션 회사를 퇴사한 후 데이터 엔지니어 준비중입니다