파이썬 코딩 도장

Unit 23. 2차원 리스트 사용하기
2차원 리스트를 만들고 요소에 접근하기
🔎 2차원 리스트 정리
- 가로×세로의 평면 구조
- 리스트 안에 리스트를 넣어서 만들 수 있음
- 안쪽의 각 리스트는 ,(콤마)로 구분
- 요소 접근 또는 할당 시 리스트에 를 두 번 사용, [ ] 안에 세로 인덱스와 가로 인덱스를 지정
- 🚨 2차원 공간은 가로×세로로 표기 -> 리스트로 만들 때는 세로×가로로 표기
리스트 = [[값, 값], [값, 값], [값, 값]] # 2차원 리스트 만들기
리스트[세로인덱스][가로인덱스] # 2차원 리스트의 요소에 접근
리스트[세로인덱스][가로인덱스] = 값 # 2차원 리스트의 요소에 값 저장
리스트 = [(값, 값), (값, 값), (값, 값)] # 리스트 안에 튜플을 넣음
튜플 = ([값, 값], [값, 값], [값, 값]) # 튜플 안에 리스트를 넣음
튜플 = ((값, 값), (값, 값), (값, 값)) # 튜플 안에 튜플을 넣음반복문으로 2차원 리스트의 요소를 모두 출력
🔎 반복문의 사용
- for문을 한 번만 사용
>>> a = [[10, 20], [30, 40], [50, 60]]
>>> for x, y in a: # 리스트의 가로 한 줄(안쪽 리스트)에서 요소 두 개를 꺼냄
... print(x, y)
...
10 20
30 40
50 60- for문을 2번 사용
a = [[10, 20], [30, 40], [50, 60]]
for i in a: # a에서 안쪽 리스트를 꺼냄
for j in i: # 안쪽 리스트에서 요소를 하나씩 꺼냄
print(j, end=' ')
print()
# 실행결과
10 20
30 40
50 60🔎 for와 range 사용하기
a = [[10, 20], [30, 40], [50, 60]]
for i in range(len(a)): # 세로 크기
for j in range(len(a[i])): # 가로 크기
print(a[i][j], end=' ')
print()🔎 while 반복문을 한 번 사용하기
a = [[10, 20], [30, 40], [50, 60]]
i = 0
while i < len(a): # 반복할 때 리스트의 크기 활용(세로 크기)
x, y = a[i] # 요소 두 개를 한꺼번에 가져오기
print(x, y)
i += 1 # 인덱스를 1 증가시킴🔎 while 반복문을 두 번 사용하기
a = [[10, 20], [30, 40], [50, 60]]
i = 0
while i < len(a): # 세로 크기
j = 0
while j < len(a[i]): # 가로 크기
print(a[i][j], end=' ')
j += 1 # 가로 인덱스를 1 증가시킴
print()
i += 1 # 세로 인덱스를 1 증가시킴- 안쪽 while에서 i를 증가시키면 안됨.
i = 0
while i < len(a):
j = 0
while j < len(a[i]):
print(a[i][j], end=' ')
j += 1
i += 1 # 잘못된 방법
print()반복문으로 리스트 만들기
🔎 톱니형 리스트 만들기
a = [3, 1, 3, 2, 5] # 가로 크기를 저장한 리스트
b = [] # 빈 리스트 생성
for i in a: # 가로 크기를 저장한 리스트로 반복
line = [] # 안쪽 리스트로 사용할 빈 리스트 생성
for j in range(i): # 리스트 a에 저장된 가로 크기만큼 반복
line.append(0)
b.append(line) # 리스트 b에 안쪽 리스트를 추가
print(b)- 실행결과
[[0, 0, 0], [0], [0, 0, 0], [0, 0], [0, 0, 0, 0, 0]]2차원 리스트의 할당과 복사 알아보기
🔎 할당과 복사
>>> a = [[10, 20], [30, 40]]
>>> b = a
>>> b[0][0] = 500
>>> a
[[500, 20], [30, 40]]
>>> b
[[500, 20], [30, 40]]>>> a = [[10, 20], [30, 40]]
>>> b = a.copy()
>>> b[0][0] = 500
>>> a
[[500, 20], [30, 40]]
>>> b
[[500, 20], [30, 40]]>>> a = [[10, 20], [30, 40]]
>>> import copy # copy 모듈을 가져옴
>>> b = copy.deepcopy(a) # copy.deepcopy 함수를 사용하여 깊은 복사
>>> b[0][0] = 500
>>> a
[[10, 20], [30, 40]]
>>> b
[[500, 20], [30, 40]]퀴즈
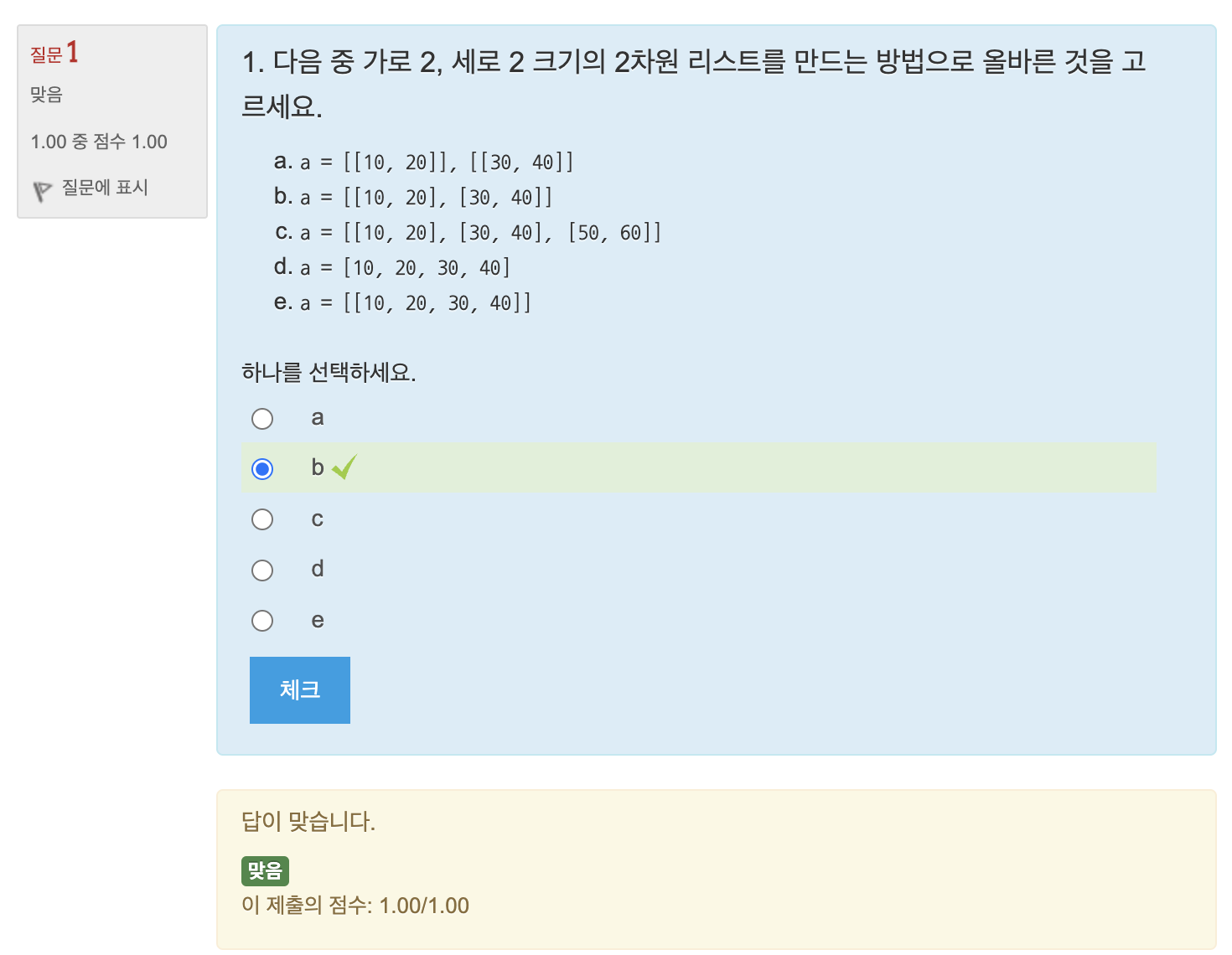
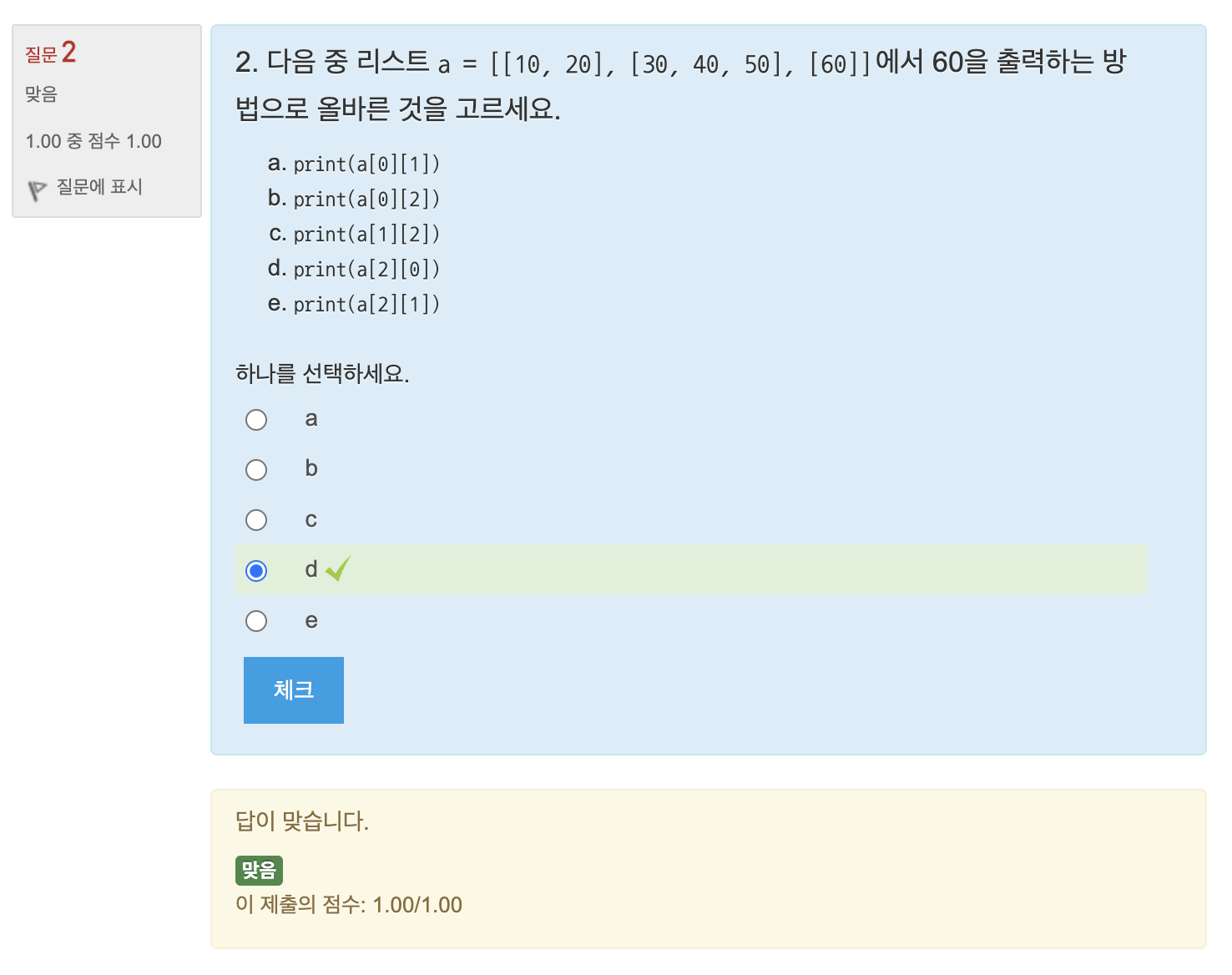
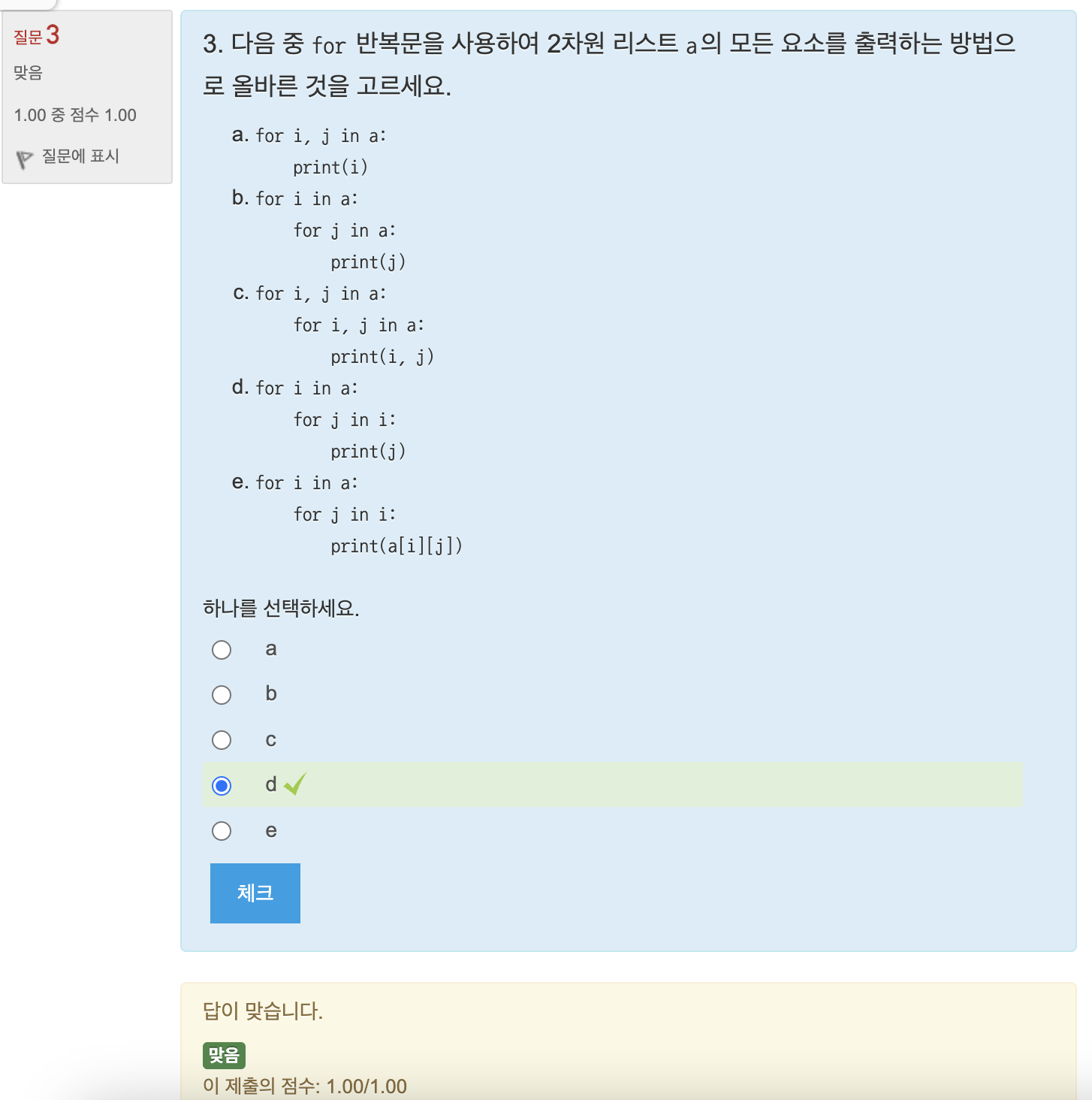
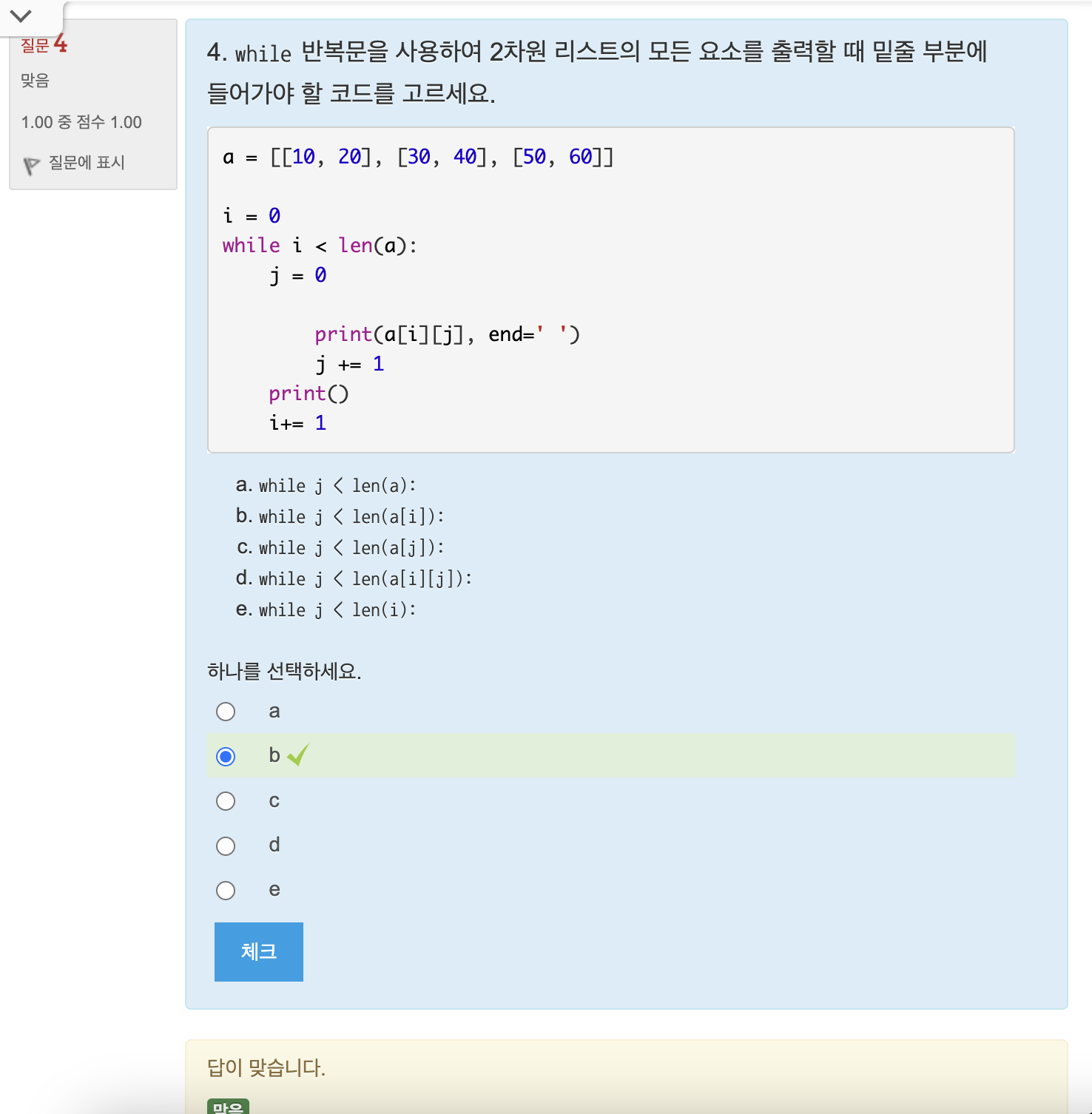
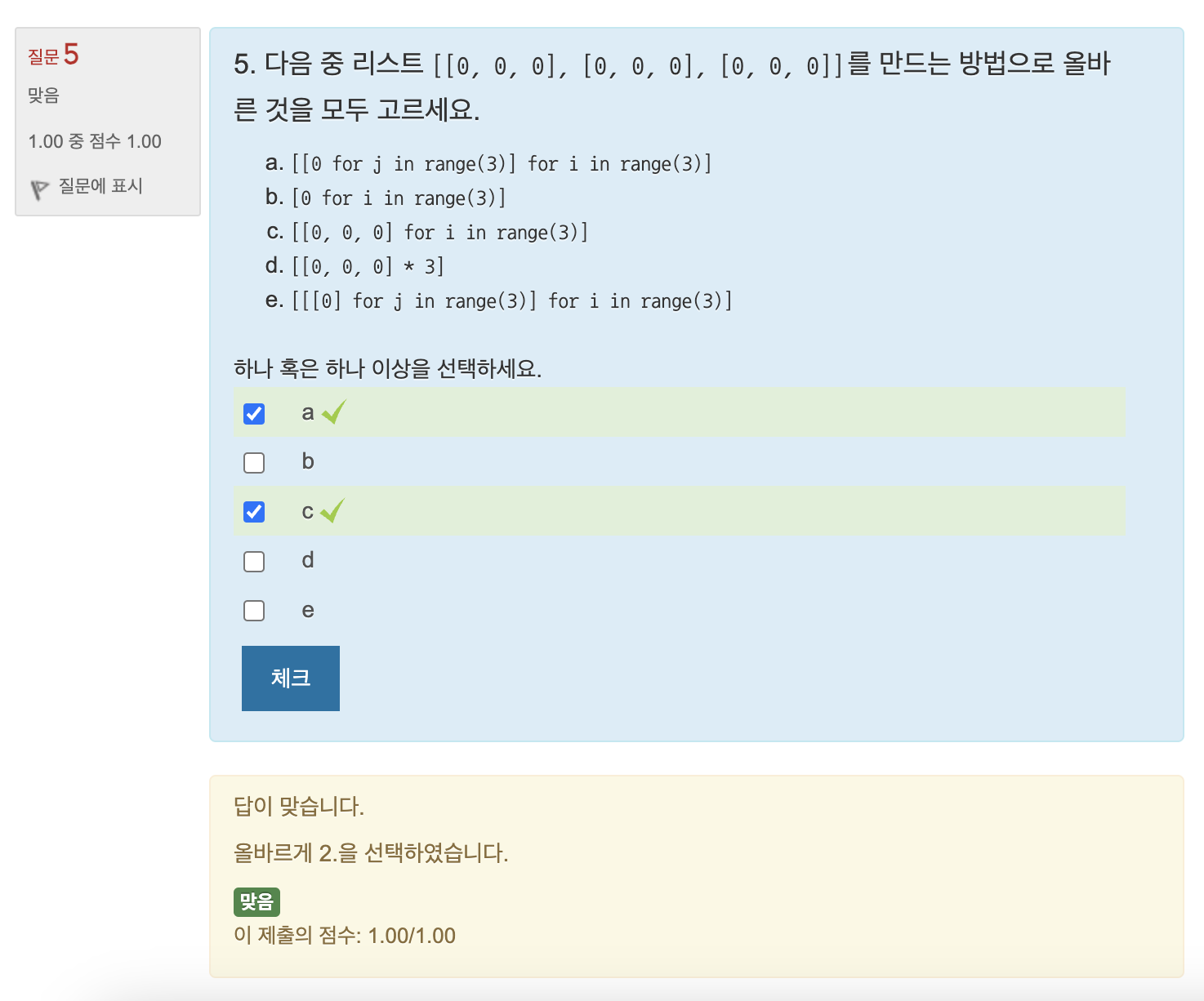
연습문제: 3차원 리스트 만들기

[[[0 for col in range(3)] for row in range(4)] for depth in range(2)]심사문제: 지뢰찾기

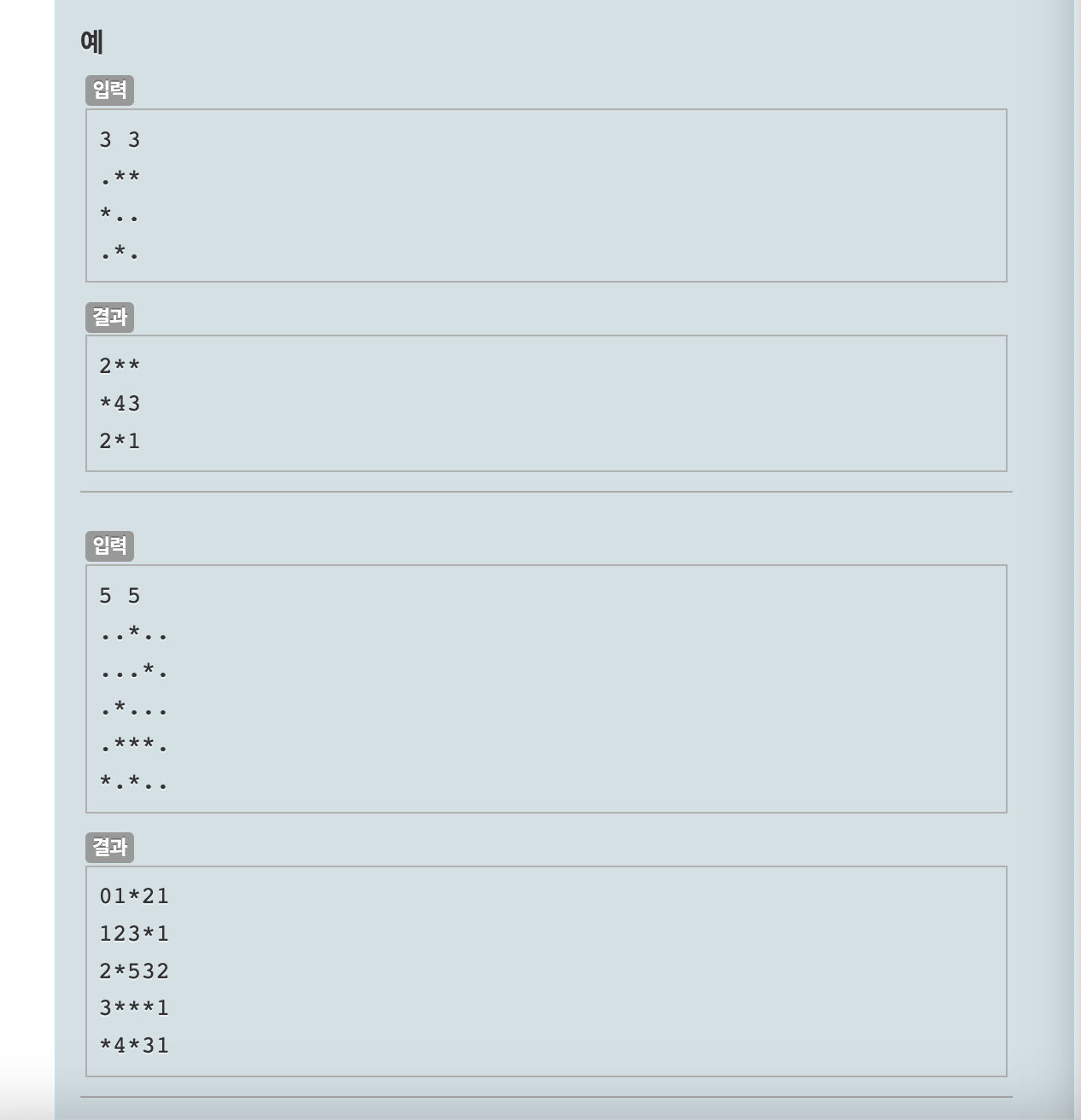
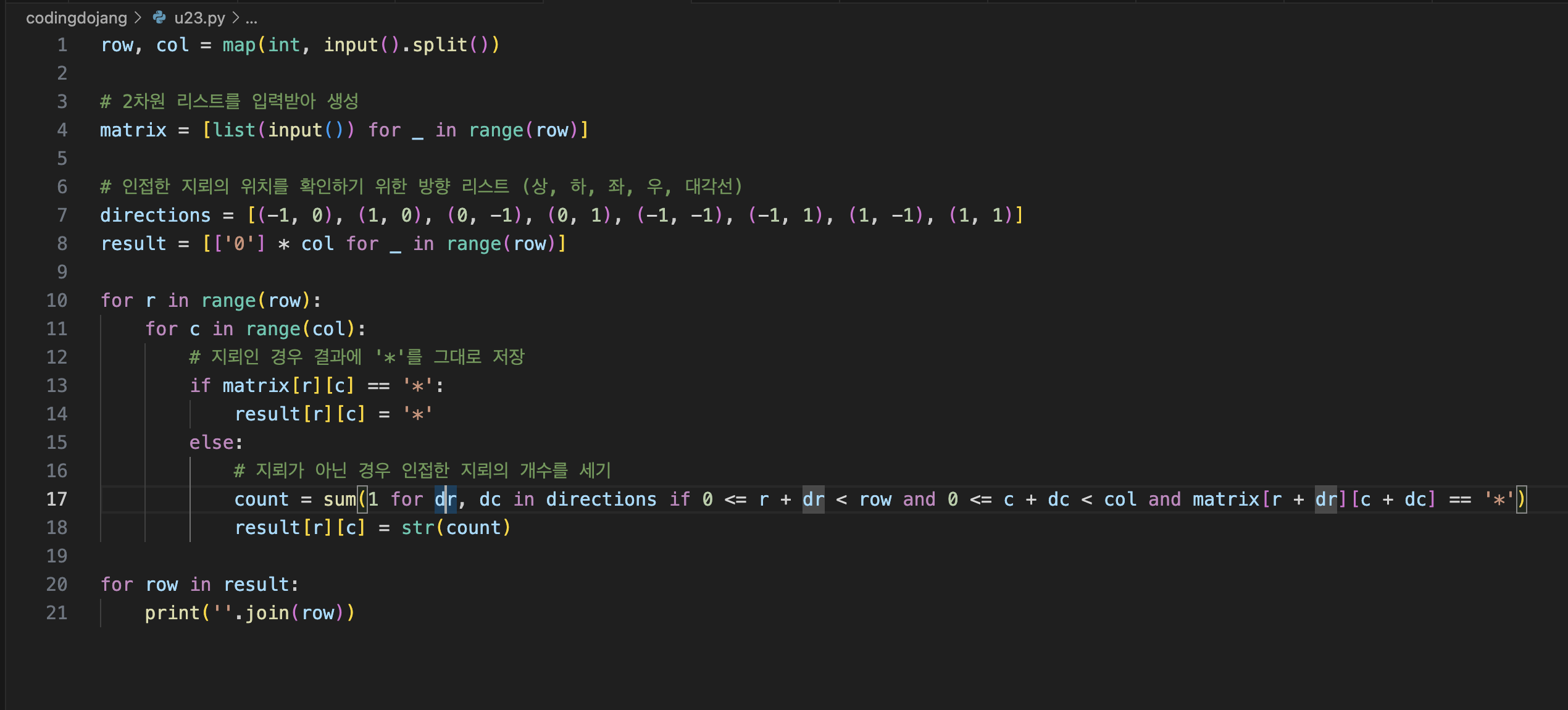

3차원 리스트 정리
- 높이×세로×가로 형태
- 리스트로 만들 때는 높이×세로×가로로 표기
리스트 = [[[값, 값], [값, 값]], [[값, 값], [값, 값]], [[값, 값], [값, 값]]] # 3차원 리스트 만들기
리스트[높이인덱스][세로인덱스][가로인덱스] # 3차원 리스트의 요소에 접근
리스트[높이인덱스][세로인덱스][가로인덱스] = 값 # 3차원 리스트의 요소에 값 저장Unit 24. 문자열 응용하기
문자열 조작하기
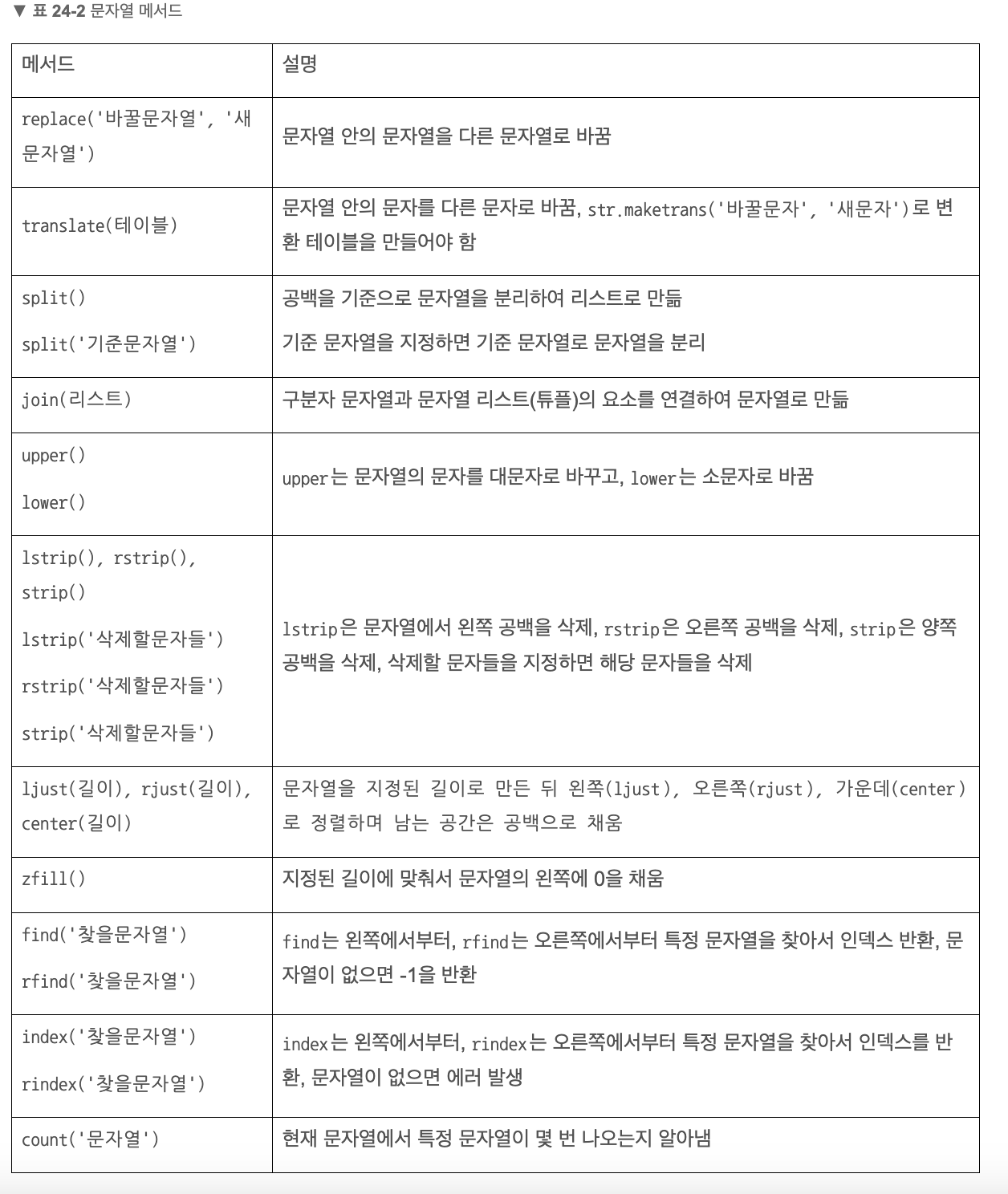
🔎 문자열 메서드
🔎 문자열 서식 지정자와 포매팅 사용하기
문자열 서식 지정자
- %로 시작
지정자 종류
- %s: 문자열
- %d: 정수
- %f: 실수
'%서식지정자' % 값 # 서식 지정자 한 개 사용
'I am %s.' % 'maria' # 'I am maria.'
'%서식지정자1, %서식지정자2' % (값1, 값2) # 서식 지정자 여러 개 사용
'Today is %d %s.' % (3, 'April') # 'Today is 3 April.'- 소수점 이하 자릿수 지정
'%.자릿수f' % 숫자 # 소수점 이하 자릿수 지정하기
'%.3f' % 2.3 # '2.300'- %뒤에 숫자를 붙이면 문자열을 지정된 길이로 만든 뒤 오른쪽으로 정렬하고 남는 공간을 공백으로 채우기
- 음수로 지정하면 왼쪽 정렬
%길이s # 문자열을 지정된 길이로 만든 뒤 오른쪽으로 정렬하고 남는 공간을 공백으로 채움
'%10s' % 'python' # ' python'
%-길이s # 문자열을 지정된 길이로 만든 뒤 왼쪽으로 정렬하고 남는 공간을 공백으로 채움
'%-10s' % 'python' # 'python '- %와 d사이에 0과 숫자 개수 -> 자릿수에 맞춰서 앞에 0이 들어감.
'%0개수d' % 숫자 # 자릿수에 맞춰서 0이 들어감
'%03d' % 1 # '001'
'%0개수.자릿수f' % 숫자 # 실수의 소수점 이하 자릿수 지정
'%08.2f' % 3.6 # '00003.60'문자열 포매팅
- { }(중괄호) 안에 인덱스를 지정
- format에는 { } 부분에 들어갈 값을 지정
'{0}'.format(값) # 값을 한 개 넣음
'{0} {1}'.format(값1, 값2) # 값을 두 개 넣음
'{0} {0} {1} {1}'.format(값1, 값2) # 같은 인덱스에는 같은 값이 들어감
'{} {} {}'.format(값1, 값2, 값3) # 인덱스를 생략하면 format에 지정한 순서대로 값이 들어감
'{name1} {name2}'.format(name1=값1, name2=값2) # { }에 이름을 지정- 3.6부터는 변수에 값을 넣고 { } 안에 변수 이름 지정, 문자열 앞에 f 붙이기
변수1, 변수2 = 값1, 값2
f'{변수1} {변수2}'- < : 문자열을 지정된 길이로 만든 뒤 왼쪽으로 정렬하고 남는 공간을 공백으로 채움
: 오른쪽 정렬
'{인덱스:<길이}'.format(값) # 문자열을 지정된 길이로 만든 뒤 왼쪽 정렬, 남는 공간을 공백으로 채움
'{인덱스:>길이}'.format(값) # 문자열을 지정된 길이로 만든 뒤 오른쪽 정렬, 남는 공간을 공백으로 채움- 인덱스나 이름 뒤에 : 을 붙이고, 0과 숫자 개수 지정 -> 자릿수에 맞춰서 0이 들어감.
'{인덱스:0개수d'}'.format(숫자) # 자릿수에 맞춰서 0이 들어감
'{인덱스:0개수.자릿수f'}.format(숫자) # 실수의 소수점 이하 자릿수 지정- 채우기, 정렬, 길이, 자릿수, 자료형 조합해 사용 가능
'{인덱스:[[채우기]정렬][길이][.자릿수][자료형]}'
'{0:0<10}'.format(15) # '1500000000': 길이 10, 왼쪽으로 정렬하고 남는 공간은 0으로 채움
'{0:0>10.2f}'.format(15) # '0000015.00': 길이 10, 오른쪽으로 정렬하고 소수점 이하 자릿수는 2자리
'{0: >10}'.format(15) # ' 15': 남는 공간을 공백으로 채움
'{0:>10}'.format(15) # ' 15': 채우기 부분을 생략하면 공백이 들어감
'{0:x>10}'.format(15) # 'xxxxxxxx15': 남는 공간을 문자 x로 채움서식 지정자 자료형

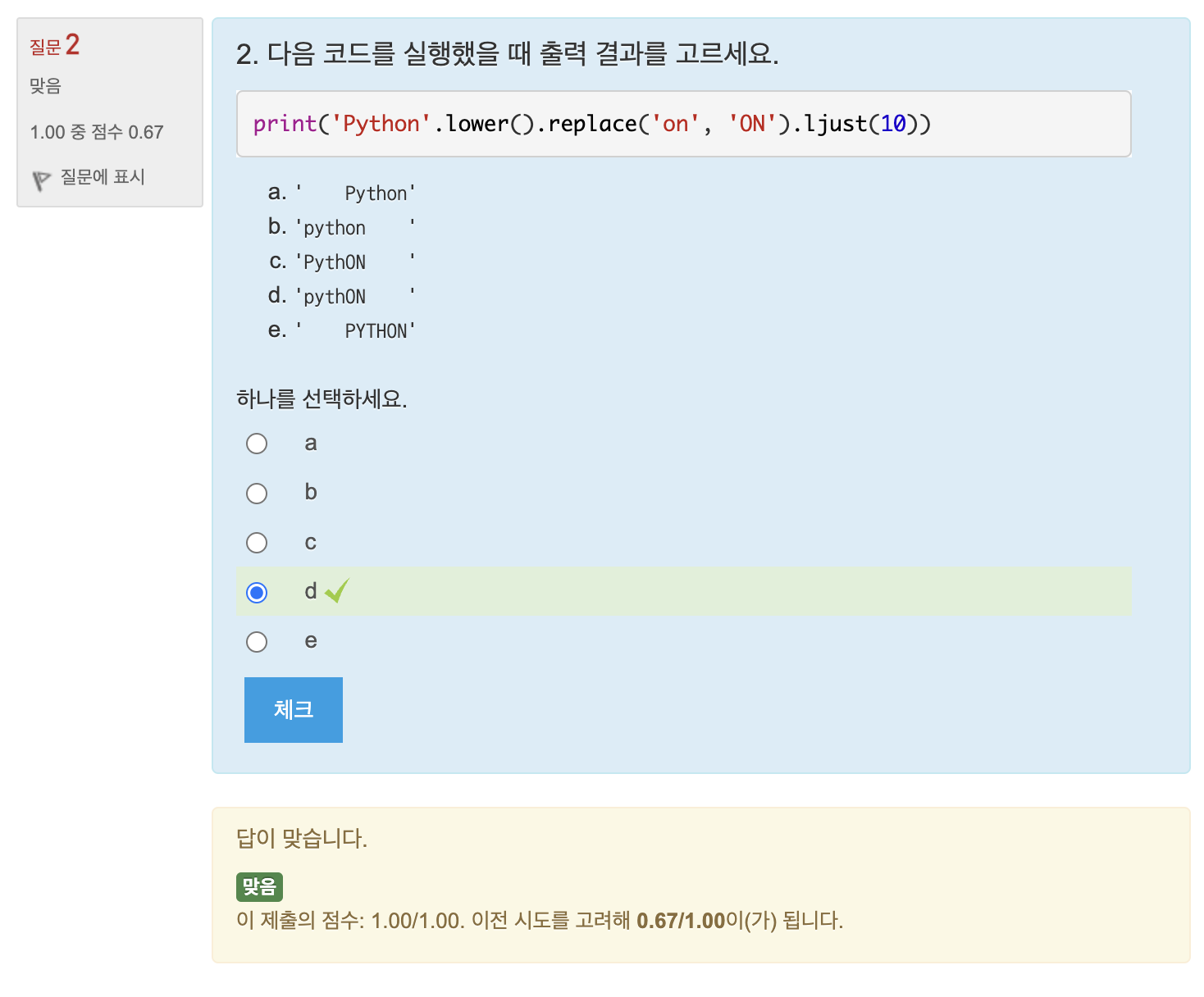
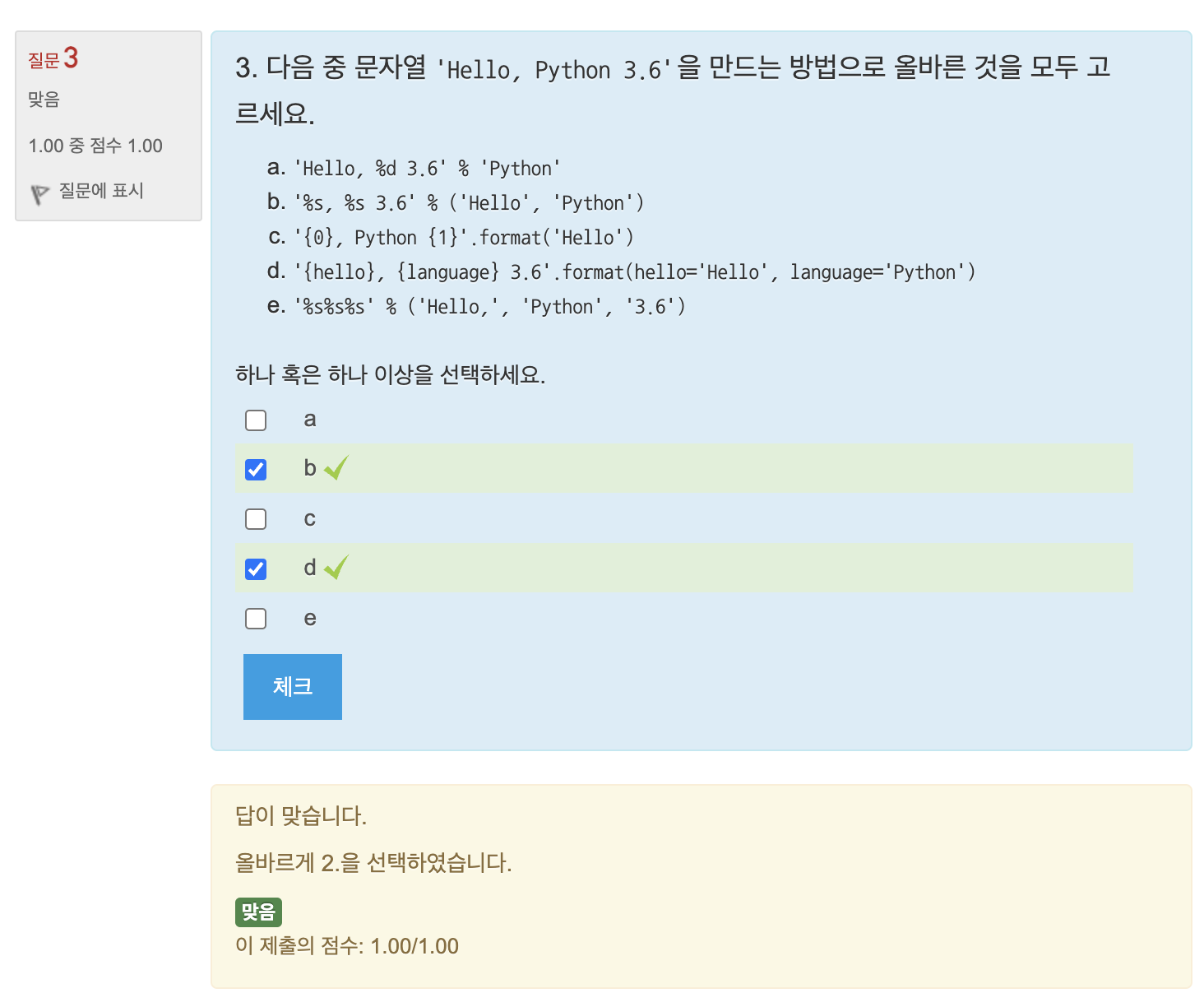
퀴즈
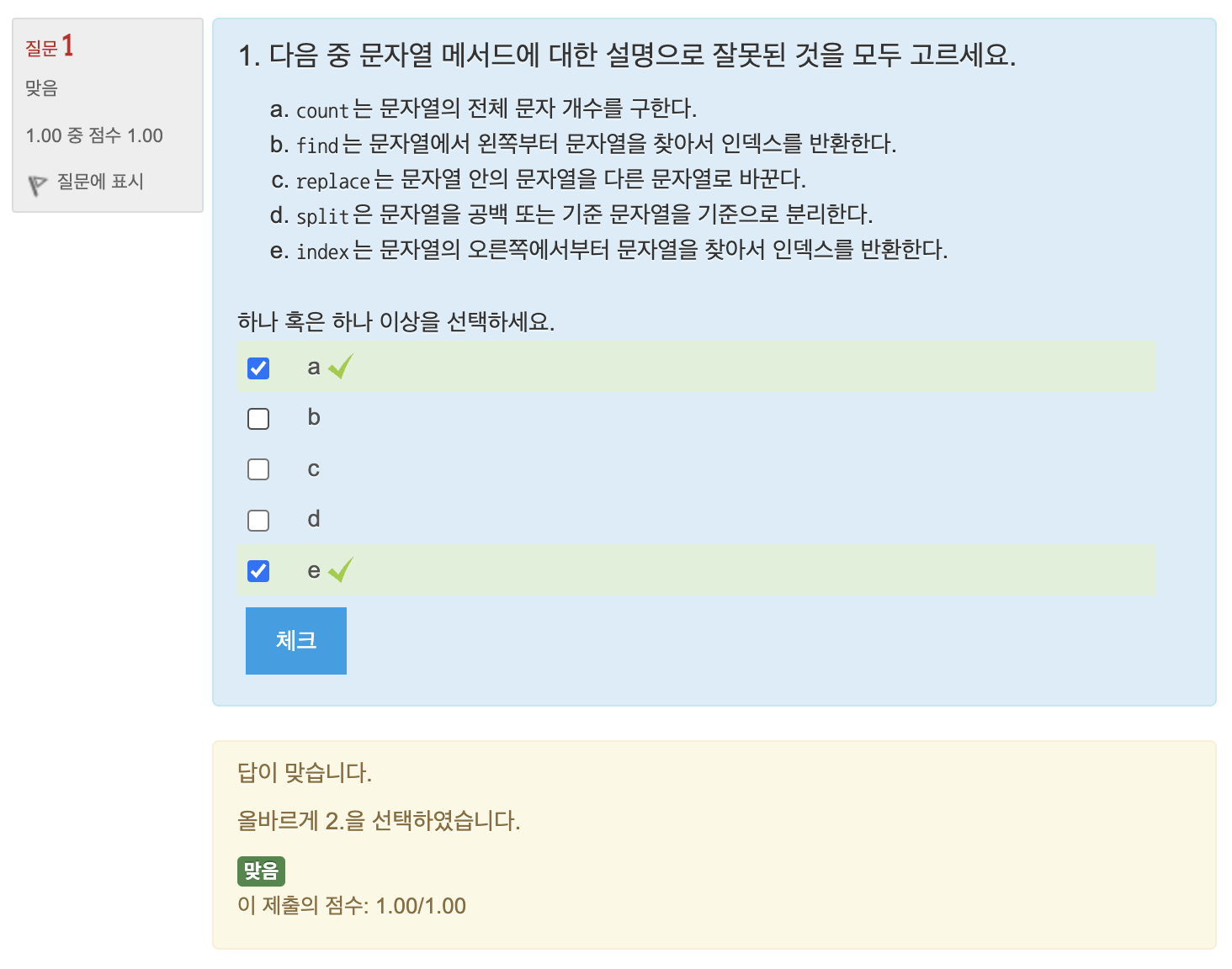
- 소문자 변환을 고려하지 않아 부분 오답

연습문제: 파일 경로에서 파일명만 가져오기
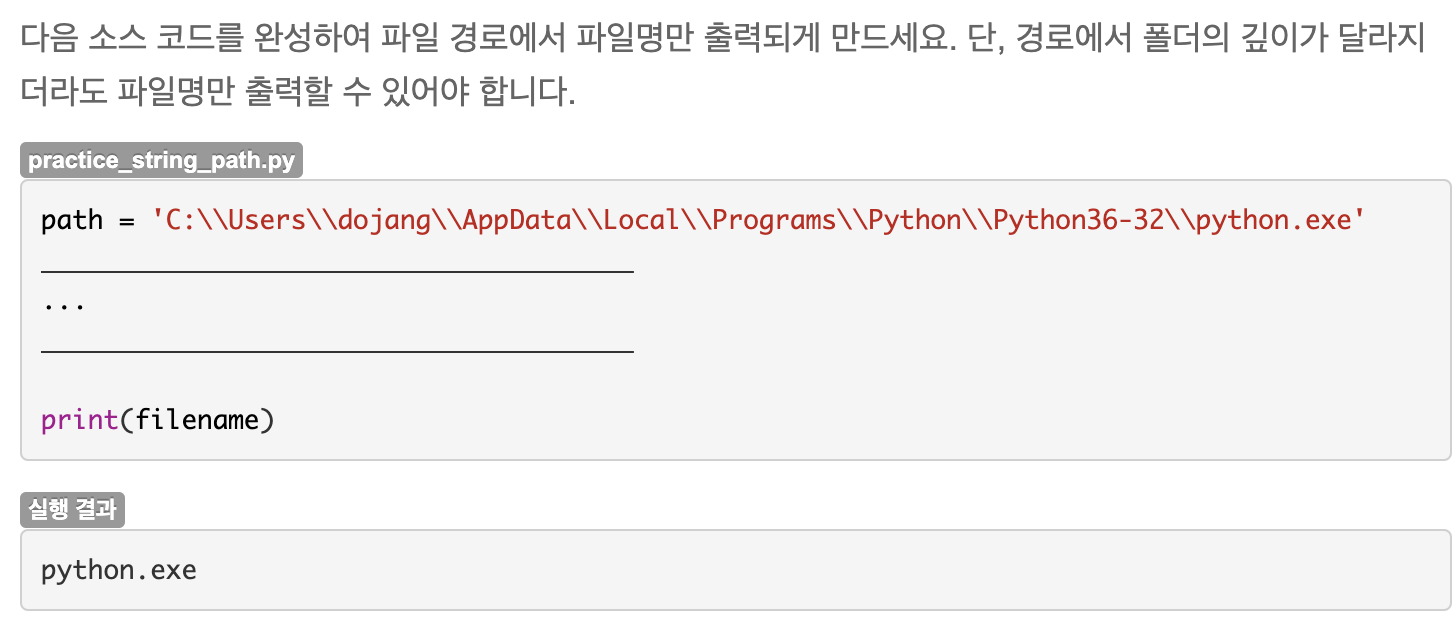
x = path.split('\\')
filename = x[-1]심사문제(1): 특정 단어 개수 세기


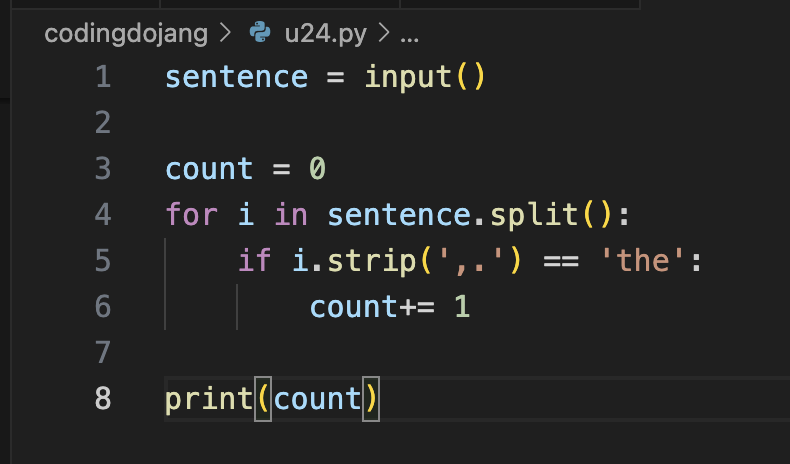

심사문제(2): 높은 가격순으로 출력하기
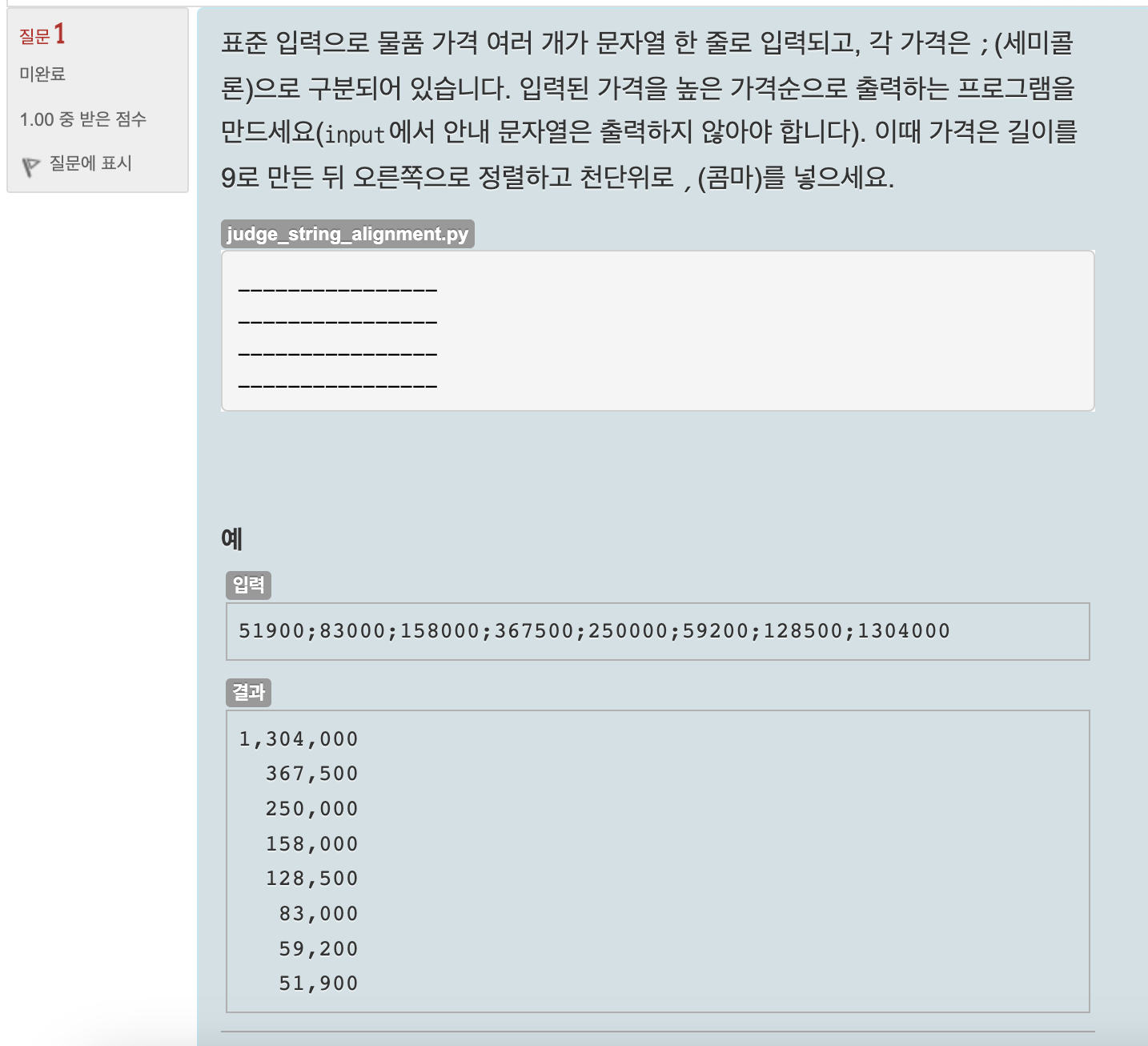
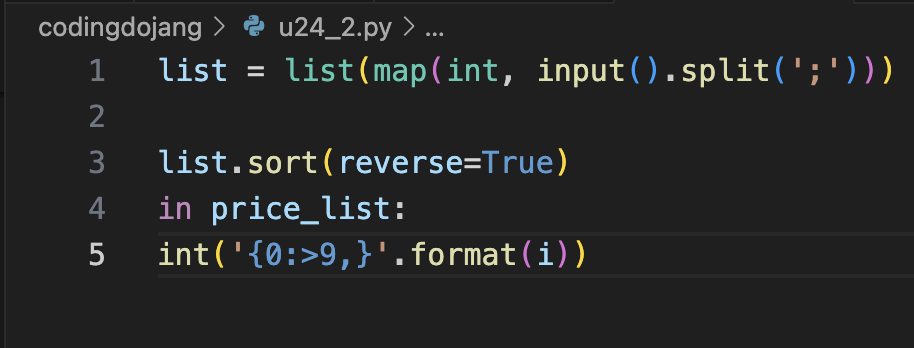

Unit 25부터 핵심 정리 내용 위주로 정리 + 퀴즈 + 연습문제 + 심사문제 풀이로 진행
Unit 25. 딕셔너리 응용하기
딕셔너리 조작하기
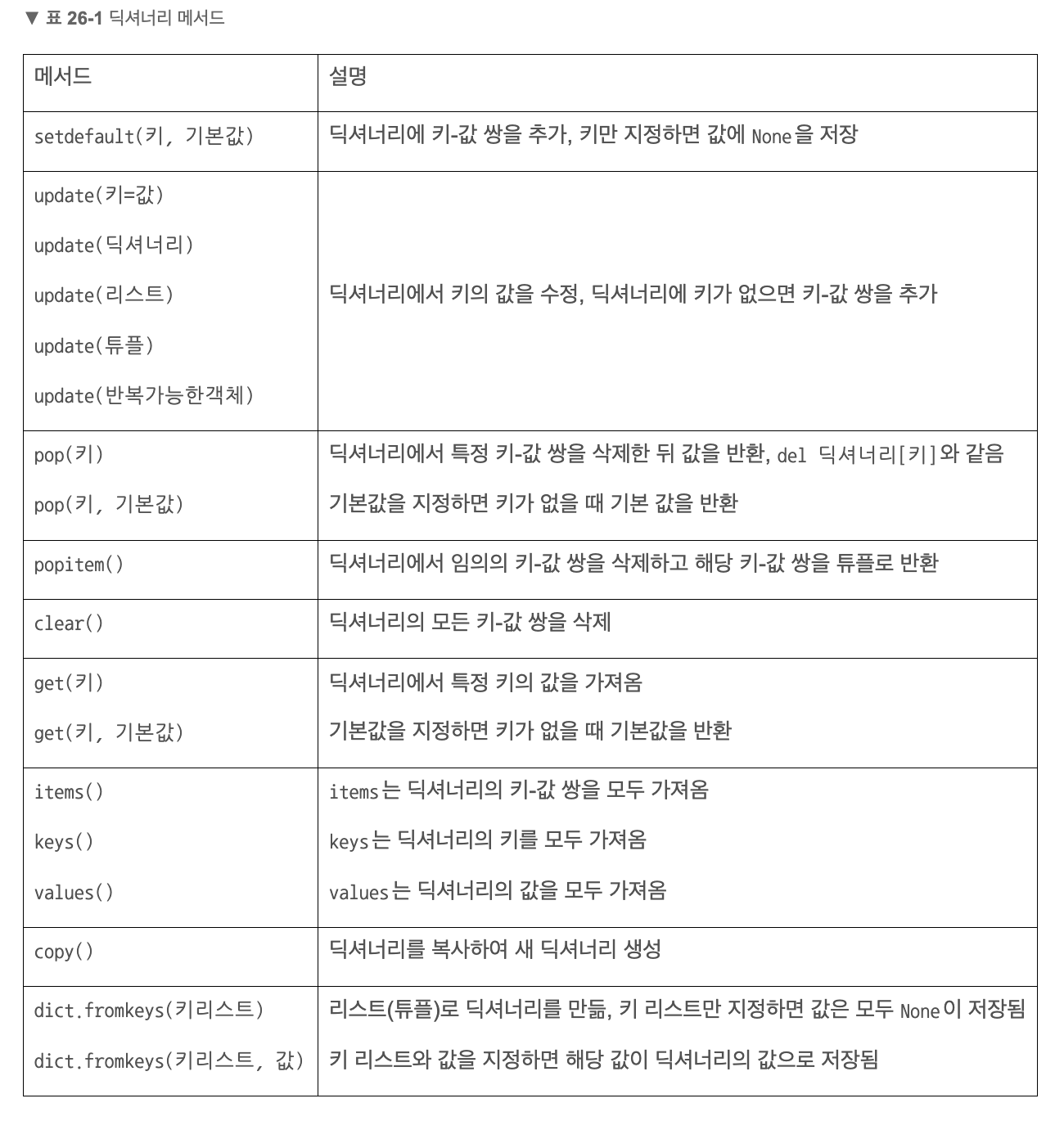
🔎 딕셔너리 메서드
반복문으로 딕셔너리의 키-값 쌍을 모두 출력하기
🔎 딕셔너리와 반복문
- for 변수 in 뒤에 딕셔너리를 지정하면 키만 꺼내옴.
- for in 뒤에 딕셔너리를 지정하고 items를 사용하면 반복 -> 키와 값을 꺼내옴.
for 변수 in 딕셔너리: # 모든 키를 꺼내옴
반복할 코드
for 키, 값 in 딕셔너리.items(): # 모든 키와 값을 꺼내옴
반복할 코드
for key, value in {'a': 10, 'b': 20, 'c': 30, 'd': 40}.items(): # 디셔너리 직접 지정도 가능
print(key, value)
for 키 in 딕셔너리.keys(): # 모든 키를 꺼내옴
반복할 코드
for 값 in 딕셔너리.values(): # 모든 값을 꺼내옴
반복할 코드딕셔너리 표현식 사용하기
🔎 딕셔너리 표현식
{키: 값 for 키, 값 in 딕셔너리}
{key: value for key, value in dict.fromkeys(['a', 'b', 'c', 'd']).items()}
dict({키: 값 for 키, 값 in 딕셔너리})
{키: 값 for 키, 값 in 딕셔너리 if 조건식}
{key: value for key, value in {'a': 10, 'b': 20, 'c': 30, 'd': 40}.items() if value != 20}
dict({키: 값 for 키, 값 in 딕셔너리 if 조건식})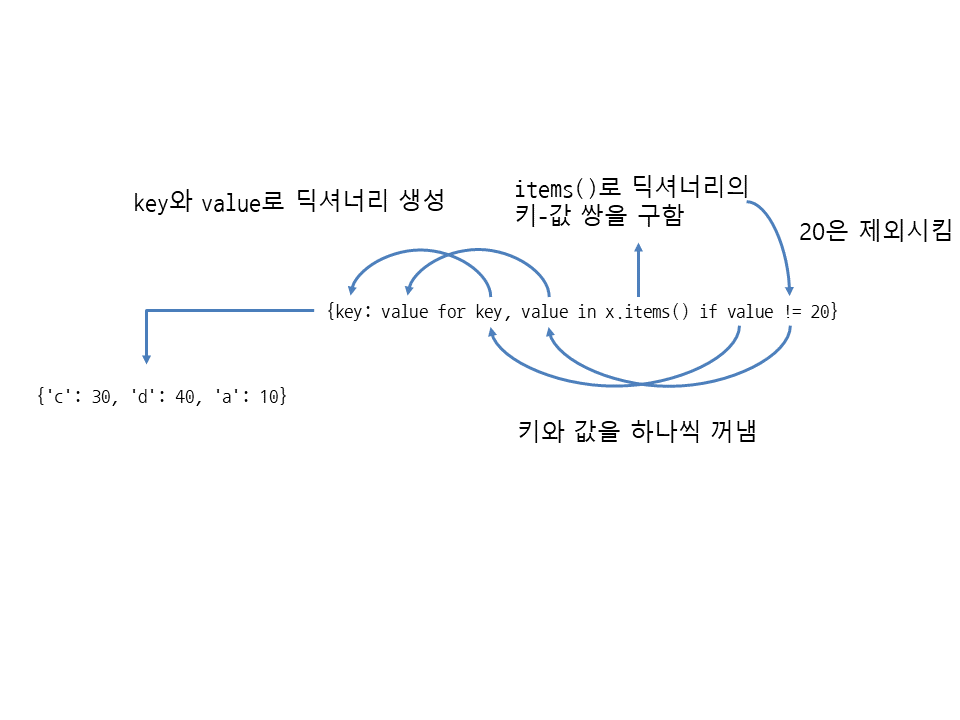
🔎 딕셔너리 안에 딕셔너리 사용하기
딕셔너리 = {키1: {키A: 값A}, 키2: {키B: 값B}} # 딕셔너리 안에 딕셔너리 넣기
딕셔너리[키][키] # 딕셔너리 안에 있는 딕셔너리에서 값에 접근
딕셔너리[키][키] = 값 # 딕셔너리 안에 있는 딕셔너리에서 키에 값 할당- 실제 예시 : 지구형 행성의 반지름, 질량, 공전주기 표현
terrestrial_planet = {
'Mercury': {
'mean_radius': 2439.7,
'mass': 3.3022E+23,
'orbital_period': 87.969
},
'Venus': {
'mean_radius': 6051.8,
'mass': 4.8676E+24,
'orbital_period': 224.70069,
},
'Earth': {
'mean_radius': 6371.0,
'mass': 5.97219E+24,
'orbital_period': 365.25641,
},
'Mars': {
'mean_radius': 3389.5,
'mass': 6.4185E+23,
'orbital_period': 686.9600,
}
}
print(terrestrial_planet['Venus']['mean_radius']) # 6051.8🔎 퀴즈
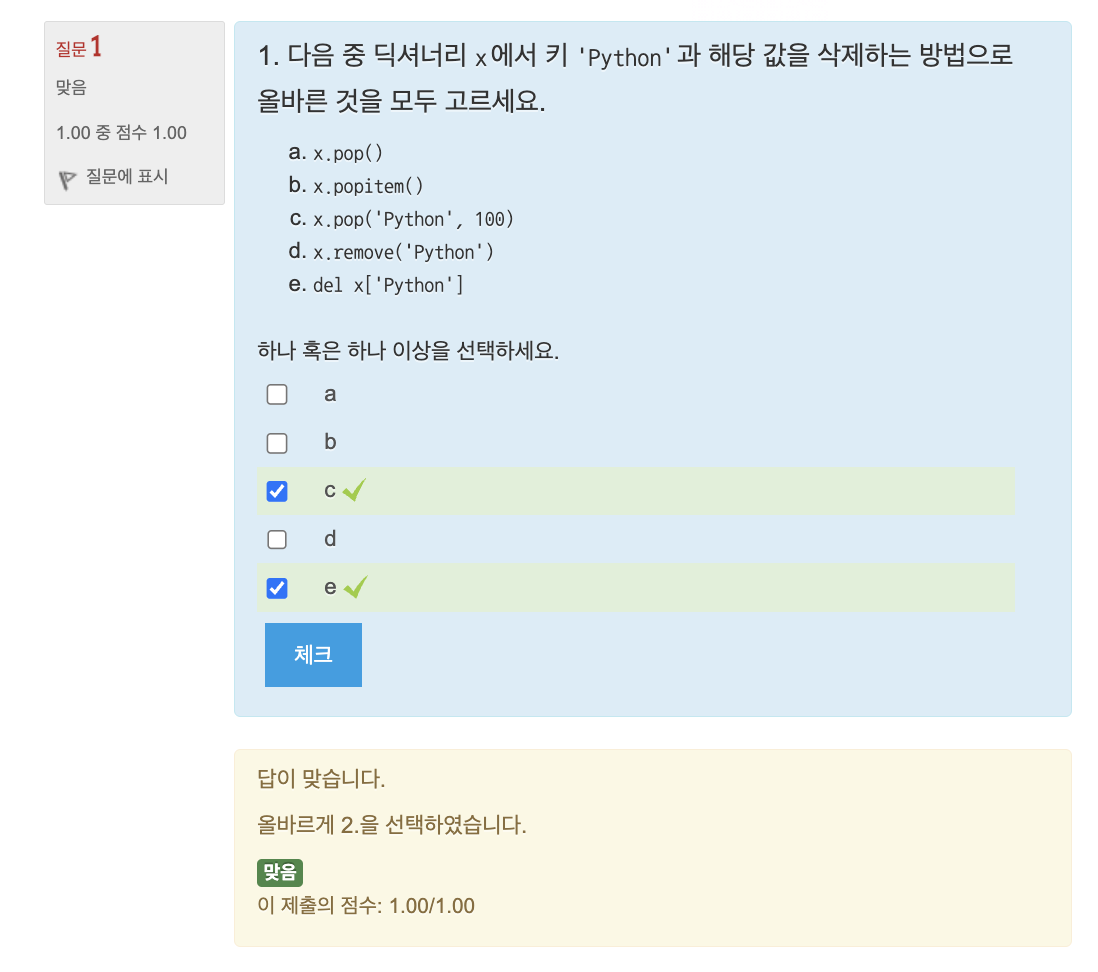
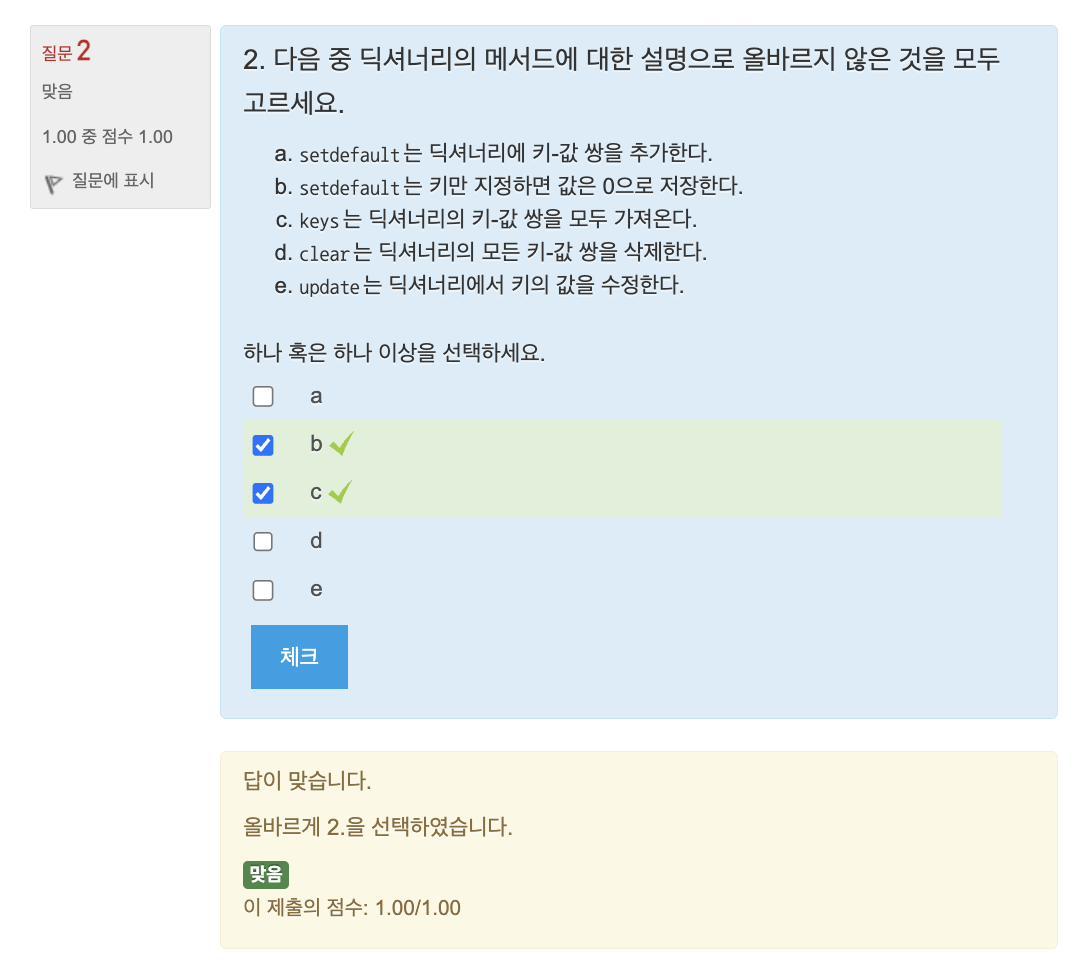
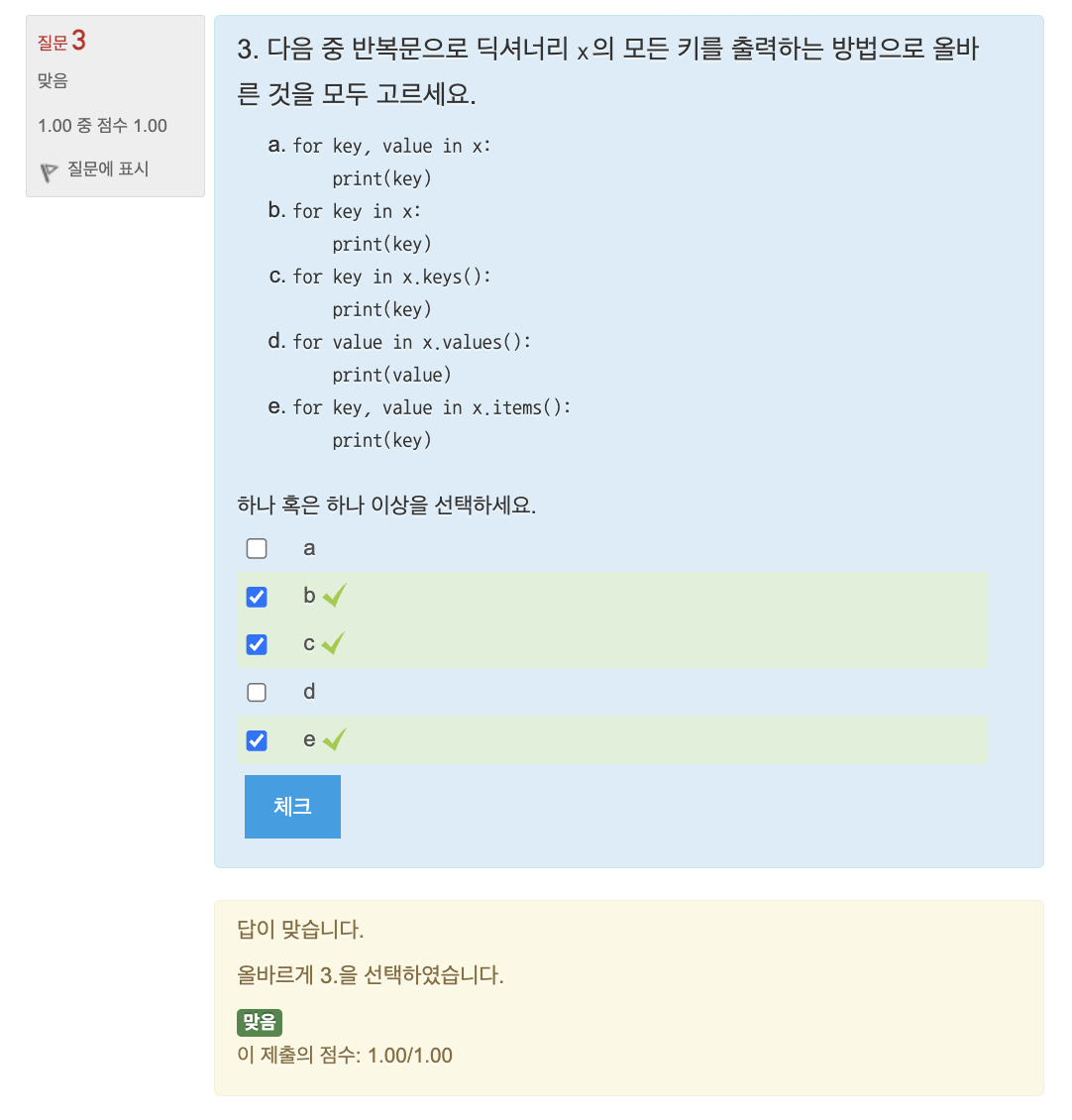
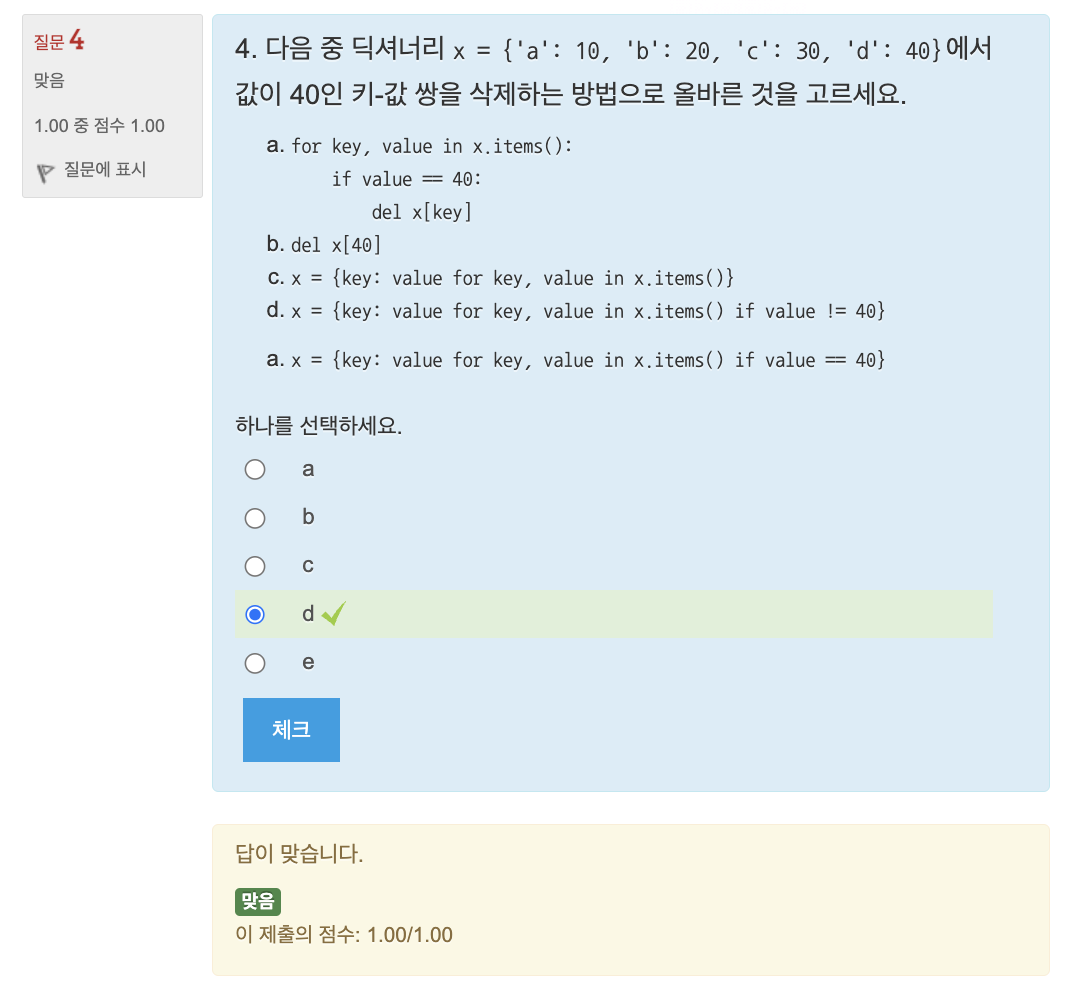
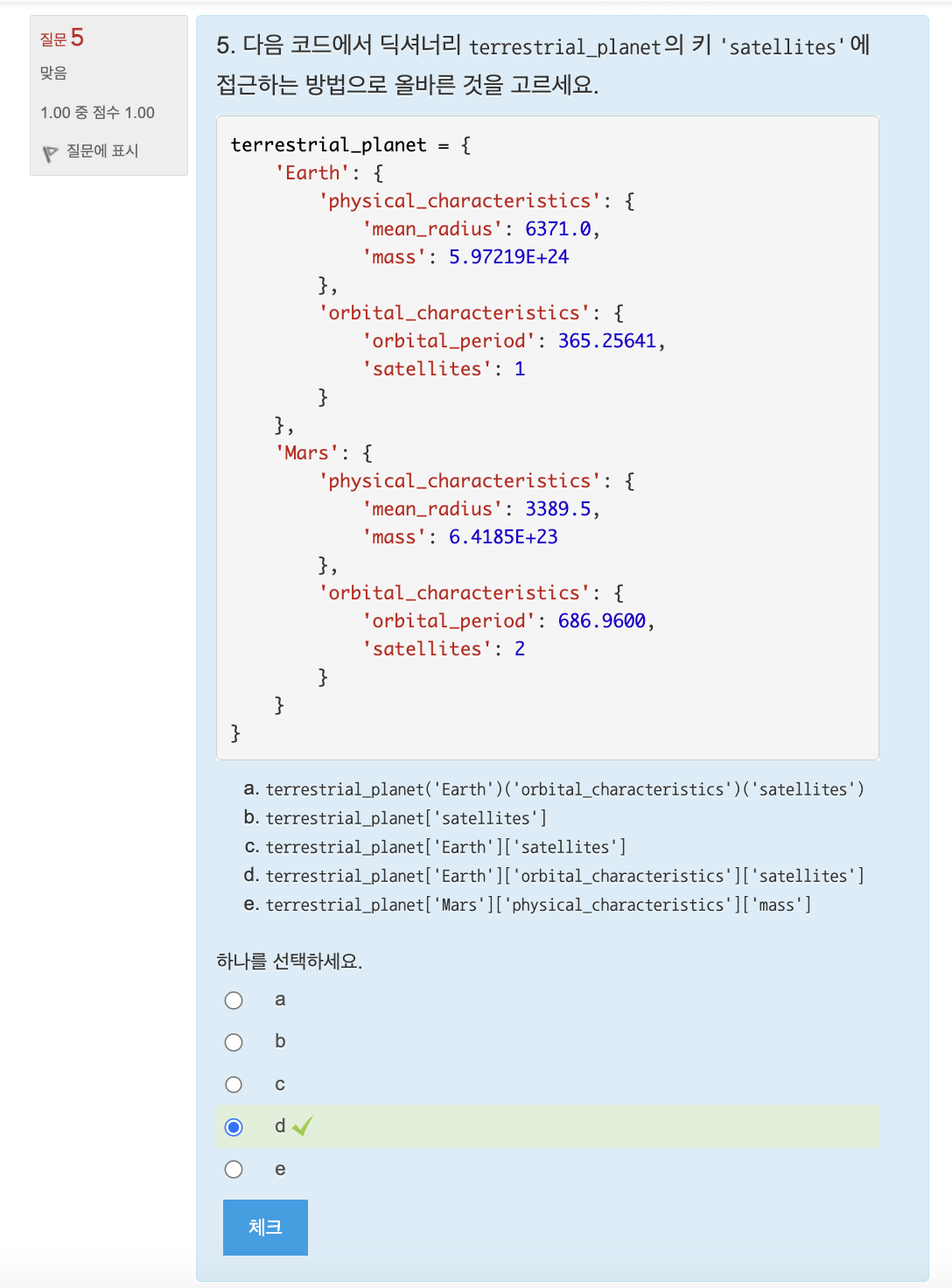

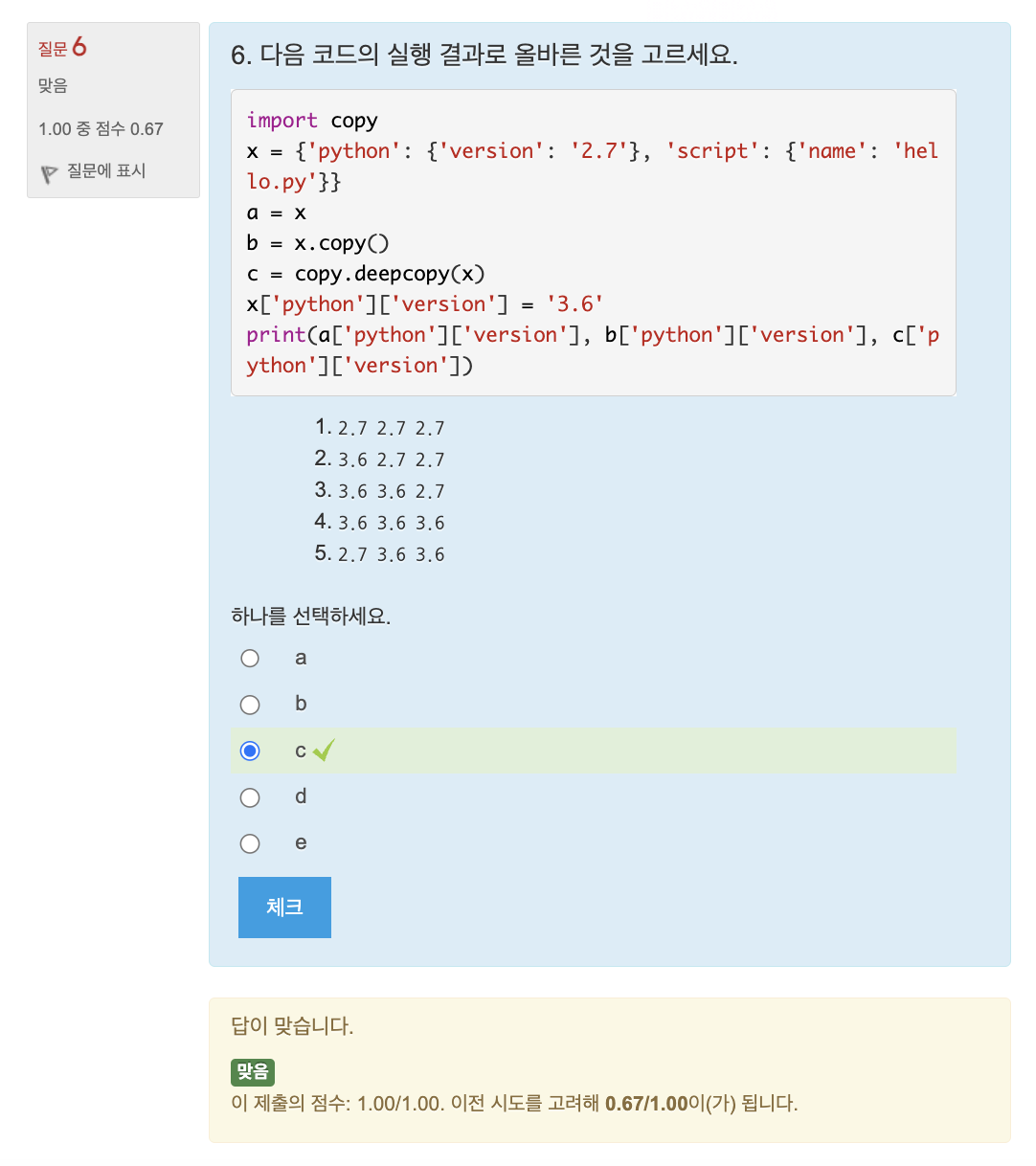
🔎 연습문제: 평균 점수 구하기
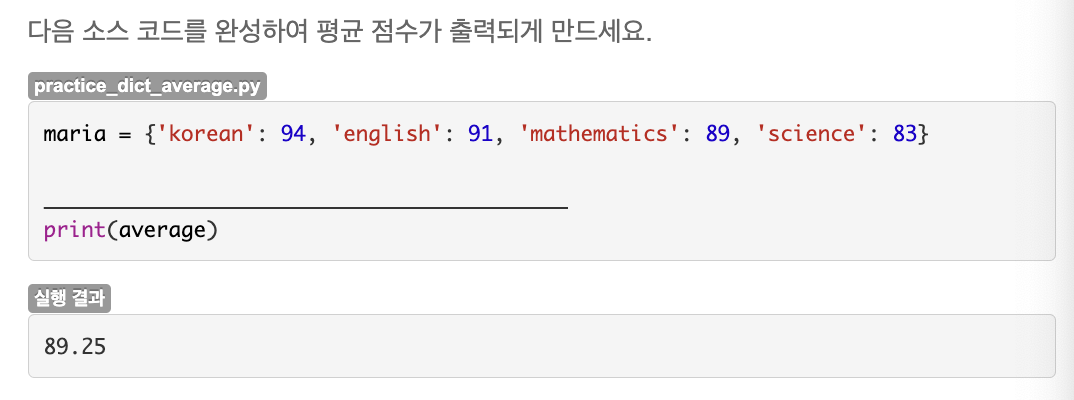
average = sum(maria.values()) / len(maria)🔎 심사문제: 딕셔너리에서 특정 값 삭제하기
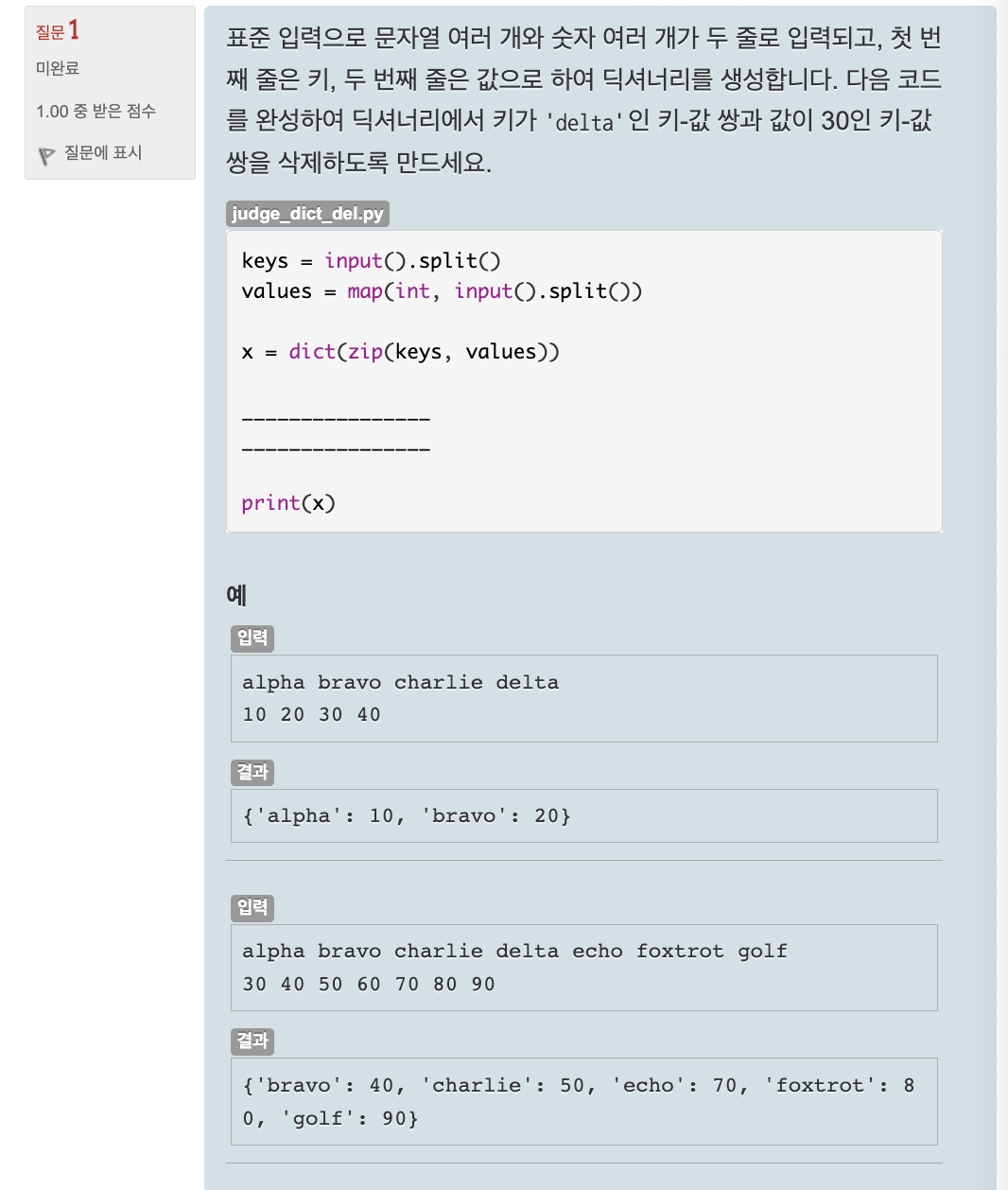
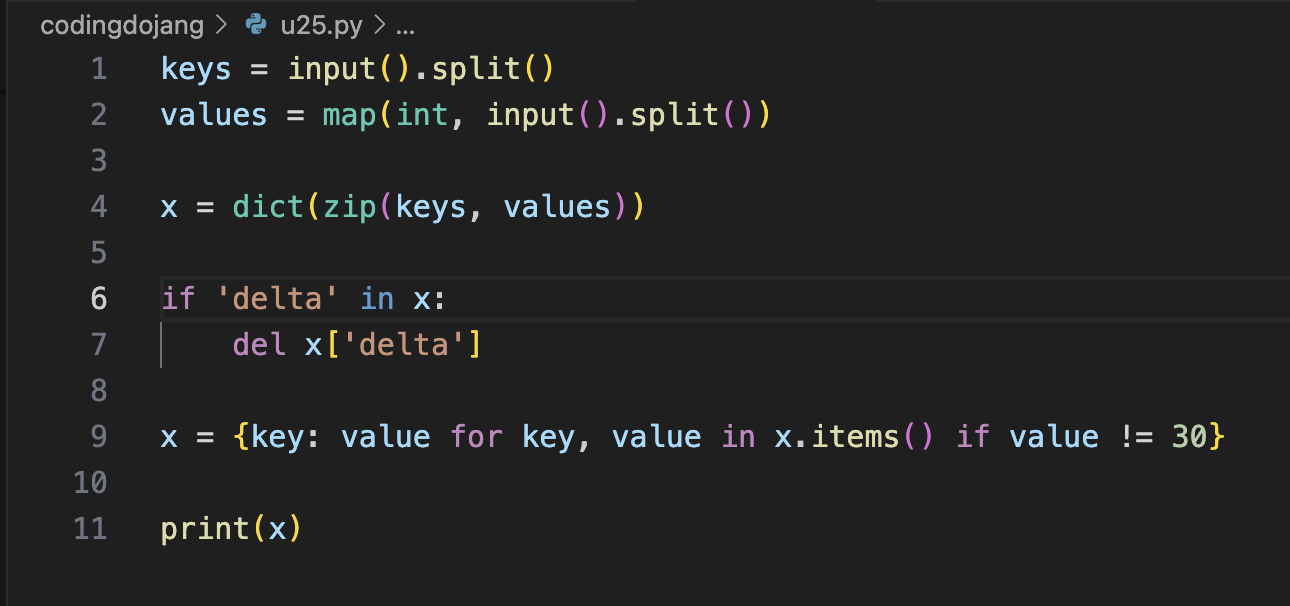

Unit 26. 세트 사용하기
세트 만들기
🔎 세트
세트 = {값1, 값2, 값3} # 세트 만들기
세트 = set(반복가능한객체) # 세트 만들기
값 in 세트 # 세트에 특정 값이 있는지 확인
값 not in 세트 # 세트에 특정 값이 없는지 확인
len(세트) # 세트의 요소 개수(길이) 구하기집합 연산 사용하기
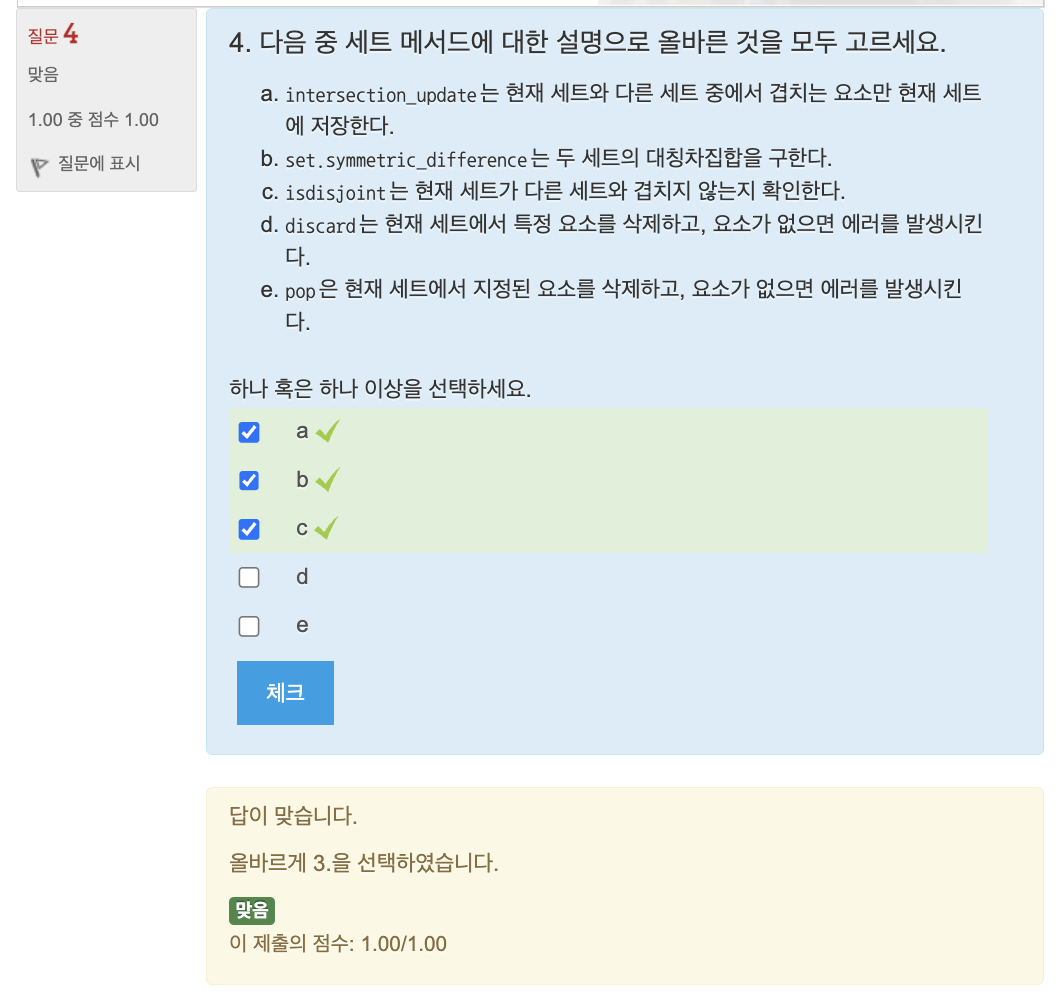
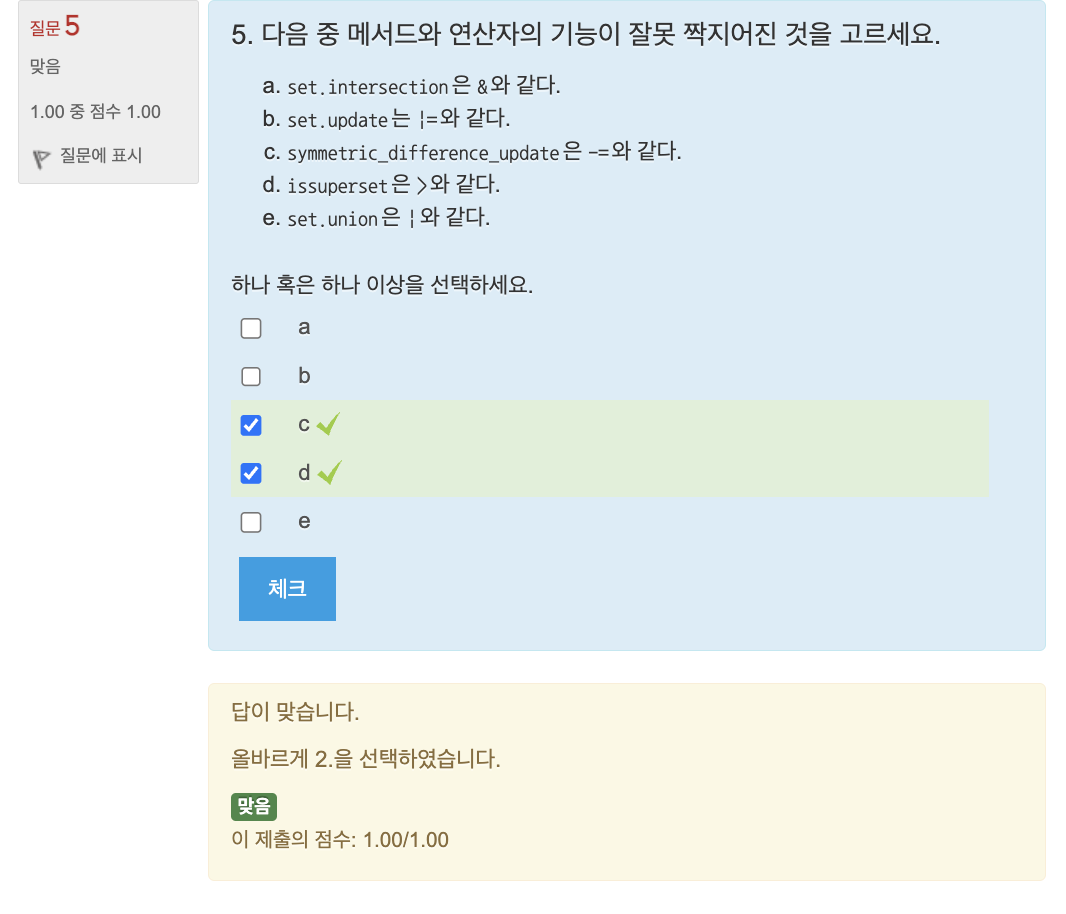
🔎 세트의 메서드와 집합 연산
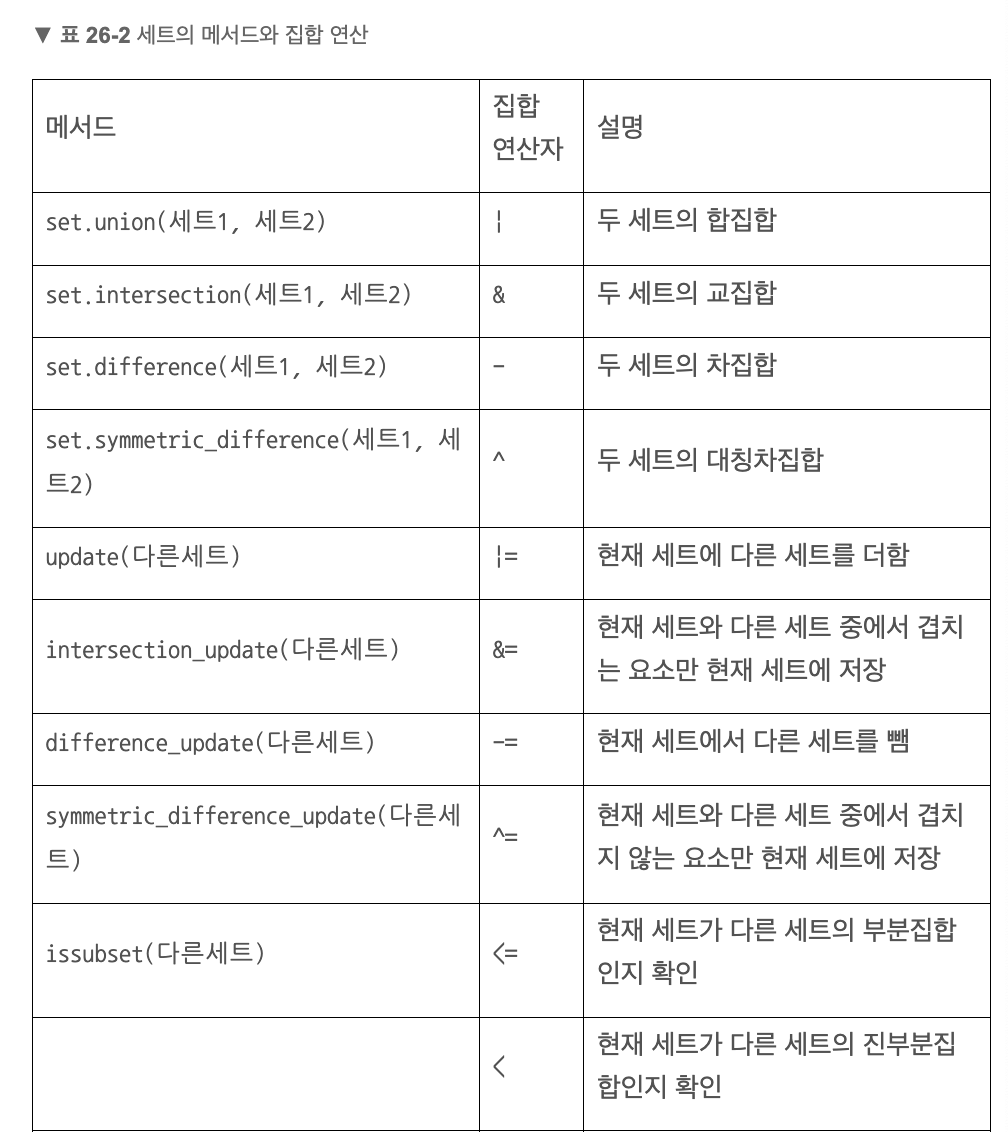
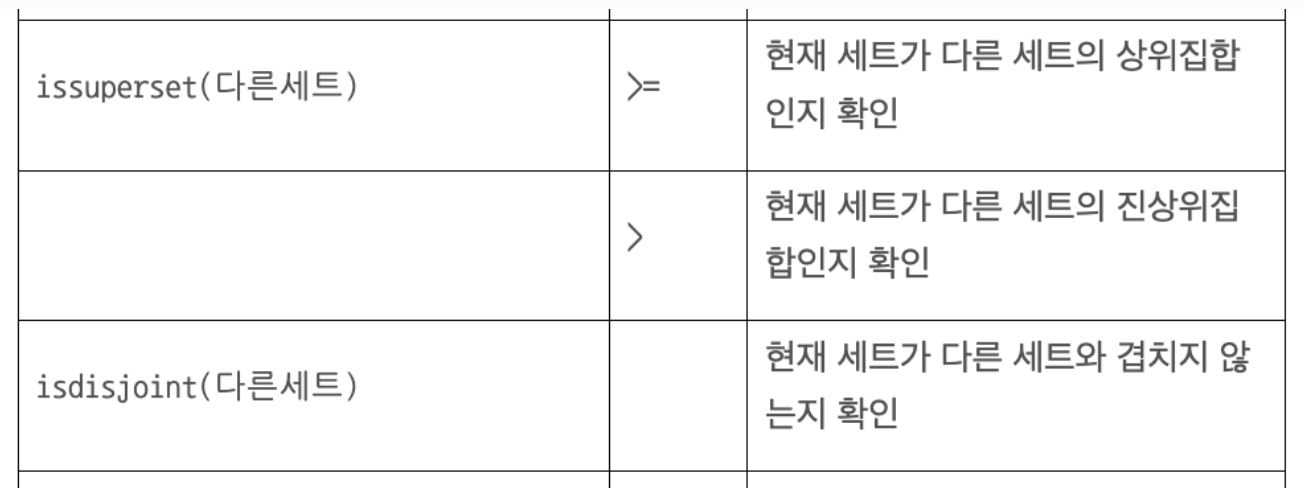
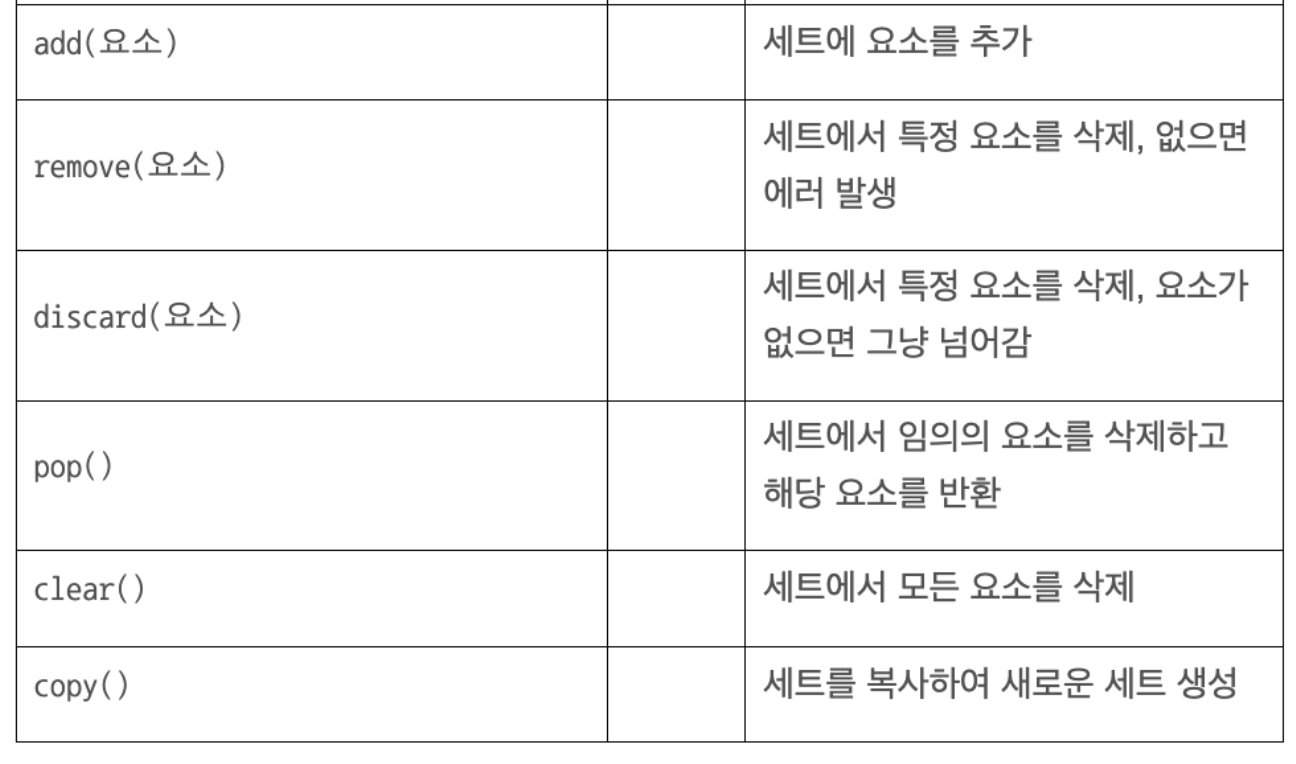
세트 조작하기
🔎 세트 조작하기
🔎 세트의 할당과 복사
- 세트 a와 b는 별개이기 때문에 -> 한쪽 값을 변경해도 다른 세트에 영향을 끼치지 ❌
>>> a = {1, 2, 3, 4}
>>> b = a.copy()
>>> b.add(5)
>>> a
{1, 2, 3, 4}
>>> b
{1, 2, 3, 4, 5}반복문으로 세트의 요소를 모두 출력하기
🔎 세트와 반복문
for 변수 in 세트:
반복할 코드세트 표현식 사용하기
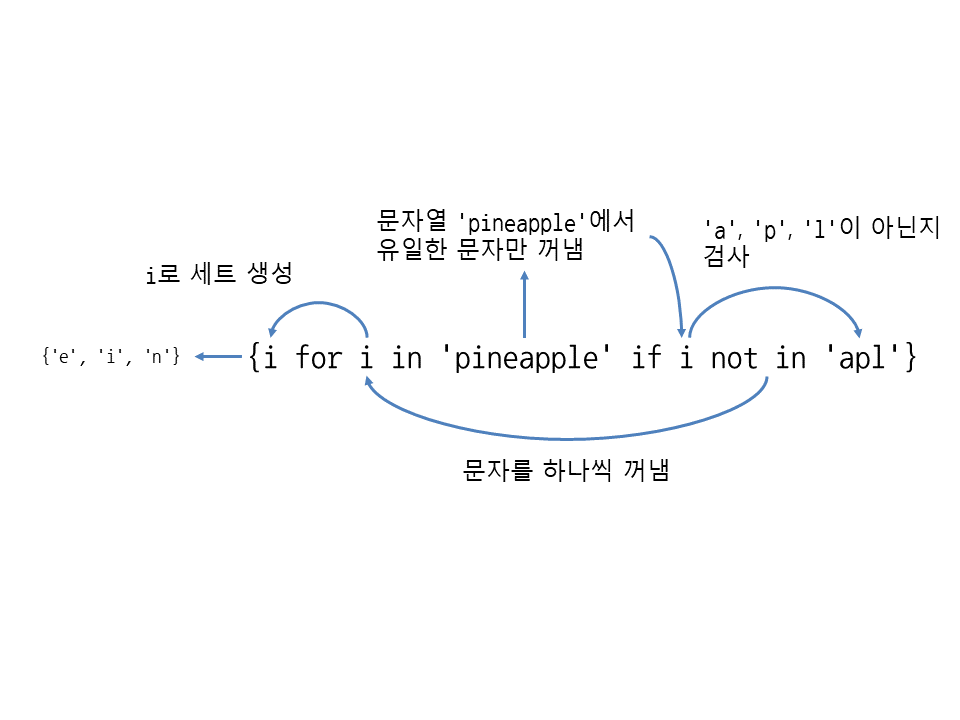
🔎 세트 표현식
- 세트 안 : 식, for 반복문, if 조건문 등 지정해 세트 생성


퀴즈
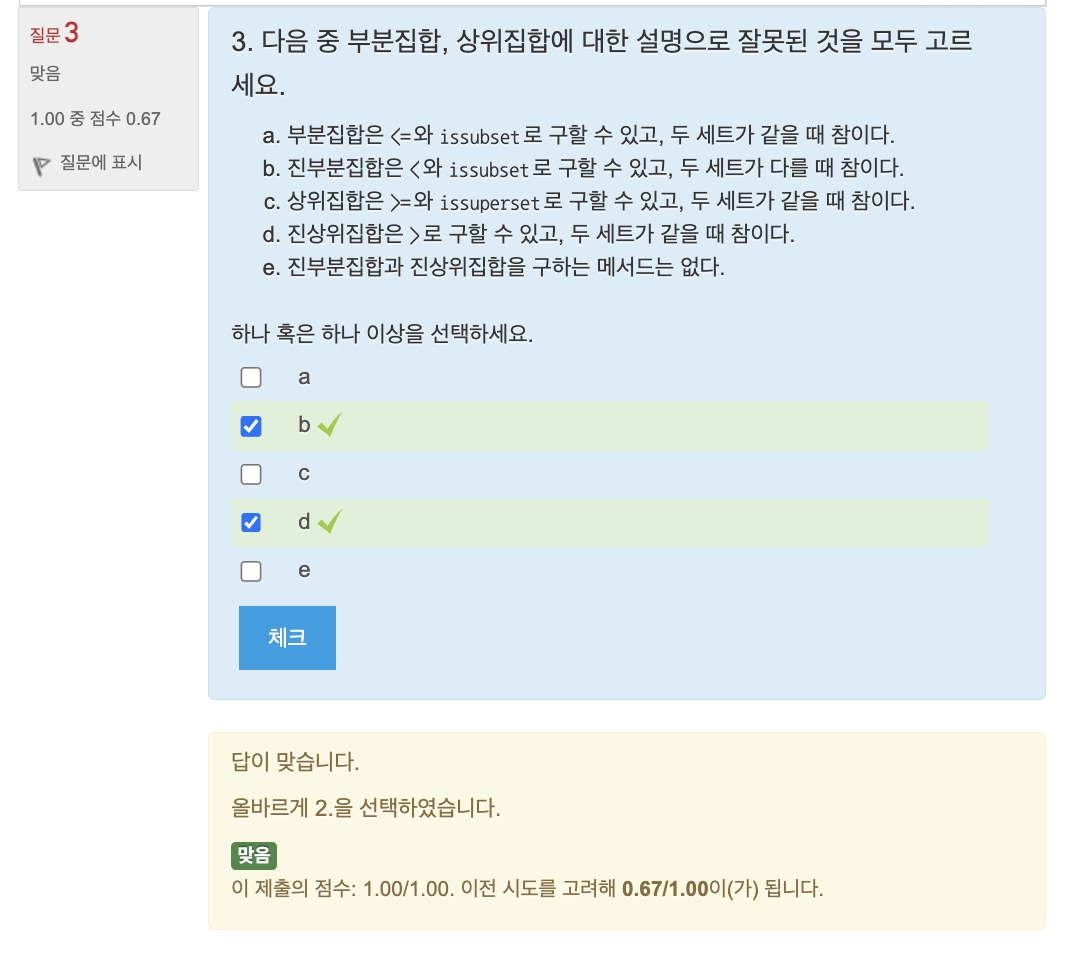
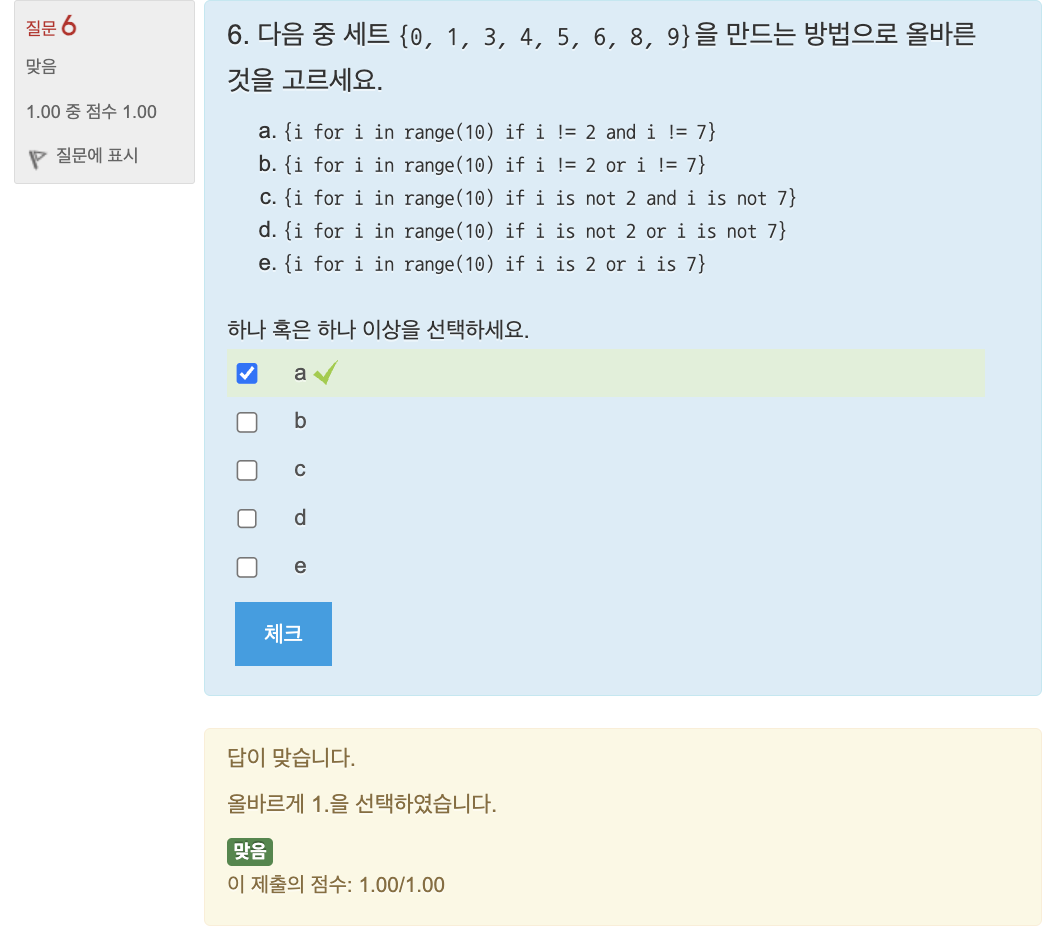
연습문제: 공배수 구하기

a = {i for i in range(1, 101) if i % 3 == 0}
b = {i for i in range(1, 101) if i % 5 == 0} 심사문제: 공약수 구하기
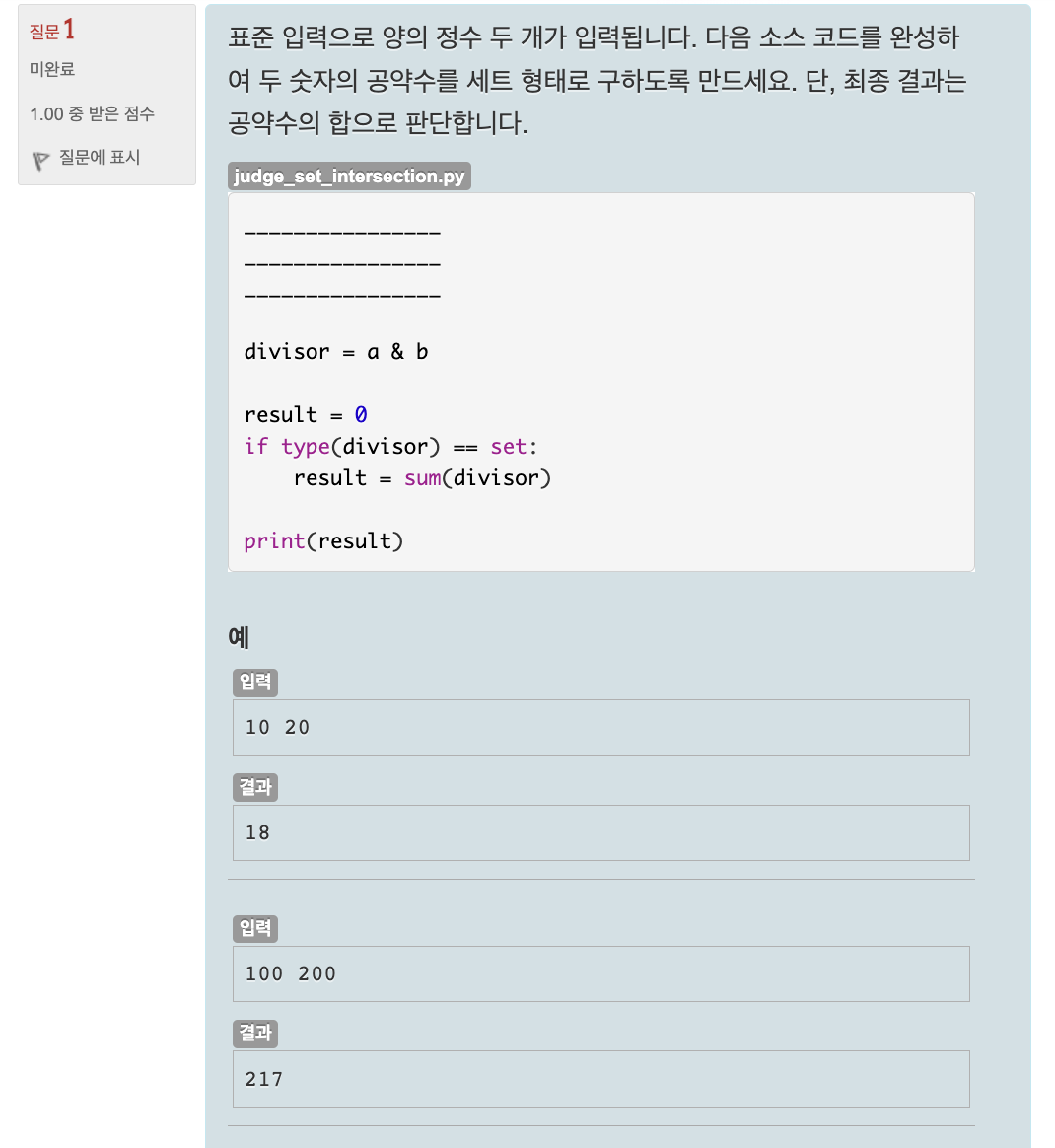
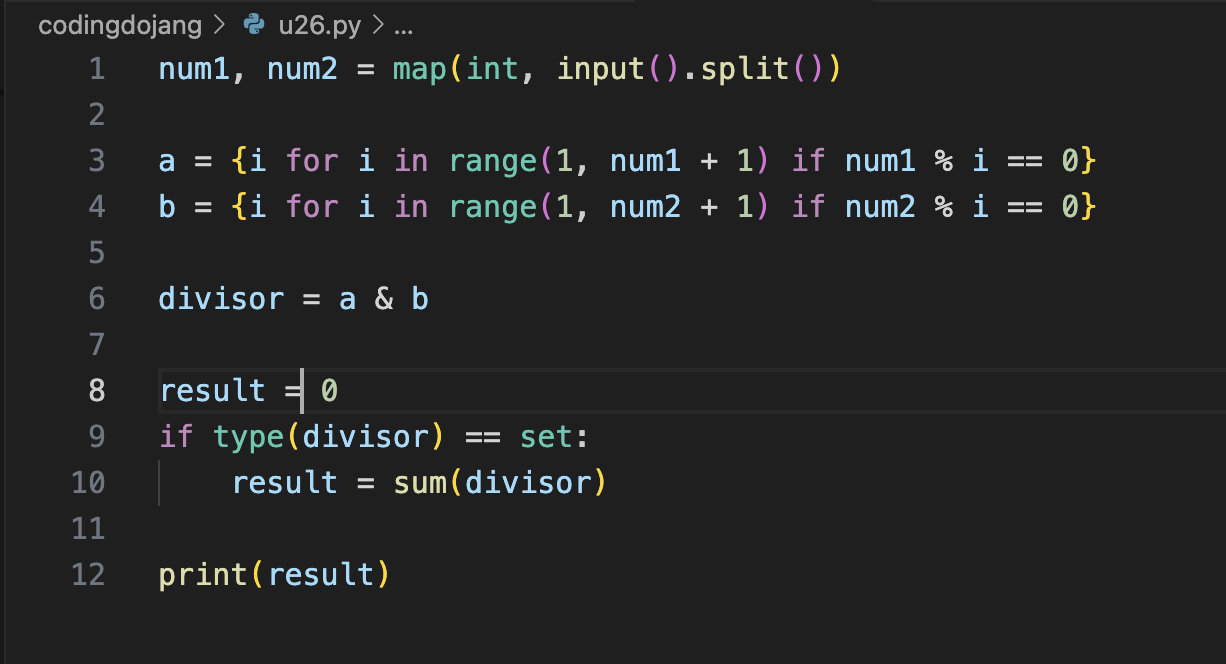

Unit 27. 파일 사용하기
파일에 문자열 쓰기, 읽기
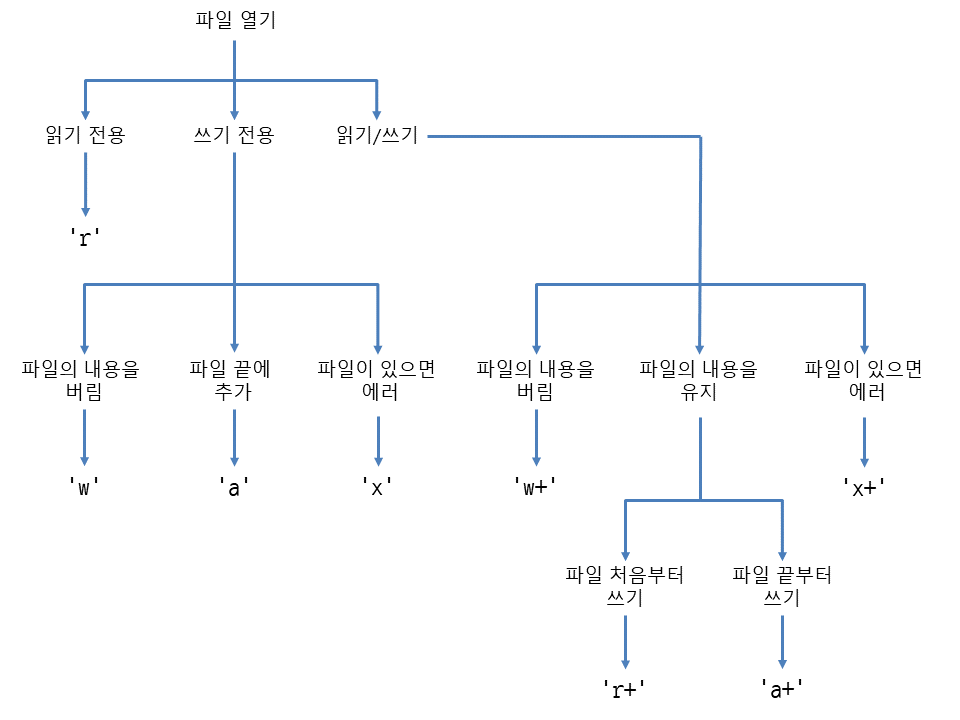
🔎 파일 열기, 닫기
- open 함수로 파일을 열어서 파일 객체 얻기
- 파일 읽기/쓰기 작업이 끝났다면 반드시 close로 파일 객체를 닫아주기
파일객체 = open(파일이름, 파일모드) # 파일 열기
파일객체.close() # 파일 객체 닫기
with open(파일이름, 파일모드) as 파일객체: # 파일을 사용한 뒤 자동으로 파일 객체를 닫아줌
코드문자열 여러 줄을 파일에 쓰기, 읽기
🔎 반복문으로 문자열 여러 줄을 파일에 쓰기
with open('hello.txt', 'w') as file: # hello.txt 파일을 쓰기 모드(w)로 열기
for i in range(3):
file.write('Hello, world! {0}\n'.format(i))🔎 리스트에 들어있는 문자열을 파일에 쓰기
lines = ['안녕하세요.\n', '파이썬\n', '코딩 도장입니다.\n']
with open('hello.txt', 'w') as file: # hello.txt 파일을 쓰기 모드(w)로 열기
file.writelines(lines)🔎 파일의 내용을 한 줄씩 리스트로 가져오기
with open('hello.txt', 'r') as file: # hello.txt 파일을 읽기 모드(r)로 열기
lines = file.readlines()
print(lines)🔎 파일의 내용을 한 줄씩 읽기
with open('hello.txt', 'r') as file: # hello.txt 파일을 읽기 모드(r)로 열기
line = None # 변수 line을 None으로 초기화
while line != '':
line = file.readline()
print(line.strip('\n')) # 파일에서 읽어온 문자열에서 \n 삭제하여 출력🔎 for 반복문으로 파일의 내용을 줄 단위로 읽기
with open('hello.txt', 'r') as file: # hello.txt 파일을 읽기 모드(r)로 열기
for line in file: # for에 파일 객체를 지정하면 파일의 내용을 한 줄씩 읽어서 변수에 저장함
print(line.strip('\n')) # 파일에서 읽어온 문자열에서 \n 삭제하여 출력💡 파일 객체는 이터레이터
- 변수 여러 개에 저장하는 언패킹(unpacking)도 가능
>> file = open('hello.txt', 'r') >> a, b, c = file >> a, b, c ('안녕하세요.\n', '파이썬\n', '코딩 도장입니다.\n')
파이썬 객체를 파일에 저장하기, 가져오기
🔎 피클링
import pickle
name = 'james'
age = 17
address = '서울시 서초구 반포동'
scores = {'korean': 90, 'english': 95, 'mathematics': 85, 'science': 82}
with open('james.p', 'wb') as file: # james.p 파일을 바이너리 쓰기 모드(wb)로 열기
pickle.dump(name, file)
pickle.dump(age, file)
pickle.dump(address, file)
pickle.dump(scores, file)s🔎 파일 모드
| 파일 모드 | 기능 | 설명 |
|---|---|---|
| 'r' | 읽기 전용 | 파일을 읽기 전용으로 열기. 단, 파일이 반드시 있어야 하며 파일이 없으면 에러 발생 |
| 'w' | 쓰기 전용 | 쓰기 전용으로 새 파일을 생성. 만약 파일이 있으면 내용을 덮어씀 |
| 'a' | 추가 | 파일을 열어 파일 끝에 값을 이어 씀. 만약 파일이 없으면 파일을 생성 |
| 'x' | 배타적 생성(쓰기) | 파일을 쓰기 모드로 생성. 파일이 이미 있으면 에러 발생 |
| 'r+' | 읽기/쓰기 | 파일을 읽기/쓰기용으로 열기. 단, 파일이 반드시 있어야 하며 파일이 없으면 에러 발생 |
| 'w+' | 읽기/쓰기 | 파일을 읽기/쓰기용으로 열기. 파일이 없으면 파일을 생성하고, 파일이 있으면 내용을 덮어씀 |
| 'a+' | 추가(읽기/쓰기) | 파일을 열어 파일 끝에 값을 이어 씀. 만약 파일이 없으면 파일을 생성. 읽기는 파일의 모든 구간에서 가능하지만, 쓰기는 파일의 끝에서만 가능함 |
| 'x+' | 배타적 생성(읽기/쓰기) | 파일을 읽기/쓰기 모드로 생성. 파일이 이미 있으면 에러 발생 |
| t | 텍스트 모드 | 파일을 읽거나 쓸 때 개행 문자 \n과 \r\n을 서로 변환, t를 생략하면 텍스트 모드 |
| b | 바이너리 모드 | 파일의 내용을 그대로 읽고, 값을 그대로 씀 |
🔎 파일 메서드
| 메서드 | 설명 |
|---|---|
| read() | 파일에서 문자열을 읽음 |
| write('문자열') | 파일에 문자열을 씀 |
| readline() | 파일의 내용을 한 줄 읽음 |
| readlines() | 파일의 내용을 한 줄씩 리스트 형태로 가져옴 |
| writelines(문자열리스트) | 파일에 리스트의 문자열을 씀, 리스트의 각 문자열에는 \n을 붙여주어야 함 |
| pickle.load(파일객체) | 파일에서 파이썬 객체를 읽음 |
| pickle.dump(객체, 파일객체) | 파이썬 객체를 파일에 저장 |
퀴즈
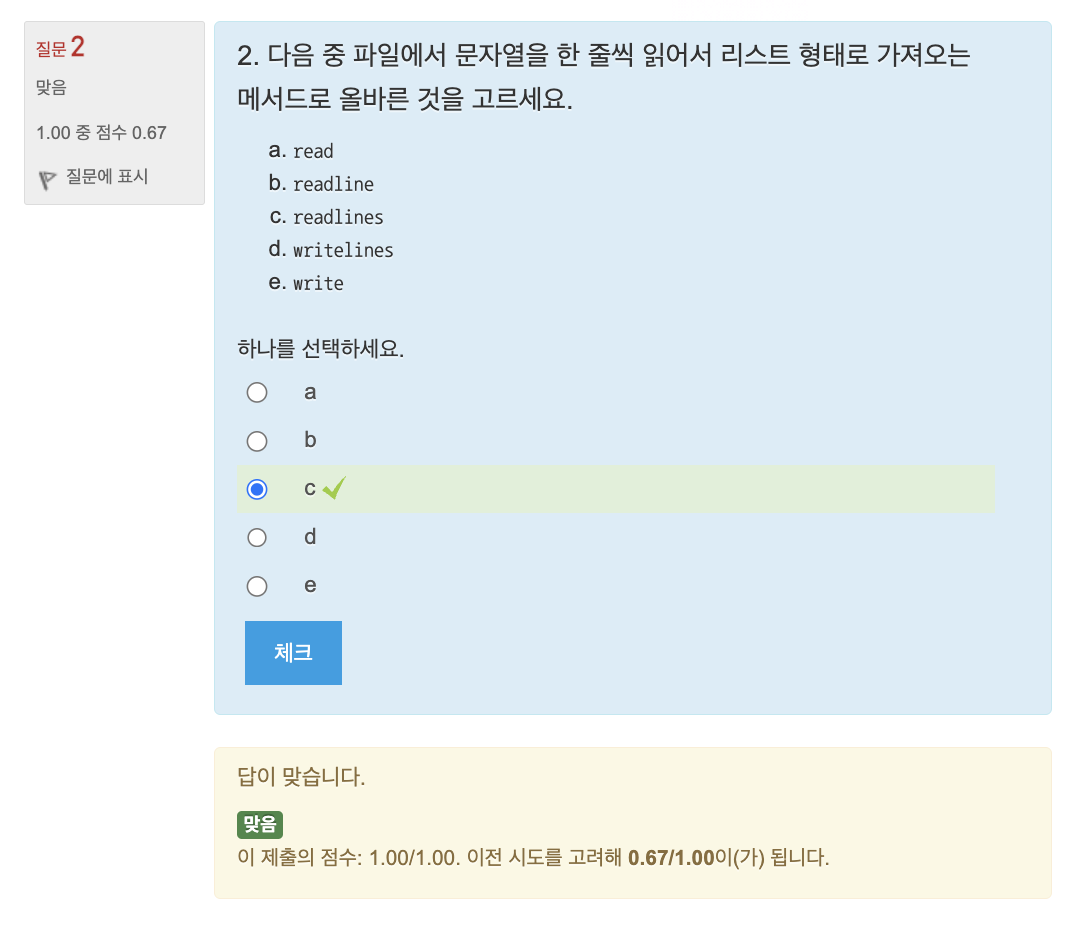
연습문제: 파일에서 10자 이하인 단어 개수 세기
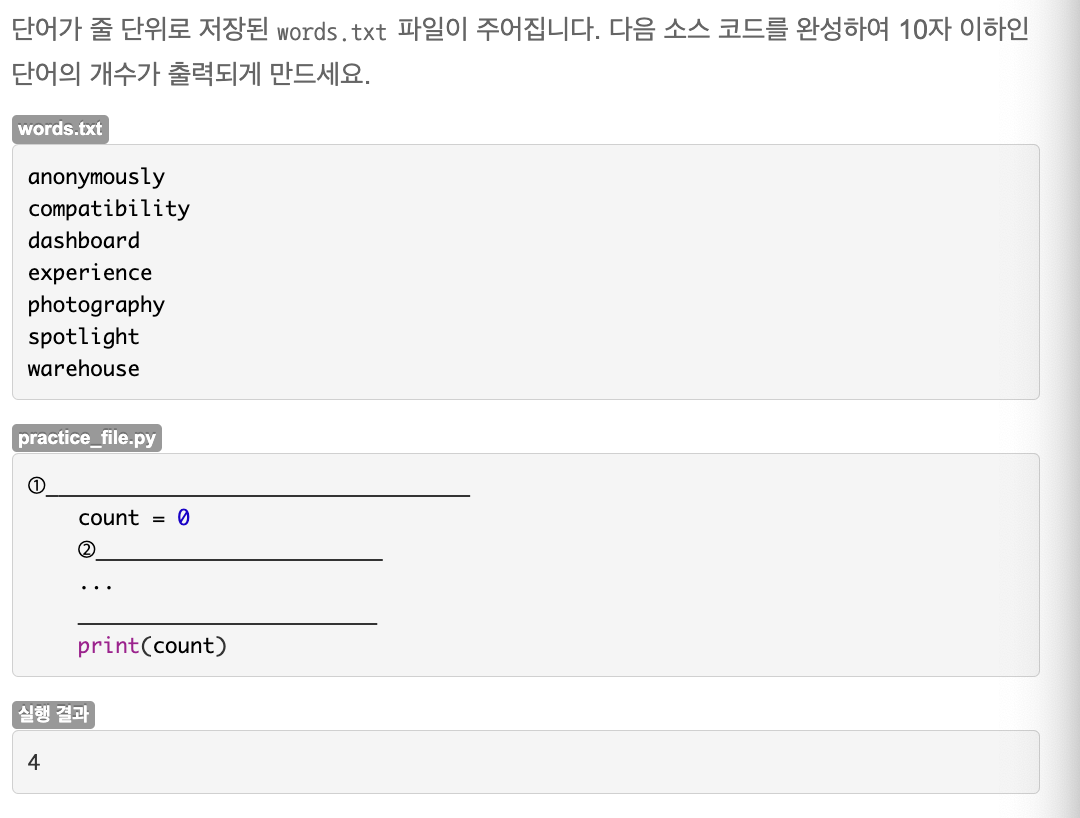
1) with open('words.txt', 'r') as file:
2)
words = file.readlines()
for word in words:
if len(word.strip('\n')) <= 10:
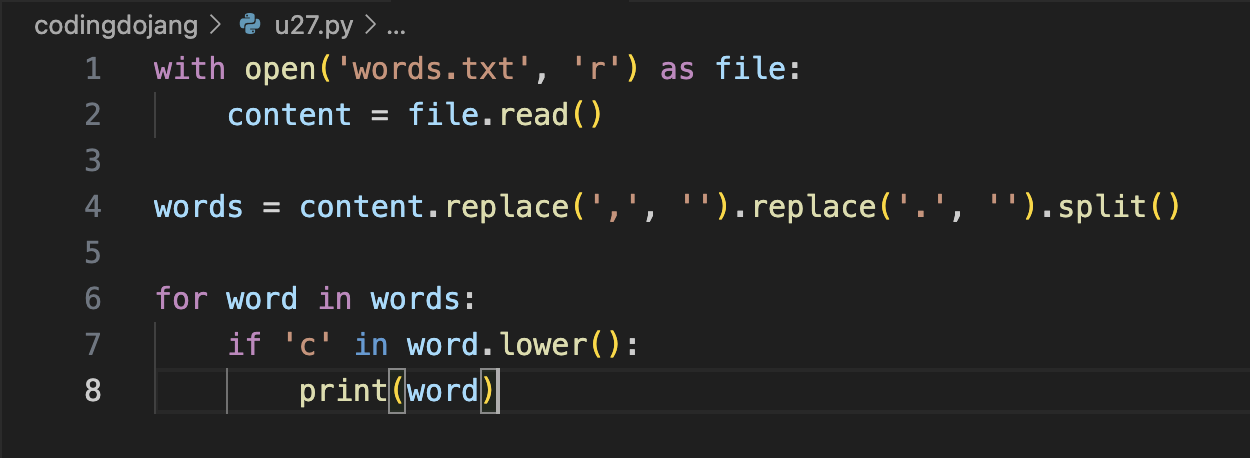
count += 1심사문제: 특정 문자가 들어있는 단어 찾기


Unit 28. 회문 판별과 N-gram 만들기
회문 판별하기
🔎 회문 판별하기
- 회문 : 순서를 거꾸로 읽어도 재대로 읽은 것과 같은 단어와 문장을 말함.
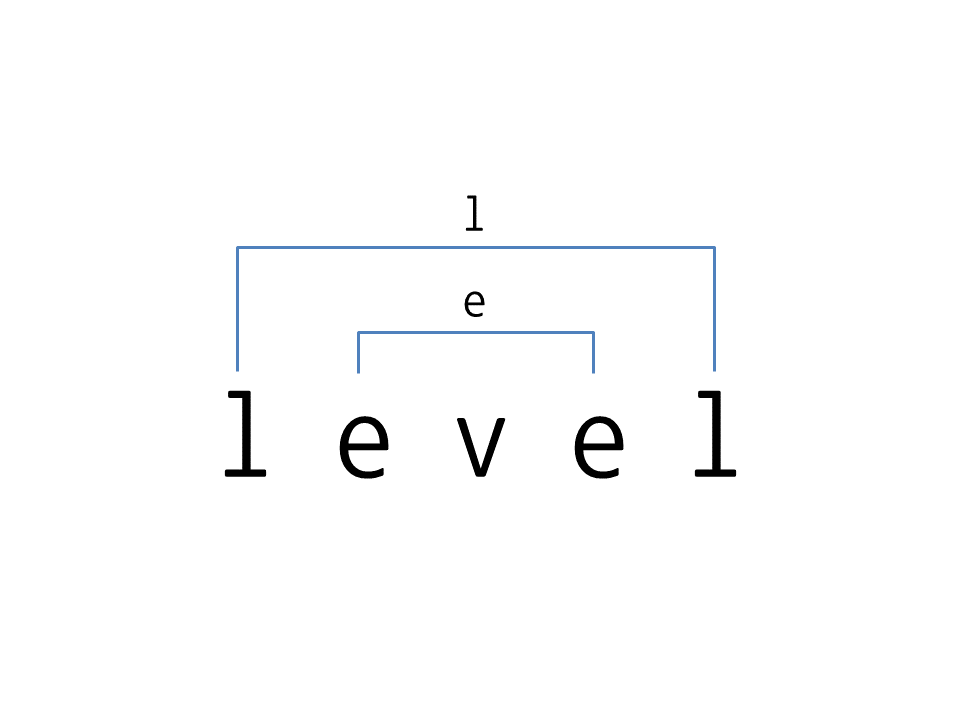
🔎 반복문으로 문자 검사하기
word = input('단어를 입력하세요: ')
is_palindrome = True # 회문 판별값을 저장할 변수, 초깃값은 True
for i in range(len(word) // 2): # 0부터 문자열 길이의 절반만큼 반복
if word[i] != word[-1 - i]: # 왼쪽 문자와 오른쪽 문자를 비교하여 문자가 다르면
is_palindrome = False # 회문이 아님
break
print(is_palindrome) # 회문 판별값 출력- 실행결과
단어를 입력하세요: level
True
----------------------
단어를 입력하세요: hello
False🔎 시퀀스 뒤집기로 문자 검사하기
word = input('단어를 입력하세요: ')
print(word == word[::-1]) # 원래 문자열과 반대로 뒤집은 문자열을 비교- 실행결과
단어를 입력하세요: level
True
단어를 입력하세요: hello
False🔎 리스트와 reversed 사용하기
>>> word = 'level'
>>> list(word) == list(reversed(word))
True- reversed로 문자열을 반대로 뒤집어서 list에 넣으면 -> 문자 순서가 반대로 된 리스트를 구할 수 있음.
>>> list(word)
['l', 'e', 'v', 'e', 'l']
>>> list(reversed(word))
['l', 'e', 'v', 'e', 'l']🔎 문자열의 join 메서드와 reversed 사용하기
>>> word = 'level'
>>> word == ''.join(reversed(word))
True>>> word
'level'
>>> ''.join(reversed(word))
'level'N-gram 만들기
🔎 N-gram
- N-gram : 문자열에서 N개의 연속된 요소를 추출하는 방법
- ex) 'Hello'라는 문자열을 문자(글자) 단위 2-gram으로 추출
He
el
ll
lo🔎 반복문으로 N-gram 출력하기
text = 'Hello'
for i in range(len(text) - 1): # 2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복함
print(text[i], text[i + 1], sep='') # 현재 문자와 그다음 문자 출력- 실행결과
He
el
ll
lo- 단어 단위 N-gram
text = 'this is python script'
words = text.split() # 공백을 기준으로 문자열을 분리하여 리스트로 만듦
for i in range(len(words) - 1): # 2-gram이므로 리스트의 마지막에서 요소 한 개 앞까지만 반복함
print(words[i], words[i + 1]) # 현재 문자열과 그다음 문자열 출력- 실행결과
this is
is python
python script🔎 zip으로 2-gram 만들기
text = 'hello'
two_gram = zip(text, text[1:])
for i in two_gram:
print(i[0], i[1], sep='')- 실행결과
He
el
ll
lo🔎 zip과 리스트 표현식으로 N-gram 만들기
>>> text = 'hello'
>>> [text[i:] for i in range(3)]
['hello', 'ello', 'llo']- 리스트 ['hello', 'ello', 'llo']를 zip에 넣기
>>> list(zip(['hello', 'ello', 'llo']))
[('hello',), ('ello',), ('llo',)]- zip에 리스트의 각 요소를 콤마로 구분해서 넣으려면 -> 리스트 앞에
*를 붙이기
>>> list(zip(*['hello', 'ello', 'llo']))
[('h', 'e', 'l'), ('e', 'l', 'l'), ('l', 'l', 'o')]연습문제: 단어 단위 N-gram 만들기

1) text.split()
2) len(words) < n
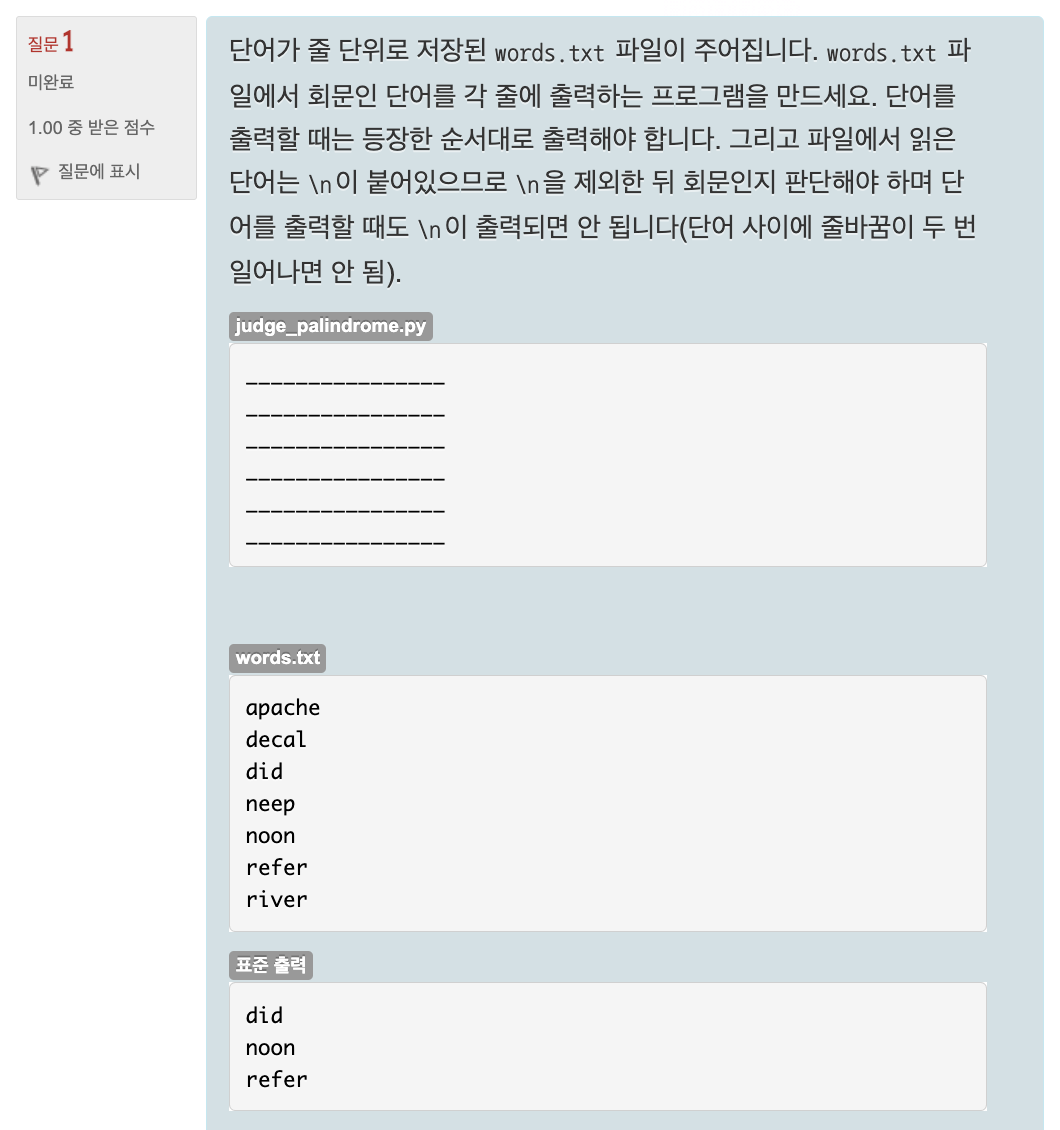
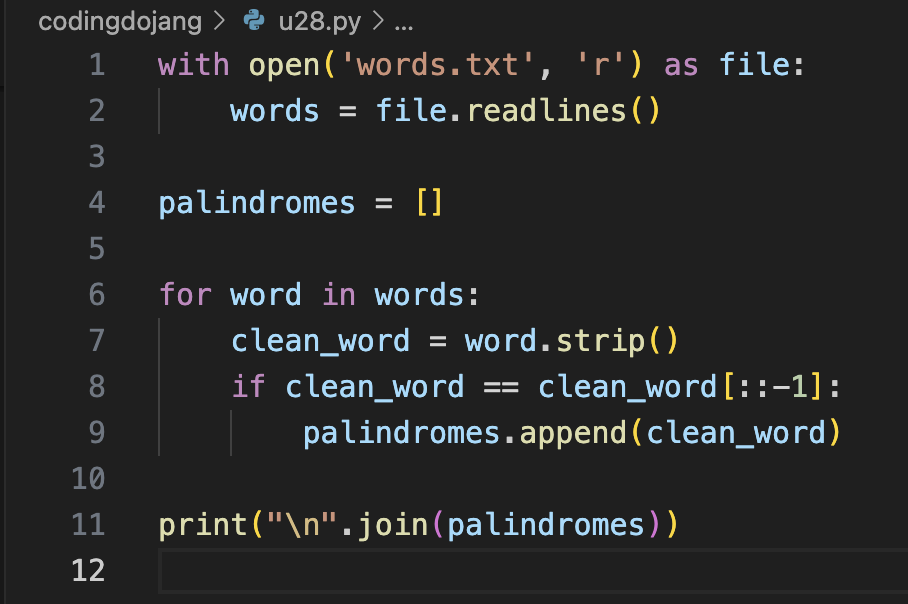
3) zip(*[words[i:] for i in range(n)])심사문제: 파일에서 회문인 단어 출력하기


언젠가 내 코드로 세상에 기여할 수 있도록, Data Science&BE 개발 기록 노트☘️