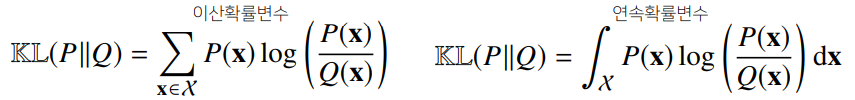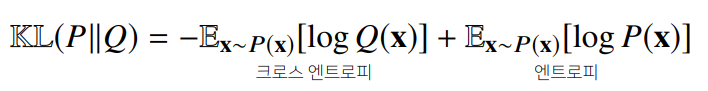2021 부스트캠프 Day10
[Day 10] 시각화 / 통계학
Data Visualization - Graph tools
matplotlib
- 파이썬의 대표적인 시각화 도구
- 다양한 graph 지원 Pandas 연동
- pyplot 객체를 사용하여 데이터를 표시
- pyplot 객체에 그래프들을 쌓은 다음 flush
- 최대 단점 argument를 kwargs 반듬
- 고정된 argument가 없어서 alt+tab으로 확인 어려움
- Graph는 원래 figure 객체에 생성됨
- pyplot 객체 사용시, 기본 figure에 그래프가 그려짐
Figure & Axes
- Matplotlib은 Figure안에 Axes로 구성
- Figure 위에 여러 개의 Axes를 생성
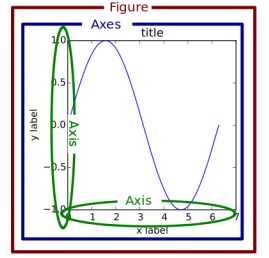
fig = plt.figure() # figure 반환
fig.set_size_inches(10,5) # 크기 지정
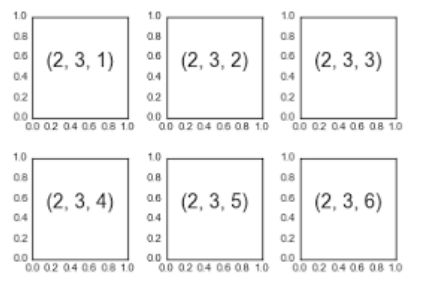
ax_1 = fig.add_subplot(1,2,1) # 두개의 plot 생성
ax_2 = fig.add_subplot(1,2,2) # 두개의 plot 생성
ax_1.plot(X_1, Y_1, c="b")
ax_2.plot(X_2, Y_2, c="g")
plot.show() # show & flushsubplots
- subplot의 순서로 grid로 작성
set color
- color 속성을 사용
- float: 흑백, rgb color, predefined color 사용
set linestyle
ls또는linestyle사용
plt.plot(X_1, Y_1, c="b", linestyle="dashed")
plt.plot(X_1, Y_1, c="r", ls="dotted")
plt.show()set title
- pyplot에 title함수 사용, figure의 subplot별 입력 가능
- latex 타입의 표현도 가능(수식표현 가능)
plt.title("Two lines")
plt.title('$y = \\frac{ax+b){test}$')set legend
- legend 함수로 범례를 표시함, loc위치 등 속성지정
plt.legend(shadow=True, fancybox=True, loc="lower right")set grid & xylim
- Graph 보조선을 긋는 grid와 xy축 범위 한계를 지정
plt.grid(True, lw=0.4, ls="--", c=".90")
plt.xlim(-100, 200)
plt.ylim(-200,200)matplotlib graph
scatter
scatter함수 사용,marker:scatter모양 지정
plt.scatter(data_1, data_2, c="b", marker="x")s: 데이터의 크기를 지정, 데이터의 크기 비교 가능
colors = np.random.rand(N)
plt.scatter(x, y, s=area, c=colors, alpha=0.5)bar chart
bar함수 사용
plt.bar(x, y, color="b", width=0.25)histogram
plt.hist(x, bins=100)boxplot
plt.boxplot(data)Seaborn : statistical data visualization
seaborn
- 기존 mtplotlib에 기본 설정을 추가
- 복잡한 그래프를 간단하게 만들 수 있는 wrapper
- 간단한코드 + 예쁜 결과
basic plots
- matplotlib와 같은 기본적인 plot
- 손쉬운 걸정으로 데이터 산출
- lineplot, scatterplot, countplot 등
sns.lineplot(x="total_bill", y="tip", data=tips)
sns.scatterplot(x="total_bill", y="tip", data=tips)
sns.countplot(x="smoker", data=tips)
sns.barplot(x="day", y="tip", data=tips)
sns.displot(tips["total_bill"])predefined plots
- Viloinplot : boxplot에 distribution을 함께 표현
- Stripplot : scatter와 categroy 정보를 함께 표현
- Swarmplot : 분포와 함께 scatter를 함께 표현
- Pointplot : category별로 numeric의 평균, 신뢰구간 표시
- regplot : scatter + 선형함수를 함께 표시
predefined multiple plots
- replot : Numeric 데이터 중심의 분포 / 선형 표시
- catplot : category 데이터 중심의 표시
- FacetGrid : 특정 조건에 따른 다양한 plot을 grid로 표시
- pairplot : 데이터 간의 상관관계 표시
- Implot : regression모델과 category데이터를 함께 표시
Mathematics for Artificial Intelligence : 통계학 맛보기
모수
-
통계적 모델링은 적절한 가정 위에서 확률분포를 추정(inference)하는 것이 목표이며, 기계학습과 통계학이 공통적으로 추구하는 목표
-
그러나 유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정
-
예측모형의 목적은 분포를 정확하게 맞추는 것보다는 데이터와 추정 방법의 불확실성을 고려해서 위험을 최소화하는 것
-
데이터가 특정 확률분포를 따른다고 선험적으로(a priori) 가정한 후 그 분포를 결정하는 모수(parameter)를 추정하는 방법을 모수적(parametrtic) 방법론이라 함.
-
특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수(nonparametric)방법론 이라 부른다. -> 기계학습의 많은 방법론은 비모수 방법론에 속함, 비모수 방법론이라고 모수가 없다라고 생각하면 안된다.
확률분포 가정하기
-
우선 히스토그램을 통해 모양을 관찰
-
데이터가 2개의 값(0 또는 1) 만 가지는 경우 -> 베르누이분포
-
데이터가 n개의 이산적인 값을 가지는 경우 -> 카테고리분포
-
데이터가 [0,1] 사이에서 값을 가지는 경우 -> 베타분포
-
데이터가 0이상의 값을 가지는 경우 -> 감마분포, 로그정규분포 등
-
데이터가 R전체에서 값을 가지는 경우 -> 정규분포, 라플라스분포 등
-
기계적으로 확률분포를 가정해서는 안되며, 데이터를 생성하는 원리를 먼저 고려하는 것이 원칙
데이터로 모수 추정
-
데이터의 확률분포를 가정했다면 모수를 추정해볼 수 있다.
-
정규분포의 모수는 평균 과 분산 으로 이를 추정하는 통계량(statistic)은 다음과 같다:
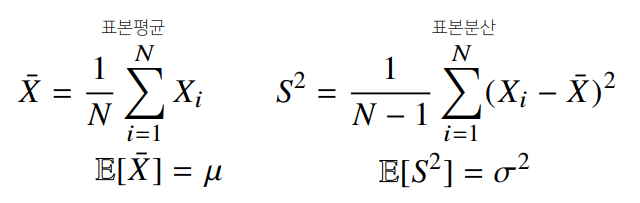
-
통계량의 확률 분포를 표집분포(samplign distribution)
-
중심극한정리(Central Limit Theorem) : 표본평균의 표집분포가 커질수록 정규분포를 따른다. 모집단의 분포가 정규분포를 따르지 않아도 성립
최대가능도 추정법(MLE : maximunm likelihood estimation)
-
표본평균이나 표본분산은 중요한 통게량이지만 확률분포마다 사용하는 모수가 다르므로 적절한 통계량이 달라지게 된다.
-
이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나
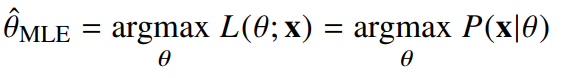
-
데이터 집합 가 독립적으로 추출되었을 경우 로그가능도를 최적화
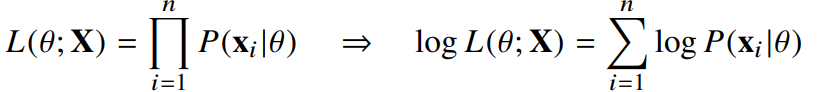
왜 로그가능도를 사용?
-
로그가능도를 최적화하는 모수는 가능도를 최적화하는 MLE가된다.
-
데이터의 숫자가 수억 단위가 된다면 컴퓨터의 정확도로는 가능도를 계산하는 것은 불가능
-
데이터가 독립일 경우, 로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀 수 있기 때문에 컴퓨터로 연산이 가능해진다.
-
경사하강법으로 가능도를 최적화할 때 미분 연산을 사용하게 되는데, 로그가능도를 사용하면 연산량을 에서 으로 줄여준다.
-
대게의 손실함수의 경우 경사하강법을 사용하므로 음의 로그가능도(negative log-likelihood)를 최적화
딥러닝에서 최대가능도 추정법
-
최대가능도 추정법을 이용해서 기계학습 모델을 학습할 수 있다.
-
딥러닝 모델의 가중치를 = 라 표기했을 때 분류 문제에서 소프트맥스 벡터는 카테고리분포의 모수 를 모델링
-
원핫벡터로 표현한 정답레이블 = 을 관찰데이터로 이용해 확률분포인 소프트맥스 벡터의 로그가능도를 최적화
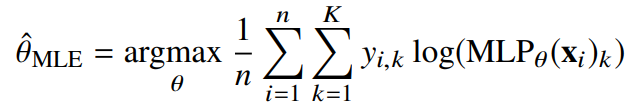
확률분포의 거리
-
기계학습에서 사용되는 손실함수들은 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도
-
데이터공간에 두 개의 확률분포 가 있을 경우 두 확률분포 사이의 거리(distance)를 계산할 때 다음과 같은 함수들을 이용
- 총변동 거리 (Total Variation Distance, TV)
- 쿨백-라이블러 발산 (Kullback-Leibler Divergence, KL)
- 바슈타인 거리 (Wasserstein Distance)
쿨백-라이블러 발산
- 분류 문제에서 정답 레이블을 , 모델 예측을 라 두면 최대가능도 추정법은 쿨백-라이블러 발산을 최소화하는 것과 같다.