mysql 설치
-
다음 명령어로 mysql repository를 설치해줍니다.
yum install https://dev.mysql.com/get/mysql80-community-release-el7-6.noarch.rpmmysql 패키지를 손쉽게 설치, 업데이트 관리가 가능
-
mysql 8버전을 설치해준다.
yum install mysql-server -
GPG key retrieval failed라는 오류가 뜨면 다음과 같이 해결한다.
vi /etc/yum.repos.d/mysql-community.repo '[mysql80-community]' 항목의 'gpgcheck' 옵션을 'gpgcheck=0' 이렇게 수정한다.보안 절차를 생략하여 설치 하는 것
-
다시 mysql을 설치를 진행해준다.
mysql-server -
mysql이 정상적으로 설치되었는지 확인한다.
mysql -V -
mysql을 실행시켜준다.
systemctl start mysqld systemctl enable mysqld -
mysql 로그인을 위해 임시 password를 확인한다.
grep 'temporary password' /var/log/mysqld.log -
확인된 password로 로그인을 한다.
mysql -u root -p -
로그인이 되었으면 root 비밀번호를 바꿔준다.
ALTER USER 'root'@'localhost' IDENTIFIED BY '원하는 비밀번호'; -
변경 사항을 적용시킨다.
flush privileges재시작 없이 수정된 환경 설정 적용해준다.
-
hive 계정을 만들어준다.
CREATE USER 'hive'@'%' IDENTIFIED BY 'Hivetest1!';새로운 데이터베이스 사용자 'hive'를 생성하고 어떤 호스트에서든 접속을 허용할 수 있도록 '%'로 설정해준다.
-
사용자 'hive'에 필요한 권한을 부여해준다.
GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';'hive' 사용자는 'metastore' 데이터베이스의 모든 테이블에 대해 모든 권한을 갖게 됩니다. 다른 데이터베이스에는 접근이나 조작할 수 없다.
-
변경 사항을 적용시킨다.
FLUSH PRIVILEGES; -
mysql을 빠져 나온다.
exit;
Hive 설치
-
hive를 설치할 디렉토리를 만들어준다.
cd /opt mkdir hive cd hive -
hive를 설치한다.
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz원하는 버전은 https://archive.apache.org/dist/hive/ 에 들어가 찾아볼 수 있다.
-
압축을 해제해준다.
tar xzf apache-hive-3.1.3-bin.tar.gz -
압축을 해제한 폴더의 이름을 편의를 위해 변경해준다.
mv apache-hive-3.1.2-bin hive-3.1.2 -
환경 변수를 추가해준다.
vim ~/.bashrc export HIVE_HOME=/opt/hive/hive-3.1.2 export PATH=$PATH:$HIVE_HOME/bin -
변경된 환경 변수를 적용시킨다.
source ~/.bashrc
Hive 설정
-
hive-config.sh에 Hadoop 설치 경로를 추가해준다.
vim $HIVE_HOME/bin/hive-config.sh export HADOOP_HOME=/opt/hadoop/hadoop-3.3.3Hive가 Hadoop 관련 실행 파일, 라이브러리 및 설정 파일을 참조할 수 있어 Hadoop 클러스터에 연결되어 데이터 처리 작업을 실행할 수 있다.
-
임시 파일이나 중간 결과를 저장하기 위해 사용될 수 있도록 tmp 폴더를 생성한다.
hdfs dfs -mkdir /tmp -
hive 데이터베이스 및 테이블의 저장소 위치로 사용될 수 있도록 폴더를 만들어준다.
hdfs dfs -mkdir -p /user/hive/warehouse -
tmp 디렉토리에 대한 그룹 쓰기 권한을 부여한다.
hdfs dfs -chmod g+w /tmp hdfs dfs -chmod 777 /tmp -
user 디렉토리에 대한 그룹 쓰기 권한을 부여한다.
hdfs dfs -chmod -R g+w /user -
hive-site.xml 파일을 만들어준다.
cd $HIVE_HOME/conf cp hive-default.xml.template hive-site.xml -
hive-site.xml 파일의 configuration 안에 마지막 줄에 다음을 추가해준다.
<property> <name>system:java.io.tmpdir</name> <value>/tmp/hive/java</value> </property> <property> <name>system:user.name</name> <value>${user.name}</value> </property> -
hive-site.xml 파일의 다음 부분들을 찾아 다음과 같이 변경해준다.
<property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>Username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>Hivetest1!</value> <description>password to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true&characterEncoding=UTF-8&serverTimezone=UTC</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>0.0.0.0<value/> <description>Bind host on which to run the HiveServer2 Thrift service.</description> </property>':/찾고싶은 문자열' 로 쉽게 찾을 수 있다.
system:java.io.tmpdir은 hive에서 자바 애플리케이션 임시 파일을 생성할 때 사용되는 임시 디렉토리 경로를 지정하는 속성이다. hive는 대용량 데이터 처리를 위해 데이터 웨어하우스 솔루션으로 임시 파일이나 중간 결과를 생성하고 처리하는 과정에서 임시 디렉토리가 필요하다.
system:user.name은 현재 실행중인 사용자의 이름을 지정한다. ${user.name}로 지정함으로써 Hive는 동적으로 현재 사용자의 이름을 가져와 사용한다. 이것으로 접근 제어나 감사 목적으로 특정 작업을 수행한 사용자를 추적할 수 있다.
javax.jdo.option.ConnectionDriverName는 Hive에서 사용되는 JDBC 드라이버의 이름을 지정하는 속성이다. Hive는 데이터베이스와 상호작용하기 위해 JDBC 드라이버를 사용해야 하며 mysql을 사용하기 때문에 com.mysql.jdbc.Driver로 값을 지정했다.
javax.jdo.option.ConnectionUserName는 Hive에서 사용하는 JDBC 데이터베이스 연결에 대한 사용자 이름을 지정하는 속성이다. 위에서 mysql 데이터베이스에 'hive'라는 사용자를 생성하여 'hive'로 설정했다.
javax.jdo.option.ConnectionPassword는 Hive에서 사용하는 JDBC 데이터베이스 연결에 대한 암호를 지정하는 속성이다.
javax.jdo.option.ConnectionURL은 Hive에서 사용하는 JDBC 데이터베이스 연결에 대한 URL을 지정하는 속성이다. metastore db에 연결을 하며 '?' 뒤로는 설정값들에 해당한다.
hive.server2.thrift.bind.host는 Hiveserver2 Thrift 서비스가 바인딩되어야 하는 호스트 이름 또는 IP 주소를 지정한다. HiveServer2는 클라이언트가 Hive 쿼리를 제출하고 Thrift API를 사용하여 Hive와 상호 작용할 수 있는 서비스이다. 기본 속성은 '0.0.0.0'이다.
-
hive-site.xml 파일의 다음 부분을 찾아 지워준다.
hive.txmn.xlock 이라는 속성을 찾아 ''을 지워준다.':/hive.txmn.xlock'을 입력하면 찾기 쉽다.
-
guava.jar를 hadoop과 호환이 되도록 같은 버전의 jar로 바꿔준다.
rm $HIVE_HOME/lib/guava-19.0.jar cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar -
mysql connector를 설치해준다.
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.46.tar.gz tar xzvf mysql-connector-java-5.1.46.tar.gz cd mysql-connector-java-5.1.46 mv mysql-connector-* /opt/hive/hive-3.1.2/lib cd .. rm -rf mysql-connector-java-5.1.46 rm -rf mysql-connector-java-5.1.46.tar.gz8버전 설치 시 hive 실행 했을 때 에러가 발생하므로 5버전을 설치해준다.
-
Hive의 스키마를 mysql DB에 초기화 시킨다.
schematool -initSchema -dbType mysqlmysql은 Hive에서 Metastore 데이터를 저장하기 위해 사용된다.
Hive 실행
- hive를 실행한다.
hive - database를 생성한다.
create database test_db; - hive를 종료한다.
exit;
Hive와 DataGrip 연결하기
- hadoop의 etc 폴더에 들어가 core-site.xml을 다음을 추가해준다.
<property>
<name>hadoop.proxyuser.lyk.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.lyk.hosts</name>
<value>*</value>
</property>hadoop.proxyuser.lyk.groups는 'lyk'라는 사용자를 proxy로 실행하는 데 허용되는 그룹 목록을 지정하는 속성이다. '*'은 모든 그룹을 허용한다는 의미이다. Hadoop에서 대리 사용자는 다른 사용자를 대신하여 클러스터 리소스에 액세스 할 수 있는 권한을 갖는다. 이 권한은 대게 특정 서비스나 애플리케이션이 클러스터 리소스에 접근하거나 조작해야 할 때 필요하다.
Hadoop에서 'lyk' 사용자를 proxy로 실행하는 데 허용되는 호스트(서버)의 목록을 지정하는 속성이다. '*' 지정한 것은 모든 호스트(서버)를 허용한다는 의미이다. 만약 host1으로 설정했다면 'lyk'사용자는 host1에서 대리로 실행할 수 있다. 이 호스트에서 'lyk' 사용자가 Hadoop 리소스에 엑세스할 수 있으며, 필요한 작업을 수행할 수 있다.
- hadoop을 재시작 해준다.
stop-dfs.sh
stop-yarn.sh
start-dfs.sh
start-yarn.sh-
hive가 설치된 서버에 hiveserver를 켠다.
hive --service hiveserver2 -
DataGrip에서 DB source를 hive를 선택 후 다음과 같이 입력하여 Test Connection을 눌러준다.
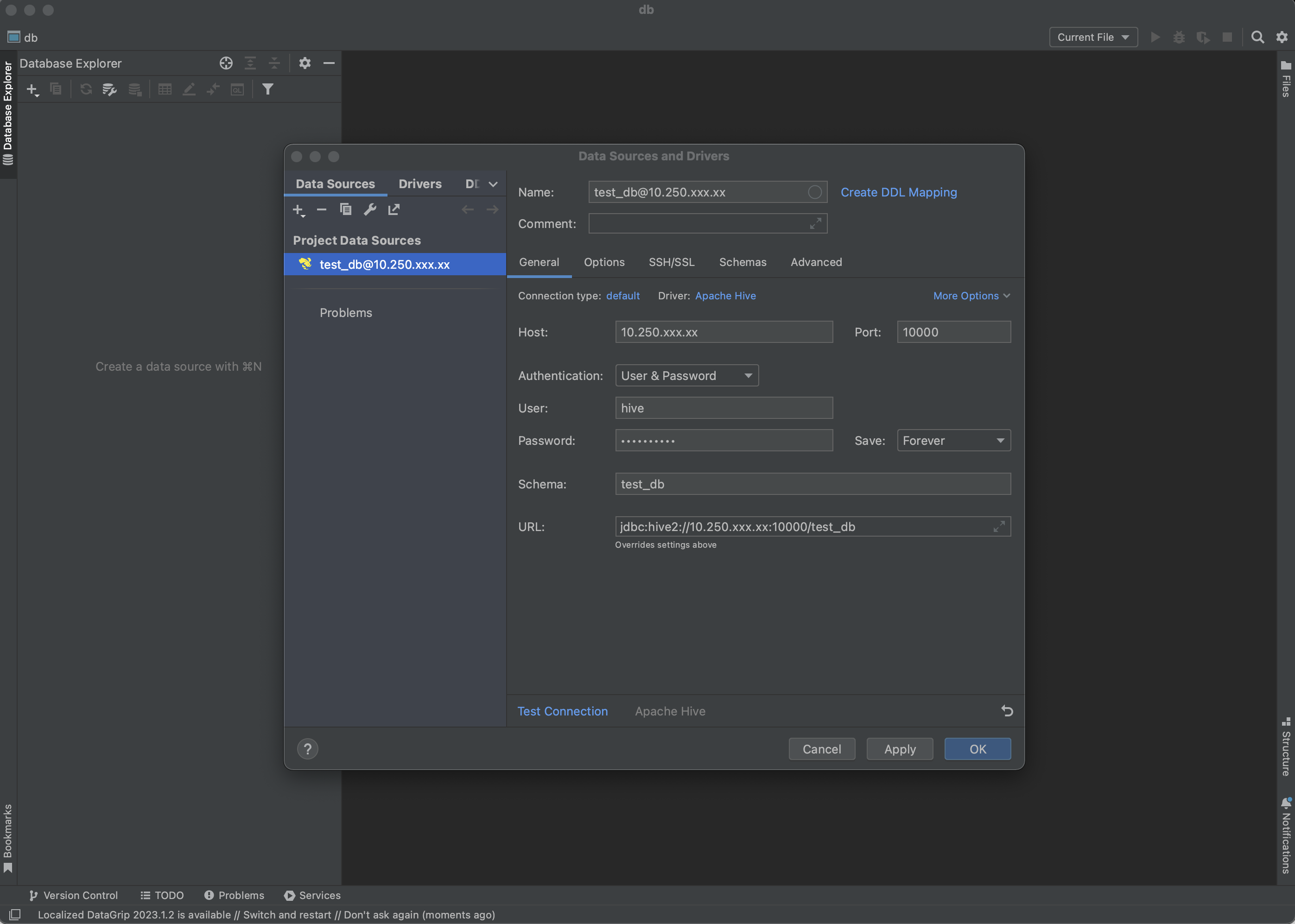
user와 비밀번호는 마음대로 입력한다. user는 꼭 입력해야 한다.
Test Connection이 성공으로 뜨면 OK를 눌러준다.
