Flume 이란?
- 대량의 로그 데이터를 효율적으로 수집, 집계 및 이동하기 위한 분산되고 안정적인 서비스이다.
특징
- 데이터를 수집하여 목적지에 전송하는 기능을 제공한다.
- 구조가 단순하고 유연하여 다양한 유형의 스트리밍 데이터르 플로우 아키텍처를 구성할 수 있다.
- 신뢰성, 규모 확장성 및 기능 확장성을 확보할 수 있다.
- 장애시에도 수집된 로그 유실을 방지 할 수 있다.
- 새로운 기능을 쉽게 커스터마이징 할 수 있다.
- 비동기 방식으로 처리한다.
구성 요소
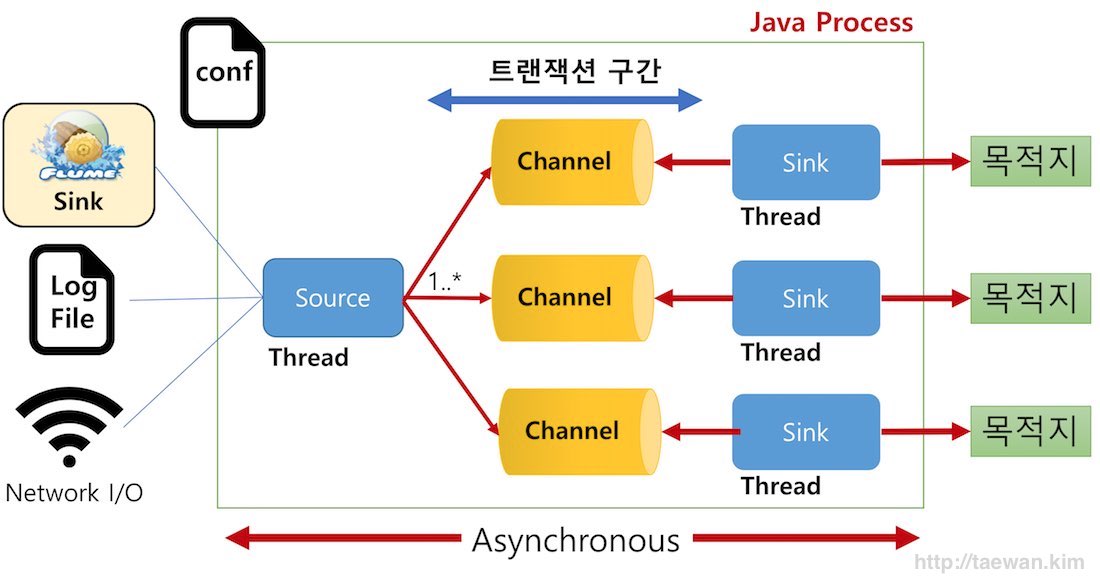
Source
- 외부 이벤트가 생성되어 수집되는 영역
- 1개 구성, 복수 Channel 지정
- Channel에 이벤트 입력
Channel
- Source와 Sink 간의 버퍼 구간
- Source와 Sink 사이의 Queue
- 채널 별로 1개 Sink 지정
- 이벤트 트랜잭션 관리
- 메모리와 파일, Queue등이 제공 됨
Sink
- 수집된 로그/이벤트를 목적지에 전달
- "단일" Channel에 연결
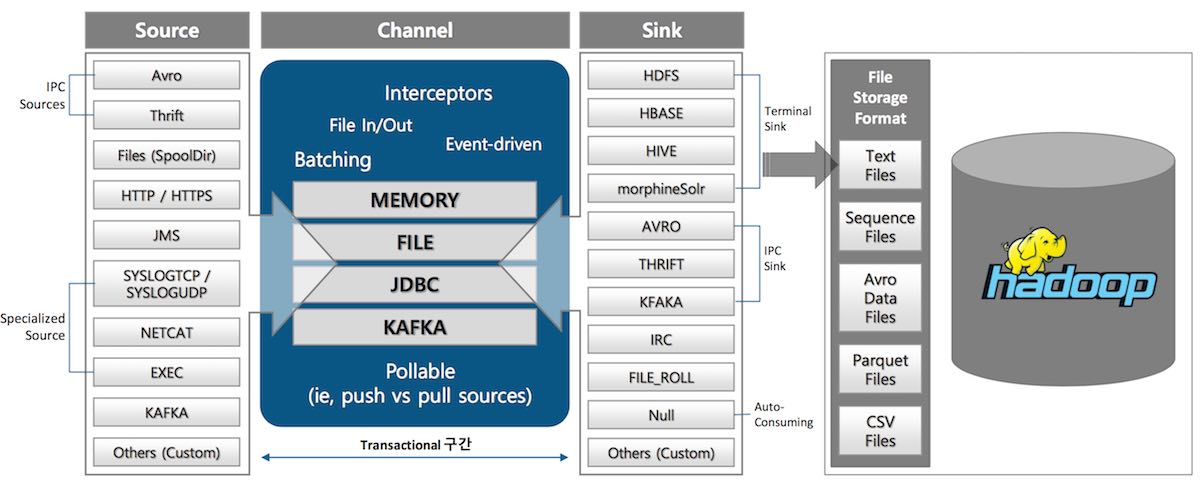
구성 요소는 다음 그림과 같이 다양한 구현 컴포넌트를 제공한다. 별도의 추가 개발 없이 로그/이벤트 수집 환경을 구성할 수 있다.
Flume과 Kafka의 결합
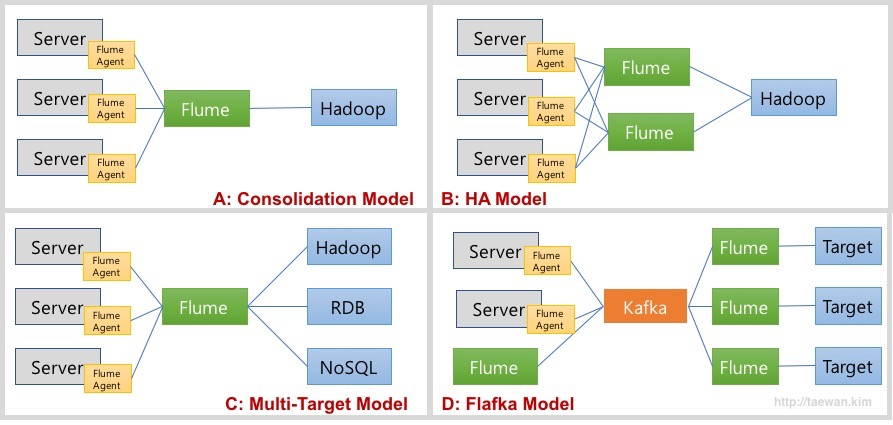
- A 모델: Consolidation Model
- 여러 서버로부터 로그를 통합하여 수집하고 저장하는 모델
- 각 서버에 Flume Agent가 설치되어 로그를 통합 Flume에 저장
- 통합 Flume은 지정된 목적지에 저장
- B 모델: HA 모델
- A 모델에서 통합 Flume 장애의 SPOF(단일 장애 포인트)에 대한 보완
- 고가용성을 위해서 통합 Flume을 이중화
- C 모델: Multi-Target Model
- A 모델에서 목적지를 복수로 지정
- D 모델: Flafka Model
- Flume이 Kafka의 Producer와 Consumer 역할 수행
- 통합 Flume을 Kafka로 대체하여 고가용성 및 확장성, 유연성 확보
- Flume을 이용하여 Kafka 개발 요소 제거
Flaka Model
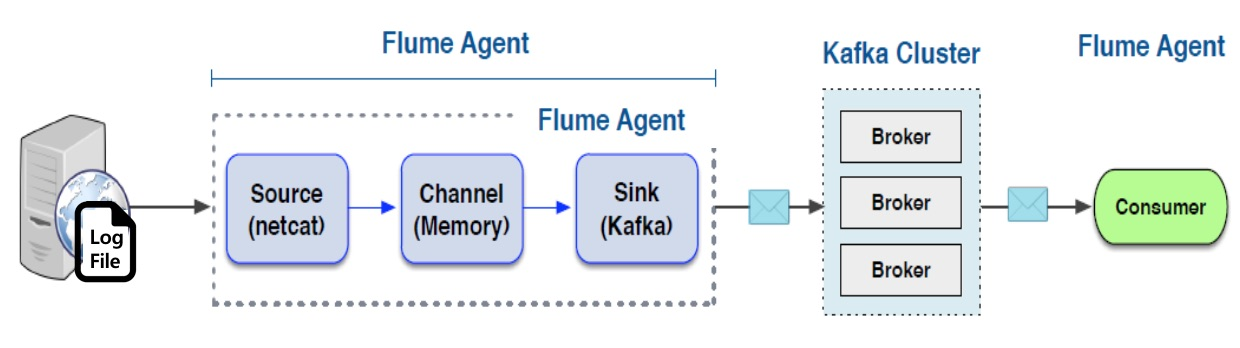
- Flume의 가장 취약점은 데이터의 안정성이다.
- Flume은 Channel로 메모리와 파일 그리고 JDBC를 제공한다. 메모리 타입은 처리 성능은 좋지만, 장애 발생 시 데이터 유실의 문제가 있다.
- 파일 타입은 데이터 안정성은 향상되지만 성능이 크게 떨어지며 고가용성 모드로 관리하기 어렵다.
- 이러한 문제를 Flume과 Kafka를 결합함으로써 해결할 수 있다.
- Flume은 다양한 소스와 목적지에 컴포넌트가 이미 구현되어 있어 설정만으로 작업을 완료할 수 있다는 장점이 있으며 장애가 발생할 경우 데이터 유실의 가능성이 있고 확장 구성이 복잡하다는 단점이 있다.
- Kafka는 저장된 데이터를 안전하게 관리할 수 있고, 구성이 간단하고 확장성이 좋다는 장점을 갖으며, 데이터 수집기(producer)와 데이터 처리기(Consumer)를 사용자가 구현해야 하는 단점이 있다.
- 각자의 단점을 보완하고 강점을 부각할 수 있다.
Flume 모니터링
-
모니터링 하는 방법은 3가지가 있다.
-
Ganglia
- 실행 시 -Dflume.monitoring.type=ganglia 옵션을 추가하여 Ganglia 모니터링이 가능하다.
-
JMX
- flume은 자바로 개발되어 있어 JMX로 모니터링 가능하다.
- 환경변수로 다음과 같은 JAVA_OPTS 옵션을 추가하는 방법이 있다.
export JAVA_OPTS=”-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=5445 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false”
-
JSON Reporting
- flume 실행 시 -Dflume.monitoring.type=http 옵션을 추가하여 웹 기반 모니터링이 가능하다.
- 리포팅 기본 포트는 41414이며 변경 가능하다. http://<모니터링 대상 Flume IP>:41414/metrics 호출하면 아래와 같은 정보가 출력됩니다.
-
Flume 설치 및 실행
Flume 설치
-
다음 사이트에 들어가 flume을 다운 받아 압축을 풀어준다.
https://www.apache.org/dyn/closer.lua/flume/1.11.0/apache-flume-1.11.0-bin.tar.gzwget https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz tar xzvf apache-flume-1.11.0-bin.tar.gz mv apache-flume-1.11.0-bin flume-1.11.0 -
환경 설정을 해준다.
vim /etc/profile export FLUME_HOME=/opt/flume/flume-1.11.0 -
conf 폴더에 들어가 flume.conf를 만들어준다.
cd $FLUME_HOME cd conf vim flume.conf -
flume.conf를 작성해준다.
agent.sources = r1 agent.channels = c1 agent.sinks = k1 agent.sources.r1.type = exec agent.sources.r1.command = tail -f /opt/flume/flume-1.11.0/logs/mylog agent.sources.r1.channels = c1 agent.channels.c1.type = memory agent.channels.c1.capacity = 1000 agent.channels.c1.transactionCapacity = 100 agent.sinks.k1.type = logger agent.sinks.k1.channel = c1 -
log 파일을 하나 만들어준다.
cd $FLUME_HOME mkdir logs cd logs touch mylog -
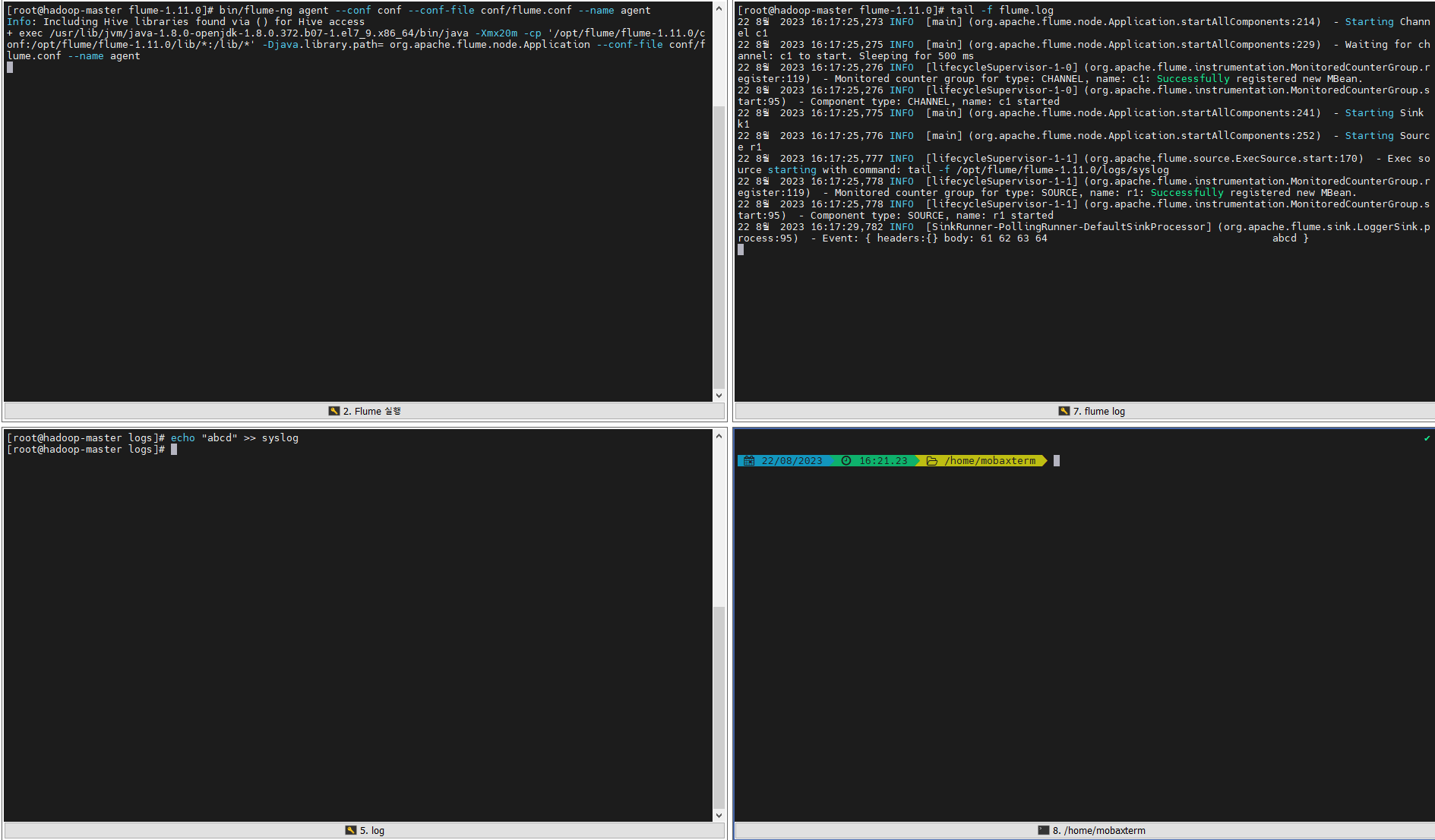
설정을 완료 했으니 flume을 실행해준다.
cd $FLUME_HOME bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name agent -
다른 shell 창을 열어 mylog 파일에 데이터를 적재해본다.
cd $FLUME_HOME/logs echo "logloglog" >> mylog -
실행되는 flume에 데이터가 잘 들어오는 확인한다.
Flume & Kafka 연동
kafka 설치 및 실행
- kafka를 설치해준다.
wget https://archive.apache.org/dist/kafka/3.1.0/kafka_2.13-3.1.0.tgz
tar xzvf kafka_2.13-3.1.0.tgz- zookeeper를 실행 시킨다.
cd kafka_2.13-3.1.0
cd bin
./zookeeper-server-start.sh ../config/zookeeper.properties- 터미널을 하나 더 열어 kafka를 실행 시킨다.
./kafka-server-start.sh ../config/server.properties- 터미너를 하나 더 열어 kafka topic을 생성해준다.
./kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1- topic 목록을 조회하여 test topic이 잘 만들어졌는지 확인
./kafka-topcis.sh --list --bootstrap-server localhost:9092- kafka console consumer를 실행시킨다.
./kafka-console-consumer.sh --topic test --bootstrap-server localhost:9092- 터미널을 하나 더 열어 kafka console producer를 실행시킨다.
./kafka-console-producer.sh --topic test --bootstrap-server localhost:9092- consumer console에 입력한 겨과가 console producer에 찍히는지 확인한다.
Flume 설정 변경
- flume 설정 파일을 열어준다.
cd $FLUME_HOME
cd conf
vim flume.conf- 설정 파일을 다음과 같이 작성해준다.
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.topic = test
agent.sinks.k1.brokerList = localhost:9092
agent.sinks.k1.requiredAcks = 1
agent.sinks.k1.channel = c1
agent.sources = r1
agent.channels = c1
agent.sinks = k1
agent.sources.r1.type = exec
agent.sources.r1.command = tail -F /opt/flume/flume-1.11.0/logs/mylog
agent.sources.r1.channels = c1
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.topic = test
agent.sinks.k1.brokerList = localhost:9092
agent.sinks.k1.requiredAcks = 1
agent.sinks.k1.channel = c1
- flume을 실행시켜준다.
cd..
bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name agent- 터미널 창을 하나 더 열어 mylog에 데이터를 적재해본다.
cd $FLUME_HOME/logs
echo "save mydata" >> ./logs/mylog- mylog에 데이터가 쌓이고 해당 로그가 producer에 출력 되는것을 볼 수 있다.
참고 사이트

미래를 생각하는 개발자