데이터브릭스에서 S3로 저장한 데이터를 타 시스템에 API로 제공해야하는 일이 생겼다.
설계와 비교
구조는 크게 4가지를 생각했다.
- API Gateway - kinesis - kinesis data firehose - S3
- Kinesis data stream : 실시간 데이터를 처리
- Kinesis data firehose : 실시간 데이터를 수집,변환,전달
- 장점
- 실시간으로 api로 데이터를 받아 S3에 저장하는 경우 좋음
- API Gateway - lambda - Athena - S3
- HTTP 요청을 수신 후 lambda 함수로 전달하여 lambda가 Athena 쿼리를 실행하여 S3 데이터를 처리 후 결과를 반환한다.
- 특징
- 대량의 데이터를 실시간으로 처리 가능
- 다양한 데이터 형식(parquet, orc, csv 등)을 지원
- 비용이 높을 수 있음
- Athena 쿼리는 결과를 얻기까지 시간이 좀 걸릴 수 있음
- 대량의 데이터(TB 단위)를 처리하는 경우 좋음
- API Gateway - lambda - Glue - S3
- HTTP 요청을 수신하여 lambda 함수로 전달 후 glue 작업을 트리거 하여 데이터 처리 후 반환
- 특징
- 복잡한 데이터 변환 작업을 자동화 하기 좋음
- 주로 ETL 작업에 많이 사용
- 데이터의 복잡한 변환 및 정리 혹은 다양한 데이터 소스를 통합하고 ETL 작업을 자동화하는 경우 좋음
- API Gateway - lambda - S3
- HTTP 요청을 수신하고 S3 데이터를 읽음
- 특징
- Lambda 함수에 직접 S3 데이터에 접근할 수 있어 실시간 응답이 가능
- 비용이 효율적
- 대량의 데이터를 처리하는 데 한계가 있음.
- 간단한 데이터 조회 및 업데이트가 필요한 경우 사용
4개의 구조를 보았을 때 하루 40만건 정도의 데이터를 조회하여 특정 row를 반환하는게 목적이라 마지막 API Gateway - lambda - S3를 사용하기로 결정
AWS Lambda
Lambda로 S3에 접근할 것이기 때문에 Lambda가 S3에 접근 할 수 있도록 정책을 먼저 생성해야 한다.
- 정책 생성
- AWS Console에서 IAM 검색
- 역할 클릭 후 역할 생성
- 서비스를 lambda로 선택
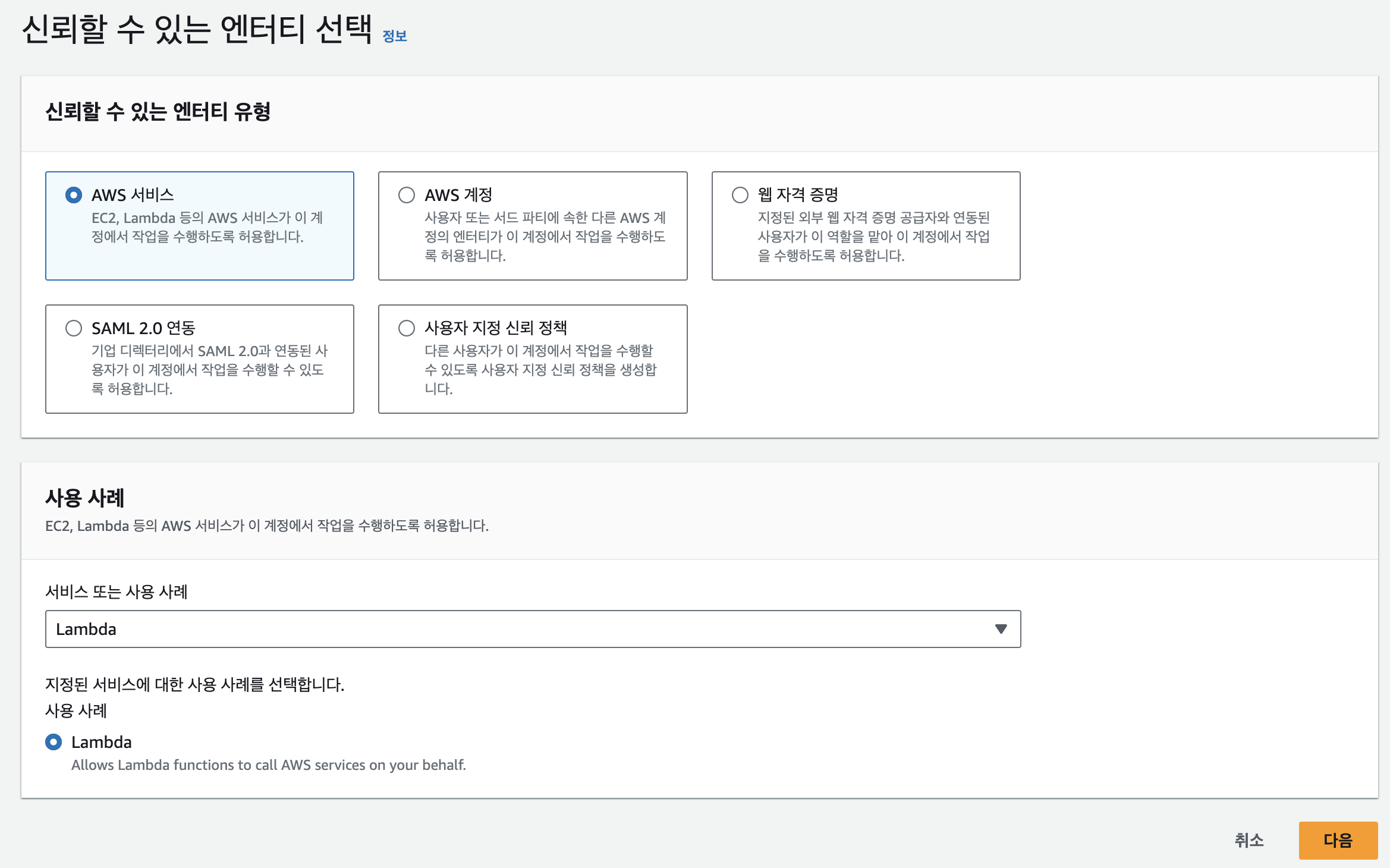
- S3 접근 권한과 lambda 기본 실행 권한 추가


- 이름을 지정하고 역할 생성
- AWS Console에서 IAM 검색
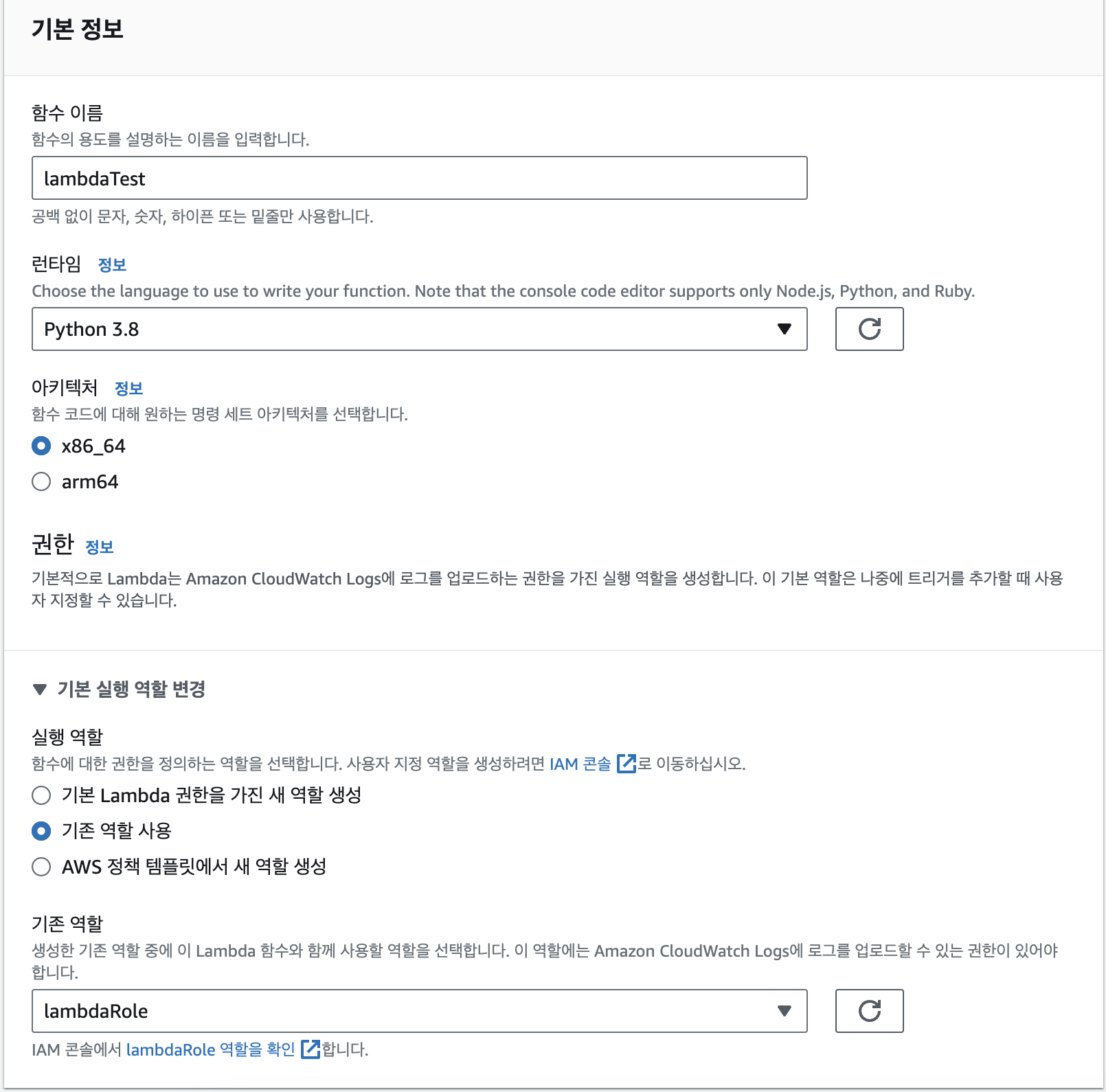
역할을 생성 했으니 이제 lambda를 생성 해보자.
- lambda 생성
- AWS Console에서 lambda 검색
- 함수 이름과 위에서 만든 역할을 설정해준다.
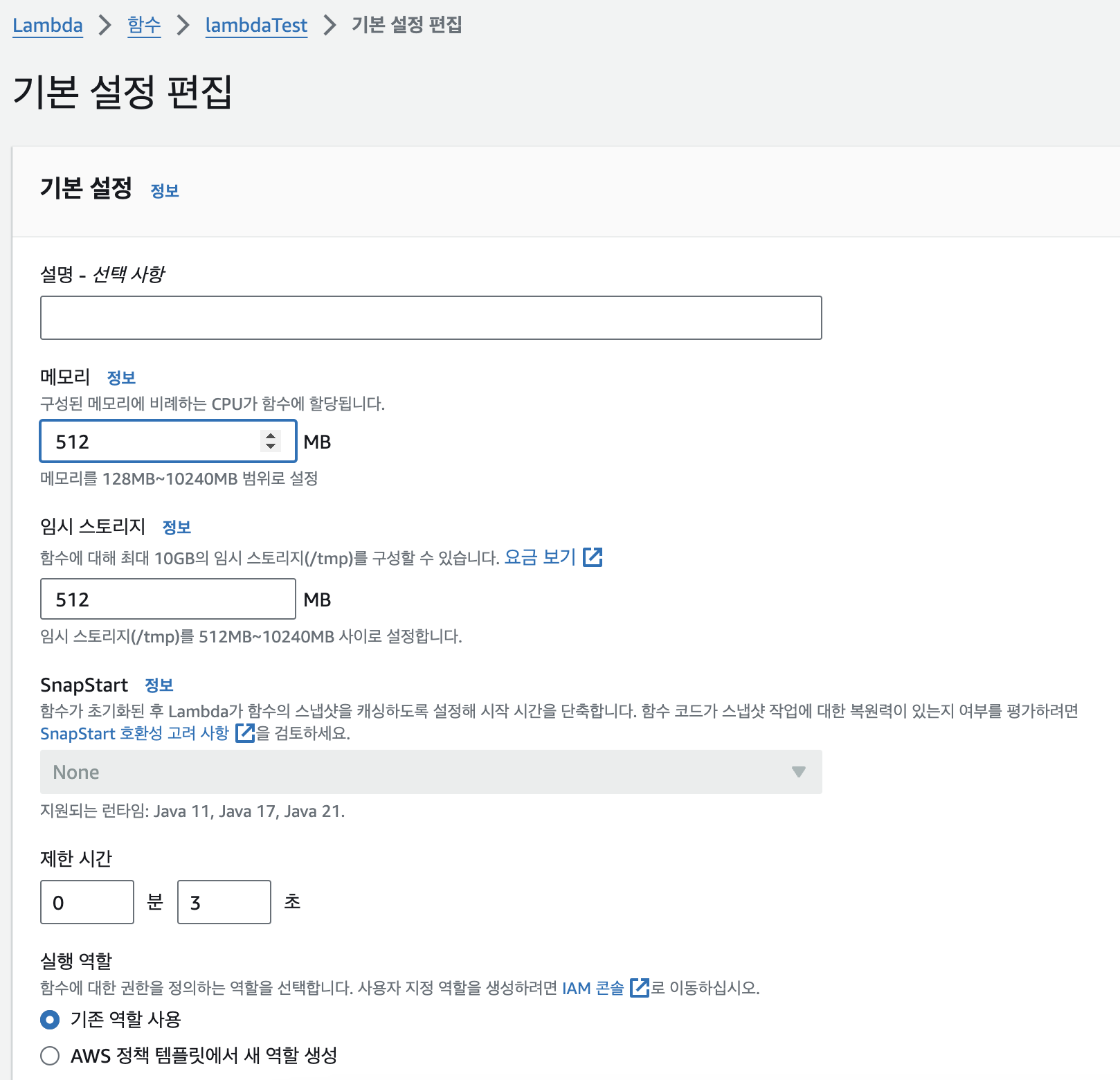
- 생성이 되었으면 구성 -> 일반 구성을 눌러 메모리를 사용해야할 만큼 늘려준다.

- AWS Console에서 lambda 검색
S3에 접근하기 위해 코드를 작성할건데 parquet 형식의 데이터를 읽기 위해서는 pyarrow library와 처리를 위한 pandas library가 필요하다.
library를 다운받아 패키징을 한다.
-
library 패키징
-
library 설치
-
필자는 mac을 사용하며 architecture가 arm64인 반면 lambda의 환경은 x86_64이기 때문에 docker로 환경에 맞는 library를 다운 받는다.
-
다음 명령어를 터미널에서 차례로 실행한다. (docker 설치 과정은 생략)
-- lambda 환경 이미지 pull docker pull lambci/lambda:build-python3.8 -- 현재 디렉토리에서 package 폴더를 만들고 docker run docker run -it --rm -v $(pwd)/package:/lambda/package lambci/lambda:build-python3.8 bash -- pandas, pyarrow 설치 pip install pandas pyarrow -t /lambda/package/python/lib/python3.8/site-packages -- container에서 나가기 exit -- lib 설치한 곳으로 이동 cd package/python/lib/python3.8/site-packages/ -- 불필요 파일 및 폴더 제거 find . -name '*.pyc' -delete find . -name '__pycache__' -type d -exec rm -rf {} + find . -name '*.dist-info' -type d -exec rm -rf {} + find . -name '*.egg-info' -type d -exec rm -rf {} + -- package 폴더로 다시 이동 cd ../../../../ -- 파일 압축 zip -r ../pyarrow-layer.zip .library의 위치를 다음과 같이 하여 압축을 해야만 한다.
layer_content.zip
└ python/lib/python3.8/site-packages/설치lambda에 library를 로드해줘야 하는데 용량 한계가 있어 폴더를 제거하지 않으면 library를 올리지 못한다.
이 경우 docker image를 ECR에 함수와 library를 docker image로 만들어 사용해 한다.
-
-
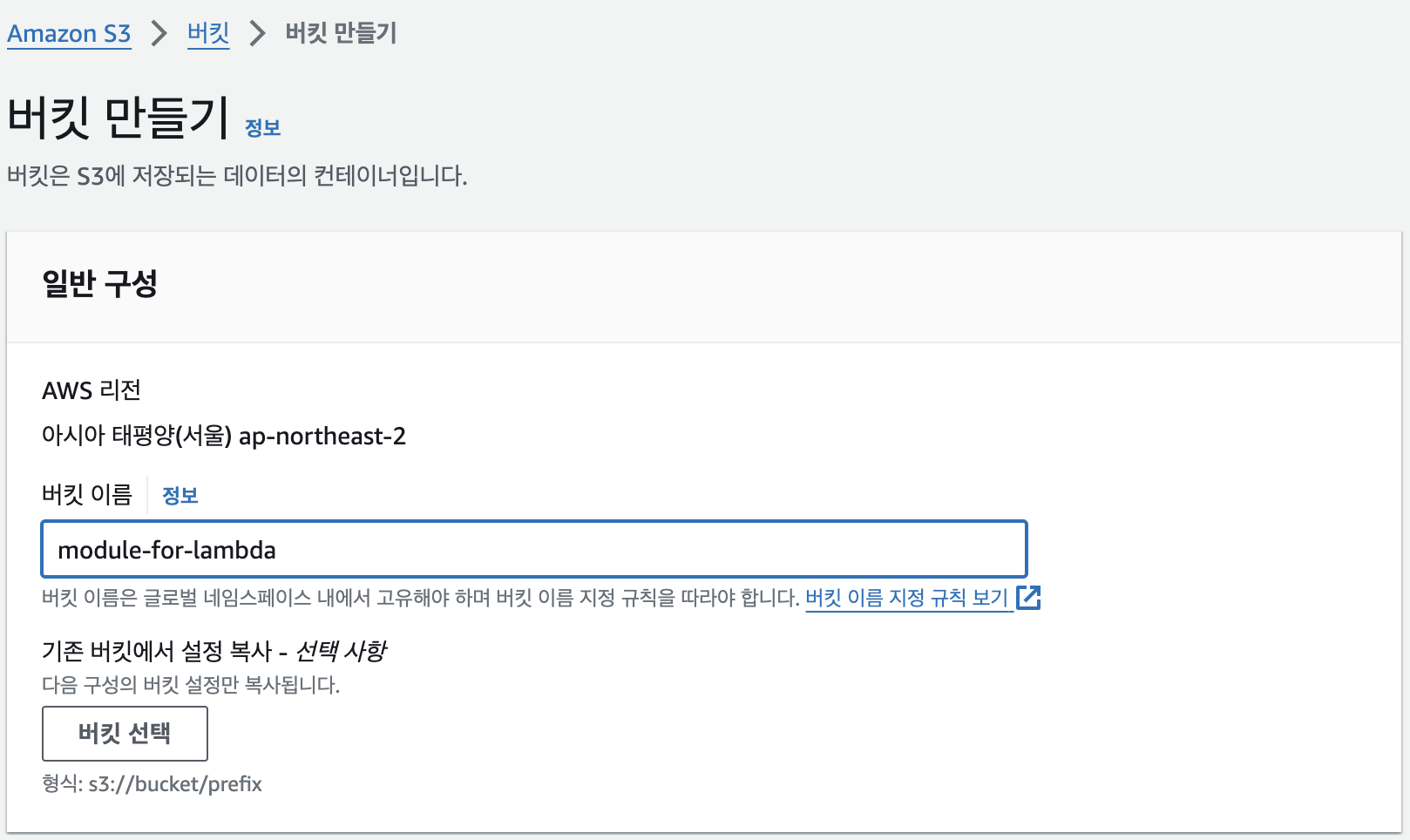
library 설치가 완료 되었으면 해당 zip 파일을 S3에 올려준다.
- S3 bucket 생성
- AWS Console에 S3를 입력하여 버킷 생성, 따로 설정 필요 없음
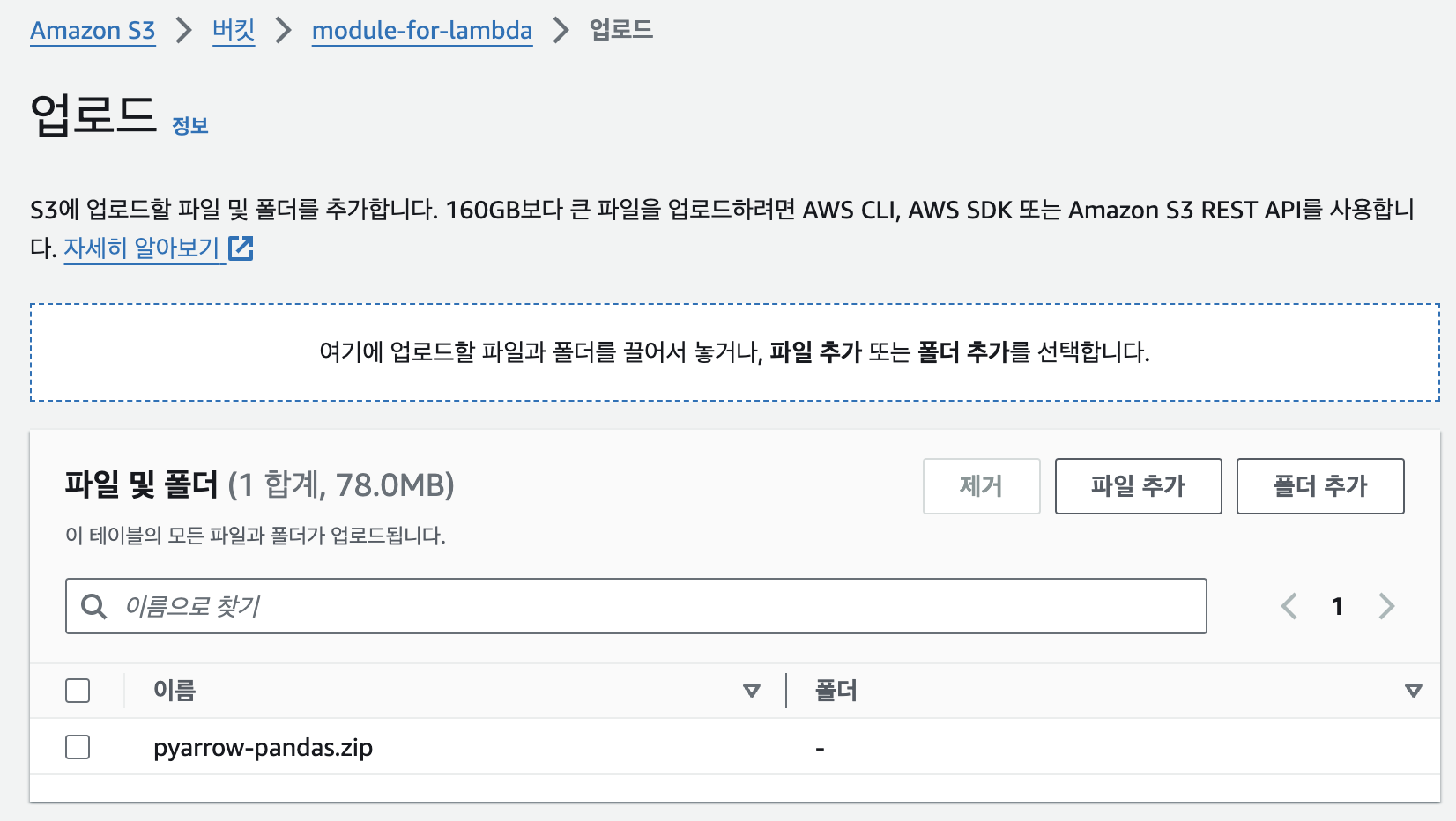
- 만든 버킷에 zip 파일을 업로드 한다.
- AWS Console에 S3를 입력하여 버킷 생성, 따로 설정 필요 없음
다시 lambda로 올라가 layer를 만들어준다.
공통으로 사용되는 패키지 또는 라이브러리를 압축하여 업로드 함으로써 여러 람다함수에서 접근하여 코드 수정 없이 사용할 수 있게 해준다.
- layer 생성
- lambda에서 계층 선택하여 계층 생성
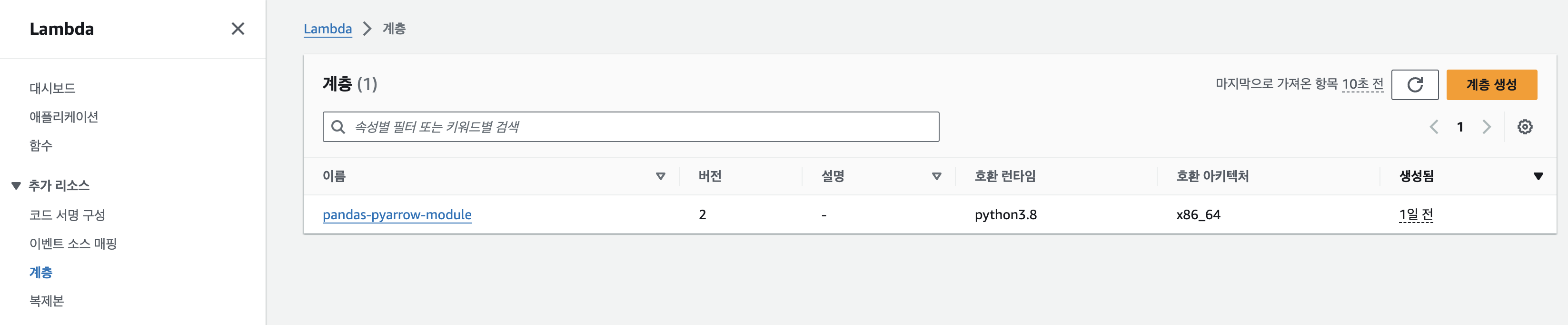
- S3에서 업로드한 bucket의 object로 들어가 S3 링크 URL을 가져온다.
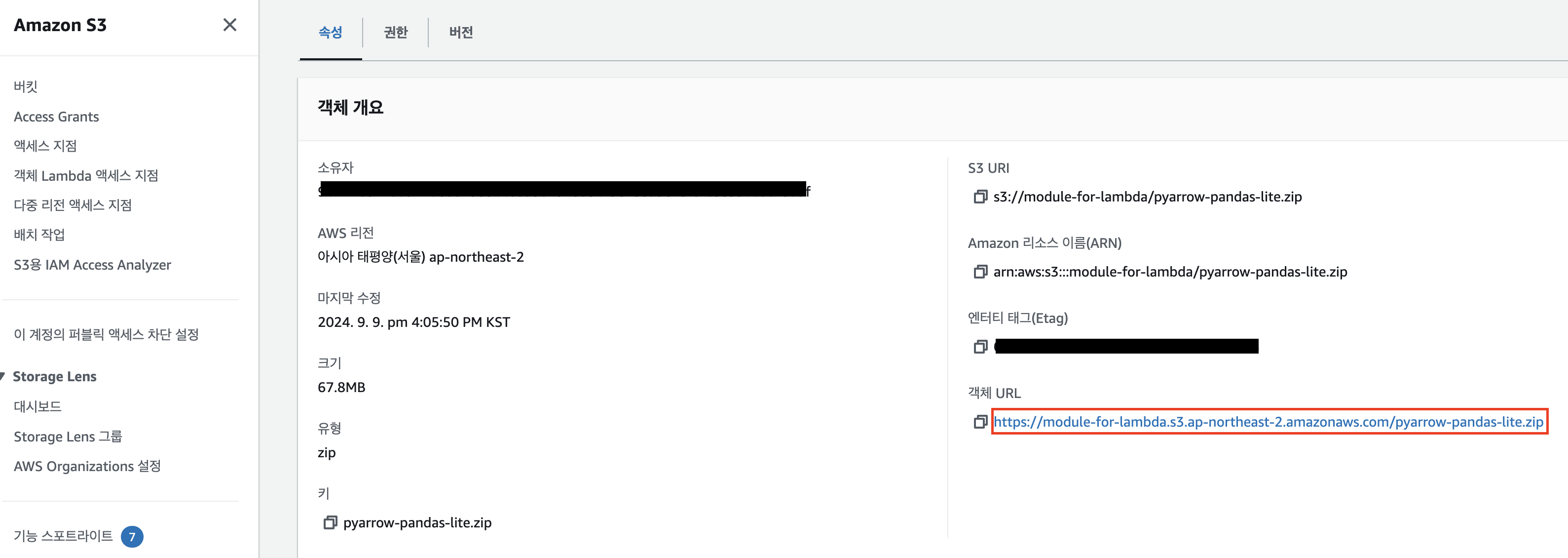
- 이름 설정 후 Amazon S3에서 파일 업로드를 선택 후 복사한 URL을 붙여 넣는다. 아키텍처는 x86_64로 하면 호환 런타임은 python3.8로 맞춰준다.

- lambda에서 계층 선택하여 계층 생성
layer를 생성 했으니 해당 함수와 연결 해준다.
-
lambda 함수와 layer 연결
- 만든 lambda 함수를 선택하여 가장 밑에 계층 항목으로 가 [Add a layer]를 누른다

- 만든 layer를 추가해준다.
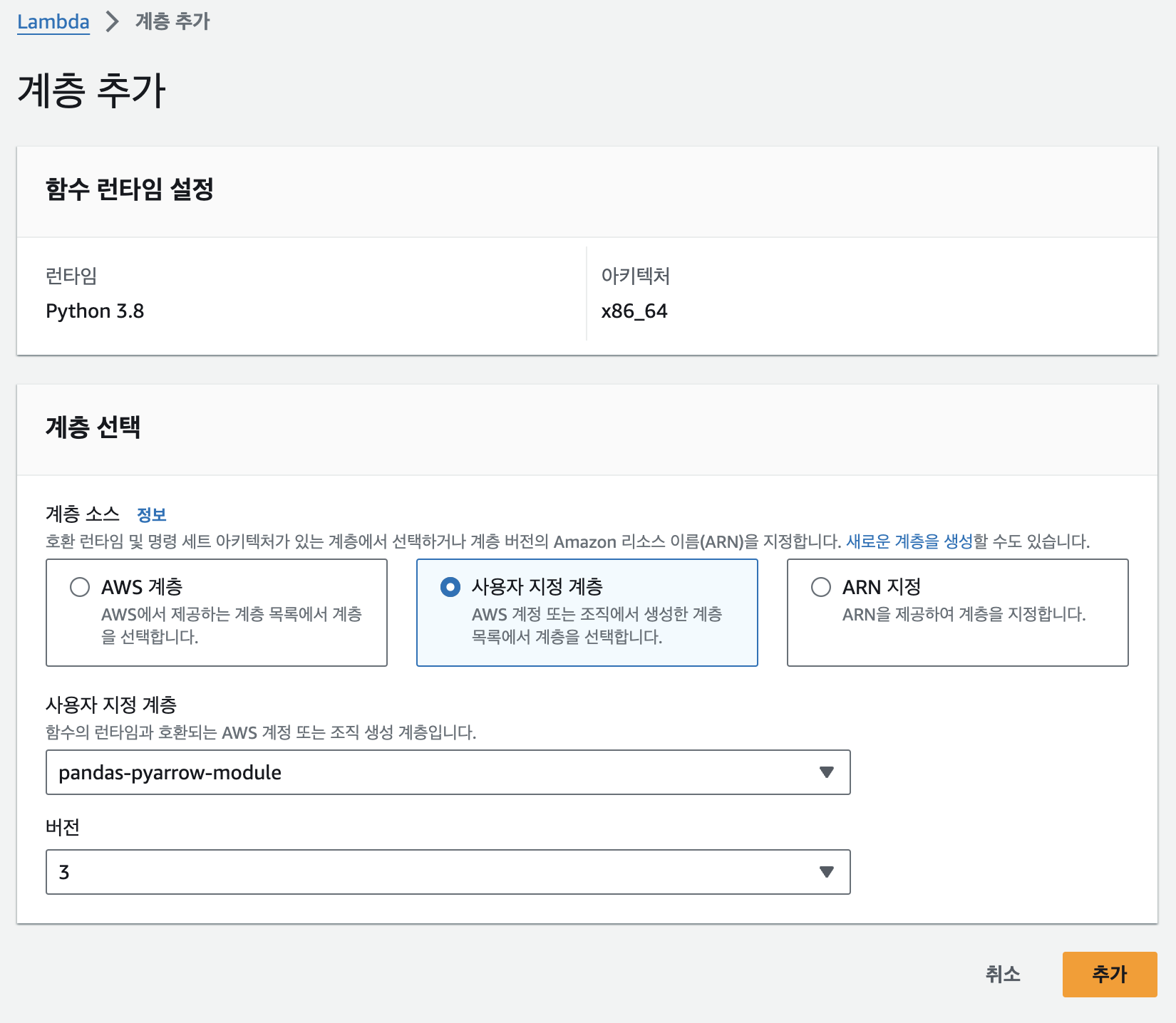
이후 lambda 코드 소스를 작성한다.
- 만든 lambda 함수를 선택하여 가장 밑에 계층 항목으로 가 [Add a layer]를 누른다
-
코드 작성 후 deploy를 눌러 코드를 반영한다.
import json import boto3 import pyarrow.parquet as pq import pyarrow as pa import logging import io import pandas as pd # Logger 설정 logger = logging.getLogger() logger.setLevel(logging.INFO) # S3 클라이언트 생성 s3_client = boto3.client('s3') def lambda_handler(event, context): try: # API Gateway에서 id S3 버킷 정보 가져오기 id_number = event.get('queryStringParameters', {}).get('id') if not id_number: raise ValueError("Query parameter 'id' is required.") bucket = 'bucket_name' prefix = 'object_name/yyyyddmm/' # 파일 경로의 접두사 (폴더와 비슷한 개념) if not id_number or not bucket: raise ValueError("Event must contain 'id' and 'bucket'.") # S3에서 파일 목록 가져오기 response = s3_client.list_objects_v2(Bucket=bucket, Prefix=prefix) if 'Contents' not in response: raise ValueError(f"No files found in bucket {bucket} with prefix {prefix}.") # 모든 Parquet 파일에서 데이터 읽기 및 필터링 all_filtered_rows = [] for item in response['Contents']: key = item['Key'] if key.endswith('.parquet'): logger.info(f"Processing file: {key}") # S3에서 Parquet 파일 다운로드 parquet_data = s3_client.get_object(Bucket=bucket, Key=key)['Body'].read() # pyarrow를 사용하여 Parquet 파일을 읽기 table = pq.read_table(io.BytesIO(parquet_data)) # DataFrame으로 변환 df = table.to_pandas() # contractNumber로 필터링 filtered_df = df[df['id'] == id_number] # dict로 변환하여 리스트에 추가 all_filtered_rows.extend(filtered_df.to_dict(orient='records')) if not all_filtered_rows: logger.info(f"No rows found for contractNumber: {contract_number}") return { 'statusCode': 200, 'body': json.dumps({'message': 'No matching rows found'}) } logger.info(f"Filtered rows: {all_filtered_rows}") return { 'statusCode': 200, 'body': json.dumps(all_filtered_rows) } except Exception as e: logger.error(f"Error processing the request: {str(e)}") return { 'statusCode': 500, 'body': json.dumps({'error': str(e)}) }필자는 json으로 id를 받아 그에 해당 되는 정보를 S3에서 조회하여 반환하는 코드를 짰다.
코드를 다 짰으면 API Gateway를 생성하여 연결하자.
- API Gateway 생성
- 트리거 추가 선택
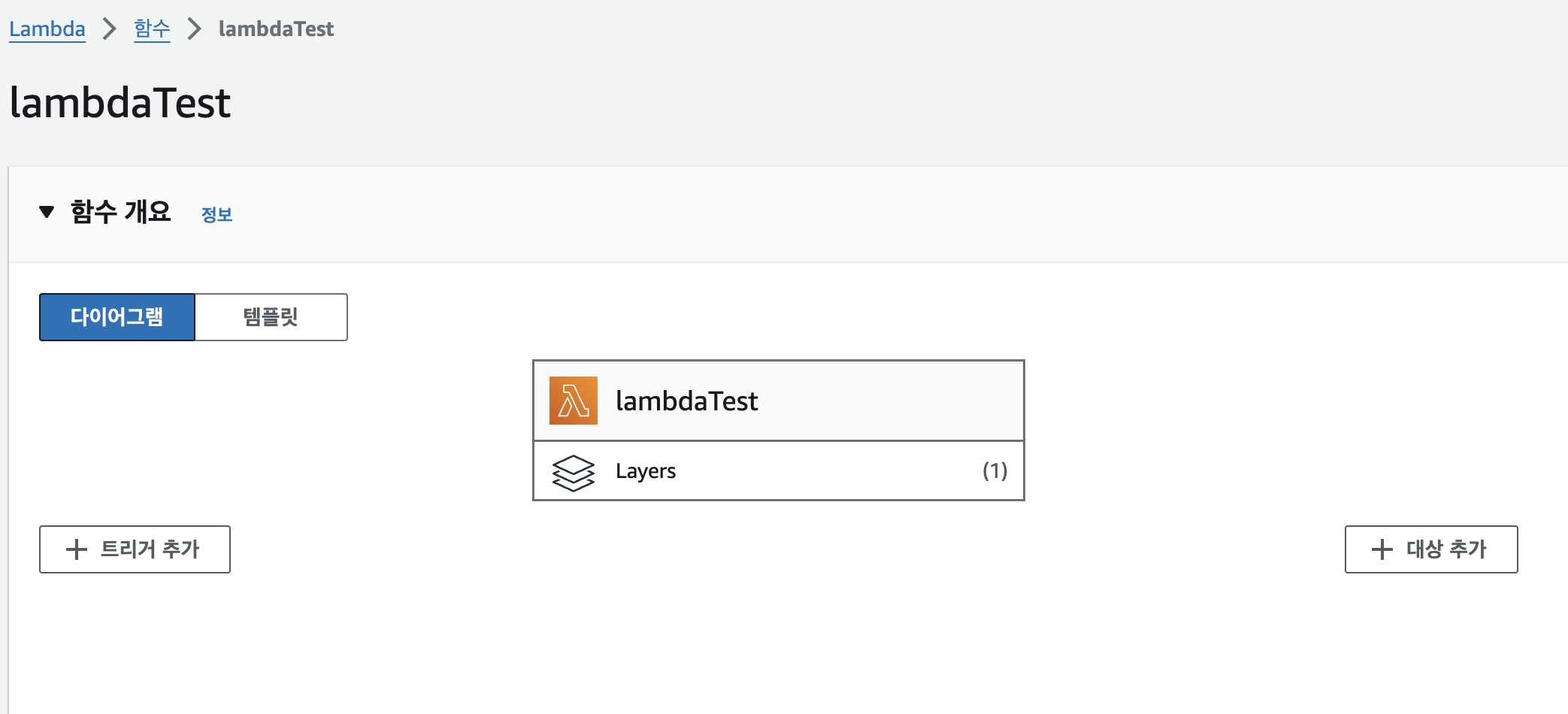
- API gateway를 선택 후 API 유형을 REST API로 선택
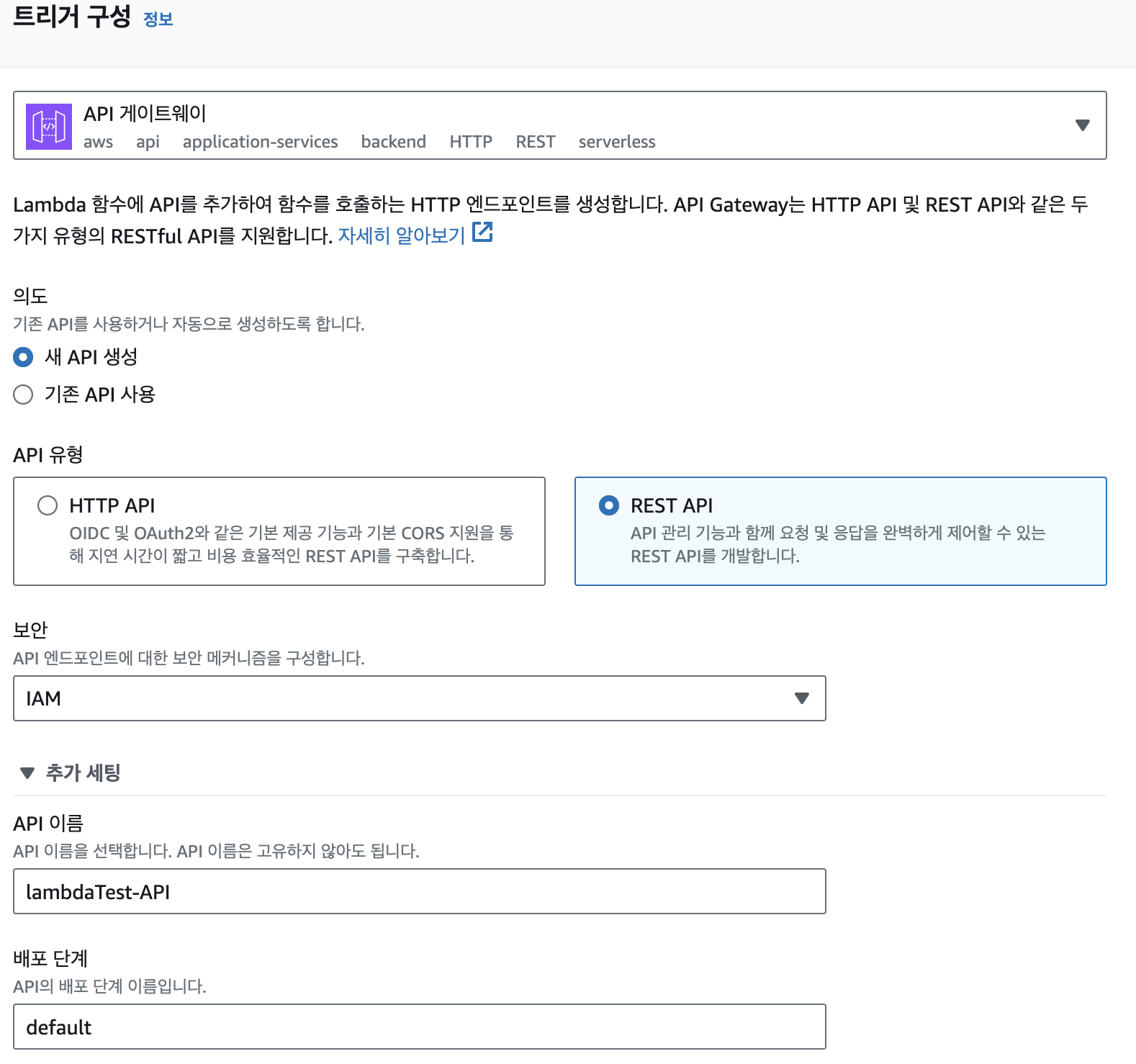
- 트리거 추가 선택
API 생성이 되었을 거고 AWS Console에 api gateway를 입력하여 새로 만든 api를 설정해준다.
- API Gateway 설정
- 생성된 api gateway를 들어가면 기본적으로 ANY가 있을 것이다. ANY는 삭제 하고 GET method를 생성한다.
- 메서드 유형은 GET, 통합 유형은 Lambda 함수, Lambda 프록시 통합 활성화, Lambda 함수 선택을 한다.
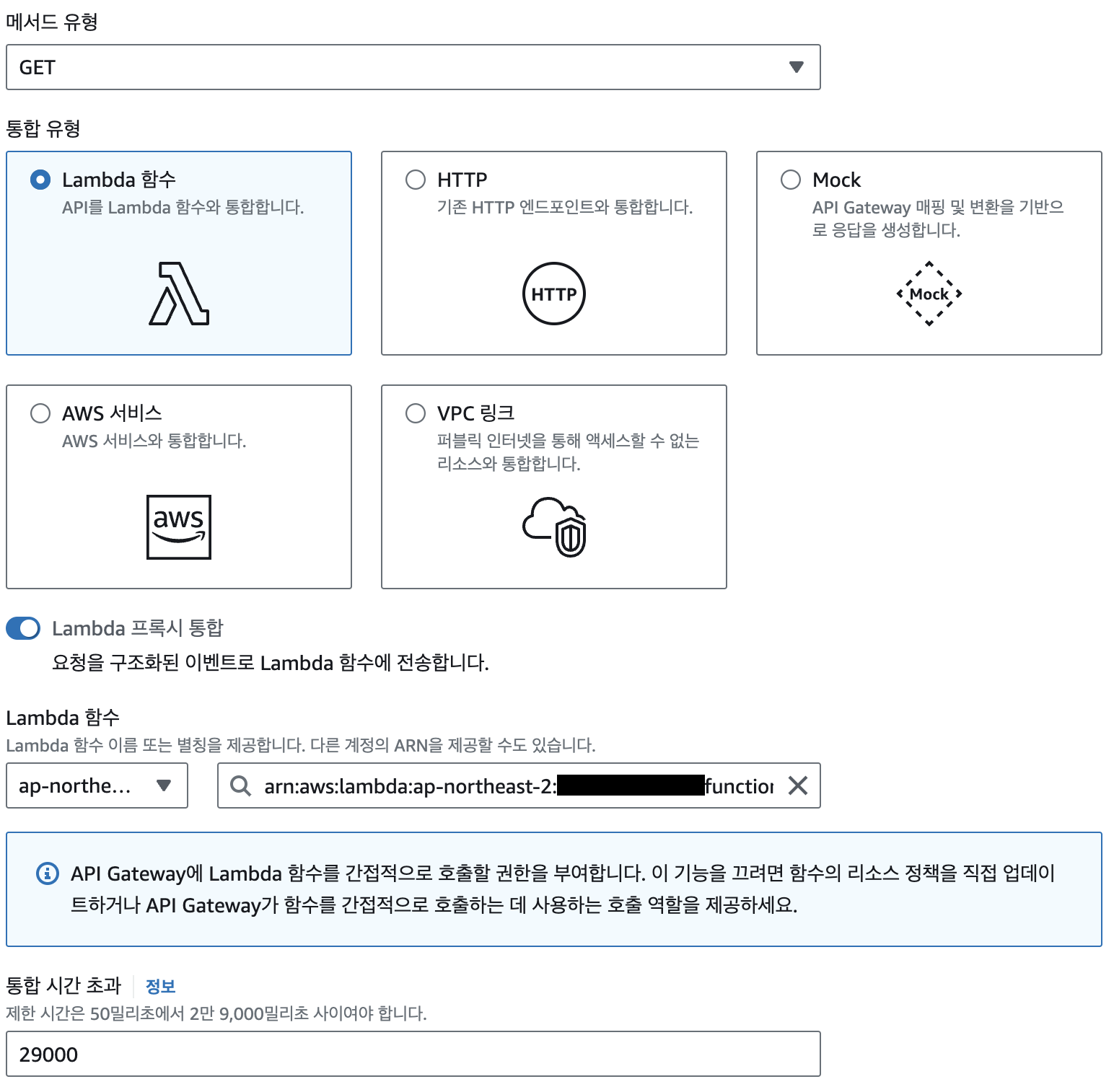
모든게 완료 되었으니 테스트를 해보자
-
테스트
- API Gateway에서 test 항목으로 들어가 쿼리 문자열을 작성해준다.
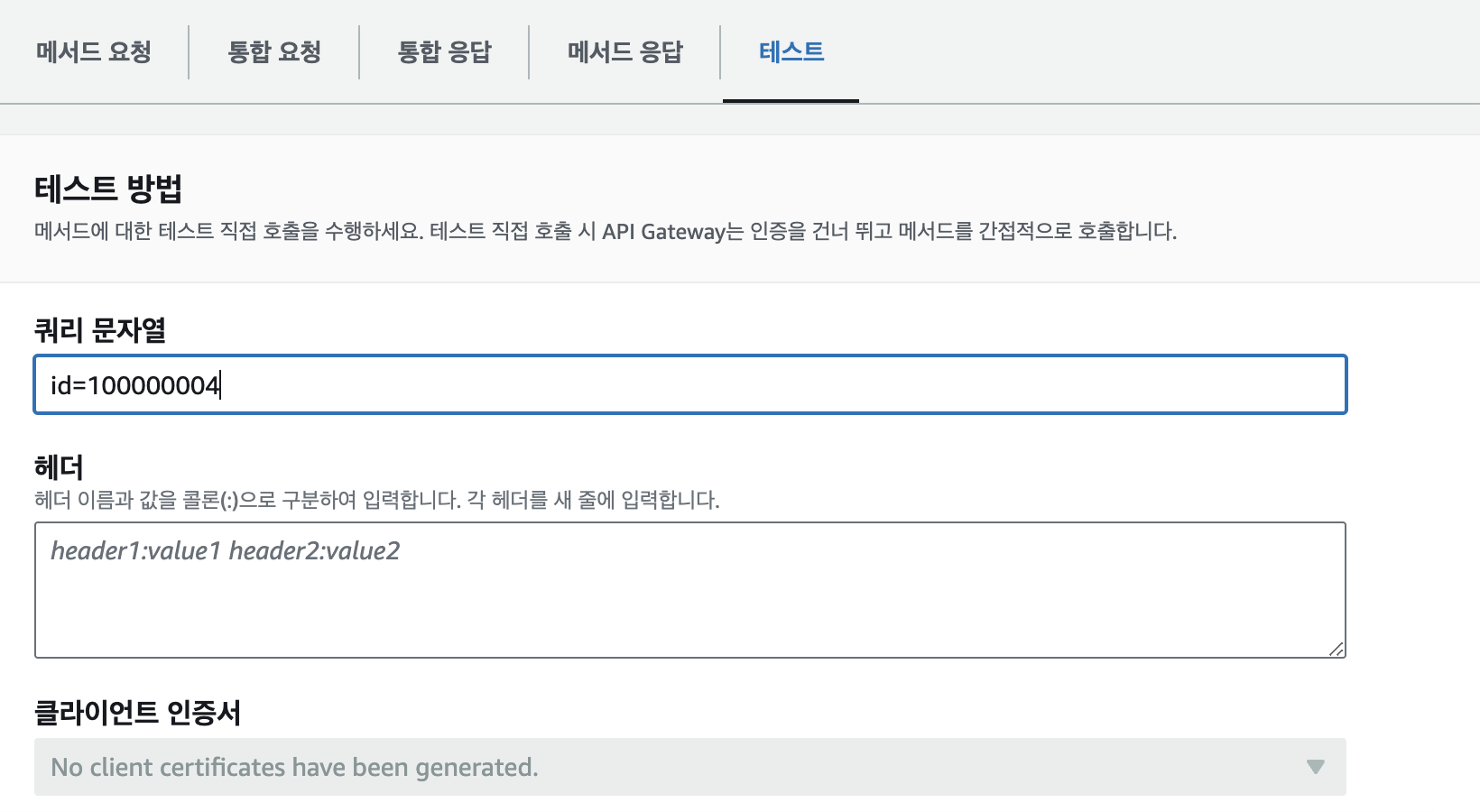
- API Gateway에서 test 항목으로 들어가 쿼리 문자열을 작성해준다.
-
결과
- 정상이라면 상태가 200으로 알맞은 데이터가 반환되어 출력되었을 것이다.

- 정상이라면 상태가 200으로 알맞은 데이터가 반환되어 출력되었을 것이다.
어려웠던 점
- 패키징 하는 법을 찾느라 어려웠음
- 공식 문서에 익숙해지자
- 계층을 추가하기
- library가 커서 억지로 크기를 맞추느라 좀 어려웠다.
- 도커 이미지를 사용하면 되지만 ECR에 올리는 등 관리 포인트가 많아져 library를 억지로 크기를 끼워 맞춤
- library가 커서 억지로 크기를 맞추느라 좀 어려웠다.
참고 사이트
