AWS ECS Capacity Provider(용량 공급자) 를 통해 서버 인프라를 비용 효율적이면서도 쉽게 관리할 수 있는 방법을 배워보자!
개요
회사에서는 도커 기반의 AWS ECS 를 많이 사용하고 있다.
최근 오토스케일링과 관련하여 발생한 몇몇 성능 및 비용 이슈들이 있었고 효율적인 오토스케일링 방법을 연구하기 시작했다.
그러던 중 Capacity Provider(용량 공급자)라는 기능을 사용해보았고 이 기능을 잘 활용하면 많은 이점이 있을거라 생각하여 다양한 분석을 해보았다.
결과적으로 해당 기능을 서비스 인프라 관리에 도입하여 개발자들이 인프라 관리에 들이는 노력을 상당 부분 줄일 수 있었고 비용이나 성능 측면에서도 상당 부분 개선이 가능했다.
사용하며 알게된 이 기술에 대한 자세한 내용과 적용 가이드를 지금부터 블로그에도 정리해보고자 한다!
기술 소개
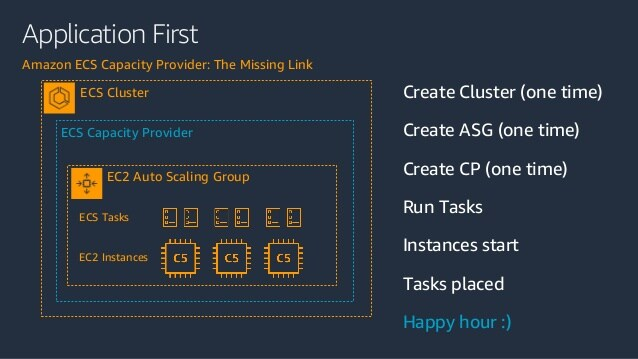
Application First
핵심 개념을 간단히 요약하면 Application-First 라는 키워드로 설명이 가능하다.
Application-First 란?
1. 어플리케이션은 각각의 요구사항을 가진다(CPU, Memory, Number of Copies … 등)
2. 인프라는 어플리케이션의 요구사항에 맞추어 반응한다(확장, 축소, 타입 선택 … 등)
이처럼 용량 공급자는 기존 ECS처럼 인프라가 먼저 구축되고 그 다음 어플리케이션을 그에 맞추어 띄우는 흐름이 아닌 어플리케이션이 먼저 스케일링에 의해 프로비저닝 상태로 들어가면 그에 맞춰 필요한 인프라를 관리해주는 자동 관리형 서비스이다.
대부분의 관리형 서비스가 그렇듯, 이 기능도 개발자가 어플리케이션의 개발에 보다 집중할 수 있도록 인프라 관리에 신경쓸 부분을 많이 줄여준다.
용량 공급자의 등장 배경
ECS는 시작 유형이 EC2와 Fargate로 나뉘어지며 이 중 EC2를 사용하면 클러스터 내에 등록되어 있는 인스턴스에 작업을 배치한다.
이 때 작업 수에 대한 Auto Scaling 이 필요한 경우에는 서비스 별 Auto Scaling(작업 수 조정 방식)을 설정한다.
하지만 이러한 서비스 Auto Scaling 은 이미 클러스터 내에 존재하는 인스턴스에 작업을 배치하는 것만 가능하기 때문에 먼저 Auto Scaling Group (ASG)를 이용하여 독립적으로 EC2 인스턴스 수를 조정해야 한다. 즉, 작업보다 EC2 인스턴스의 오토스케일링이 우선되어야 한다.
ECS 서비스에서 작업 수에 대한 Scale Out 이 완료되는 시간은 대부분 20초 내로 끝날 정도로 빠르지만 ASG의 Scale Out 은 인스턴스가 프로비저닝이 완료되기까지 적어도 3-5분 정도가 소요되기 때문에 이 독립적인 두 Auto Scaling 의 간극을 맞추기 위한 방법이 필요하다.
지금까지는 ASG 의 Scaling 트리거를 ECS Service에 비해 낮게 하여 인스턴스의 프로비저닝이 미리 수행되도록 하는 방식을 사용하는 경우가 많았는데 이러한 방식은 임계치에 대한 기준이 모호하여 리소스를 효율적으로 관리하지도 못할 뿐만 아니라 트리거가 될 지표나 단계를 수정, 보완할 때에도 양 쪽의 Auto Scaling 세팅을 독립적으로 설정해야 하는 번거로움이 있었다.
용량 공급자는 이러한 문제들을 극복하기 위해 클러스터 내에 ASG를 용량 공급자로 등록하여 태스크 단위의 오토스케일링만으로 자동적인 인스턴스 관리를 지원한다.
따라서 인스턴스에 대한 별도 오토스케일링을 할 필요 없이 내가 필요로 하는 작업 수에 맞게 쉽고 직관적인 인프라 관리를 지원해준다고 할 수 있다.
(Fargate의 경우는 ASG를 사용하지 않고 이미 AWS에서 default로 정의한 용량 공급자를 사용한다. 이번 포스트에서는 EC2에 대한 설명이 주를 이루며 Fargate에 대한 부분은 USING AWS FARGATE SPOT CAPACITY PROVIDERS 이 포스트를 보면 이해하기 쉽다.)
용량 공급자 핵심 원리
용량공급자는 먼저 원하는 작업 수를 실행하는 데에 필요한 리소스와 그에 맞는 인스턴스 수를 계산한다. 그리고 현재 돌고 있는 인스턴스 수와 비교하여 인스턴스 수를 조정하는 방식으로 인프라를 관리한다.
이 때 사용자는 Capacity Provider Reservation 이라는 메트릭으로 비율을 설정하여 이후 빠른 확장을 위한 Extra 인스턴스를 가지고 있도록 할 수도 있는데 이 메트릭 설정에 대한 자세한 내용은 뒤에 소개한다.
추가적으로 용량공급자는 관리형 인스턴스 보호 라는 기능을 가지고 있기 때문에 작업이 실행중인 인스턴스는 종료하지 않도록 하여 보다 안정적인 관리가 가능하다는 장점도 가지고 있다.
참고한 자료들 중 도움이 되었던 자료들을 글 마지막에 정리해놓았으니 원리나 활용방식 등에 대해 보다 자세한 자료를 보고싶으면 살펴봐도 좋다.
사용 효과
해당 기능을 사용하여 얻을 수 있는 효과나 활용 방안을 정리해보았다.
-
Task 수에 대한, 즉 어플리케이션 단위의 필요 요구사항에 집중하고 서버 오토스케일링에 대한 책임은 Capacity Provider에게 맡길 수 있다.=> 개발자의 인프라 관리에 대한 부담 감소
-
ECS Service 와 ASG의 독립적인 오토스케일링 세팅으로 인해 생겼던 리소스 비효율성, 불안정성을 해결하고 보다 효율적이고 직관적인 설정으로 안전한 관리 가능
=> 서버 비용 감소, 안정성 증가, Scaling 성능 향상 -
관리형 인스턴스 보호 기능을 이용한 안정성 향상=> 안정성 증가
위 사용은 Capacity Provider 를 사용하면 얻을 수 있는 기본적 이점이다.
그런데 여기에서 두 개 이상의 용량공급자를 클러스터에 등록할 수 있다는 점을 응용하면 활용할 수 있는 방식이 더욱 많아지게 된다.
 <Multiple Capacity Provider 참고 자료>
<Multiple Capacity Provider 참고 자료>
- 비용 효율적인 방식으로 전략적 인프라 설계 가능
용량공급자 전략을 두 개 이상 설정할 시에는 각 용량공급자에 대해 기본적으로 실행할 작업 수인 Base, 그리고 Scale Out 시 추가할 작업이 각 용량공급자에 어떤 비율로 배치되어야 하는 지에 대한 Weight 을 설정할 수 있다.
이 기능의 가장 대표적인 활용 방안은 On-Demand(OD) / Spot 의 비율을 조절하는 방식이며 Base 작업들은 OD로 모두 설정하여 안정성을 확보하고 이후 Scale Out 시에는 Spot 으로 설정하여 비용을 절약하는 형태로 사용이 가능하다.
ASG에도 이미 OD와 Spot 비율을 조절할 수 있는 기능이 있지만 용량공급자에서 지원하는 기능은 작업(ECS Task)에 대한 설정이고 인스턴스는 뒤따라오는 개념이기 때문에 클러스터 내에 여러 어플리케이션을 사용한다면 ASG의 기능과 달리 서비스별로 명확한 구분 및 관리가 가능할거라는 점에서 활용가치가 있다고 판단된다.
다른 활용방안 중에는 availibility zone 분산 배치 등이 있으며 이와 같이 작업에 대한 용량공급자들의 역할을 설정할 수 있는 모든 가능성이 열려있다.
=> Cost 최적화, 분산 배치 등 특정 서비스 대한 전략적 인프라 설계 활용성이 상당히 좋아짐
- 인프라 구축 자동화 시스템에 대한 가능성 & 여러 서비스를 단일 클러스터에서 관리
한 클러스터 내에서 다양한 서비스에 대한 개별 인프라 관리가 가능해지면서 인프라 구축 자동화라는 개념으로도 확장할 수 있을 것으로 보인다.
많은 자료를 찾아보았지만 용량공급자를 소개하는 문서에서는 모두 위에 소개한 이점들처럼 한 어플리케이션에 대한 인프라 Scaling 자동화 관점에서만 소개하고 있다.
하지만 클러스터 내에 다양한 서비스(어플리케이션)를 독립적으로 관리할 수 있다는 측면을 소개하는 자료나 문서는 찾지 못했다.
그래서 직접 간단한 실험을 통해 다양한 서비스가 존재하는 ECS 클러스터 내에서 각각의 용량 공급자, 즉 서버 인프라가 특정 서비스에 독립적으로 작용할 수 있음을 확인했다.
이것이 가능하다면 지금까지 클러스터와 ASG가 대부분 1:1로 대응되는 구조로 사용되었던 방식과 달리 완전히 다른 인프라 설정을 필요로 하는 서비스들을 한 클러스터 내에서 관리할 수 있게 되고 이는 인프라 관리와 자동화 측면에서 상당히 용이할 수 있다는 생각이 들었다.
이걸 정말 실제 서비스에 사용할 수 있을지는 더 구체적인 실험이 필요할 것 같다.
=> 클러스터 내 다양한 서비스 및 인프라 시스템 구축이 가능해져 관리가 편해짐
=> 이후 인프라 구축 자동화 시스템으로의 확장 가능성
실제 사용 과정
이제부터는 실제로 ECS Cluster 와 ASG 를 연결하고 서비스에 연결하는 과정을 진행해보자.
예제는 AWS 콘솔을 사용하여 진행한다.
이번 예제에서는 ECS Cluster, Service(Task Definition), ASG 를 생성하기 위한 구체적 과정은 주제와 벗어난다고 판단하여 많이 생략하였다.
순서대로 진행하면 아래와 같다.
1. ECS 클러스터를 생성한다.

테스트 용으로 빈 클러스터를 생성했다.
이 때 빈 클러스터로 만들었을 시에는 신경써주어야 할 부분이 하나 있다.
클러스터 생성시 빈 클러스터가 아니라 EC2에 대한 설정을 직접 하고 생성하면 자동으로 Auto Scaling Group이 생성된다.
이 때 생성된 ASG는 자신이 관리하는 EC2 인스턴스들이 자신을 생성시킨 ECS 클러스터에 자동으로 등록되도록, 즉 ECS의 컨테이너 인스턴스로 사용되도록 Launch Configuration에 설정이 자동으로 되어있다.
하지만 우리가 빈 클러스터를 생성하면 ASG가 만들어지지 않게 되고 따라서 이후에 직접 수동으로 만들어야 하는데 이 때에는 Launch Template(시작 템플릿), Launch Configuration(시작 구성) 역시도 직접 생성해야 하고 이 때 우리가 ECS 클러스터를 등록하는 설정을 따로 해주지 않으면 해당 ASG에서 관리되는 EC2 인스턴스들은 우리가 원하는 ECS에 등록되지 않는다.(당연하게도 독립적으로 생성한 ASG는 우리가 원하는 ECS 클러스터를 알 수 없다..!)
설정 방법은 사용자 데이터(user data)에 아래처럼 ecs container agent 파라미터 중 클러스터에 대한 정보를 등록해주는 것이다.
또한 이 설정과 함께 IAM 인스턴스 프로파일도 ECS 등록에 대한 역할을 갖도록 함께 설정해줘야 정상적으로 ECS에 등록이 된다.
이 부분은 클러스터 생성과 밀접한 관련이 있기 때문에 미리 설명했으며 실제로는 ASG를 생성해야 하는 단계에서 진행하면 된다.
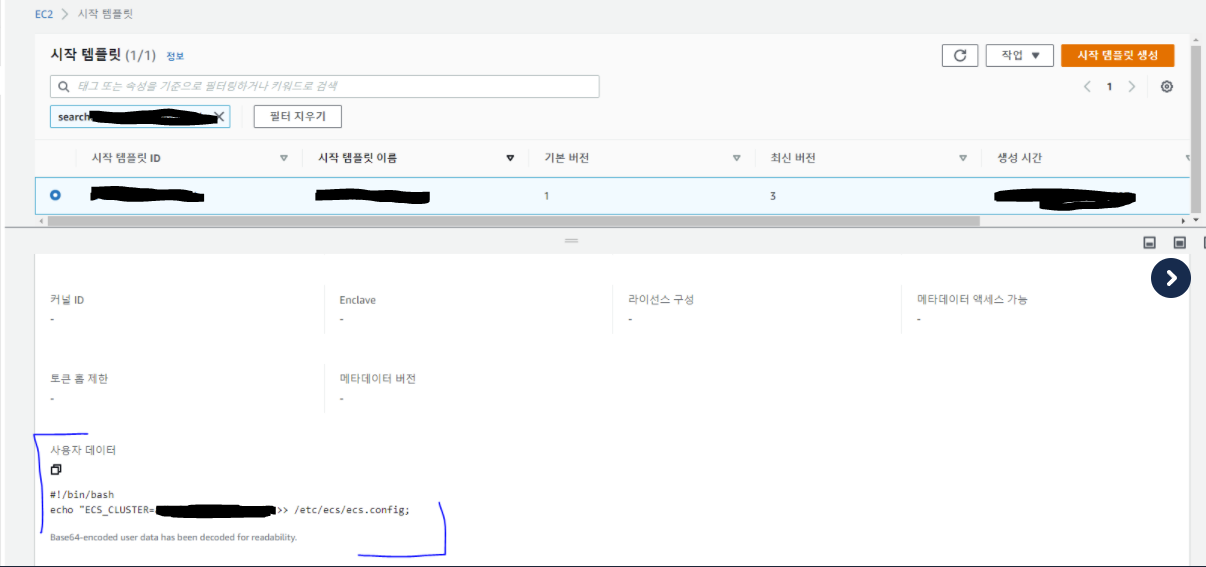
<user data 작성 형식>
#!/bin/bash
echo "ECS_CLUSTER=THIS_IS_MY_CLUSTER_NAME" >> /etc/ecs/ecs.config;
2. ASG를 생성한다.
원하는 인스턴스 세팅과 Launch Template 설정(user data 설정 확인)을 마친 뒤 ASG를 생성한다.
3. ECS 클러스터에 용량 공급자로 ASG를 등록한다.
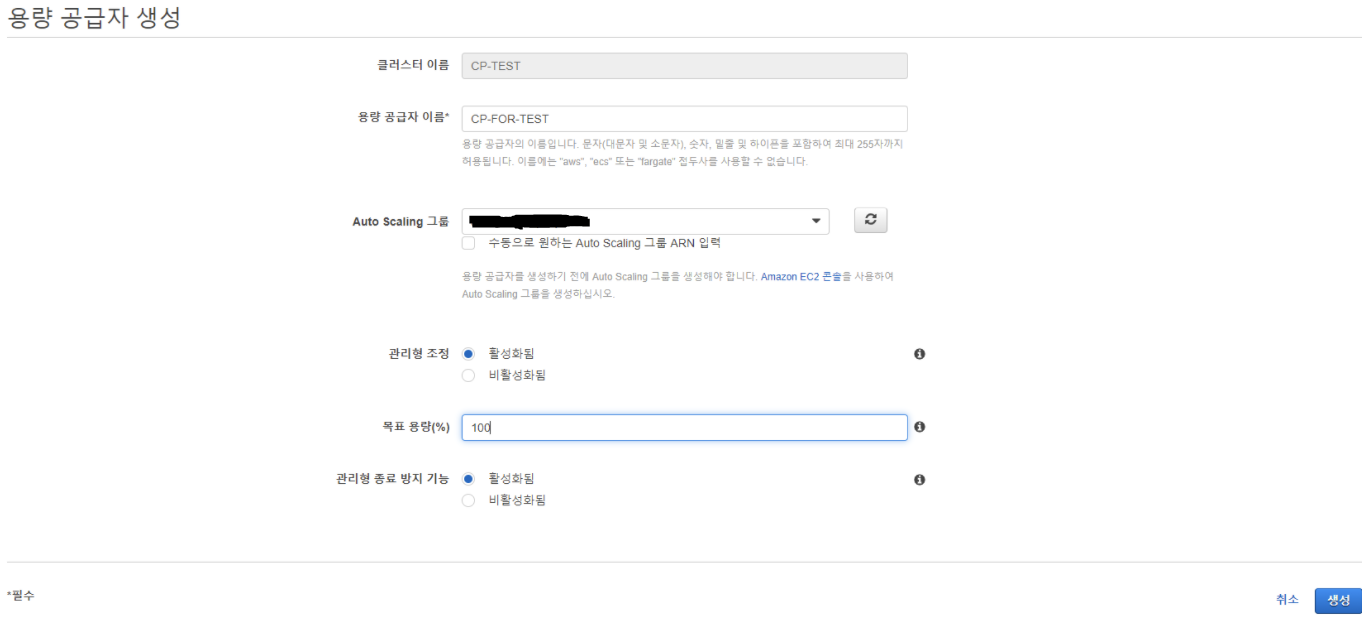
이 때 설정에 대한 설명을 간략히 하자면
목표 용량 부분이 기술 소개에서 언급했던 Capacity Provider Reservation 이라는 메트릭 지표에 대한 목표 수치를 의미한다.
이 메트릭을 쉽게 표현하면 다음과 같다.
N = 현재 Running 상태인 인스턴스 수
M = (현재 이미 실행 중인 작업 + 추가로 필요한 작업)을 실행하기 위한 모든 리소스를 위해 필요한 총 인스턴스 수
= 필요한 인스턴스 수
Capacity Provider Resrvation = 100 * M/N
= 현재 총 가동중인 인스턴스 중 실제로 지금 필요한 인스턴스의 비율(퍼센트)
즉 100%면 인스턴스 10개가 필요할 때에는 10개만 딱 실행하는 것을 목표로 스케일링을 진행하고50%면 인스턴스 10개가 필요하더라도 이후 빠른 Scaling을 위하여 20개를 실행하는 것이다.
가장 비용적으로 효율적인 것은 100%이겠지만 성능을 고려하면, 즉 빠른 Scale Out을 어느 정도 보장하고 싶다면 그 이하의 비율로 세팅하는 것이 좋을 것이다.
관리형 종료 방지 기능은 Scale In 단계에서 작동하는 기능이다.
Scale In이 필요하다고 판단했을 때 아무 인스턴스나 종료하는 것이 아니라 작업이 실행중인 인스턴스를 피해 빈 인스턴스를 종료하여 작업 성능이나 안정성을 높여주는 기능이라고 보면 된다.다만 이 기능을 사용하기 위해서는 ASG에서 한 가지 세팅이 필요한데 “인스턴스 축소 보호” 라는 기능을 켜주어야 용량 공급자에서도 관리형 종료 방지 기능을 켤 수 있다.
이렇게 설정을 마치면 용량 공급자가 등록된 것을 확인할 수 있다.
4. 용량 공급자 전략 등록
용량 공급자는 ECS 서비스를 생성할 때 시작 유형과 용량 공급자 유형 중 용량 공급자를 선택하여 등록할 수 있다.
이렇게 개별적으로 등록할 수도 있지만 클러스터에 기본 용량 공급자 전략으로 설정하여 따로 세팅을 따로 하지 않은 서비스들의 인프라를 함께 관리할 수도 있다.
아래처럼 클러스터 업데이트 화면에서 등록할 수 있다.
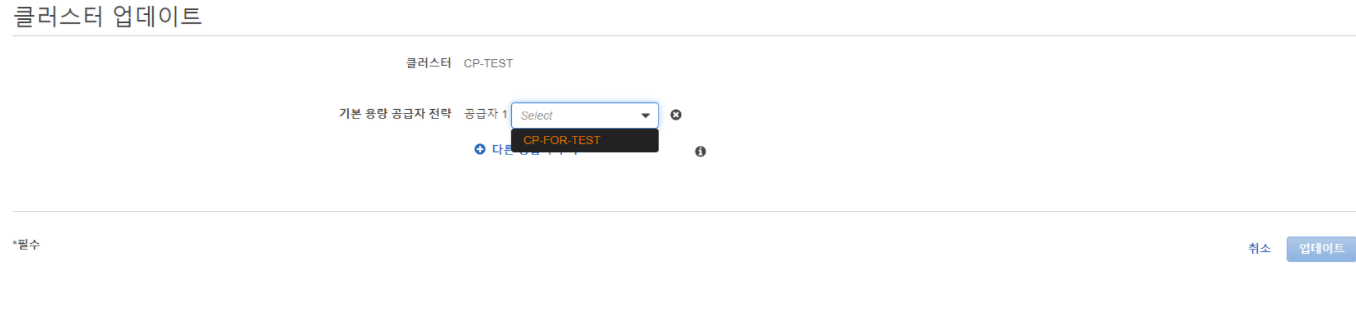
이렇게 클러스터 기본 용량 공급자 전략 등록 이외에 서비스에서도 등록하는 설정을 해보자.
5. 서비스 생성
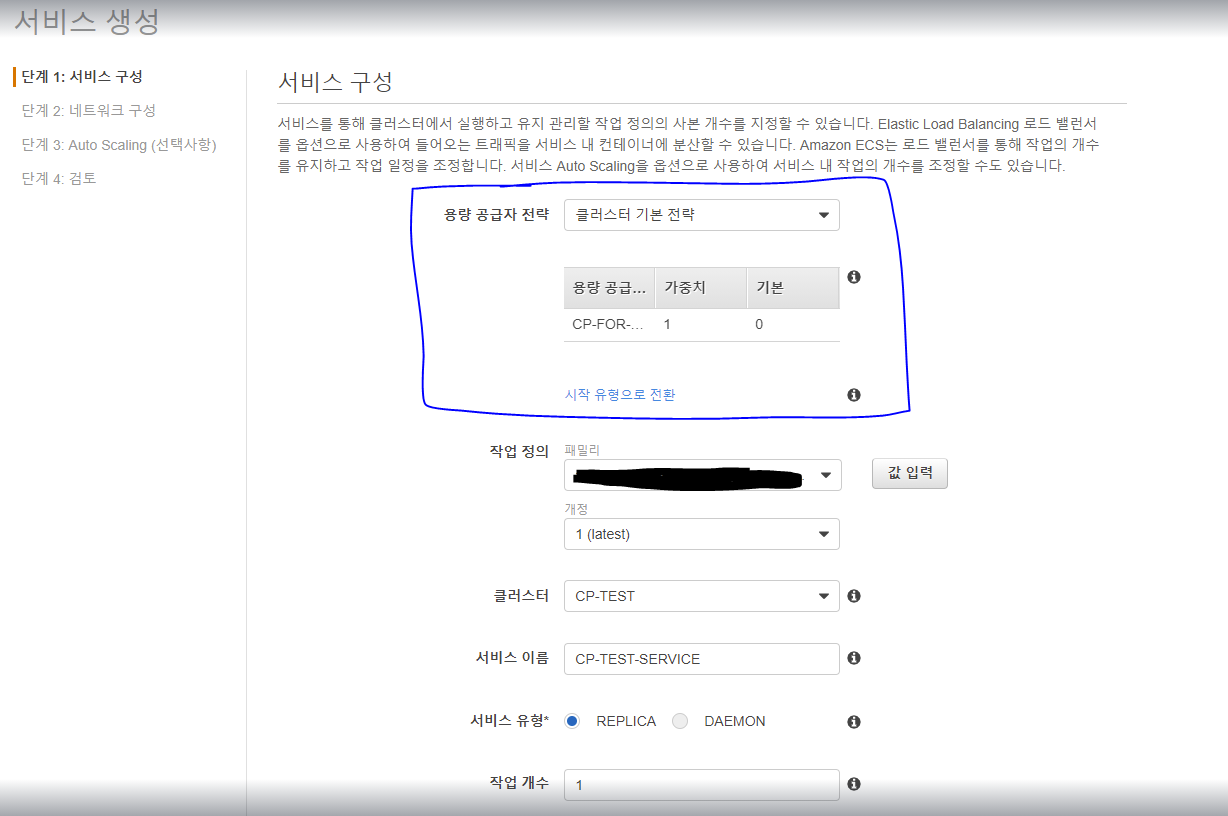
이처럼 클러스터 기본 전략이라는 유형으로 CP-FOR-TEST 가 등록되어 있음을 확인할 수 있다.
만약 클러스터 내에 등록된 다른 용량 공급자를 사용하고 싶다면 클러스터 기본 전략이 아닌 사용자 지정 전략을 선택하여 직접 지정할 수 있다.
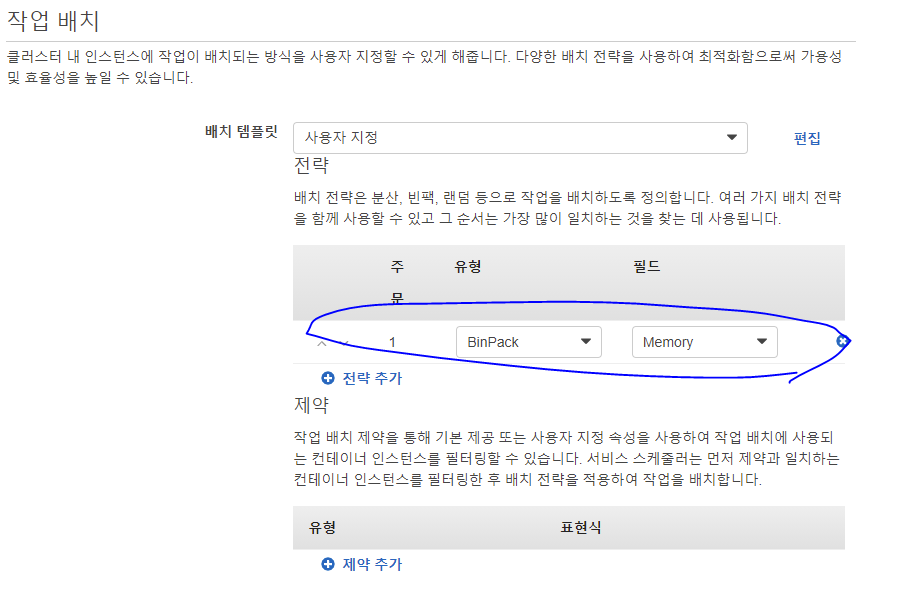
서비스 생성시 작업 배치 전략도 이 기능에 굉장히 영향을 많이 주는 부분이다.
처음 이 기능을 사용했을 때에 인스턴스 내 리소스들이 굉장히 비효율적으로 사용되고 있어서 알아내는 데에 시간이 걸렸는데 Support Center에 문의를 해보니 작업 배치 전략과 연결고리가 있었다.
이 내용은 일단은 결론부터 말하면 Binpack을 사용하는 것이 좋다.
왜냐하면 가장 비용 최적화된 형태로 작업을 배치하는 전략이 Binpack이고 이 전략이 인스턴스 수를 계산하는데 영향을 주기 때문이다.
필드는 어플리케이션에 따라 더 핵심적인 리소스를 선택하면 된다.
사실 여기까지만 하면 실제 서비스에서 사용하는 방식은 끝이고 이후부터는 이제 Auto Scaling이 제대로 작동하는지 확인해보자.
그리고 CloudWatch를 통해 Capacity Provider Reservation 메트릭의 변화를 살펴보고 인과관계를 이해해보자.
6. Auto Scaling 과정 분석
이전 단계에서는 ASG에 인스턴스가 한 개도 실행되지 않은 상태였고 여기에서 작업 수를 1로 설정하여 서비스를 생성하였다. 그래서 일단은 아래처럼 작업이 프로비저닝 상태에 들어갔음을 알 수 있다.

그리고 약 2분 후 작업이 실행되어 Running 상태로 들어갔음을 확인할 수 있다.
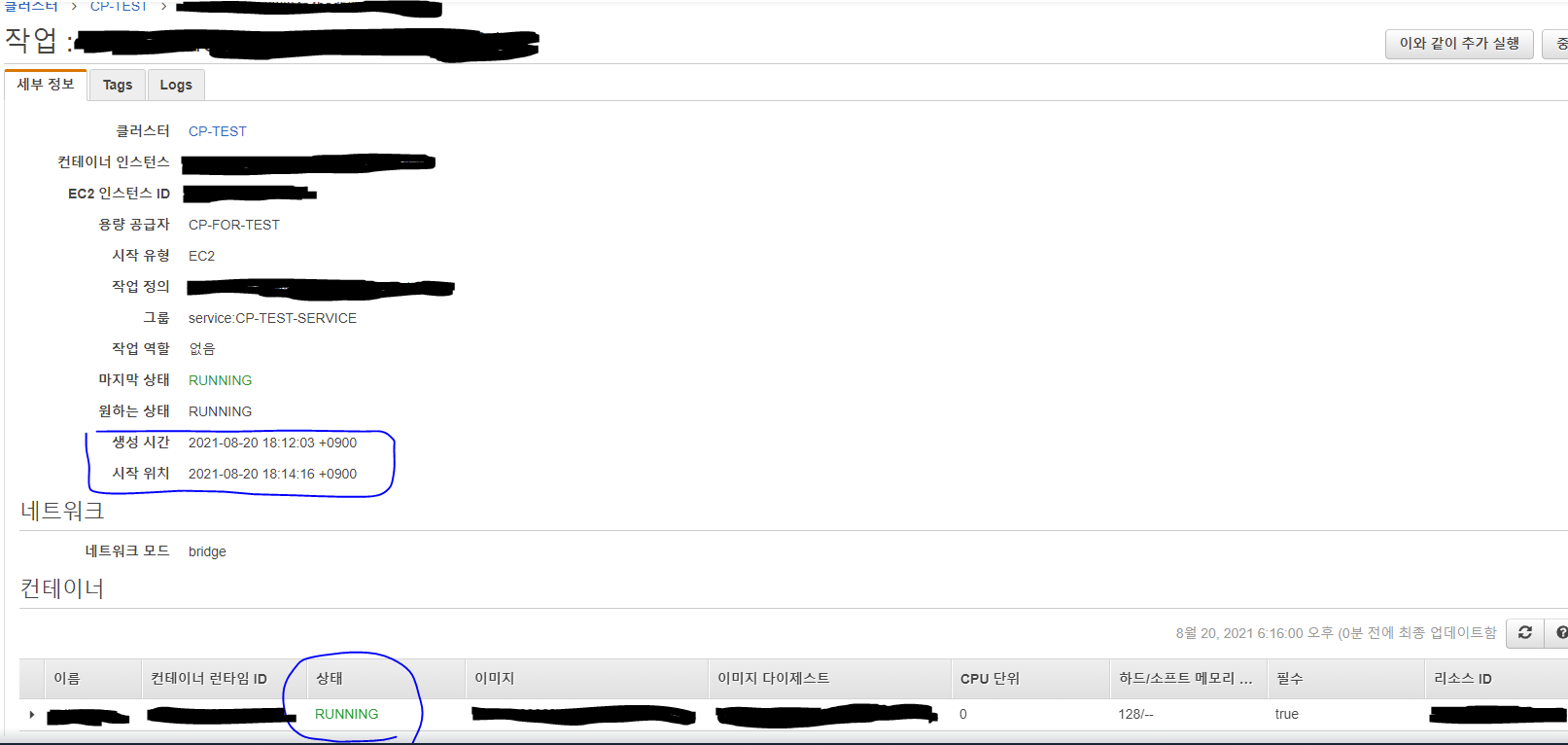
그리고 당연히 인스턴스도 확장된 것을 볼 수있다.

여기서 의문이 들 수 있는 부분은 작업 1개면 메트릭을 100%로 설정했기 때문에 인스턴스가 1개만 되어도 충분한데 왜 2개를 확장했는가? 이다.
이 부분은 위 참고문서에서 찾아본 결과 이러한 설명을 찾을 수 있었다.
if N=0 and M>0, meaning tasks are provisioning but no instances are running, then the CapacityProviderReservation = 200 and N will adjust upwards to add instances to the ASG.
위에서 소개했던 메트릭 공식에서(N, M으로 계산하는 방식) N=0, M>0 인 상황, 즉 현재 작동중인 인스턴스 수가 0개에서 Scale Out이 될 때에는 공식으로 계산이 불가하여 고정적으로 200이라는 값을 가지게 된다고 하는데 아마 이러한 공식의 특수성 때문에 2개가 생성된 것으로 보인다.
저렇게 2개가 생성된 이후에는 특수성이 사라지고 공식 계산이 가능해지기 때문에 다시 메트릭 값이 50%로 내려가고 몇 분뒤에는 인스턴스 하나가 다시 사라지는 것을 확인할 수 있었다.
이제 Capacity Provider Reservation 메트릭과 작업 수를 통해 위 과정을 분석해보자.
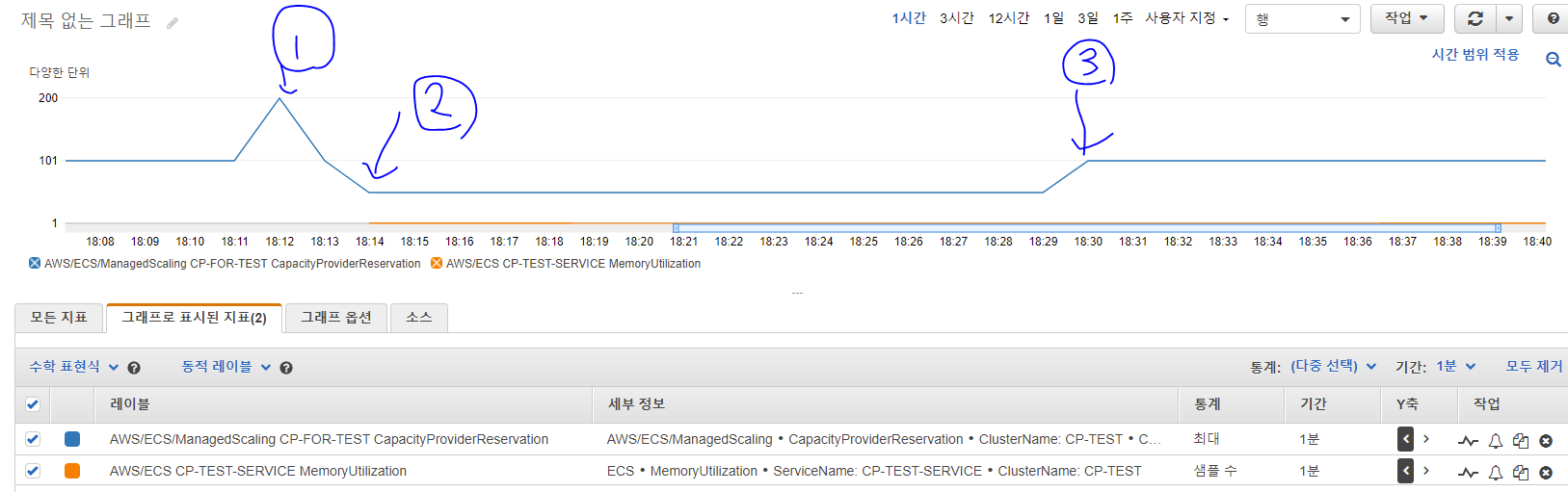
파란색은 Capacity Provider Reservation, 주황색은 서비스(CP-TEST-SERVICE)에 실행중인 작업 수이다.(참고로 서비스 내 작업 수는 서비스의 MemoryUtilization 지표의 샘플 수 통계로 확인이 가능하다.)
그래프에 쳐놓은 1, 2, 3 에 대해 설명해보자.
-
서비스에서 작업을 1개 요구하여 N=0, M>0 then Metric = 200 이 되고,
이 때 우리가 설정한 목표 메트릭 100%가 되기 위해 인스턴스가 프로비저닝 상태에 들어간다(2개) -
프로비저닝이 끝나고 ECS에서 작업이 성공적으로 인스턴스 위에 배치되었다.
하지만 우리가 필요로 하는 인스턴스 수는 1개, 현재 돌고 있는 인스턴스 2개이기 때문에 메트릭은 50%가 된다. -
목표 메트릭이 100%을 위해 인스턴스 하나를 다시 종료하여 1개가 된다.
따라서 목표 인스턴스 수 = 1, 돌고 있는 인스턴스 수 = 1 이 되어 메트릭은 100%가 되고 상태가 유지된다.
(주황색 작업 수는 아래에 있어서 안보이지만 모두 1로 맞춰져 있다.)
이러한 내부 과정을 거쳐 오토스케일링이 진행된다.
이처럼 처음 목표대로 서비스 오토스케일링(Application Requirements) 만으로 인프라가 자동을 관리되는 것을 간단하게 확인할 수 있었다.
실제 서비스 레벨에서는 보다 자세한 과정을 거칠 수 있겠지만 기본적으로 ASG를 직접 관리하는 것에 비해 상당히 효과적임을 알 수 있다.
성능 개선 정량적 분석
실험 설계
기존에 사용하던 프로세스와 현재 방식을 비교해 보았을 때 정량적으로 얼마나 성능개선이 이루어지고 비용절감이 가능한지에 대한 분석을 진행해보았다.
첫 번째 실험 상황은 평소보다 갑자기 높은 트래픽이 발생하여 한꺼번에 많은 인스턴스가 Scale Out 되어야 하고 이후에는 다시 트래픽이 낮아져 Sclae In 되어야 하는 상황이다.
이번에 오토스케일링 방식에 대한 아이디어를 찾게된 이유도 바로 위와 같은 상황이 발생했을 때 대처가 어려웠기 때문에 고민하던 것이었다.
따라서 비슷한 상황에서 얼마나 문제를 잘 해결할 수 있게 되었는지 실험해보는 것이 좋다고 판단하였다.
각각의 상황은 다음과 같다.
1. 작업이 한 개만 돌고 있다가 트래픽이 높아져 갑자기 작업이 20개가 필요한 상황이 되었다
2. 20개가 다 켜진 뒤에는 다시 트래픽이 낮아져 작업이 1개만 필요한 상황이 되었다.
1번 방식은 기존 프로세스처럼 ASG 가 ECS Cluster 의 총 Memory Reservation이 특정 수치(70%)을 넘어가면 인스턴스를 한 개 추가하고 특정 수치(30%)보다 낮아지면 한 개 제거하는 식으로 진행했다.(여기에서 인스턴스 수를 한 번에 몇 개를 추가할지에 대한 부분은 사실 트래픽이 순간적으로 얼마나 높아지는지, 인스턴스가 몇 개 필요한지를 알아야 한다. 그렇지만 ASG는 ECS 클러스터 Memory Reservation만 봐서는 이 부분을 알 수 없기 때문에 어차피 몇 개로 설정하던 더 높은 트래픽이 들어올 가능성이 항상 존재하고 높일수록 리소스 낭비가 생기기 때문에 완벽하게 잡을 수 없다. 따라서 실험에서는 1개로 지정하였다.)
2번 방식은 이번 가이드를 통해 적용한 방식으로 용량 공급자 환경을 구성하여 100% 메트릭을 기준으로 자동 조절하는 방식이다.
이번 수치 분석에서 판단할 항목은 아래 두 가지이다.
1. 성능 : 작업 20개가 다 Running 상태로 들어가는데 걸린 총 시간이 얼마나 되는가?
2. 비용 : 목표로 하는 최적의 인스턴스 수로 조절 되는가?
실험 결과
1번 기존 방식 - Scaling 결과
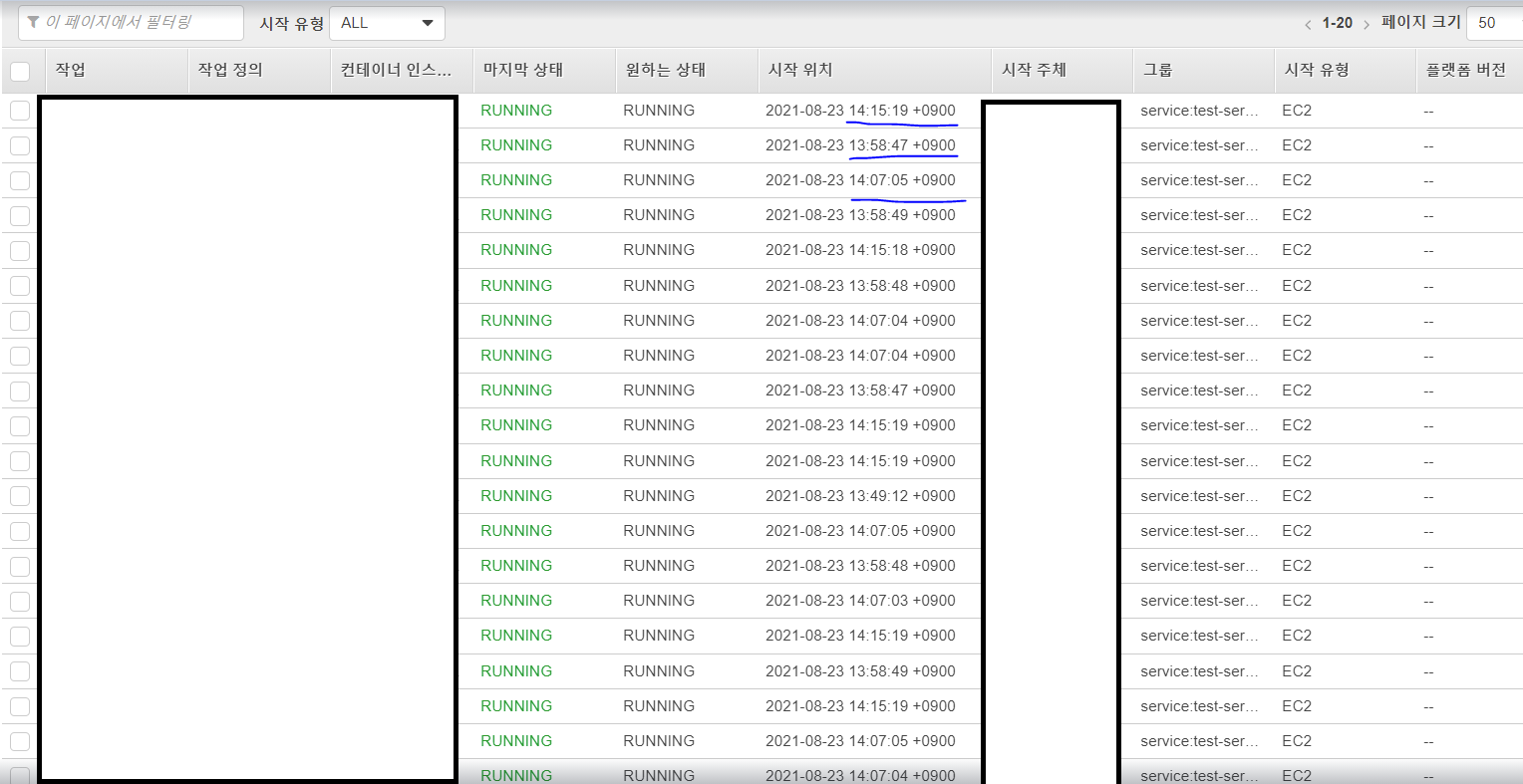
1:58:30 - Running 1 Task (작업 20개로 변경)
1:58:50 (20초 경과) - Running 7 Tasks (인스턴스 1개 full)
2:07:05 (8분 30초) - Running 14 Tasks (인스턴스 2개로 증가 + full)
2:15:19 (16분 50초) - Running 20 Tasks (인스턴스 3개로 증가)
2:23:15 (24분 45초) - 인스턴스 4개로 증가(Memory Reservation이 아직 70이 넘기 때문에 한 개 더 증가됨)
=> 총 16분 50초만에 작업 20개가 모두 실행되었다.
2번 개선된 방식 - Scaing 결과
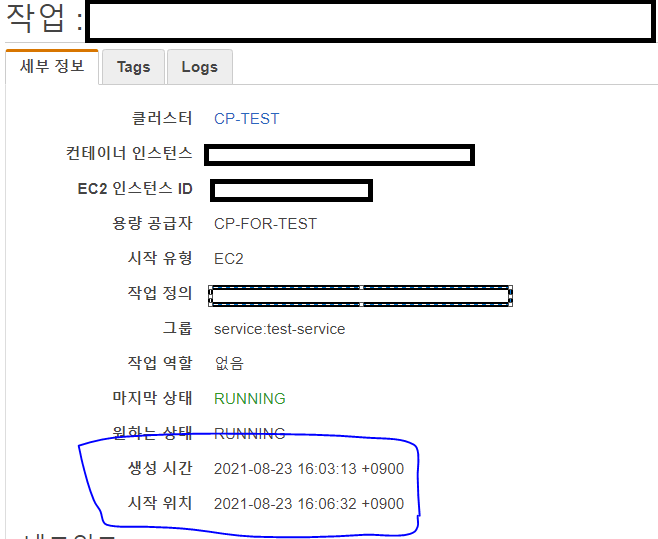
4:03:10 - Running 1 Task (작업 20개로 변경)
4:06:32 (3분 20초 경과) - Running 20 Tasks (인스턴스 1 → 3개로 증가)
=> 총 3분 20초만에 작업 20개가 모두 실행되었다
아래는 참고 사진들이다.
<1. 작업을 20개로 변경한 즉시 작업들이 바로 프로비저닝 상태로 생성된 모습>
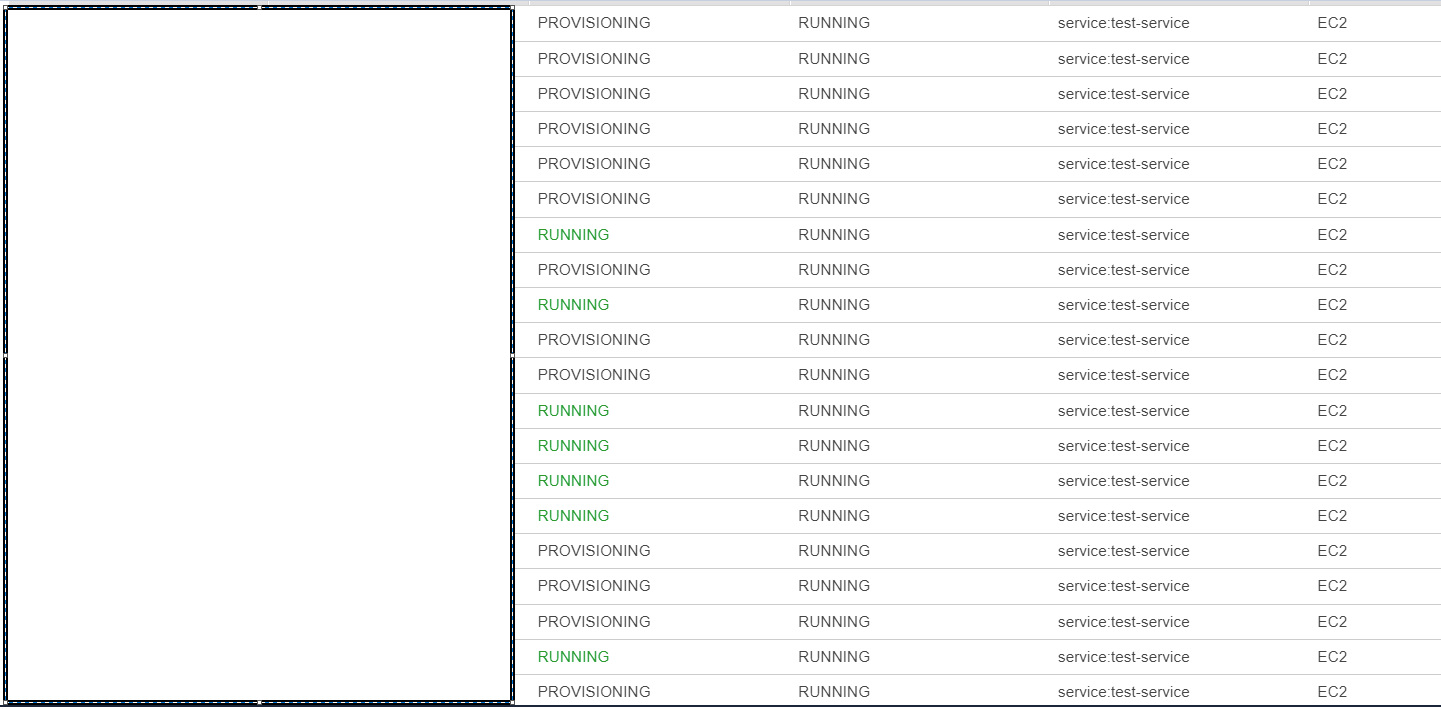
<2. 필요 인스턴스 수가 제대로 계산되어 즉시 Scale Out 되는 모습>

<3. 프로비저닝 상태로 대기중이던 작업이 인스턴스가 프로비저닝 상태일 때부터 바로 Running 되는 모습>(인스턴스의 Scale Out 시작 시간이 4:05:48 종료 시간이 4:11:04 이지만 작업이 Running 상태가 된 시간은 4:06:32 로 인스턴스가 프로비저닝 중일 때 실행이 되었음을 의미)
각 항목에 대해 분석을 해보자.
물론 이번 실험 상황에서 두 방식 모두 최적화를 진행하지 않은 기본적인 세팅을 기준으로 하였다.
실제 환경에서 Cloud Watch 경보 기준이나 인스턴스 Warm Up Period, 인스턴스 Cool down Period 등의 세팅에 대한 최적화를 진행하면 개선 효과는 달라질 수 있다.
이번 실험을 기준으로 한 성능 개선효과를 측정했음을 참고하자.
- Scale Out 시간은 16분 50초 → 3분 20초=> 약 80 % 빠른 성능 개선
- 원하는 인스턴스 수는 3개 / 기존 방식 최종 4개 / 개선 방식 최종 3개=> 기존 방식에서 발생하던 33% 낭비 사라짐
실험을 통해 알 수 있는 것은 아무리 최적화를 잘 한다고 하더라도 결국은 기존 방식대로 하면 비용과 성능 두 가지 사이에서 고민을 할 수 밖에 없다는 점이다.
작업이 오토스케일링 되는 시점보다 이전부터 인스턴스가 추가되도록 설정하면 성능은 좋겠지만 비용 낭비가 생기게 된다.
그렇다고 서비스의 오토스케일링 기준과 비슷한 기준을 잡거나 혹은 이번 실험상황처럼 ECS 클러스터의 메모리 적재량을 기준으로 판단하게 되면 단계별 설정을 하기도 어려울 뿐 아니라 이렇게 한 번에 많은 트래픽이 들어왔을 때 인스턴스의 웜업 시간으로 인해 지연 처리되는 등의 성능 이슈가 생길 것이다.
따라서 필요한 작업 수에 따라 필요한 인스턴스 량을 곧바로 계산하여 그에 맞는 인스턴스 수를 프로비저닝하고 작업을 미리 프로비저닝 상태로 대기시켜 놓음으로써 비용과 성능을 둘 다 최적화 할 수 있는 용량공급자 기능이 좋은 선택이 될 것이다.
결론
이번에는 내가 실무에서 굉장히 많이 사용하는 ECS 라는 서비스를 더욱 효율적이고 쉽게, 그리고 안정적으로 관리할 수 있는 방안에 대해 심층적으로 분석해보았다.
이를 통해 팀에서 실제로 사용하는 서비스가 비용 효율적이고 안정적인 성능을 내면서 관리될 수 있게 되었으며 이후 다른 클러스터에서 사용중이었던 서비스에도 확장하여 적용하였다.
Capacity Provider 기능을 이용하면 개발자가 어플리케이션 개발에 보다 집중할 수 있는 환경을 만들어 줄 것이라 기대하며 추후에 인프라 자동화 시스템 등을 구축할 때에도 용이하게 이용될 수 있을 것이라 생각된다.
참고자료
AWS Article - Deep Dive on Amazon ECS Cluster Auto Scaling
AWS re:Invent 2019 New Launch Feature Amazon ECS Cluster Capacity Providers | Ernest Chiang
amazon-ecs-scaling-best-practices


ecs 구성하는 중 service의 task가 scail out이 될 때 부족한 instance는 어떻게 증가시키는지 알기 어려웠는데 완벽히 이해했습니다.
fargate를 사용하고 싶지만 ec2에 비해 비용이 상당한 것 같아 조금 복잡하지만 container instance로 구축하고있네요 ㅠㅠ