
Goal
- 힙 자료구조의 이해
- 최소 힙과 최대 힙의 삽입, 삭제 과정의 이해와 구현
Heap
먼저 힙이란 완전 이진 트리 형태로서 최소값과 또는 최대값을 찾아내는데 유용한 자료구조입니다.
그렇다면 앞서 말했듯이 완전 이진트리를 충족한다는 것은 즉, 중복 값을 허용하고 반 정렬 상태를 의미하게 된다. 반정렬 상태를 충족 한다는 것은 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있다는 정도를 의미하고, 간단히 말하면 부모 노드의 키 값이 자식 노드의 키 값보다 하상 큰(작은)이진 트리를 말한다.
힙(heap)의 종류
힙에는 크게 두가지의 힙으로 나뉜다. 최대 힙과 최소 힙으로 나뉘는데 나는 이렇게 큰 분류를 설명을 하면서 개념을 좀 더 쌓아가고자 한다.
Min Heap(최소 힙)
부모 노드의 키가 자식 노드의 키보다 작거나 같은 형태를 의미한다.
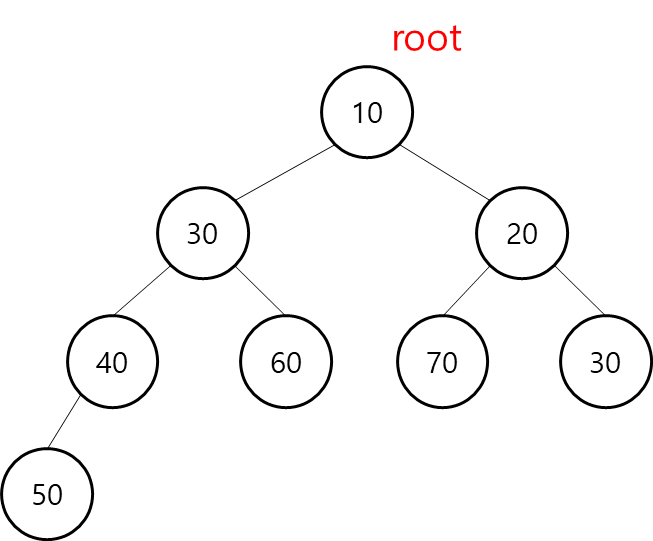
위 그림을 본다면 한 번에 이해가 가기 한결 편하다. 그림을 보면 부모 노드가 자식 노드보다 작은 상태를 유지하고 있다. 그렇기에 맨 아래 노드 자식이 없는 노드에서는 큰 값들이 있고 가장 상단 root에는 최소의 값이 있는 것을 볼 수 있는데. 이러한 완전 이진 트리 형태를 유지하면서 값이 최댓값으로 반 정렬된 상태를 최소 힙이라고 볼 수 있다.
Max Heap(최대 힙)
부모 노드의 키가 자식 노드의 키보다 크거나 같은 형태를 의미한다.
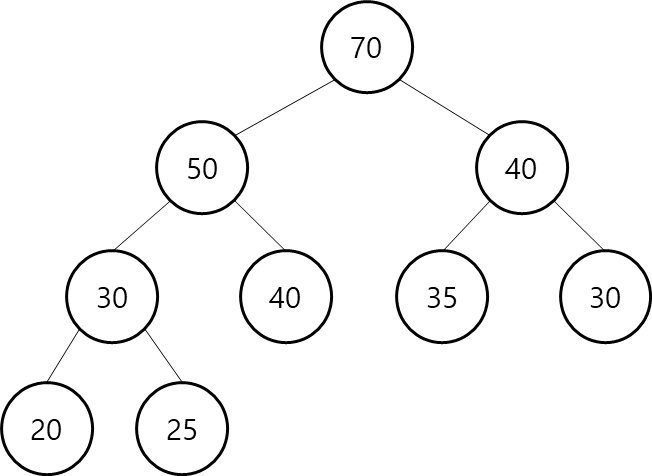
최소 힙과 유사한 형태를 띠는데 다만 차이점이라면 최상단 노드에 가장 큰 값이 나오고 하단의 자식 노드로 갈수록 값이 작아지는 형태의 완전 이진 트리이다.
최소 힙 - 삭입
그렇다면 대표적인 예시인 삽입을 하면서 전반적인 흐름이 어떻게 되는지 살펴볼 것이다.
먼저 대표적인 삽입의 흐름은 아래와 같다.
1. 트리의 가장 끝 위치에 데이터 삽입
2. 부모 노드와 키 비교한 후 작을 경우 부모 자리와 교체
그림으로 좀 더 살펴보자!!
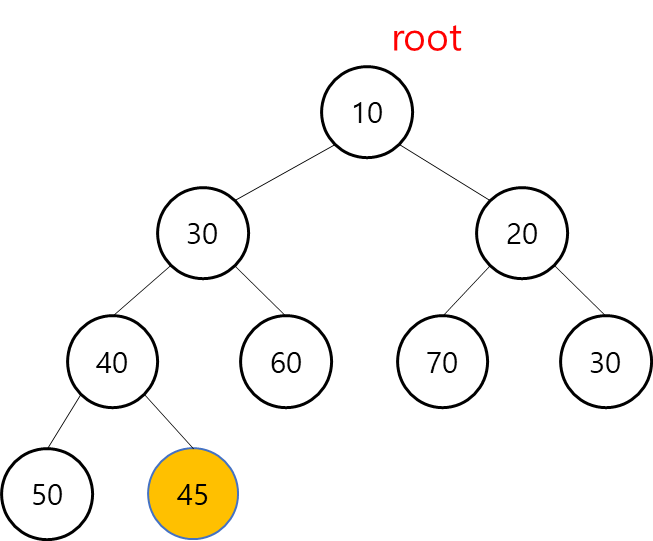
1. 그림에서 45라는 값이 추가 됐을 경우 먼저 트리의 가장 끝 위치에 45라는 노드를 삽입한다.
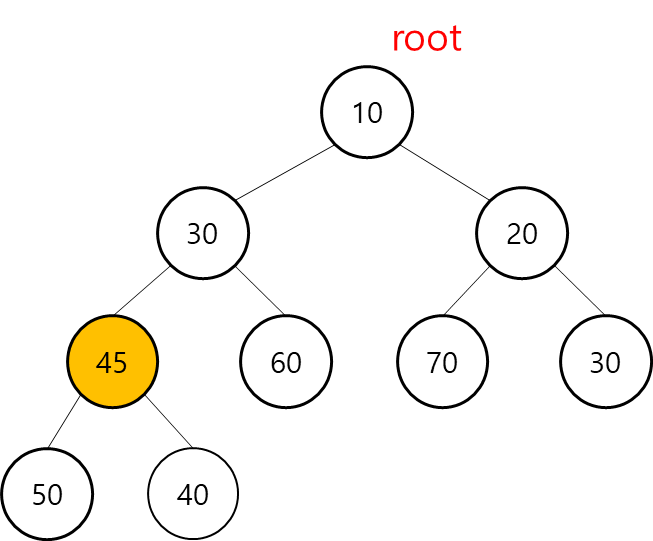
2. 부모 노드 40 과 자식 노드 45 를 비교 했을 때 자식 노드가 더 클 경우 서로의 자리를 교체한다. 그렇게 한다면 위와 같은 그림 형태가 만들어 진다.
그렇다면 이제 그림으로는 어느정도 이해가 갔을거라고 생각한다. 바로 Code로 알아보자!!
먼저 클래스를 만들어주자.
class MinHeap{
ArrayList<Integer> heap;
public MinHeap(){
this.heap = new ArrayList<>();
this.heap.add(0); // index로 찾기 위한 0의 dummy 데이터 삽입
}
}필자는 ArrayList형태로 구현할 예정이기 때문에 위와 같은 구조로 만들어 줬다.
public void insert(int data) {
//1 . 마지막 위치에 데이터 삽입
heap.add(data);
// 우리는 비교할 자식 노드의 Index를 가지고 부모 노드 cur / 2 의 Index의 데이터 끼리 비교할 것이다.
int cur = heap.size() - 1; // 마지막 위치의 데이터
// 이제 여기서 계속해서 자식 노드와 부모 노드가 큰 값이 있는지를 찾고 있다면은 값을 바꿔준다.
// 최소 비교 대상을 준수 및 부모 노드의 데이터를 최근에 가져온 데이터와 비교
while (cur > 1 && heap.get(cur / 2) > heap.get(cur)) {
int parentVal = heap.get(cur/2);
heap.set(cur / 2, data);
heap.set(cur, parentVal);
cur /= 2;
}
}그렇다면 위와 같은 형태의 삭제는 어떻게 이뤄질까?
최소 힙 - 삭제
1.최상위 노드 반환 및 삭제
2.가장 마지막 위치의 노드를 최상위 노드로 위치 시킴
3.자식 노드 중 작은 값과 비교 후 부모 노드가 더 크면 자리 교체(반복)
위와 같은 과정을 가지고 있는데 차근차근 그림을 통해 숙지를 해 나가자!
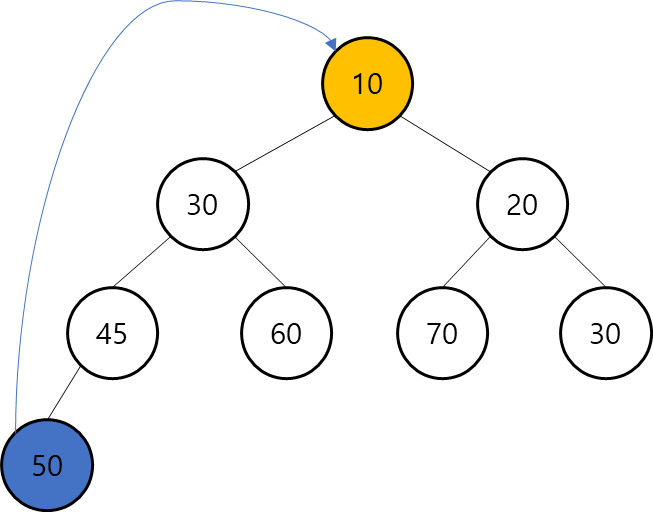
- 먼저 최상위 노드(20)를 삭제를 하고,
- 기존 20을 대체할 50 index의 마자믹 노드를 넣는다.
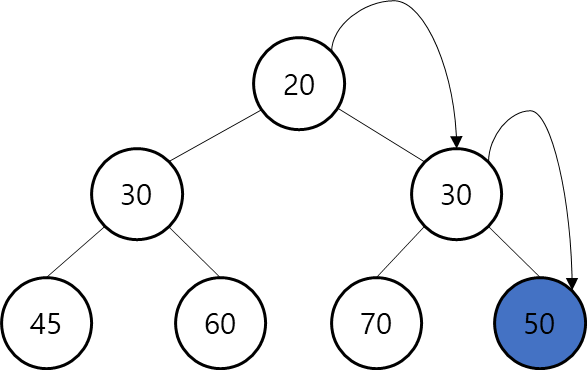
3. 자식 노드들 중에 (20 , 30)작은 값과 비교 후 부모 노드가 더 크면 자리 교체(반복) 해서 교체를 한다면 20이 최상단에 위치하게 되고 마자믹 노드에는 50이 위치하게 된다.
바로 Code로 알아보자!!
public Integer delete() {
if (heap.size() == 1) {
System.out.println("Heap is empty");
return null;
}
// 상위 데이터
int target = heap.get(1);
// 1 , 2에 해당하는 과정을 수행하고,
heap.set(1, heap.get(heap.size() - 1));
heap.remove(heap.size() - 1);
int cur = 1; // 최상위 노드 index
while (true) {
// 외쪽 자식 노드
int leftIdx = cur * 2;
// 오른쪽 자식 노드
int rightIdx = cur * 2 + 1;
int targetIdx = -1;
if (rightIdx < heap.size()) { // 오른쪽 자식 노드가 있는지 체크
//
targetIdx = heap.get(leftIdx) < heap.get(rightIdx) ? leftIdx : rightIdx;
} else if (leftIdx < heap.size()) {
// 자식 노드가 하나인 경우
targetIdx = leftIdx;
} else {
break;
}
if (heap.get(cur) < heap.get(targetIdx)) {
break;
} else {
int parentval = heap.get(cur);
heap.set(cur, heap.get(targetIdx));
heap.set(targetIdx,parentval);
cur = targetIdx;
}
}
return target;
}위와 같은 코드가 구성이되고 해당 주석을 잘 참고 하신다면 이해하는데 부족은 없을거라고 생각이 든다.
마찬가지로 내가 글을 써 내려가면서도 이해가 어렵다는 알고리즘인 거 같다. 하지만 Ologn으로써 빠르게 정렬을 해나가는 알고리즘으로써 공부해서 나쁠 거는 없다는 생각이 든다. 그리고 이러한 활용은 어떻게든 유용하지 않을까? 싶다.
