공부 목적으로 정리한 글이며 다른 분들의 포스트를 상당히 참고했습니다
Regular Expression
-
정규표현식 Regular Expression은 줄여서 regex라고 부르기도 한다.
-
특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식이다.
-
파이썬 뿐 아니라 다른 언어에서도 사용하며, 활용성이 매우 높다.
Meta Characters
- 메타 문자란 문자 본래의 의미가 아닌 특정용도로 사용되는 문자를 의미한다.
- 정규 표현식에 사용되는 메타 문자
.^$*+?\|(){}[][ ] 메타 문자
- 대괄호 안에 포함된 문자 중 하나가 포함(혹은 매치)
[abc] # a 또는 b 또는 c - 메타 문자
-문자는 [ ] 안에서 문자 사이의 범위를 의미한다. () 소괄호 안에서는 문자 '-' 그대로의 의미이다.
[a-c] # a부터 c까지
[a-zA-Z] # 모든 알파벳
[abc] # 동일한 결과^ 메타 문자
^문자는^뒤의 문자로 시작하면 문자와 매치된다.- 여러 문자열인 경우 첫 줄만 적용되지만, re.MULTILINE 옵션을 사용하면 각 줄에 적용된다.
^a # a로 시작하는 문자
aaa # 매치
baa # 매치되지 않음^문자는 [ ] 안에서 반대를 의미한다.
[^a-c] # a부터 c까지를 제외한 문자. 메타 문자
-
.문자는 두 문자 사이에 줄바꿈 문자인\n를 제외한 모든 문자와 매치된다. -
점 하나 당 하나의 문자이다.
a..b이면 a와 b 사이에 문자 2개가 있는 경우를 의미한다. '.' 문자 그대로 사용하려면 '.' 로 사용해야 한다.
a.b # a와 b 사이에 \n를 제외한 모든 문자
aab # a와 b 사이에 a는 모든 문자에 포함됨으로 매치
abc # a와 b 사이에는 문자가 없음으로 매치되지 않음.문자는 [ ] 안에서 원래 의미인 마침표를 의미한다.
a[.]b # a와 b 사이에 마침표가 있으면 매치
a.b # a와 b 사이에 마침표가 있음으로 매치
a0b # a와 b 사이에 마침표가 없음으로 매치되지 않음* 메타 문자
*문자는 앞 문자가 0개 이상일 때 매치된다.
ab*c # a와 c 사이에 b가 0개 이상인 문자
ac # a와 c 사이에 b가 0개임으로 매치
abc # a와 c 사이에 b가 1개임으로 매치
adc # a와 c 사이에 d가 1개임으로 매치되지 않음+ 메타 문자
+문자는 앞 문자가 1개 이상일 때 매치된다.
ab*c # a와 c 사이에 b가 1개 이상인 문자
ac # a와 c 사이에 b가 0개임으로 매치되지 않음
abbbc # a와 c 사이에 b가 3개임으로 매치
adc # a와 c 사이에 d가 1개임으로 매치되지 않음? 메타 문자
?문자는 앞 문자가 0~1개일 때 매치된다.
ab?c # a와 c 사이에 b가 0~1개인 문자
ac # a와 c 사이에 b가 0개임으로 매치
abbbc # a와 c 사이에 b가 3개임으로 매치되지 않음
adc # a와 c 사이에 d가 1개임으로 매치되지 않음{m} 메타 문자
{m}문자는 앞 문자가 m번 반복될 때 매치된다.
ab{3}c # a와 c 사이에 b가 3개인 문자
ac # a와 c 사이에 b가 0개임으로 매치되지 않음
abbbc # a와 c 사이에 b가 3개임으로 매치
abbbbbc # a와 c 사이에 b가 5개임으로 매치되지 않음{m, n} 메타 문자
{m, n}문자는 앞 문자가 m번에서 n번까지 반복될 때 매치된다.
ab{3, 5}c # a와 c 사이에 b가 3~5개인 문자
ac # a와 c 사이에 b가 0개임으로 매치되지 않음
abbbc # a와 c 사이에 b가 3개임으로 매치
abbbbbbc # a와 c 사이에 b가 6개임으로 매치| 메타 문자
|문자는 여러 개의 정규표현식을 or로 구분하며, 이중 하나와 매치된다.
a|b|c # a 또는 b 또는 c인 문자
ac # 매치
b # 매치
d # 매치되지 않음$ 메타 문자
-
$문자는$문자 앞의 문자로 끝나면 매치된다. -
여러 문자열인 경우 마지막 줄만 적용되지만, re.MULTILINE 옵션을 사용하면 각 줄에 적용된다.
a$ # a로 끝나는 문자
aaa # 매치
aab # 매치되지 않음\A, \Z 메타 문자
\A문자는^와 동일하지만 re.MULTILINE 옵션을 무시하고 항상 문자열 첫 줄의 시작 문자를 검사한다.\Z는$와 동일하지만 re.MULTILINE 옵션을 무시하고 항상 문자열 마지막 줄의 끝 문자를 검사한다.
\s, \w, \d
\A문자는^와 동일하지만 re.MULTILINE 옵션을 무시하고 항상 문자열 첫 줄의 시작 문자를 검사한다.\Z는$와 동일하지만 re.MULTILINE 옵션을 무시하고 항상 문자열 마지막 줄의 끝 문자를 검사한다.
문자 그대로의 \ 사용하기
- 표현식에서 문자 그대로의
\을 표현하는 방법은 2가지가 있다.
re.compile('\\\\string', '\string') #가독성이 떨어지니 2번째 방법을 자주 사용한다
re.compile(r'\\string', '\string')조건식이 있는 표현식
표현식1(?=표현식2)
- 표현식1 뒤의 문자열이 표현식2와 동일할 때 표현식1이 매치된다.
'hello(?=world)' # hello 뒤에 world가 있으면 hello 매치
helloworld # 매치
byeworld # hello가 없음으로 매치되지 않음
hellohello # hello 뒤에 world가 없음으로 매치되지 않음표현식1(?!표현식2)
- 표현식1 뒤의 문자열이 표현식2와 동일하지 않을 때 표현식1이 매치된다.
'hello(?!world)' # hello 뒤에 world가 없으면 hello 매치
helloworld # 매치되지 않음
byeworld # hello가 없음으로 매치되지 않음
hellohello # hello 뒤에 world가 없음으로 매치(?<=표현식1)표현식2
- 표현식2 앞의 문자열이 표현식1과 동일할 때 표현식2가 매치된다.
'(?<=hello)world' # world 앞에 hello가 있으면 world 매치
helloworld # 매치
byeworld # hello가 없음으로 매치되지 않음
worldworld # world 앞에 world가 없음으로 매치되지 않음(?<!표현식1)표현식2
- 표현식2 앞의 문자열이 표현식1과 동일하지 않을 때 표현식2가 매치된다.
'(?<!hello)world' # world 앞에 hello가 없으면 world 매치
helloworld # 매치되지 않음
byeworld # hello가 없음으로 매치
worldworld # world 앞에 world가 없음으로 매치python re 모듈
- python의
re모듈을 통해 정규표현식을 사용
import re정규표현식 compile 하기
re.compile()을 통해 정규표현식을 컴파일 하여 변수에 저장한 후 사용할 수 있다.- 정규표현식 변수는
_sre.SRE_Pattern패턴 클래스 객체이다.
r = re.compile('정규표현식')
print(type(r))
compile 옵션
re.DOTALL , re.S
re.DOTALL혹은re.S옵션을 넣어주면.을 사용했을 때\n또한 포함하여 매칭한다.
rg = re.compile('.')
rs = rg.findall('12\n34')
print(rs)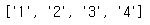 옵션을 추가하지 않으면
옵션을 추가하지 않으면 \n 은 매칭되지 않는다.
rg = re.compile('.', re.DOTALL)
rs = rg.findall('12\n34')
print(rs)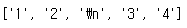 옵션을 추가하면
옵션을 추가하면 \n 또한 매칭된다.
re.IGNORECASE , re.I
re.IGNORECASE혹은re.I옵션을 넣어주면 대소문자를 구별하지 않고 매칭한다.
re.compile('[a-z]', re.IGNORECASE) # 알파벳 대소문자 모두 매칭re.MULTILINE , re.M
re.MULTILINE혹은re.M옵션을 넣어주면 앞 혹은 뒤의 문자를 확인하는^와$를 여러 줄의 문자열에도 적용 가능하게하여 매칭한다.
re.VERBOSE , re.X
-
re.VERBOSE혹은re.X옵션을 넣어주면 정규표현식에 공백과 코멘트를 추가하여 더욱 가독성 좋게 표현식을 작성할 수 있다. -
[]내의 공백은 제외
re.compile(r"""
[a-z] #알파벳 소문자
""", re.VERBOSE)매서드
match 매서드
- 패턴 객체의 match 매서드는 문자열의 시작부분 부터 검색하여 일치하지 않는 부분이 나올 때까지 찾는다.
r = re.compile('[a-z]+') # 알파벳이 하나 이상 반복되는 지
print(r.match('abcabc'))
print(r.match('123abc'))
print(r.match('abc123'))
# 또는
print(re.match('abc', 'abcabc'))
search 매서드
- search 매서드는 문자열 전체에서 검색하여 처음으로 매치되는 문자열을 찾는다.
print(r.search('abcabc'))
print(r.search('123abc'))
print(r.search('123abc'))
# 또는
print(re.search('abc', 'abcabc'))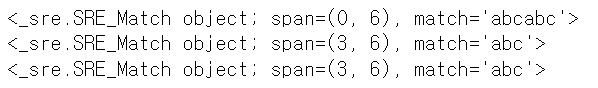
findall 매서드
- findall 매서드는 문자열 전체에서 일치하는 모든 패턴을 찾아 리스트로 반환한다.
print(r.findall('123abc456def'))
# 또는
print(re.findall('abc', 'abcabc'))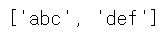
finditer 매서드
-
finditer 매서드는 문자열 전체에서 일치하는 모든 패턴을 찾아 반복가능 객체로 반환한다.
-
반환타입은 callable_iterator 이다. 반복가능한 객체의 각 요소는 match 객체이다.
fitr = r.finditer('1a2b3c4d')
print(type(fitr))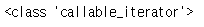
for i in fitr:
print(i)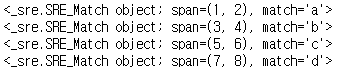
sub 매서드
- sub 매서드는 문자열에서 특정 문자 패턴을 원하는 문자로 변경할 수 있다.
text = re.sub('찾을 패턴', '패턴 변경할 내용', '원본')match 객체와 매서드
- finditer 각 요소들 처럼 반환된 match 객체는 아래와 같은 정보를 담고있다.
<_sre.SRE_Match object; span=(매치 시작지점 인덱스, 매치 끝지점 인덱스), match='매치된 문자열'>
- match 객체는 각 정보에 접근할 수 있는 매서드를 제공한다.
- group() : 매치된 문자열 출력
- start() : 매치 시작지점 인덱스 출력
- end() : 매치 끝지점 인덱스 출력
- span() : (start(), end())를 튜플로 출력
fitr = r.finditer('1a2b3c4d') for i in fitr: print(i. group(), i.start(), i.end(), i.span())

그룹화
- 소괄호를 사용해 그룹화와 캡쳐 기능을 사용할 수 있다.
그룹화
-
위의 표현식에 대한 문자들은 하나의 문자에만 적용되어 불편함이 있다.
-
예를 들어 '12'가 반복되는 '12', '1212', '121212' 와 같은 문자를 매칭하고 싶지만 '12+'는 '122', '12222'와 같이 문자 '2'에만 적용되어 반복된다.
re.findall('12+','12221212')
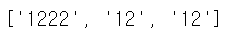
- 표현식을 그룹화 하여 문자를 적용하면 이러한 불편함을 해결할 수 있다.
re.match('(12)+','1212')
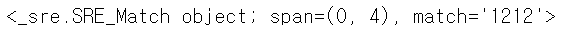
- 여러개의 그룹으로 만들 수 있다.
groups()매서드를 사용하면 그룹들을 튜플 형태로 리턴할 수 있다.group()매서드를 사용하면 각 그룹에 대한 매치 결과를 얻을 수 있다.
pp = re.match('(12)...(de)', '12abcde67') grouping = pp.groups() print(grouping)

print(pp.group(), # 전체 매치 결과 pp.group(0), # 전체 매치 결과와 동일 pp.group(1), # 첫번째 그룹 매치 결과 pp.group(2)) # 두번째 그룹 매치 결과
❓ 의문인 점: 'de' 그룹으로 매칭할 때 match 함수라면 none 결과가 나와야 하는 것 아닌지..?
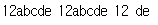
- 'find~' 매서드는 소괄호를 사용할 때 예외 사항이 있다. 이것은 소괄호의 캡쳐 기능과 연관이 있다. findall 매서드는 소괄호를 사용하면 캡처기능으로 인해 캡처 그룹만을 리스트로 반환한다.
re.findall('(12)+','12221212')

for i in re.finditer('(12)+','12221212'): print(i)

소괄호 그룹 순서
- 여는 소괄호의 순서에 따라, 가장 바깥쪽 소괄호부터 첫번째 그룹이 된다.
그룹 이름 지정
- 그룹에 이름을 지정하려면
(?P<그룹이름>표현식)형식을 사용해야 한다.
b = re.search('(?P<f>12)(?P<s>34)', '1234') print(b.group('f'), b.group('s'))
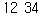
- 표현식에서 그룹이름으로 호출할 수도 있다.
re.search('(?P<f>12)(?P<s>34)..(?P=f)(?P=s)', '1234561234')
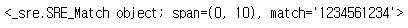
그룹 재참조
- 표현식에서
\그룹번호를 사용해 그룹을 재참조할 수 있다. 표현식 앞에r을 붙여야 한다.
re.search(r'(?P<f>12)(?P<s>34)..\1\2', '1234561234')
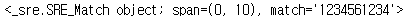
캡처
- 표현식과 매치되는 문자 중에서 원하는 부분만 추출하고 싶을 때 소괄호의 캡처 기능을 사용한다.
print(re.findall('\d{4}-(\d\d)-(\d\d)', '2028-07-28')) print(re.findall('\d{4}-(\d\d)-(\d\d)', '1999/05/21 2018-07-28 2018-06-31 2019.01.01'))
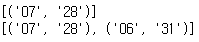
비 캡처 기능
- 소괄호를 사용해 그룹화는 하고 싶지만 캡처 기능은 사용하고 싶지 않은 경우가 있다.
'121212'만 필요하나 그룹화 때문에 '12' 또한 캡처 된 경우 ⬇️
a = re.search('((12)+)','aaa121212') print(a) print(a.group(1)) print(a.group(2))
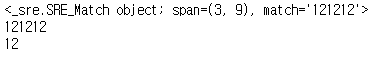
-
비캡처 그룹은
(?:<regex>)와 같이 사용한다. -
비캡처 그룹은 재참조가 불가하다.
-
소괄호 뒤에 물음표가 붙는
(?s)와 같은 모드 변경자 또한 캡처 그룹으로 작동하지 않는다.
a = re.search('((?:12)+)','aaa121212') print(a) print(a.group(1)) print(a.group(2))
두번째 그룹은 없다는 오류가 발생한다. (비 캡처 그룹으로 지정했기 때문)

