배경
우리 채팅 서비스에서는 사용자가 자신이 자주 사용하는 구문들을 등록해 놓고 숏컷(단축키)으로 빠르게 입력할 수 있는 기능이 있다. 최대 8개까지 등록할 수 있고 번호 순서는 등록된 순서를 따라 배치된다. 이 번호 순서에 맞게 단축키를 사용해 빠르게 문구를 input 창에 입력할 수 있다(예를 들어 1번째 문구를 단축키로 입력하는 경우 Ctrl + 1을 사용).
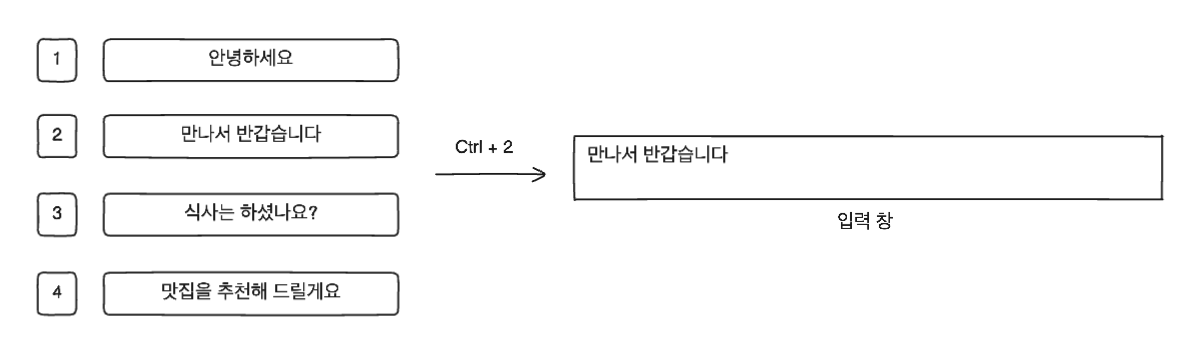
이 때 사용성 문제가 발생하였는데, 문구 수정 기능이 없는 상태에서 중간의 문구를 삭제하였을 때 바로 다음 숏컷의 순서가 당겨져 삭제된 문구의 번호를 차지하게 되는 것이 굉장히 불편했다(문구의 수정이 불가능한 것도 불편함의 이유 중 하나였던 것은 맞다).
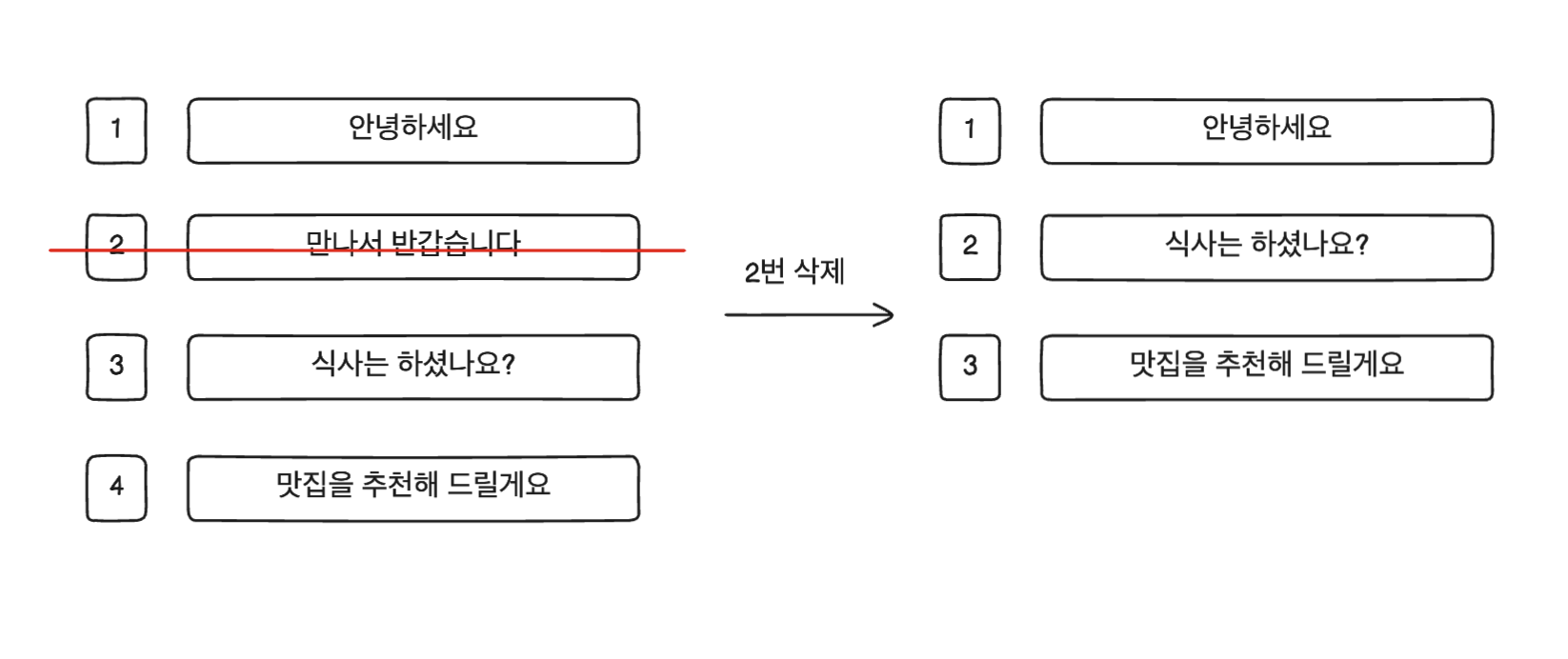
위의 그림처럼, 2번째 문구를 삭제하고 난 뒤 ‘식사는 하셨나요?’ 문구를 입력하려 Ctrl + 3 단축키를 사용하면 엉뚱하게 ‘맛집을 추천해 드릴게요’가 나오는 꼴이다.
따라서 한 번 배포를 하고 난 뒤 기획을 수정하게 되었다. 1번부터 8번까지 숏컷을 등록할 수 있는 슬롯이 고정되어 있어서 각 슬롯에 숏컷을 등록 또는 수정하도록 하여 숏컷의 번호가 바뀌는 일을 막을 수 있게 개선하였다.
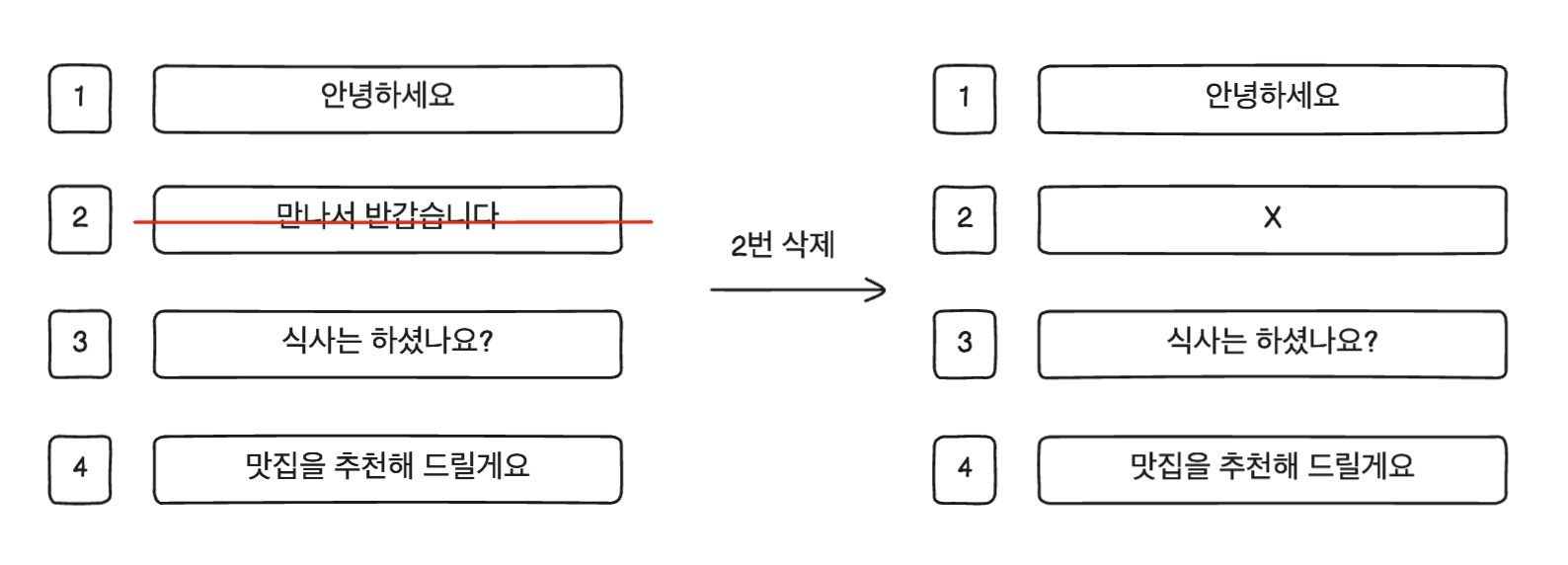
이 때 가장 고민했던 부분은 UI 변경이 아닌 숏컷 데이터 변경이었다. 기존의 숏컷 데이터는 번호가 변경될 여지가 충분했기에 각각의 숏컷을 구분하기 위해 숏컷 생성 시간을 가지고 있어야 했다.
interface Shortcut {
text: string
createdAt: Date
}
const shortcut = ref<Shortcut[]>([
{ text: '안녕하세요', createdAt: 1713338797985 },
{ text: '만나서 반갑습니다', createdAt: 1713338831991 },
{ text: '식사는 하셨나요?', createdAt: 1713338839214 },
{ text: '맛집을 추천해 드릴게요', createdAt: 1713338845178 }
])하지만 이제 문구를 삭제한다고 해서 순서가 변경되는 일이 없다. 문구의 순서(index)가 곧 id의 역할을 하게 되므로 createdAt 속성은 필요하지 않게 되었다. 따라서 다음과 같이 숏컷 데이터를 문자열의 배열로 변경하려 한다.
const shortcut = ref<string[]>([
'안녕하세요',
'만나서 반갑습니다', // 2번 삭제 시
'식사는 하셨나요?',
'맛집을 추천해 드릴게요'
])
// 만약 중간의 문구를 삭제한다면 빈 문자열로 교체해주면 된다.
const shortcut = ref<string[]>([
'안녕하세요',
'',
'식사는 하셨나요?',
'맛집을 추천해 드릴게요'
])사실 데이터를 변경하지 않아도 됐겠지만, 숏컷 배열에서의 인덱스가 해당 숏컷의 슬롯 번호 역할을 하므로 숏컷 생성 시간은 필요 없는 데이터가 되었다. 따라서 최대한 데이터 용량을 줄이기 위해 삭제하기로 결정하였다.
기존의 데이터 마이그레이션하기
이렇게 데이터 타입을 변경하려 했을 때 문제는, 이미 기존의 데이터 타입을 가지고 숏컷을 활용하고 있는 사용자들이 있다는 것이다. 지금은 숏컷 데이터를 로컬 스토리지에 저장하고 있다. 따라서 내가 숏컷 데이터 타입을 변경하려면 사용자의 로컬에 저장되어 있는 숏컷 데이터의 타입을 모두 string[]으로 변경하여야 한다.
마음 같아서는 숏컷을 싹 초기화하고 싶지만, 사용자 입장에서 잘 사용하던 숏컷이 모두 초기화되면 너무 당혹스러울 것이 분명하기 때문에 만약 예전 숏컷 데이터를 가지고 있다면 최신 타입으로 싹 교체해주는 로직이 추가되어야 했다.
시도 1. 무작정 작성
일단 무작정 작성해 보았다. 로컬 스토리지에서 숏컷 데이터를 불러 와 이 데이터가 타입이 변경되기 전 예전 데이터인지를 확인하여야 한다. 숏컷 데이터에 text 속성이 있는지 여부에 따라서 데이터를 string[]으로 가공해야 할지, 가공하지 않아도 될지가 나뉘기 때문에, 런타임에서 타입을 좁혀줄 수 있도록 Type Predicates를 활용했다.
interface Shortcut {
text: string
createdAt: Date
}
const isOldShortcuts = (shortcuts: string[] | Shortcut[]): shortcuts is Shortcut[] => {
// 배열 내 값에 하나라도 text 속성이 있다면 예전 데이터
return shortcuts.some(shortcut => typeof shortcut === 'object' && 'text' in shortcut)
}
/* 활용 */
if (isOldShortcuts(parsedShortcuts)) {
// 여기서부터 parsedShortcuts의 타입은 Shortcut[]
shortcuts = parsedShortcuts.map(shortcut => shortcut.text)
}isOldShortcuts()의 반환값이 참이라면, 타입이 Shortcut[]로 좁혀지게 된다.
위의 함수를 사용하여 getShortcutList() 함수를 작성하였다. getShortcutList()는
- 로컬 스토리지에 저장된 숏컷 데이터가 타입 변경 전의 데이터인지를 판단하여
- 타입 변경 전의 데이터면 데이터를
string[]으로 가공하고 아니라면 데이터를 가공하지 않는다. - 만약 숏컷의 개수가 8 미만이라면 나머지 값에 빈 문자열을 할당한다. 이는 숏컷의 개수가 고정되어야 하기 때문이다.
- 그리고 이 숏컷 데이터를
shortcutList변수에 할당한다.
const SHORTCUT_LOCAL_STORAGE_KEY = 'shortcuts'
const SHORTCUT_COUNT = 8
const saveShortcutsToLocal = (shrotcuts: string[]) => {
localStorage.setItem(SHORTCUT_LOCAL_STORAGE_KEY, JSON.stringify(shortcuts))
}
const getShortcutList = (): void => {
const localStorageShortcuts = localStorage.getItem(SHORTCUT_LOCAL_STORAGE_KEY)
if (localStorageShortcuts === null) {
handleEmptyShortcuts()
return
}
let shortcuts: string[] = []
const parsedShortcuts = JSON.parse(localStorageShortcuts) as string[] | Shortcut[]
// 1. string[]으로 숏컷 데이터 가공
if (isOldShortcuts(parsedShortcuts)) {
shortcuts = parsedShortcuts.map(shortcut => shortcut.text)
}
// 2. 무조건 숏컷의 개수를 8로 고정
if (shortcuts.length < SHORTCUT_COUNT) {
shortcuts = Array.from({ length: SHORTCUT_COUNT }, (_, index) =>
index < shortcuts.length ? shortcuts[index] : '',
)
}
// 3. 변수에 할당 및 로컬 스토리지 데이터 교체
shortcutList.value = [...shortcuts]
saveShortcutsToLocal(shortcuts)
}시도 2. 함수화하기
위의 코드는 나쁘지 않지만, getShortcutList() 함수의 길이가 길어지면서 가독성이 떨어진다는 단점이 있다. 각 로직마다 주석을 달아 놓았기 때문에 이해하는 데 어려움이 없는 것은 사실이다. 하지만 코드를 이해하기 위해서 주석이 필요하다는 것 자체가 코드가 개선될 여지가 있다는 사실. 주석을 굳이 작성하지 않아도 변수명과 함수명 만으로도 코드가 뜻하는 바를 나타낼 수 있다.
따라서 가공 로직들을 모두 함수로 빼내 보았다.
const extractTextFromOldShortcuts = (shortcuts: Shortcut[]): string[] => {
return shortcuts.map(shortcut => shortcut.text)
}
const makeShortcutLengthFixed = (shortcuts: string[]): string[] => {
return Array.from(
{ length: SHORTCUT_COUNT },
(_, index) => (index < shortcuts.length ? shortcuts[index] : '')
)
}
const getShortcutList = (): void => {
//...
let shortcuts
const parsedShortcuts = JSON.parse(localStorageShortcuts) as string[] | Shortcut[]
if (isOldShortcuts(parsedShortcuts)) {
shortcuts = extractTextFromOldShortcuts(parsedShortcuts)
}
if (shortcuts.length < SHORTCUT_COUNT) {
shortcuts = makeShortcutLengthFixed(extractedShortcuts)
}
shortcutList.value = [...shortcuts]
saveShortcutsToLocal(shortcuts)
}여기서 포인트는 가공 로직을 함수로 빼면서 데이터가 가공 대상인지를 판단하는 if문 역시 함수 안으로 집어넣을 수 있다는 것이다. 데이터를 가공하기 전 타입을 좁히거나 숏컷 배열의 길이를 조사해서 가공할 필요가 있는지를 조사하는 분기문이 필요한데, 이 때 함수의 인자를 잘 가공해서 함수에게 주느냐, 아니면 함수에게 인자를 던져주고 함수 내부에서 판단하느냐의 문제이다.
나는 함수 내부에 분기문을 넣는 방식을 택했다. 그 이유는 처리 대상이 아닌 인자를 받았을 때 이를 인지하고 분기하는 것은 함수의 책임이기 때문이다. 만약 분기문이 함수 바깥에 존재한다면, 해당 함수를 사용하는 쪽에서 분기문을 항상 신경써 주어야 한다. 이 함수를 재사용한다면 매번 분기문을 반복해서 작성해야 하므로 그만큼 불필요한 코드가 늘어나는 것이다. 함수에 어느 정도 유연성을 주어 예외 상황에 해당하는 인자를 주어도 함수가 알아서 해결해줄 것이라는 믿음을 위해, 즉 개떡같이 줘도 찰떡같이 알아먹는 함수를 만들기 위해 다음과 같이 수정하였다.
const extractTextFromOldShortcuts = (shortcuts: string[] | Shortcut[]): string[] => {
if (isOldShortcuts(shortcuts)) {
return shortcuts.map(shortcut => shortcut.text)
}
return shortcuts
}
const makeShortcutLengthFixed = (shortcuts: string[]) => {
if (shortcuts.length === SHORTCUT_COUNT) return shortcuts
return Array.from(
{ length: SHORTCUT_COUNT },
(_, index) => (index < shortcuts.length ? shortcuts[index] : '')
)
}
const getShortcutList = (): void => {
//...
const parsedShortcuts = JSON.parse(localStorageShortcuts) as string[] | Shortcut[]
const extractedShortcuts = extractTextFromOldShortcuts(parsedShortcuts)
const fixedLengthShortcuts = makeShortcutLengthFixed(extractedShortcuts)
const shortcuts = fixedLengthShortcuts
shortcutList.value = [...shortcuts]
saveShortcutsToLocal(shortcuts)
}아까보다는 getShortcutList()의 가독성이 더 좋아진 것 같다. 변수명도 적당히 지어진 것 같아 각각의 가공 과정이 무슨 과정인지 파악하기도 용이하다.
하지만 가공 과정의 시작과 끝이 분명하지 않다. 만약 나중에 모든 기기의 숏컷 값이 최신화되어서 위의 처리가 필요없어진다면 그 로직만 싸악 드러내고 싶다. 이를 위해서 아예 숏컷을 가공하는 로직을 다른 함수로 감싸 캡슐화해버리기로 했다.
시도 3. 캡슐화하기
함수 하나를 호출하기만 하면 알아서 데이터의 형식을 변경해줄 수 있도록 가공 로직을 하나의 함수로 감쌌다.
const handleOldShortcuts = (shortcuts: string[] | Shortcut[]): string[] => {
let updatedShortcuts = extractTextFromOldShortcuts(shortcuts)
updatedShortcuts = makeShortcutLengthFixed(updatedShortcuts)
return updatedShortcuts
}이제 숏컷을 가져오는 함수에서 다음과 같이 handleOldShortcuts() 하나만 호출하면 되므로 맨 처음과 비교했을 때 훨씬 깔끔해진 것을 볼 수 있다.
const getShortcutList = (): void => {
//...
const parsedShortcuts = JSON.parse(localStorageShortcuts) as string[] | Shortcut[]
const shortcuts = handleOldShortcuts(parsedShortcuts)
shortcutList.value = [...shortcuts]
saveShortcutsToLocal(shortcuts)
}결론
이 작업은 로컬 스토리지에 저장된 숏컷 데이터의 형식을 변경하는 작업이었다. 기획이 변경되면서 숏컷 데이터를 좀 더 간단한 형식으로 개선할 수 있게 되었고, 사용자들의 로컬에 저장된 기존 데이터의 형식만 교체하는 미션이었다. 이 데이터 가공 로직은 숏컷을 가져와 데이터를 변수에 할당하는 메인 로직은 아니므로, 최대한 주요 코드의 흐름을 해치지 않는 선에서 코드를 추가하고자 했다. 따라서 단계를 나눠 로직을 함수화하였고, 결과적으로 로직을 일일이 늘어놓는 것보다 더 깔끔하게 코드를 작성할 수 있었다.
