JPA
jpa는 Java Persistence API로 자바 ORM 기술에 대한 표준 명세이다.
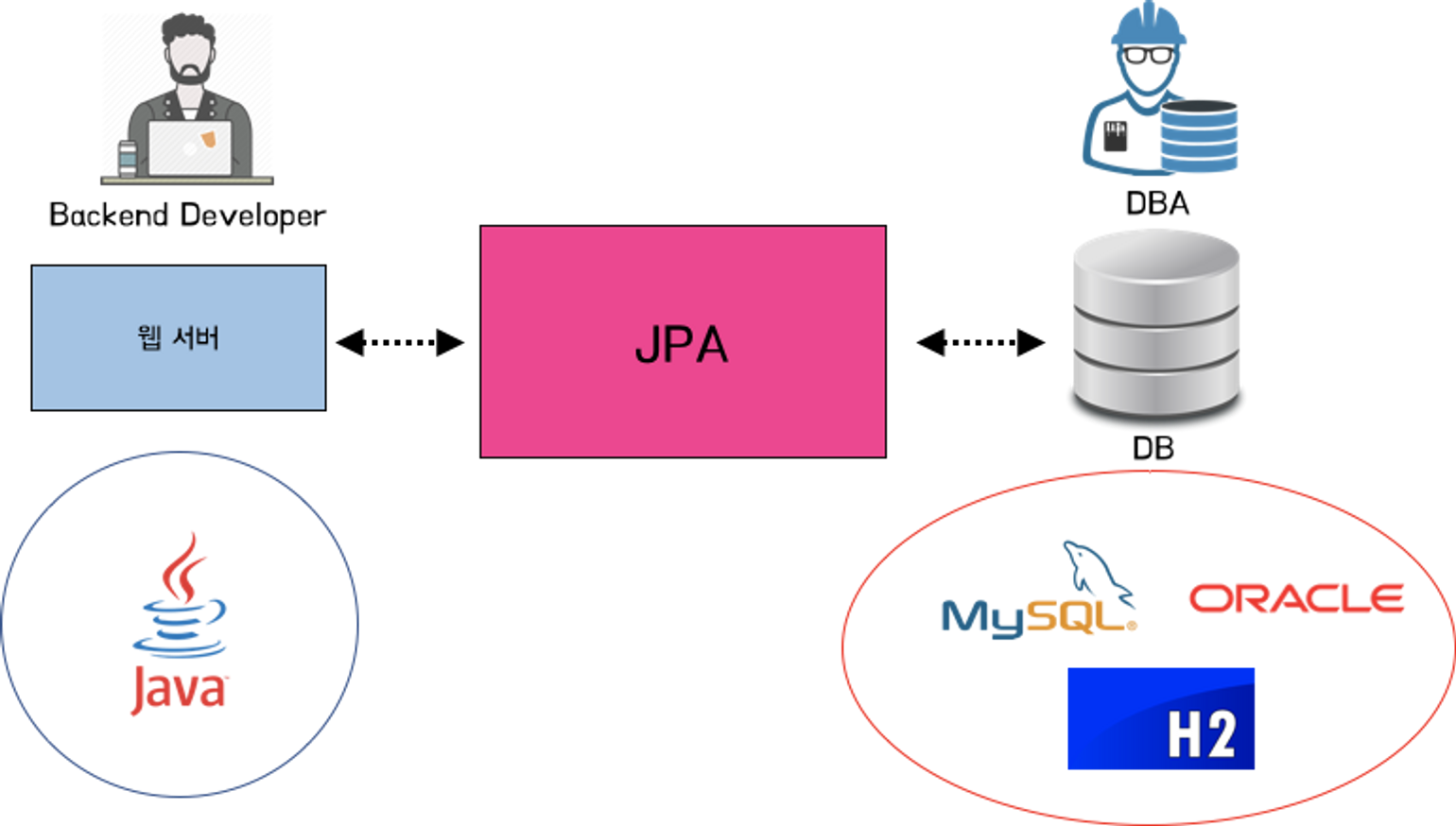
JPA는 애플리케이션과 JDBC 사이에서 동작된다.
JPA를 사용하면 DB 연결 과정을 직접 개발하지 않아도 자동으로 처리해준다.
또한 객체를 통해 간접적으로 DB 데이터를 다룰 수 있기 때문에 매우 쉽게 DB 작업을 처리할 수 있다.
구현한 프레임워크 중 사실상 표준이 하이버네이트입니다.
스프링 부트에서는 기본적으로 ‘하이버네이트’ 구현체를 사용 한다.
Entity
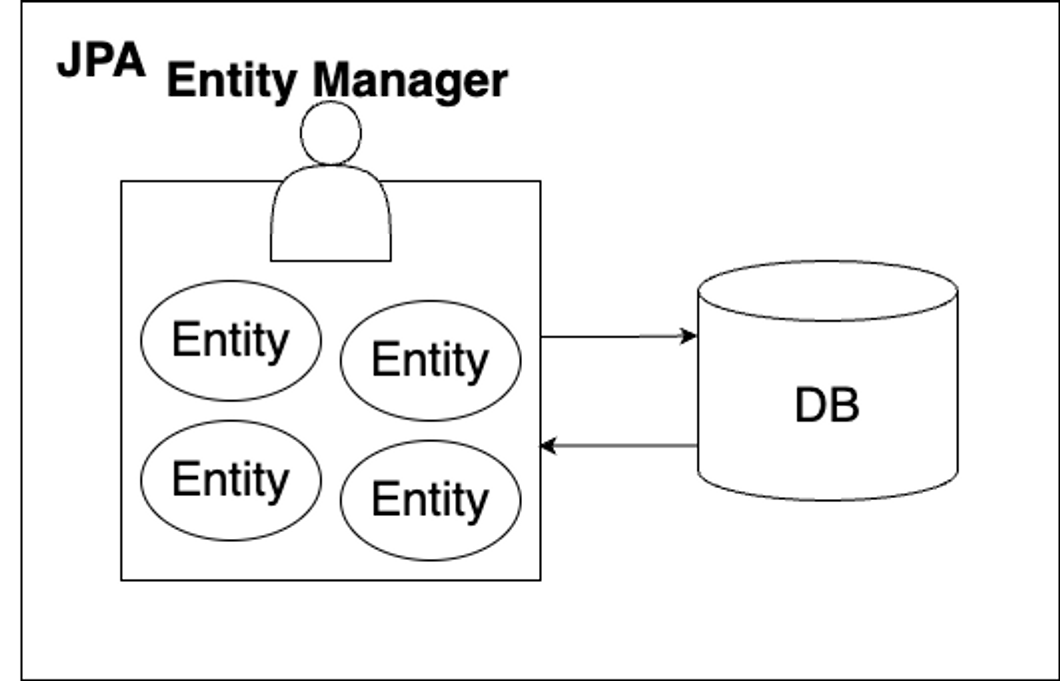
JPA에서 관리되는 클래스 즉, 객체
Entity 클래스는 DB의 테이블과 매핑되어 JPA에 의해 관리된다.
영속성 (persistence
Persistence를 객체의 관점으로 해석해 보자면 ‘객체가 생명(객체가 유지되는 시간)이나 공간(객체의 위치)을 자유롭게 유지하고 이동할수 있는 객체의 성질’을 의미
SQL을 작성하지 않아도 JPA를 사용하여 DB에 데이터를 저장하거나 조회할 수 있으며 수정, 삭제 또한 가능하다.
트랜잭션(Transaction)
데이터들의 무결성과 정합성을 유지하기 위한 하나의 논리적 개념
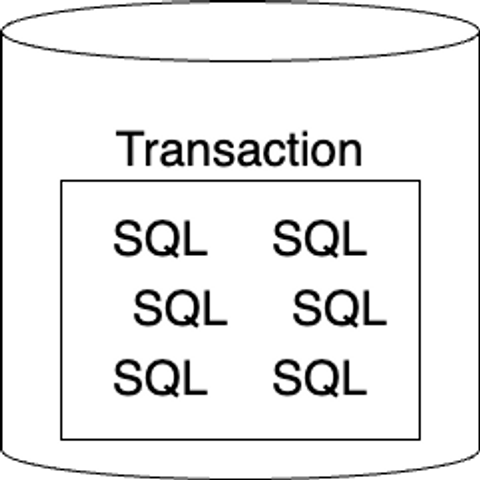
여러 개의 SQL이 하나의 트랜잭션에 포함될 수 있다.
이때, 모든 SQL이 성공적으로 수행이 되면 DB에 영구적으로 변경을 반영하지만 SQL 중 단 하나라도 실패한다면 모든 변경을 되돌린다.
JPA의 트랜잭션
DB에서 하나의 트랜잭션에 여러 개의 SQL을 포함하고 있다가 마지막에 영구적으로 변경을 반영하는 것 처럼 JPA에서도 영속성 컨텍스트로 관리하고 있는 변경이 발생한 객체들의 정보를 쓰기 지연 저장소에 전부 가지고 있다가 마지막에 SQL을 한번에 DB에 요청해 변경을 반영한다.
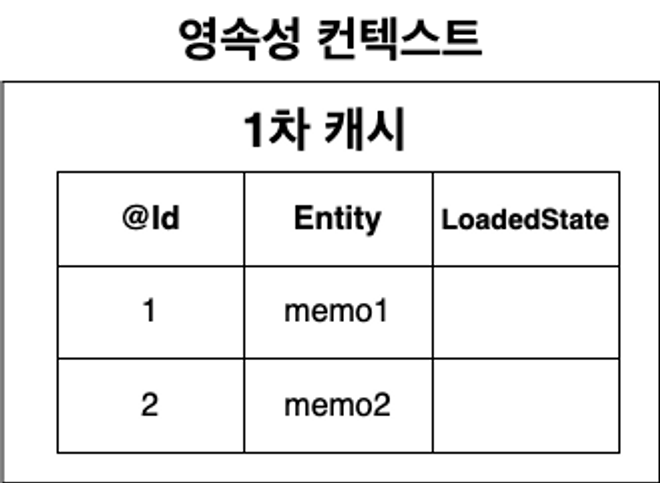
영속성 컨텍스트
Entity 객체를 효율적으로 쉽게 관리하기 위해 만들어진 공간
1차 캐시
영속성 컨텍스트는 내부적으로 캐시 저장소를 가지고 있다.
우리가 저장하는 Entity 객체들이 1차 캐시 즉, 캐시 저장소에 저장된다.
캐시 저장소는 Map 자료구조 형태
key에는 @Id로 매핑한 기본 키 즉, 식별자 값을 저장
value에는 해당 Entity 클래스의 객체를 저장
영속성 컨텍스트는 캐시 저장소 Key에 저장한 식별자값을 사용하여 Entity 객체를 구분하고 관리한다.
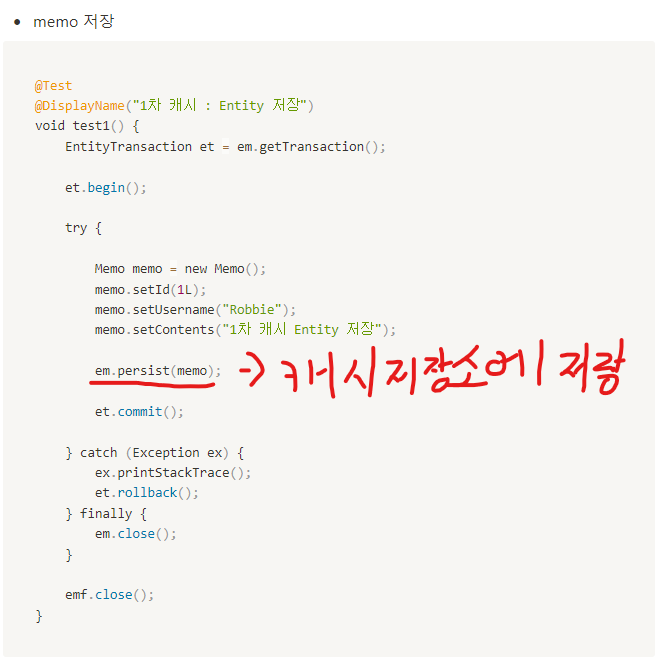
Entity 저장

em.persist(memo); 메서드가 호출되면 memo Entity 객체를 캐시 저장소에 저장
Entity 조회
캐시 저장소에 조회하는 Id가 존재하지 않은 경우
-
캐시 저장소 조회
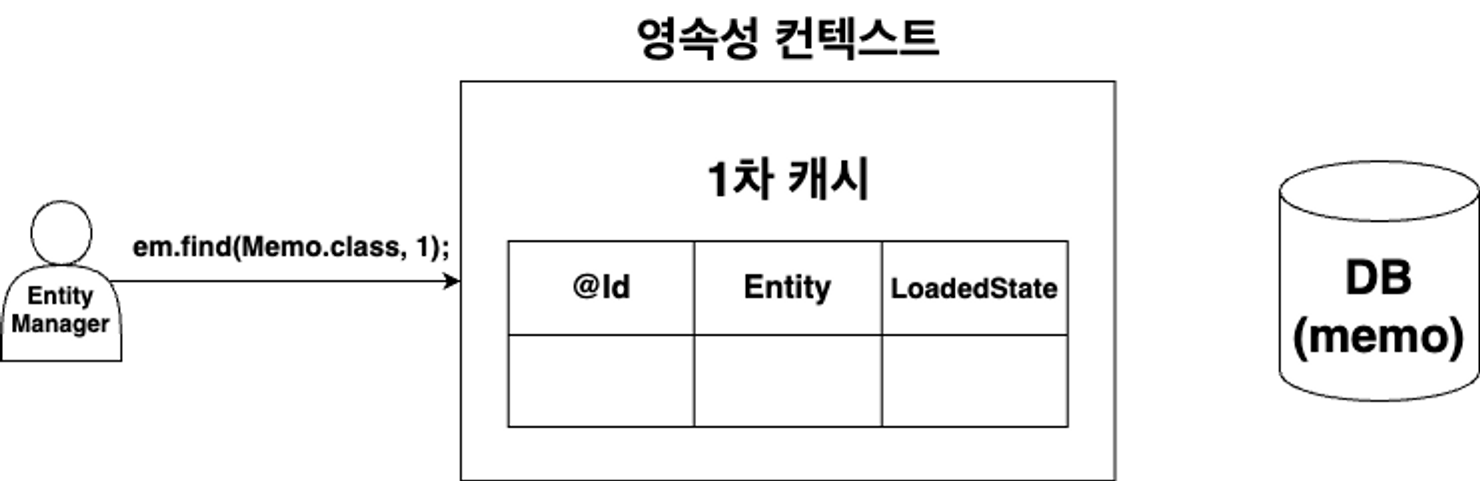
-
DB SELECT 조회 후 캐시 저장소에 저장
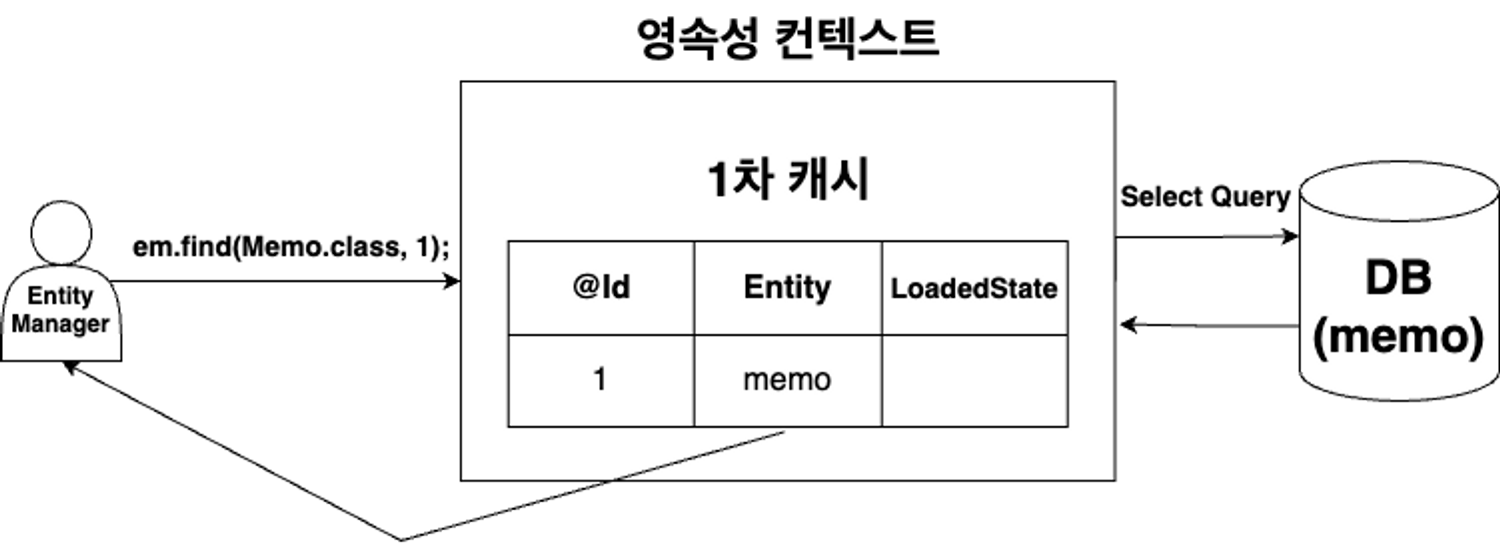
em.find(Memo.class, 1); 호출 시 캐시 저장소를 확인 한 후 해당 값이 없을 경우 →
DB에 SELECT 조회 후 해당 값을 캐시 저장소에 저장하고 반환합니다
캐시 저장소에 조회하는 Id가 존재하는 경우
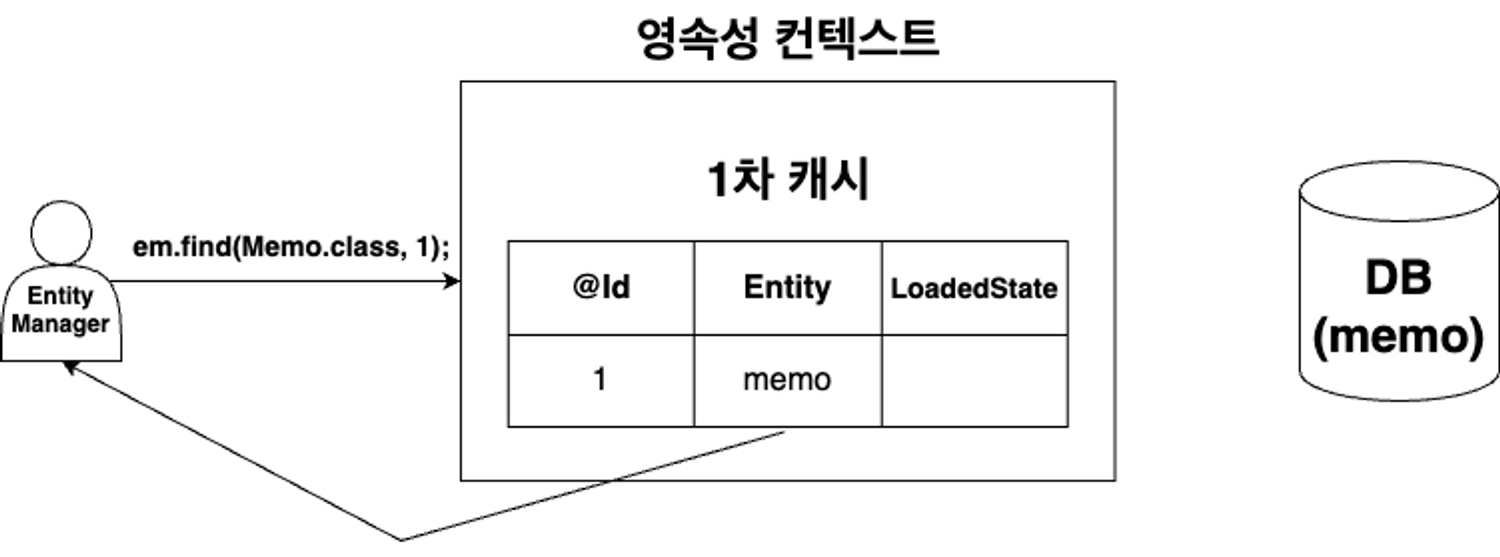
em.find(Memo.class, 1);호출 시 캐시 저장소에 식별자 값이 1이면서 Memo Entity 타입인 값이 있는지 조회 → 값이 있다면 해당 Entity 객체를 반환
Entity 삭제
삭제할 Entity를 조회한 후 캐시 저장소에 없다면 DB에 조회해서 저장
em.remove(entity);
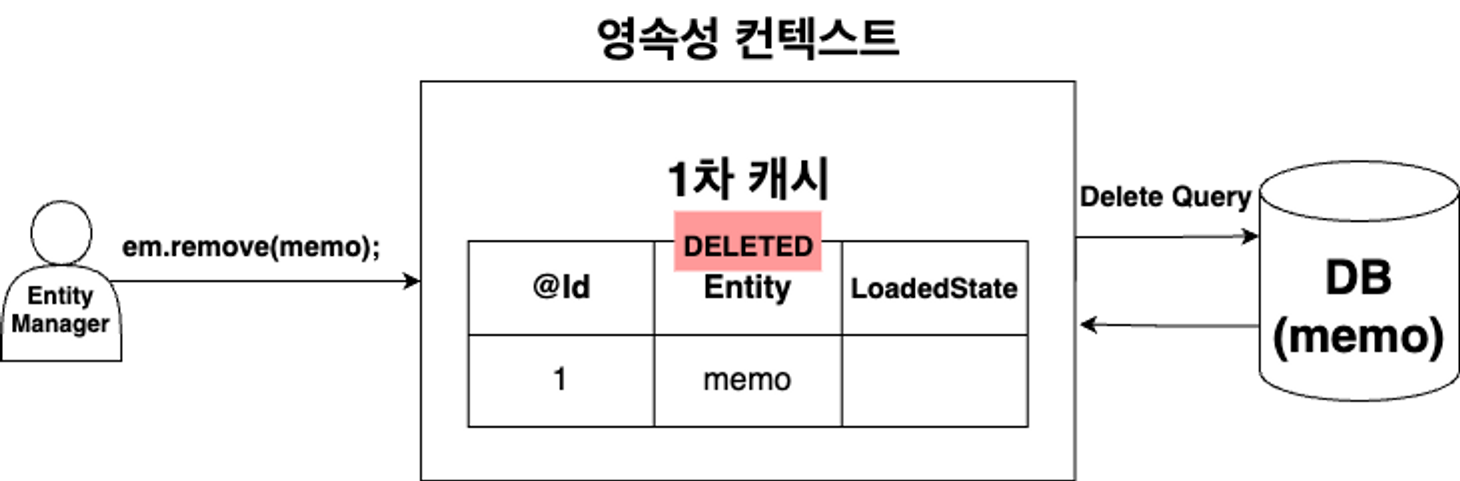
em.remove(memo); 호출 시 삭제할 Entity를 DELETED 상태로 만든 후 트랜잭션 commit 후 Delete SQL이 DB에 요청된다.
1차 캐시의 장점
- DB 조회 횟수를 줄임
- '1차 캐시'를 사용해 DB row 1개 당 객체 1개가 사용되는 것을 보장 (객체 동일성 보장)
Entity 정리
-
Entity 객체들은 영속성 컨텍스트에 저장된다. → 바로 반영되는건 X
-
EntitiyTransaction을 커밋하여 영구적으로 DB에 한번에 반영한다.
-
Enitity 객체들은 영속성 컨텍스트의 내부 저장소인 1차 캐시에 저장되며 캐시 저장소는 Map 자료구조이다. → 영속성 컨텍스트는 캐시 저장소 Key에 저장한 식별자값을 사용하여 Entity 객체를 구분하고 관리
-
Entity 조회의 경우 캐시 저장소에 고유키 값(ID)이 존재하지 않는 경우 DB에 조회 후 해당 값을 캐시 저장소에 저장한다. → 이때 DB에서 데이터를 조회만 하는 경우에는 데이터의 변경이 발생하는 것이 아니기 때문에 트랜잭션이 없어도 조회가 가능
반대로 캐시 저장소에 조회하는 고유 키 값 ID값이 있을 경우 캐시 저장소에서 조회 후 해당 Entity 객체를 반환한다.
- Entity 삭제는 먼저 조회를 한 후 캐시 저장소에 없다면 DB에 조회해서 저장한다. 이후 remove 매서드 호출시 Deleted상태로 캐시에 저장 된 다음 Transaction commit 후 Delete SQL이 DB에 요청
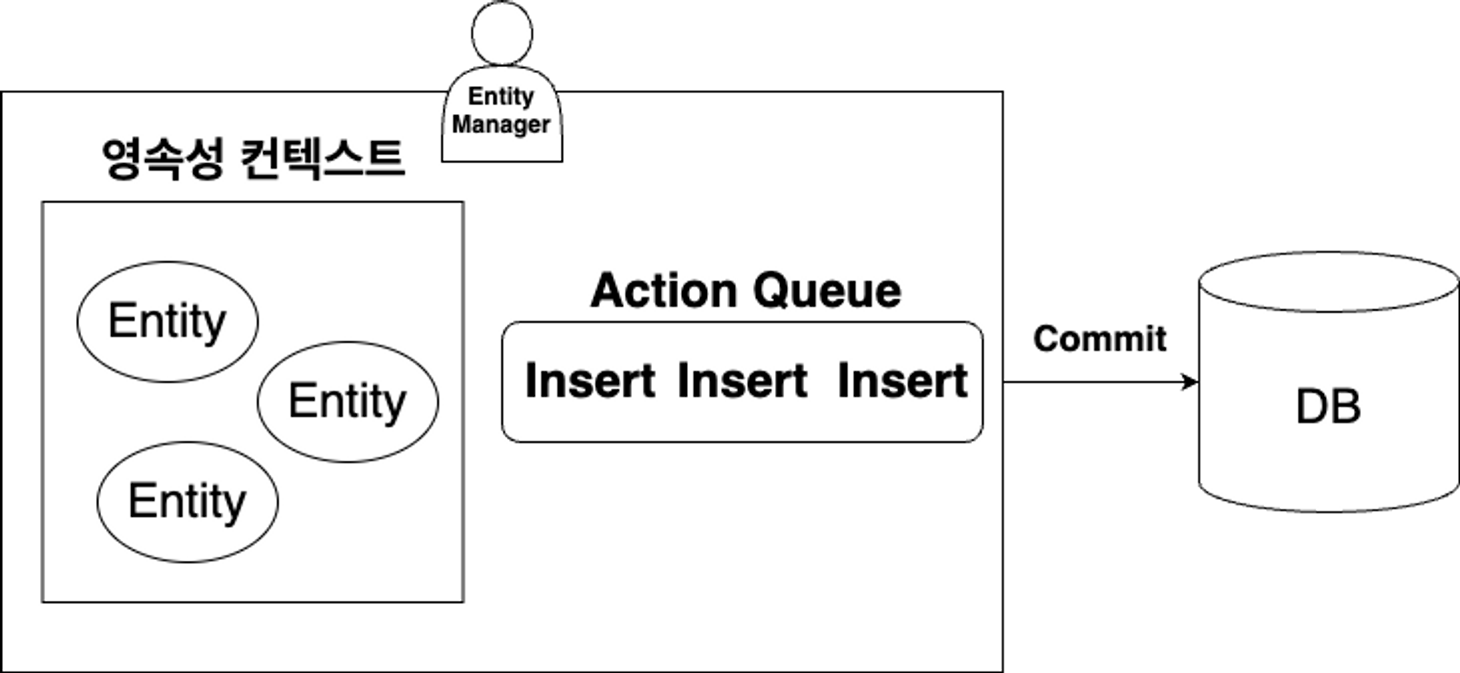
쓰기 지연 저장소 (Action Queue)
JPA가 트랜잭션처럼 SQL을 모아서 한번에 DB로 Commit하여 반영한다.
JPA는 이를 구현하기 위해 쓰기 지연 저장소를 만들어서 SQL들을 모아뒀다가 트랜잭션 Commit 후 한번에 DB에 반영한다.
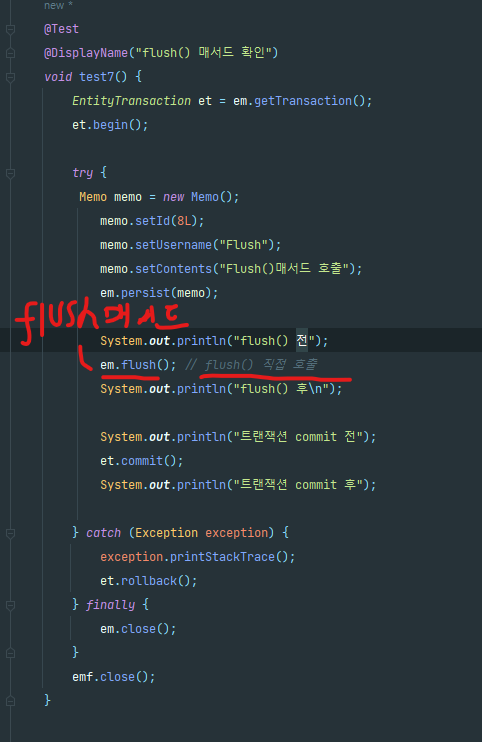
Flush() 매서드
트랜잭션 commit 후 추가적인 동작이 있는데 바로 em.flush(); 메서드의 호출이다.
flush 메서드는 영속성 컨텍스트의 변경 내용들을 DB에 반영하는 역할을 수행한다.
즉, 쓰기 지연 저장소의 SQL들을 DB에 요청하는 역할을 수행한다.
실행 결과
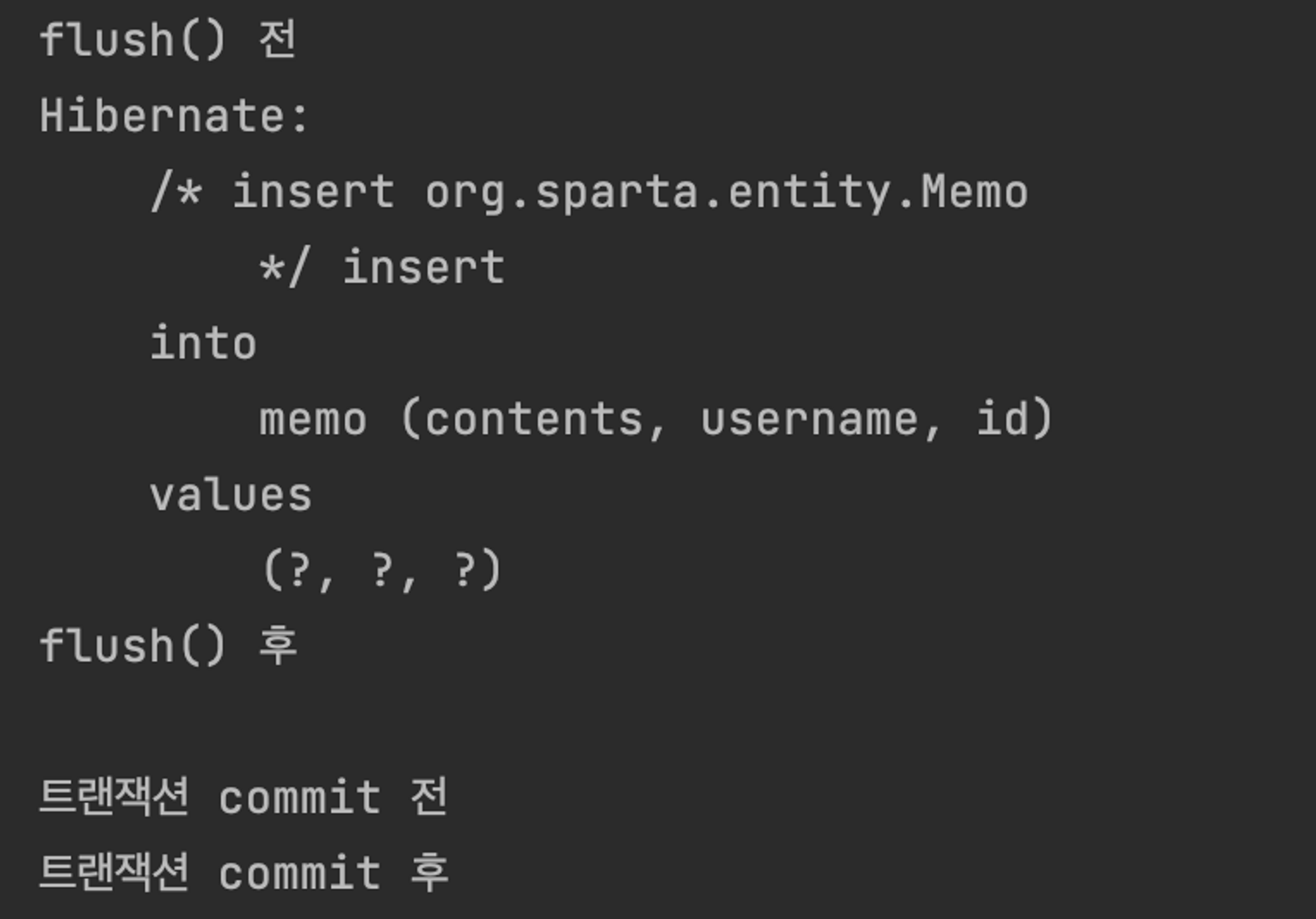
em.flush(); 메서드가 호출되자 바로 DB에 쓰기 지연 저장소의 SQL이 요청되었다.
이미 쓰기 지연 저장소의 SQL이 요청 되었기 때문에 더 이상 요청할 SQL이 없어 트랜잭션이 commit 된 후에 SQL 기록이 보이지 않는다.
만일 트랜잭션 설정하지 않을 경우?
트랜잭션을 설정하지 않고 플러시 메서드를 호출하면 no transaction is in progress 메시지와 함께 TransactionRequiredException 오류가 발생

Insert, Update, Delete 즉, 데이터 변경 SQL을 DB에 요청 및 반영하기 위해서는 트랜잭션이 필요하다.
변경 감지 (Dirty Checking)
JPA에서의 Update 처리는 별도의 매서드가 있을 것 같지만 있지 않다.
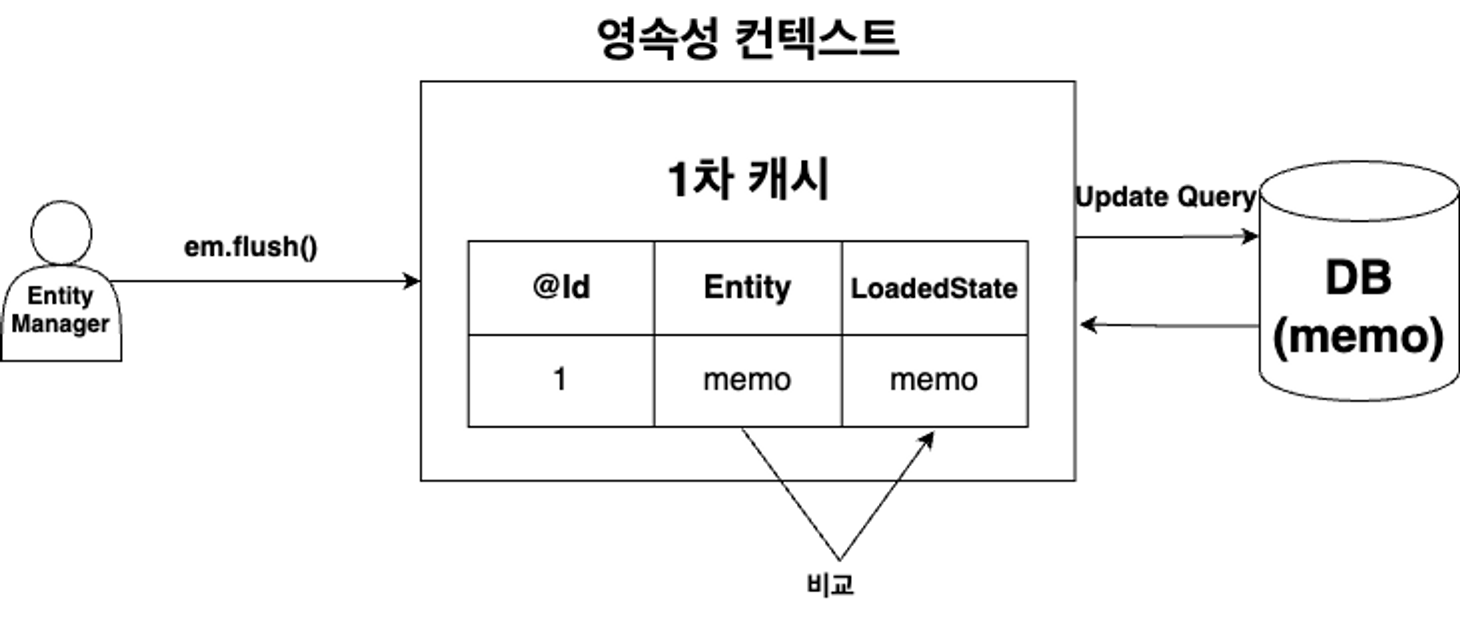
Update 진행과정
- JPA는 영속성 컨텍스트에 Entity를 저장할 때 최초 상태(LoadedState)를 저장한다.
- 트랜잭션이 commit되고 em.flush(); 가 호출되면 Entity의 현재 상태와 저장한 최초 상태를 비교한다.
- 변경 내용이 있다면 Update SQL을 생성하여 쓰기 지연 저장소에 저장하고 모든 쓰기지연 저장소의 SQL을 DB에 요청한다.
- 마지막으로 DB의 트랜잭션이 commit 되면서 반영된다.
결론적으로 변경하고 싶은 데이터가 있다면 먼저 데이터를 조회하고 해당 Entity 객체의 데이터를 변경하면 자동으로 Update SQL이 생성되고 DB에 반영된다. → 이 과정을 DirtyChecking 이라 한다.
