EDA
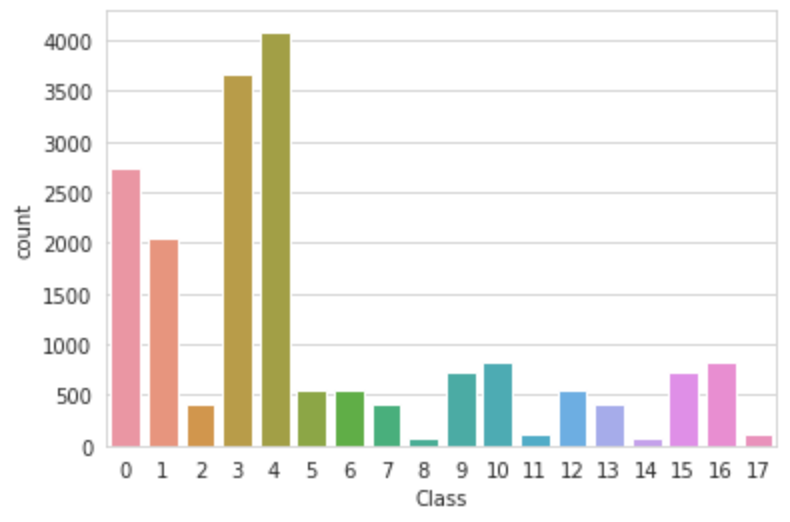
• gender / race / age 를 조합하여 총 18 개의 classes
• (height=512, width=384) 이미지를 입력 받아 class 예측 하는 image classification
• 총 2700명, 인 당 7장(정상 착용 5장 / 미착용 1장 / 잘못 착용 1장), 총 18900 장
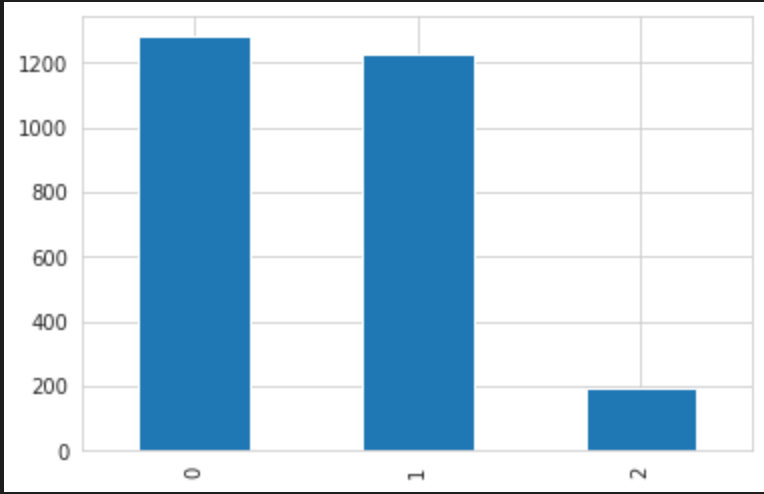
• male 1042 명, female 1658 명
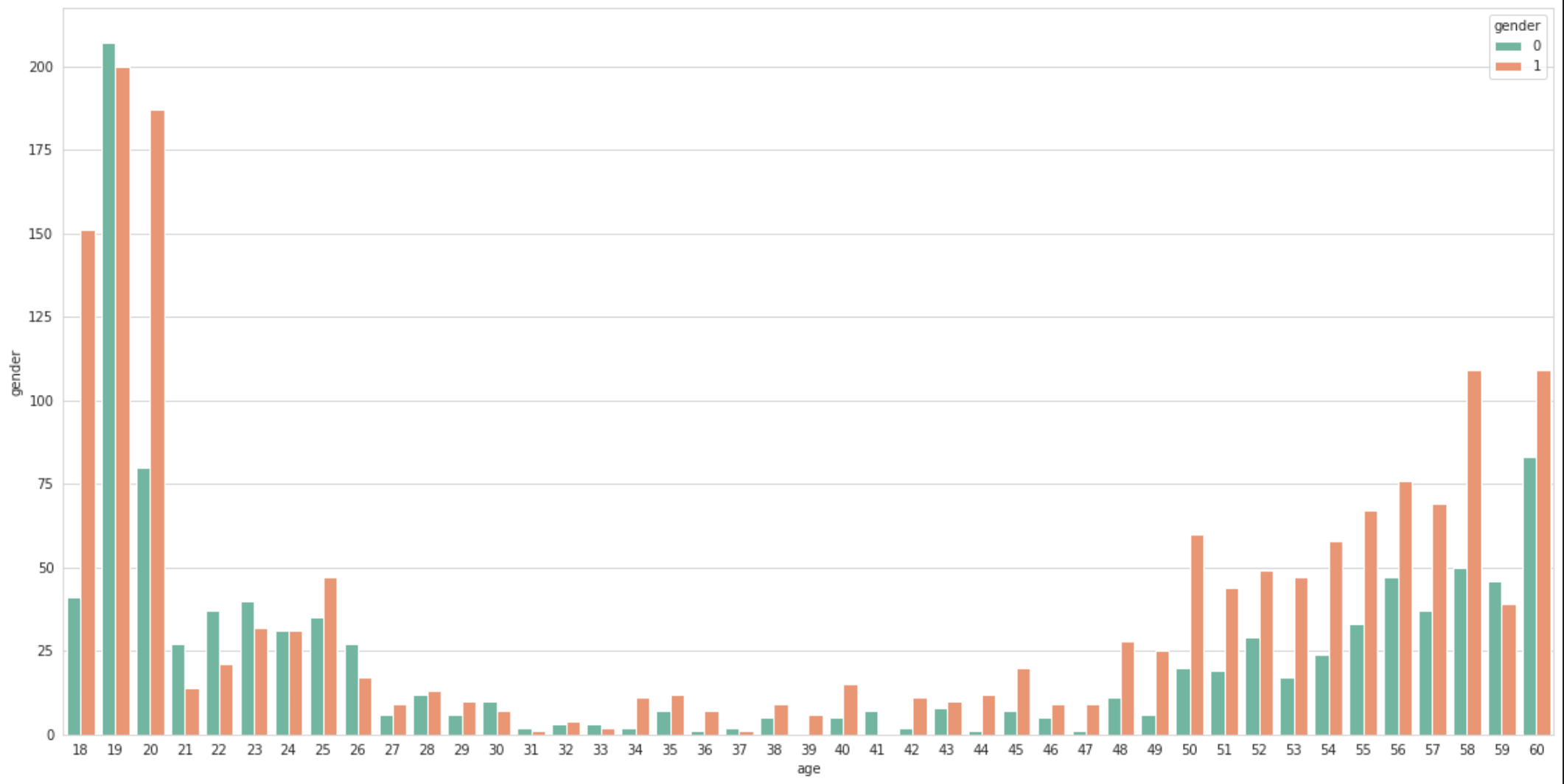
• 데이터가 <=20 과 50 ~ 60 에 밀집되어 있음
• age 라벨 중 60대 이상을 가르키는 라벨의 데이터 수(class 2, 5, 8, 11, 14, 17)가 현저히 적다
• 전체적으로 마스크를 착용하고 60 미만인 class 0, 1, 3, 4 가 많은 imbalanced data 임
Data
• 실제 이미지와 이미지가 가르키는 label 이 잘못된 경우가 다수 존재하여 이를 수정 필요
• 토론게시판 참고
• 일차적으로 전수조사 진행한 캠퍼의 게시글 통해 수정
• 이후 토론 게시판 글을 이용해 수정 및 데이터셋 저장
• 초기 baseline code 이용 이전에는 단순히 모든 사진들을 8:2 로 train/val split하였음
• 하지만 같은 인물의 사진이 train 과 val 에 섞여 들어가며, val acc/f1 test 값이 비정상적으로 높아지는 결과발생
• 따라서 인물별 사진을 저장하는 폴더들을 8:2 split 후 개별 dataset 생성.... 매번 shuffle을 진행하며 8:2 train / val split을 10번 하면 0.8^10=0.1074이므로 90% 이상의 이미지는 최소한 한 번은 val data에 포함될 것이라고 가정했습니다. 이 가정을 이용하여, ResNet-18 베이스라인을 10회 돌려서 2회 이상 틀린 이미지는 라벨에 오류가 있을 가능성이 높을 것이라고 생각하게 되었고, 따라서 train 데이터 라벨 오류 전수 조사를 위해 이 작업을 진행하였습니다....
Model & Train
• 초반에는 Baseline Code에 정의 되어 있던 기본 CNN based model을 정의하고 이를 학습 후 label 예측
• 이후 efficient net 의 b2~b7 까지의 모델을 pretained 가중치와 함께 가져와 마스크 이미지 분류 task에 맞게 학습 진행
• 가벼운 b2 부터 무거운 b7 까지 b7 이 10 epoch 도는 시간 동안의 최대 epoch으로 학습 후 f1/acc 비교 -> 큰 차이는 없다.
• augmentation 진행 (centercrop/colorjitter/RandomRot/RandomHorizFlip/RandomPerspective/Normalize)
• 학습에 얼굴이 가장 중요할것이라 판단하여 centercrop 사용. 크기가 충분히 크지 않으면 얼굴이 잘리는 경우도 발생. 결과가 크게 좋지 않았음. 따라서 얼굴만 crop 한다기보다는 네 모서리들을 약간 잘라낸다는 느낌으로 크기를 늘린 centercrop 진행
• colorjitter 로 이미지의 다양한 변화. Random 시리즈들로 정면외에 기울어진 얼굴들을 학습시키려 노력
• MTCNN으로 얼굴 감지하고 crop 하여 새로운 이미지들을 생성.
opencv 이용 얼굴 추출도 해보자
• 60 대의 이미지 및 그 외 이미지들의 augmentation을 위해 같은 이미지의 사진들을 추가 생성하여 transforms 하였지만 좋은 결과를 얻지 못함.
• 따라서 60대의 사진만 한번 더 resampling 하기로 결정
• focal 이 imbalanced dataset을 학습 시키는데 효율적이라는 말을 듣고 cross-ent -> focal 변경
• eval을 위한 이미지들을 제외한 이미지들을 기존 train/val 8:2 split 에서 자체 f1/acc 테스트를 위하여 train/val/test 6:2:2 split
• scheduler 교체 & lr 변경. cyclelr 사용
• stacking ensembling 으로 상위 결과 도출한 모델 3가지의 예측 csv 를 수정
• age 데이터의 부족으로 gender/mask 는 90이상의 정확도를 갖지만 age는 70 근처의 성능.
• 전체 f1/acc 값은 age 의 값과 거의 동일
• 60대 데이터 부족. 따라서 60대라고 예측한 것은 부족한 데이터에도 60대라고 한 것이기 때문에 다른 것보다 확신이 있다고 생각. 따라서 세 모델 중 하나라도 60대라고 예측하면 60대로 수정. 하지만 gender나 mask 예측값 까지 다르다면 잘못된 예측이라 가정하고 무시
ToDo List
• TestTimeAugment, PseudoLabeling 등을 활용해보려 하였으나 시간 부족으로 인해 완성하지 못했던 것 그리고 opencv 활용 등 아쉬운 것이 많다.
