08.31 옵티마이저
옵티마이저
-
여러개의 실행 계획중 최저비용을 가지고 있는 계획을 선택해서 sql 을 실행한다.
-
옵티마이저가 내가 원하는대로 움직이게 힌트를 사용해서 실행계획을 변경 한다.
-
sql 실행 계획을 plan_table 에 저장한다.
-
파싱 - execution - fetch
-
기본적으로 비용 기반 옵티마이저를 사용한다. (통계정보를 사용)
-
비용기반 옵티마이저 서브 엔진
- Query Transformer
- sql 문을 효율적으로 실행하기 위해 옵티마이저가 변환한다.
- Estimator
- 통계정보를 사용해서 sql 실행비용을 계산
- plan generator
- sql 을 실행할 실행 계획을 수립한다.
- Query Transformer
-
규칙 기반 옵티마이저의 우선순위

- /+ RULE / 규칙기반옵티마이저를 사용해라
-
인덱스
- 인덱스는 인덱스 키(예: EMPNO)로 정렬되어 있기 때문에 원하는 데이터를 빠르게 조회한다.
- 인덱스는 오름/내림차순으로 탐색이 가능하다.
- 하나의 테이블에 여러 개의 인덱스를 생성할 수 있고, 하나의 인덱스는 여러 개의 칼럼으로 구성될 수 있다.
- 테이블을 생성할 때 기본키는 자동으로 인덱스가 만들어지고 이름은 SYSXXXX 이다.
-
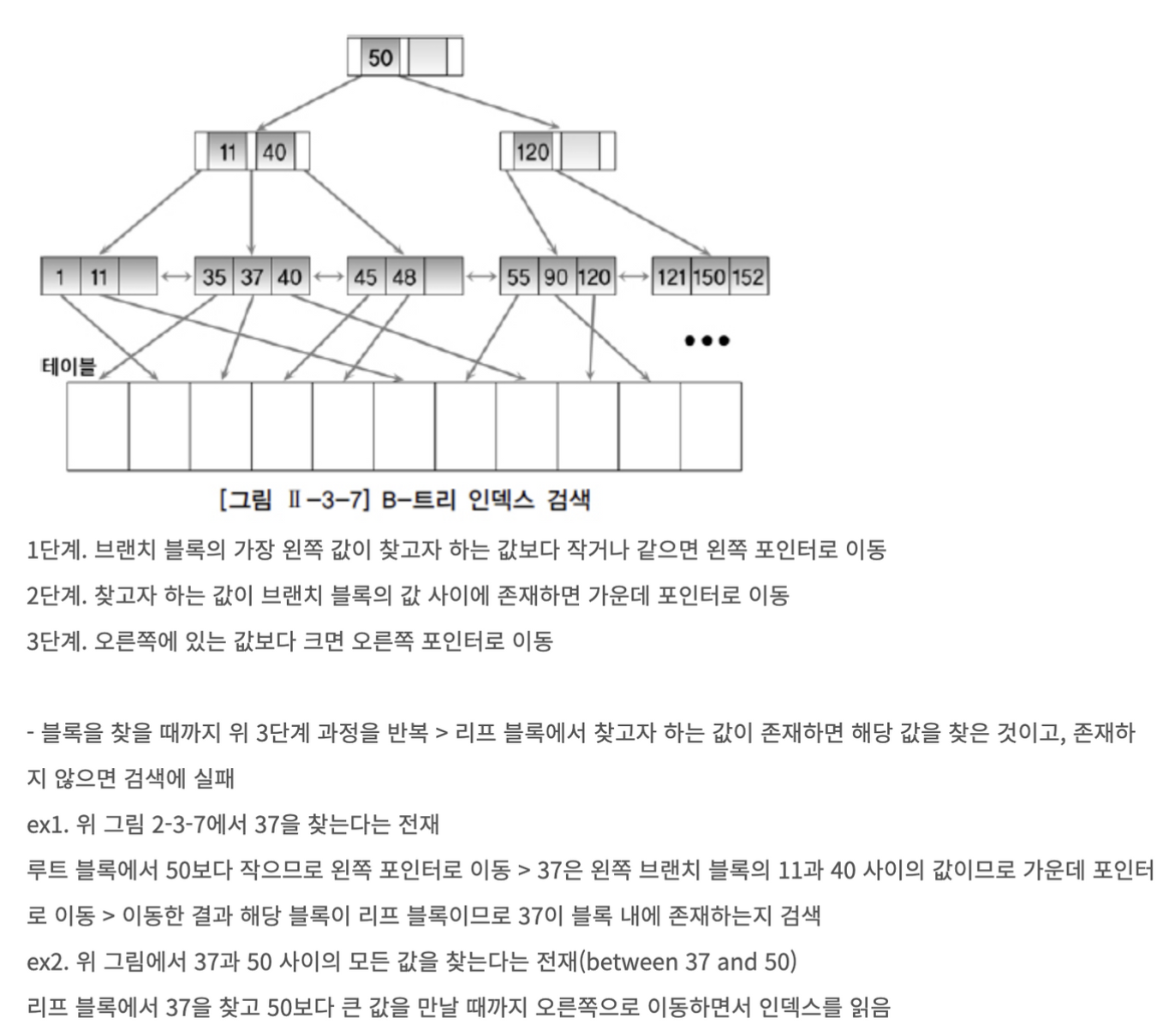
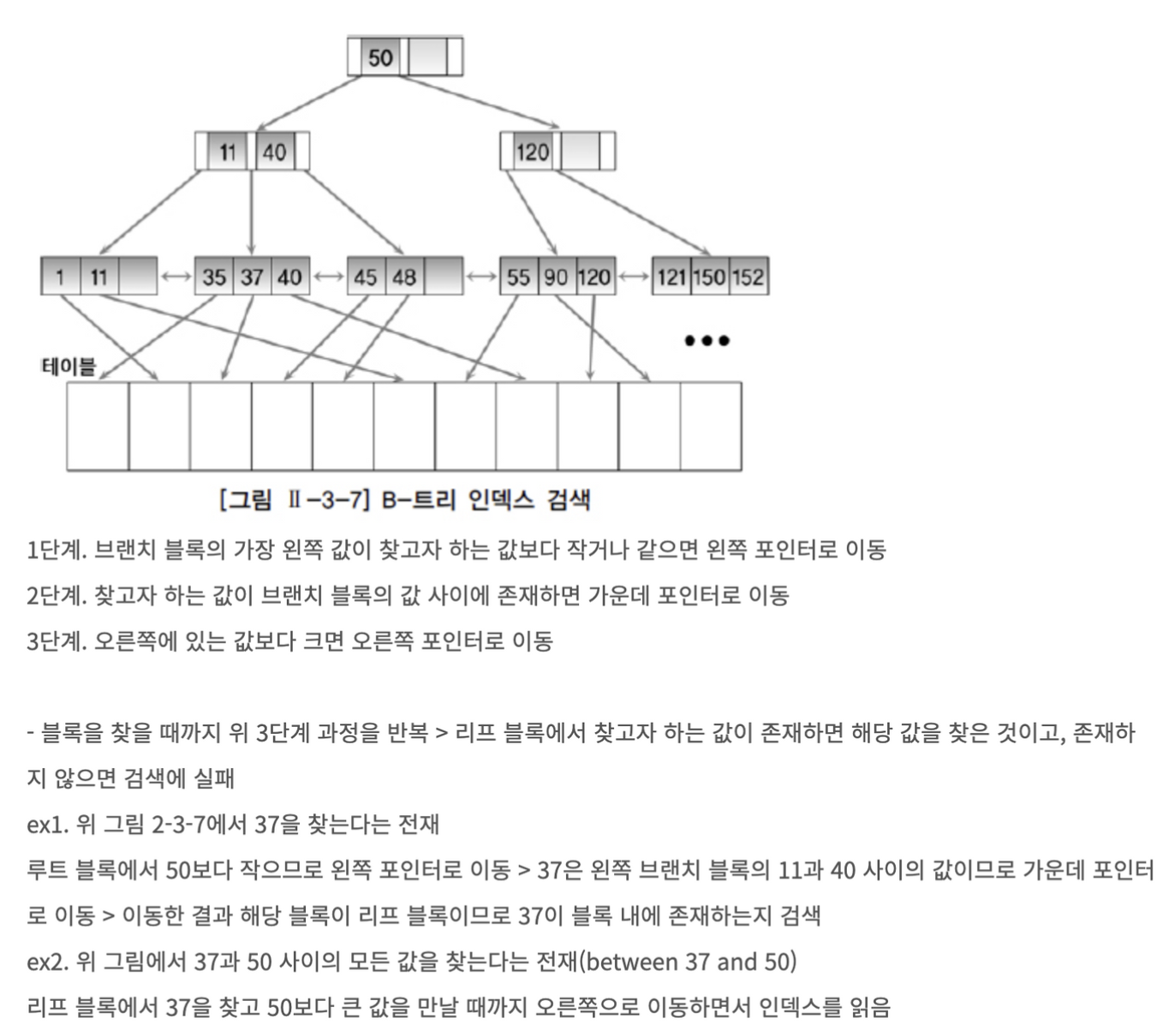
Root Block은 인덱스 트리에서 가장 상위에 있는 노드를 의미
-
Branch Block은 다음 단계의 주소를 가지고 있는 포인터로 되어 있다.
-
leaf block은 인덱스 키와 rowid로 구성되고 인덱스 키는 정렬되어서 저장되어있고, double linked list 구조로 양방향 스캔이 가능하다.
-
- 인덱스 생성
- create index ind1 on emp (ename asc, sal desc);
- 인덱스 유일 스캔
- 인덱스의 키 값이 중복되지 않는 경우, 해당 인덱스를 사용할 때 발생된다.
- 특정 하나의 empno를 조회
- 인덱스 범위 스캔
- 데이터 양이 적은 경우에는 인덱스 자체를 실행하지 않고 table full scan 이 될 수 있다.
- 인덱스의 leaf block의 특정 범위를 스캔한다.
- 인덱스 전체 스캔
- 인덱스에서 검색되는 인덱스 키가 많은 경우에 leaf block의 처음부터 끝까지 전체를 읽어 들인다.
- high water mark
- 테이블에 데이터가 저장된 블록에서 최상의 위치, 데이터가 삭제되면 변경된다.
- Execution Plan
- nested loop 방식의 조인은 dept 테이블에서 먼저 데이터를 찾고 그다음 emp 테이블을 찾는 것을 의미한다. 이런것을 Random Access 라고 한다.
- 먼저 조회되는 테이블을 outer table이라고 하고 그다음에 조회되는 테이블을 inner table 이라 한다.
옵티마이저 조인
- Nested Loop 조인
- 하나의 테이블에서 데이터를 먼저 찾고 그 다음 테이블을 조인하는 방식
- outer table 과 inner table
- 외부 테이블의 크기가 작은 것을 먼저 찾는 것이 중요
- random access가 많이 발생하면 성능 지연이 생긴다.
- 한 테이블의 rowid 로 다른 테이블의 인덱스들을 찾는 과정을 random access 라고 한다.
- sort merge 조인
- 두개의 테이블을 sort_area 라는 메모리 공간에 모두 로딩하고 sort 수행한다.
- 두개의 테이블에 대해서 sort 되면 두 테이블을 병합한다.
- sort 때문에 데이터의 양이 많아지면 성능이 떨어진다.
- hash 조인
- 두 개의 테이블 중에서 작은 테이블을 hash 메모리에 로딩하고 두 개의 테이블의 조인 키를 사용해서 해시 테이블을 생성한다.
- cpu 연산을 많이한다.
- hash 조인시에는 선행 테이블이 메모리에 충분히 로딩되는 크기여야한다.

반 걸음씩 이라도 가보자.