
Transformer
재귀 적인 구조가 없고 attention을 활용
Sequence to sequence model
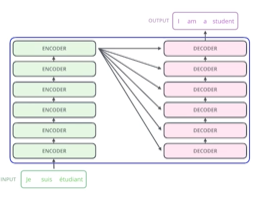
RNN은 입력 시퀀스의 개수 만큼 재귀적으로 돌지만 Transformer는 그렇지 않다.
키포인트
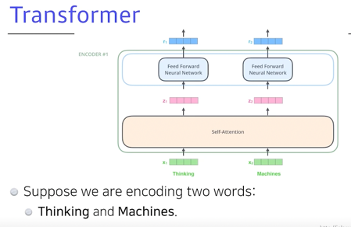
1. N개의 단어가 어떻게 인코더에서 한번에 처리가 되는지
2. 인코더와 디코더 사이에 어떤 정보를 주고 받는지
3. 디코더가 어떻게 시퀀스를 다시 generate 할 수 있는지
벡터가 한번에 들어간다.
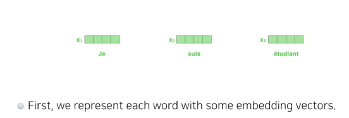
단어마다 워드 임베딩을 통해 벡터화를 시킨다.
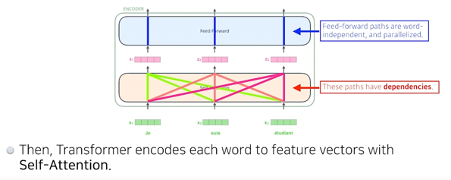
N개의 단어의 임베딩 벡터 x 가 각각의 n개의 z를 만들 때 Z1을 만들기 위해 x1만을 사용하는 것이 아니라 나머지 n-1개의 벡터들도 활용한다.
하나의 문장에서의 한 단어를 설명할 때는 단어 그 자체의 의미 외에도 문장 속에서 다른 단어들과 어떤 interaction이 있는지도 고려해야한다./ animal과 연관이 크게 있다고 학습이 되는 것

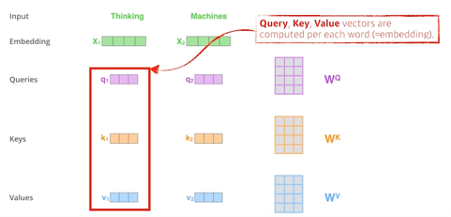
한 단어 마다 차원 축소를 통해 q,k,v 를 생성할 수 있고 q,k,v 를 통해 x1을 새로운 벡터로 만들 수 있다.
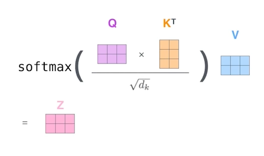
Score벡터
내가 인코딩 하고자 하는 q와 n개의 k를 구하고 q와 모든 k를 각각 내적을 한다.
이를 통해서 그 단어와 자기 자신을 포함한 다른 단어들 과의 관계를 score벡터로 표현한다.
그 후
보통 키 벡터의 차원에 루트를 씌운 값 만큼 나눠준다.
그리고 나서 sum이 1이 될 수 있게 softmax 를 취해준다.

이를 attention weight 라고 한다.(단어와 다른 단어들 사이에서 얼마나 인터렉션을 해야 되는가)
= 스칼라 값
이후 각각의 단어의 value 벡터와 weight를 곱한 값들의 sum이 z 이다.
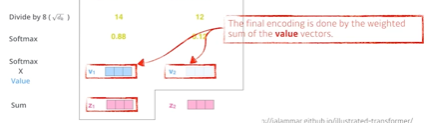
주의할 점: Q와 K의 차원은 동일해야한다.
최종적으로 나오는 z의 벡터의 차원은 value 벡터의 것과 동일해야한다(multihead 에서는 조금 다름)
행렬로의 계산
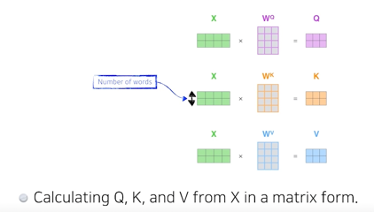
QKV 를 찾아 내는데 사용되는 W(multi-layer perceptron)은 단어들마다 share 된다.
내 입력이 고정되더라도 옆에 존재하는 입력이 달라지면 출력이 달라질 수 있는 여지가 있기 때문에 많은걸 표현할 수 있는 transformer 구조이다. 반대로 많은 것을 표현할 수 있기 때문에 컴퓨테이션도 오래 걸린다. O(n^2)
Multihead Attention
하나의 단어 벡터 x에 대하여 QKV 를 하나만 만드는게 아니라 n개를 만드는 것
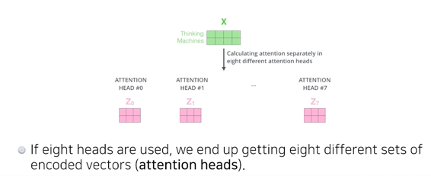
따라서 n개의 인코딩된 결과벡터 z가 나온다.
다만 입력과 출력의 차원을 맞춰주어야 하기 때문에 n개의 z를 입력 차원과 같게 축소해야함

따라서 여기서는 221의 concat한 z를 214의 행렬과 곱해준다(linear layer)
하지만 구현 자체는 이렇게 구현되어 있지 않다.
원래 내게 주어진 임베딩디멘젼이 100이고 헤드를 10개 사용한다 하면 100디멘젼을 10개로 나눠서 실제로 QKV를 만드는것은 10디멘젼짜리들로 만든다. 코드에서 더 설명
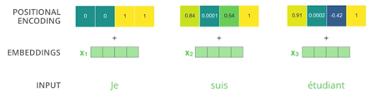
입력값이 ab로 들어온 것과 ba로 들어온 것의 self attention을 살펴보면 AA,AB,BA,BB로 순서와 관계없이 동일하다. 따라서 우리는 순서 정보를 부여하기 위해 positional encoding벡터를 더해준다.


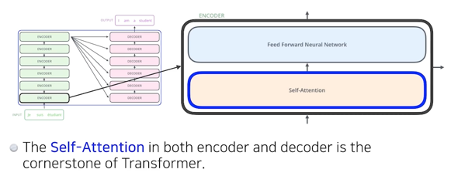
Self attention으로 n개의 단어가 다시 주어지면 layer-norm을 진행하고 FFNN(모든 단어들 다 동일한 layer)을 돌리고 이것저것 반복
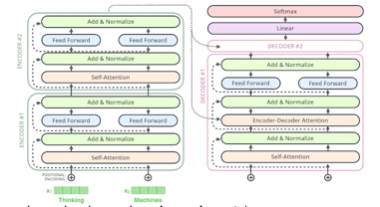
인코더에서 디코더로 어떤 정보가 전해지나?
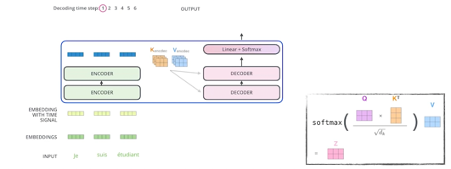
가장 상위 인코더에서 나온 벡터들의 K,V를 decoder에 넘겨준다.
이후 디코더에 들어가게 되는 단어들의 쿼리 벡터와 인코더에서 주어지는 K,V를 가지고 출력을 한 단어씩 autoregressive하게 만든다.

인코더에서와 다르게 디코더에서는 어떤 값이 들어갈지 모르니까 마스킹 처리를 하고 self-att 진행한다. Masked head attention(self-att)
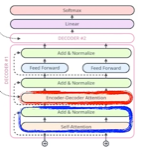

인코더 디코더 어텐션 = 인코더에서 K,V 디코더에서 Q를 받아 진행한다.
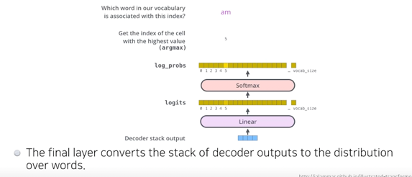
Final layer 에서는 최종디코더 출력값을 linear(fc) -> softmax -> onehot -> one word
Vision Transformer
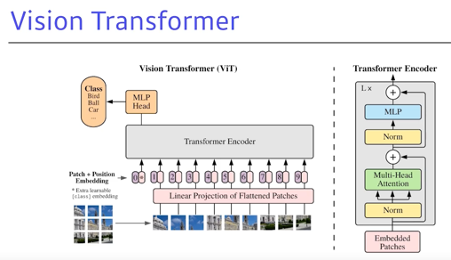
이미지 분류를 할 때 인코더만을 사용하고, 인코더에서 나오는 첫번째 인코디드 벡터를 그냥 classifier에 집어넣는 식으로 진행
Dall-E

문장이 주어지면 그 문장을 나타내는 그림을 생성
