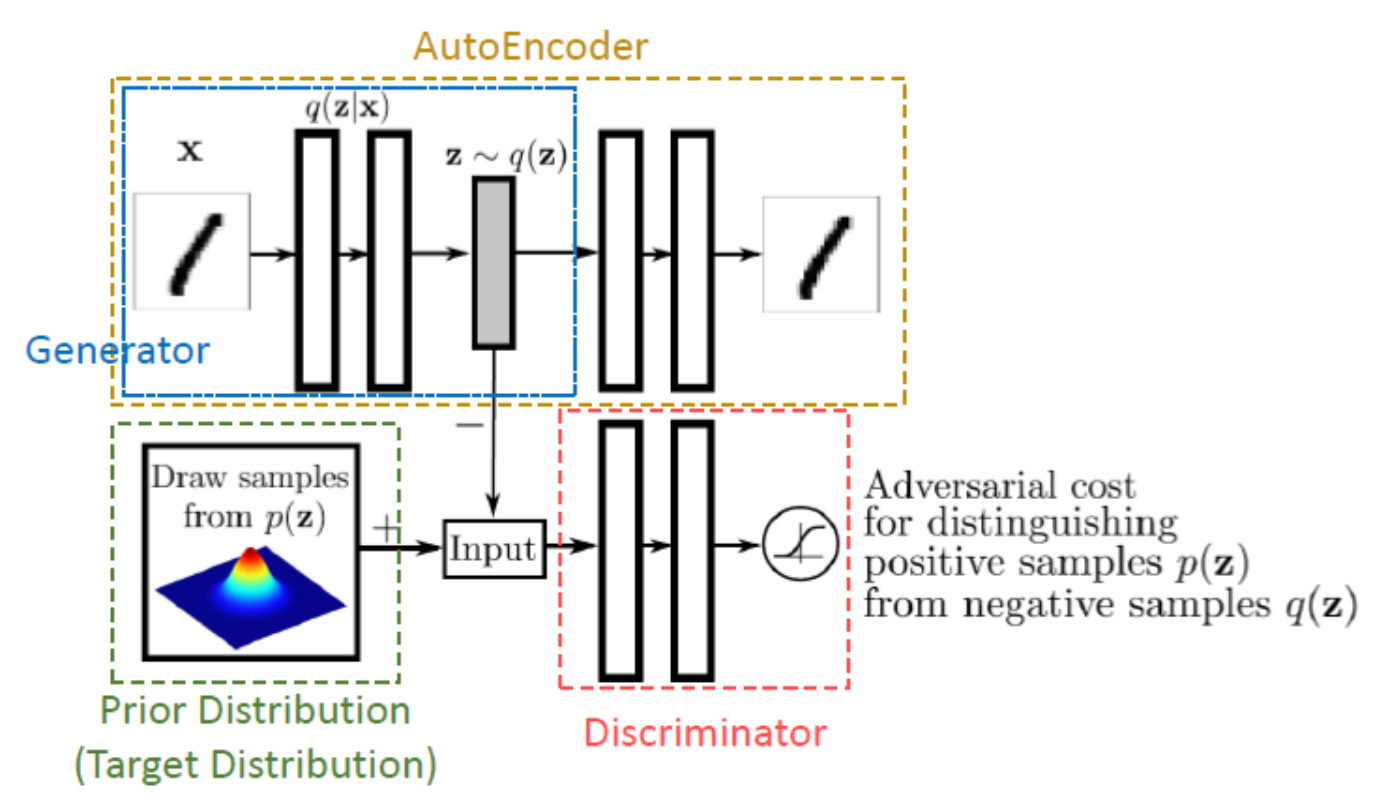
AAE 구조
ToDo list
• 1. Generator(Encoder)
Blue Part
• 2. Decoder in Autoencoder
Yello Part
• 3. Discriminator
Red Part
요약
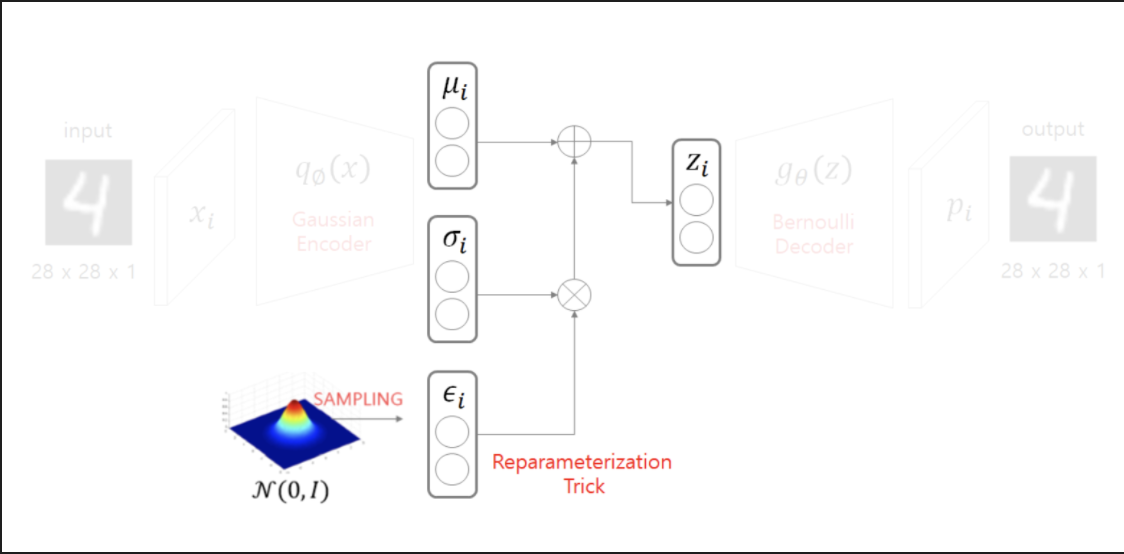
input X를 Gaussian Encoder에 통과시켜 mu와 sigma를 얻는다.
z를 다시 28X28X1 형태의 mnistData로 바꾸는 과정인 p(z) 에서 샘플링을 할때 데이터의 확률 분포와 같은 분포에서 샘플을 뽑아야 하는데, backpropagation을 하기 위해선, reparametrization의 과정을 거친다.
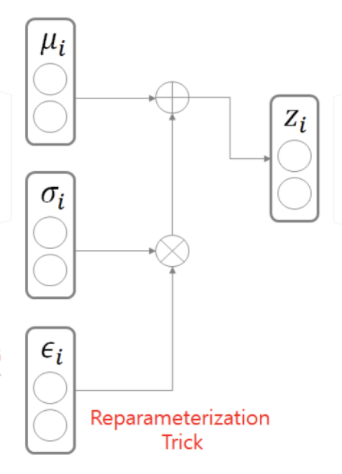
reparameterization
def reparameterization(mu, logvar):
std = torch.exp(logvar / 2)
sampled_z = Variable(Tensor(np.random.normal(0, 1, (mu.size(0), latent_dim))))
z = sampled_z * std + mu
return zEncoder
32X32X1(1024) image X -> 512 -> mu & logvar -> Z
self.model = nn.Sequential(
### TASK 1: BUILD UP ENCODER ###
nn.Linear(1024, 512),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.Linear(512, 512),
nn.Dropout(p=0.2),
nn.ReLU()
)self.mu = nn.Linear(512, latent_dim)
self.logvar = nn.Linear(512, latent_dim)z = reparameterization(mu, logvar)```Decoder
Encoder 의 역순
Z (512) -> X (1024) -> X (32X32X1)
이미지 생성
self.model = nn.Sequential(
nn.Linear(latent_dim, 512),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.Linear(512, 1024),
nn.Tanh(),
)q = q.view(q.shape[0], *img_shape)Discriminator
판별과정
Z(512) -> (256) -> 예측(1)
self.model = nn.Sequential(
### TASK 2: BUILD UP Discriminator ###
nn.Linear(latent_dim, 512),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.Linear(512, 256),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid(),
)Training
for epoch in range(n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
encoded_imgs = encoder(real_imgs)
decoded_imgs = decoder(encoded_imgs)
# Loss measures generator's ability to fool the discriminator
g_loss = 0.001 * adversarial_loss(discriminator(encoded_imgs), valid) + 0.999 * pixelwise_loss(
decoded_imgs, real_imgs
)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as discriminator ground truth
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], latent_dim))))
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(z), valid)
fake_loss = adversarial_loss(discriminator(encoded_imgs.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
d_loss.backward()
optimizer_D.step()

반 걸음씩 이라도 가보자.