
Redis
NOSQL DB로써의 Redis 특징 정리
- key-value store
- 다양한 자료구조 지원
- 원하는 수준의 영속성 구성가능
- In-Memory 솔루션이라는 점에서 오는 특징을 활용할 때 가장 효율적
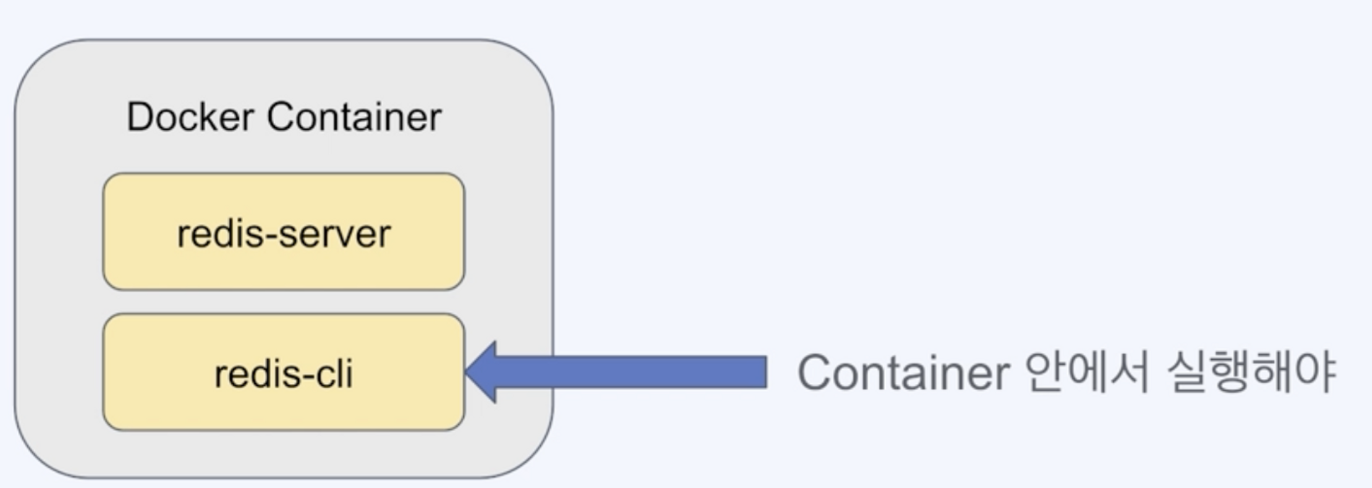
Redis 실행
컨테이너 안에서 redis-server, redis-cli를 관리한다
docker pull redis
docker run --name my-redis -d -p 6379:6379 redis
docker exec -it my-redis /bin/sh
#redis-cli
후 redis 명령어 실행
특정 DB 에 접속하기
redis-cli -n 1
Redis Data type
Strings, Lists, Sets, Hashs, SortedSets, BitMap, HyperLogLog
String
Strings 타입은 Redis의 가장 기본적인 Type 입니다. 일반적으로 우리가 알고 있는 Key-value 형식을 따르고 있습니다. key와 value 모두 binary safe 하기때문에 어떠한 데이터의 종류도 key, value의 값이 될 수 있습니다.
Lists
Lists는 Linked List와 유사한 형태로 데이터가 저장되는 Redis에서 제공하는 자료구조입니다. 따라서 처음과 마지막 부분에 element를 추가 / 삭제 / 조회하는 것은 O(1)의 속도를 가지지만 중간의 특정 index 값을 조회할 때는 O(N)의 속도를 가지는 단점을 동일하게 가지고 있습니다.
중간에 있는 index값을 가져와야할 경우가 많다면 Sorted Set 자료구조를 추천한다
Sets
Redis Sets는 순서가 보장되지않는 Strings의 집합 자료구조입니다. 기본적으로 추가, 삭제, element의 존재 유무확인 등에 대해서 O(1)의 속도를 보장합니다. 또한 Set 이기 때문에 동일한 value는 추가한다고 해서 2개가 공존하지 않습니다.
- 트래킹에 사용될 수 있습니다. 블로그에 접근한 IP 리스트를 관리하고자 할 때 중복을 허용하지 않는 Sets 자료구조를 활용한다면 좋을 결과를 얻을 수 있을 것입니다.
- 모든 태그를 나타내는 리스트에도 사용될 수 있습니다. 각 포스팅마다 태그가 있고 해당 태그의 모든 리스트를 보고 싶을 때 중복이 허용되지 않는 Set은 사용하기 좋은 자료구조 일 수 있습니다.
- Sets는 Sets간의 합집합, 차집합 등을 지원해주기 때문에 문제해결에 도움이 될 수 있습니다. ex)
SINTER - Sets의 요소를 랜덤으로 뽑는
SPOP,SRANDMEMBER등의 명령어가 있습니다.
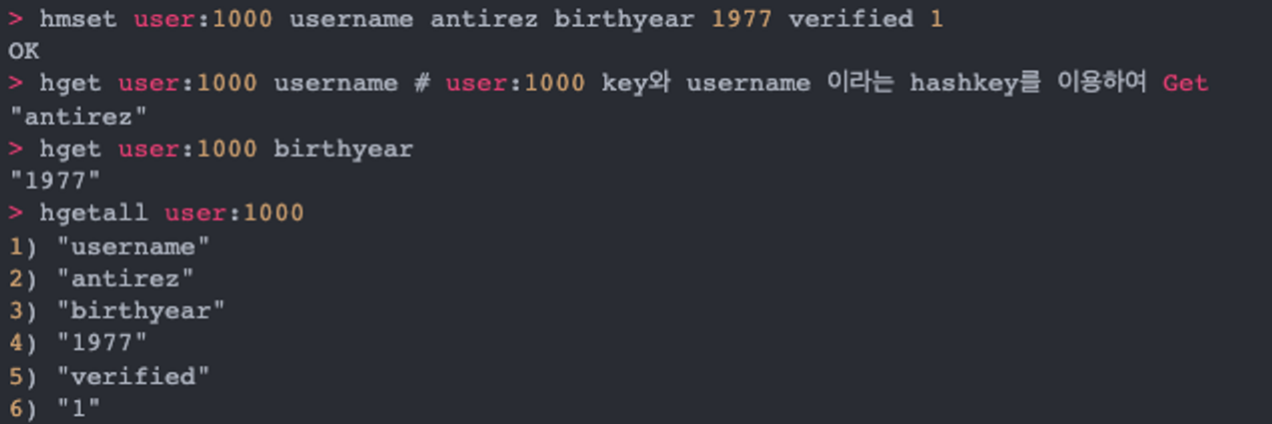
Hashes
Redis의 Hashes는 value로 또 다른 key-value Map을 가지는 자료구조입니다. 쉽게 이해하기 위해서 아래의 바로 예제를 보자
Sorted sets
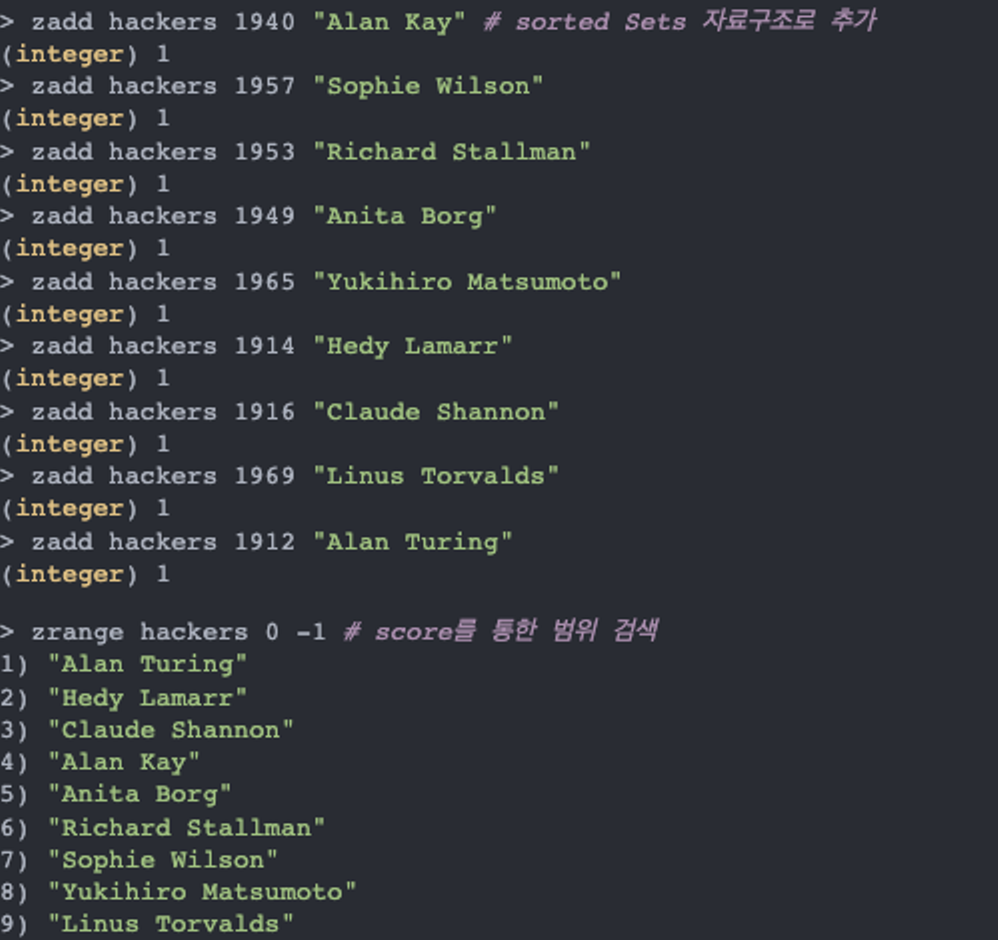
Redis의 Sorted sets 자료구조는 Sets 자료구조에 Score를 추가로 기록하여 score가 낮은순서부터 높은순서대로 정렬되는 자료구조입니다. 동일한 값은 오지 못하며 Score는 동일할 수 있다는 사실을 명심하셔야합니다.
아래는 Sorted Sets 명령어의 특이사항 및 활용방법입니다.
- 온라인 게임의 랭킹에 사용될 수 있습니다.
ZADD명령어를 통해 score와 이름을 함께 보내면 쉽고 빠르게 정렬되고 유일값을 가지는 자료구조를 만들 수 있습니다. 또한 찾을때는ZRANK,ZRANGE명령어를 이용할 수 있습니다. - Sorted Sets는 자주 Redis에 저장된 데이터의 index를 저장하기 위해서 사용되기도 합니다. hashes에 user를 담아둔다고 한다면 이 값을 나이순으로 정렬하던지 할 수 있는 것입니다.
Redis를 실무에서 활용하는 법
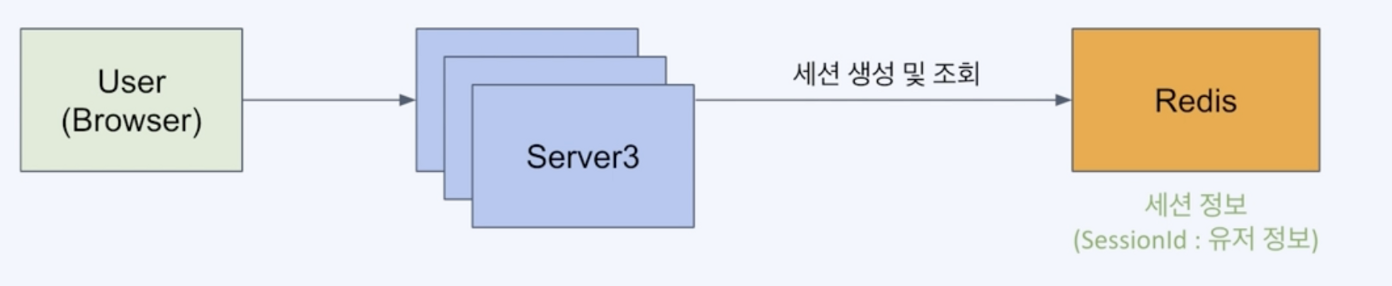
분산환경에서의 세션 처리
: 서버들이 외부의 저장소를 두고 세션 정보를 공유할 방법이 필요 → Session clustering
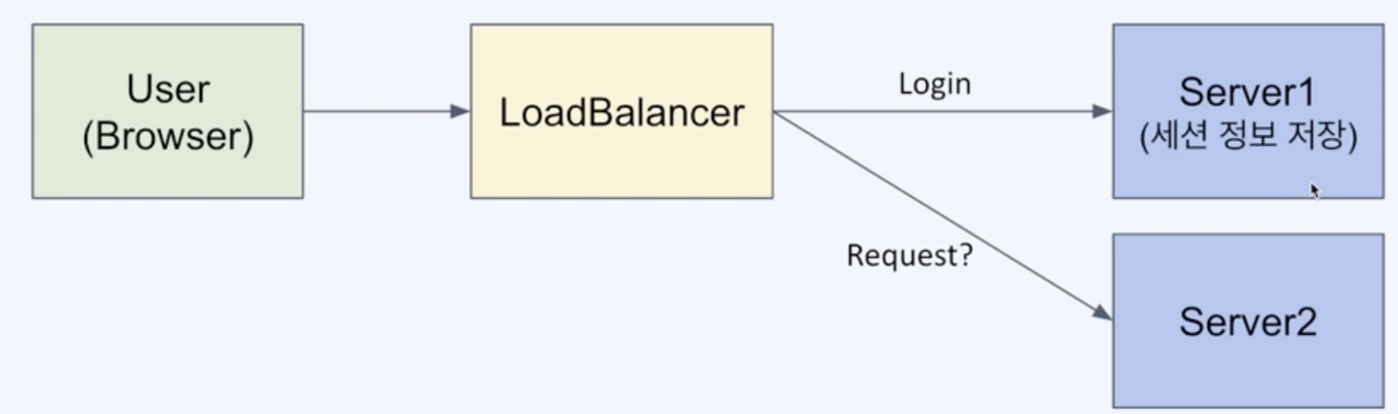
case1. RDB 사용
관계형 데이터베이스 모델이 필요한가
영속성이 필요한 데이터인가
성능요구사항을 충족하는가(세션은 모든 요청에 대해서 접근이 이루어짐 → RDB의 부하)
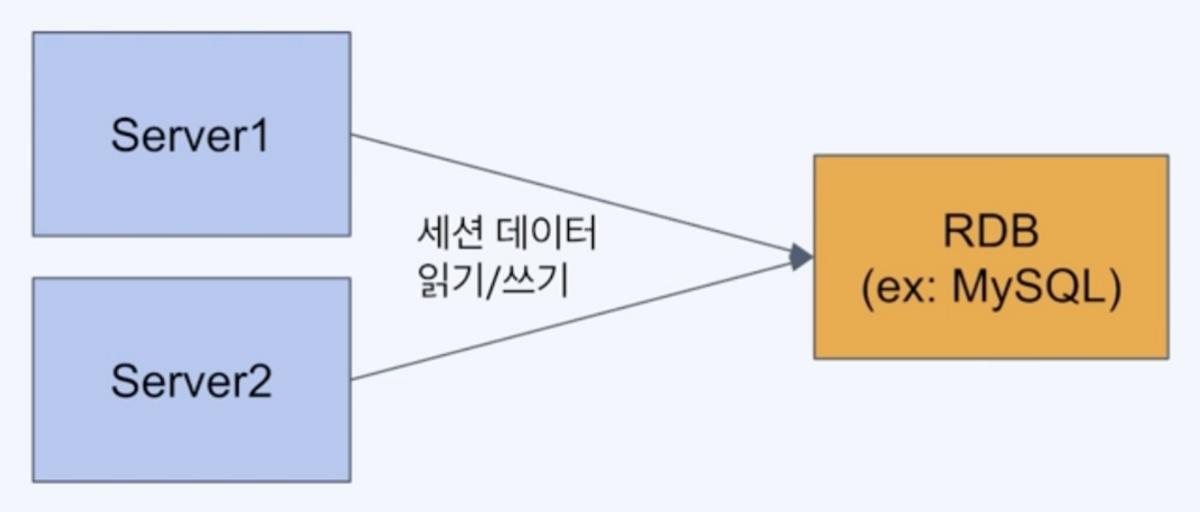
Case2. Redis 사용(*권장)
세션 데이터는 단순한 key-value 구조
세션 데이터는 영속성이 필요없음
세션 데이터는 변경이 빈번하고 빠른 엑세스 구조
Redis로 캐시레이어 만들기
먼저 캐싱에 대해 알아보자
캐싱의 원리와 장점
- 네트워크 지연 감소
- 서버 리소스 사용감소
- 병목현상 감소
캐싱의 종류
- Cache-Aside( Lazy Loading) 캐시분리
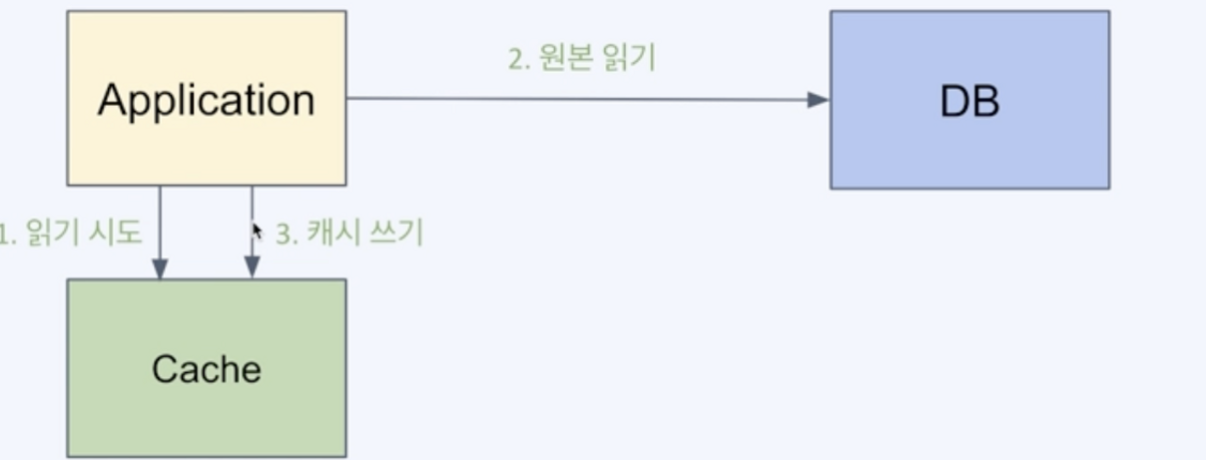
캐시를 옆에 두고 필요할 때만 데이터를 캐시에 로드하는 전략이다.
캐시는 데이터베이스와 직접 연결되지 않고, 애플리케이션이 주체가 된다. 애플리케이션이 요청을 받으면 데이터가 캐시에 있는지 먼저 검사하며, 그 결과에 따라(캐시에 데이터가 로딩되어있는지의 여부) 다음 액션이 아래와 같이 결정된다
-
처음 사용자가 요청했을 때, 캐시 스토리지에는 아무 데이터도 없는 상황
애플리케이션은 먼저 캐시 저장소에 데이터가 있는지 조회한다. 하지만 데이터가 없다.애플리케이션은 Contents DB 에서 데이터를 조회하고 사용자에게 제공한다.애플리케이션은 Contents DB 에서 가져왔던 데이터를 캐시 저장소에 저장한다.
-
다음 사용자가 요청했을 때는 이미 캐시 저장소에 데이터가 있는 상황
애플리케이션은 먼저 캐시 저장소에 데이터가 있는지 조회한다. 캐시 저장소에 저장되어있는 데이터를 제공한다.
이 방법은 캐시에 대한 의존성이 낮으므로 캐시가 다운되더라도 원천 데이터베이스로 서비스를 계속할 수 있다. 따라서 읽기 요청이 많은 경우 적합하다
이렇게 Cache Aside Pattern 으로 구현하는 경우에도 애플리케이션이 처음 실행될때 초기 데이터를캐시 저장소에 미리 넣어두는 것도 좋은 방법이라고 한다 🙂
이 분의 블로그글을 참고하면 Cache Aside Pattern을 구현시 아래와 같은 것들을 고려하면 좋을 것 같다고 한다

- Write through
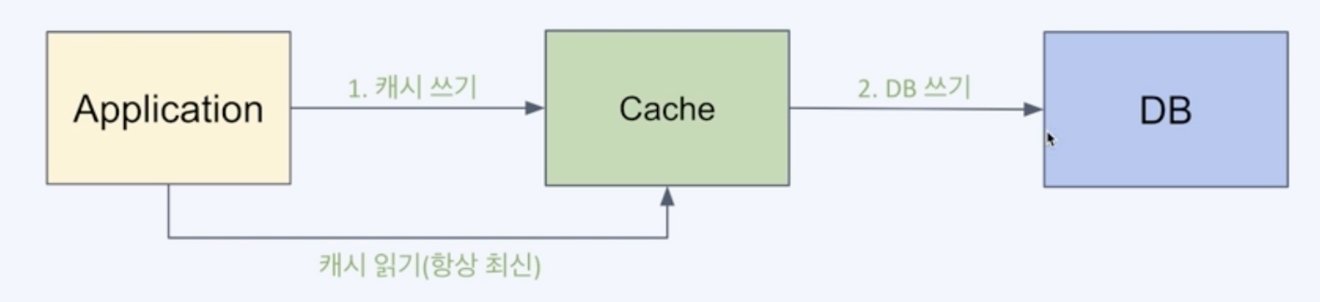
애플리케이션이 직접 바라보는 것은 데이터베이스가 아니라 캐시이다.
캐시가 주 데이터 스토어의 역할을 한다
데이터가 캐시와 DB에 모두 반영이 되었을때를 정상적인 쓰기 오퍼레이션이 성공한 것으로 간주된다. 이러한 면에서 신뢰성이 높다. 즉 장애발생시 데이터를 유실할 가능성을 낮춰준다
그러나, 캐시와 데이터베이스 모두에 기록해야되므로 쓰기 레이턴시가 증가한다.
기록한 데이터를 다시 자주 읽는 경우에 좋다
-
Write back
쓰기 요청은 캐시까지만이다. 케시에 데이터가 갱신되면 쓰기요청은 완료된다.
그리고 별도의 서비스등을 통해 캐시의 내용이 나중에 데이터베이스로 동기화된다.캐시의 flush 정책(LRU, FIFO, LIFO 등)에 따라 데이터가 데이터베이스로 저장된다.
쓰기 요청이 많은 경우 적합하다.
캐시의 내용을 데이터베이스에 몰아서 수행하므로 쓰기 비용을 절약할 수 있다
바꿔말하면, 데이터를 모아뒀다가 한번에 기록하므로 그 사이에 장애가 발생하면 데이터의 유실이 발생할 수 있다
Spring의 캐시 추상화
@Cacheable매소드에 캐시를 적용한다(Cache-Aside 방법)
레디스 주의점
레디스를 사용하지 않더라도 운영체제에서는 스왑 인/아웃을 수행할 수 있습니다. 스왑 인/아웃은 운영체제의 메모리 관리 기능 중 하나로, 메모리 부족 상황에서 사용됩니다. 이는 운영체제가 물리적 메모리(RAM)에 적재된 프로세스나 데이터를 디스크의 스왑 공간으로 이동시키는 것을 의미합니다.
스왑 인/아웃은 운영체제의 자체 기능이기 때문에, 어떤 애플리케이션을 사용하느냐에 상관없이 발생할 수 있습니다. 따라서 레디스를 사용하지 않더라도 운영체제가 메모리 부족 상황에 직면하면 스왑 인/아웃을 수행할 수 있습니다.
다만, 레디스는 메모리 기반의 데이터베이스로 알려져 있으며, 레디스 서버는 자체적으로 메모리를 관리합니다. 따라서 레디스를 사용할 때는 메모리 사용량에 주의해야 합니다. 메모리 사용량이 높아질 경우에는 스왑 인/아웃이 발생할 가능성이 높아지며, 이는 성능 저하로 이어질 수 있습니다.
따라서 레디스를 사용할 때는 충분한 메모리 용량을 할당하고, 메모리 사용량을 모니터링하여 스왑 인/아웃이 발생하지 않도록 관리하는 것이 중요합니다. 메모리 용량이 부족한 경우에는 메모리를 추가하거나, 데이터를 더 효율적으로 관리하는 방법을 고려할 수 있습니다.
Redis의 백업과 장애복구
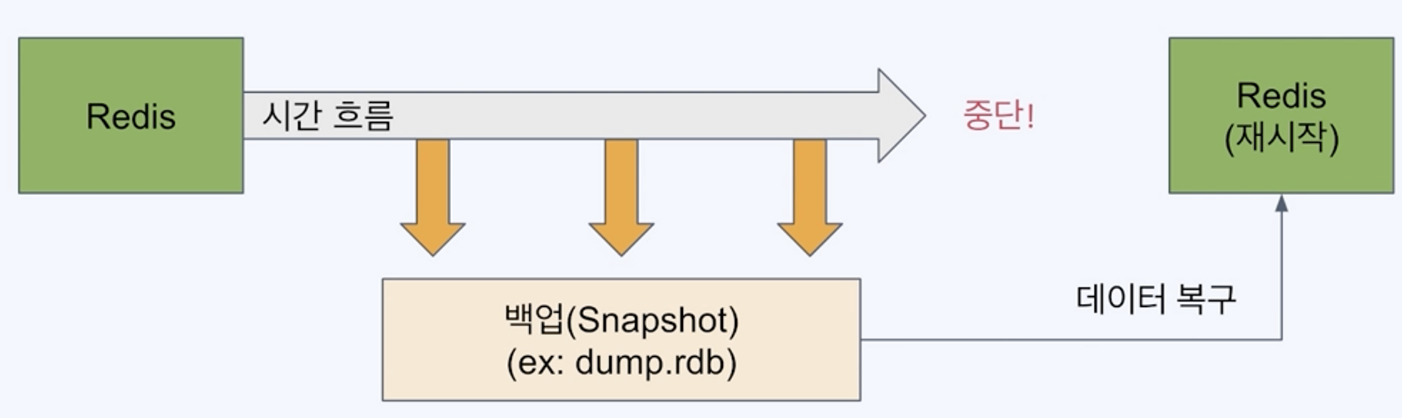
RDB(Redis database)를 사용한 백업
- 특정 시점의 스냅샷으로 데이터 저장
- 재시작시 RDB 파일이 있으면 읽어서 복구
- fork를 사용해 백업하므로 서비스 중인 프로세스는 성능에 영향없음, fork를 이용하기에 cpu와 메모리 자원을 많이 소모
- 데이터 무결성이나 정합성에 대한 요구가 크지 않은 경우 사용 가능
Redis 는 빠른 성능을 중요하게 여기기 때문에 위와 같은 trade-off 가 존재한다
자세한 스냅샷 저장법은 이 링크를 참고하자
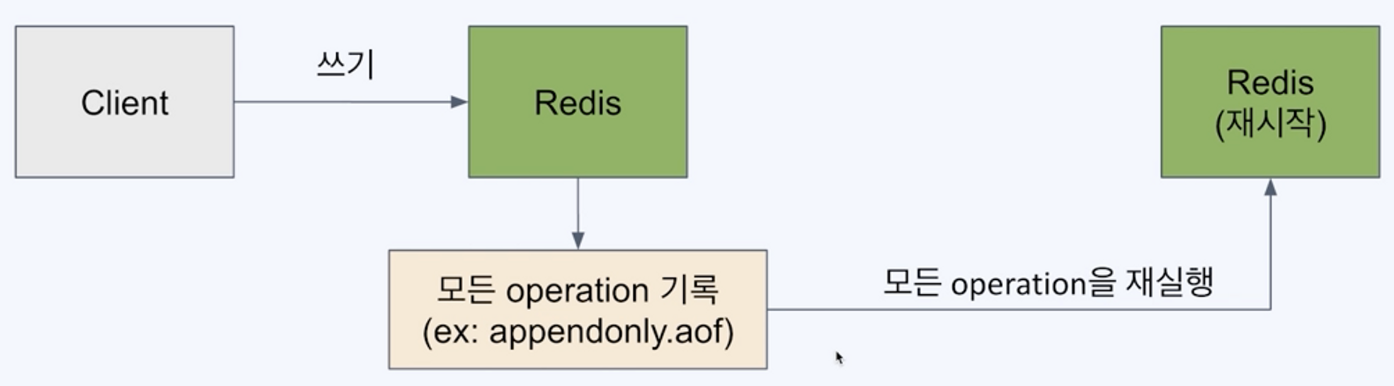
AOF(Append Only File)를 사용한 백업
모든 쓰기 요청에 대한 로그를 저장
static.com/9270226c-34c8-49f3-9bc4-4170f2515748/Untitled.png)
- 모든 변경 사항이 기록되기에 RDB 방식 대비 안정적 백업 가능
- 백업파일 손상 위험 적음
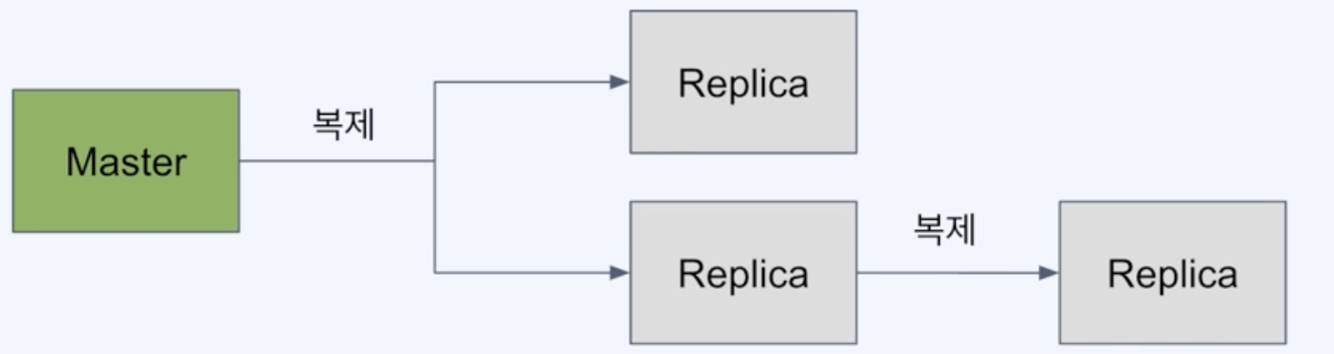
Redis 의 복제
백업만으로는 장애 대비에 미흡함
- master가 죽었을 경우 replica(slave or secondary) 중 하나를 master로 전환해 즉시 서비스 정상화 가능
- 복제본(replica)는 read-only 노드로 사용가능하므로 traffic 분산도 가능
마스터의 백업노드들을 여러개 유지하는 것
RDB나 AOP보다 훨씬 빠르게 장애 복구 가능
하지만 이 방법 역시 마스터를 수동으로 바꿔줘야한다는 단점이 있다
이에 redis sentinel 이라는 기술이 있다
Redis Sentinel 를 이용한 자동 장애 조치
- Redis 에서 HA(high availability)를 제공하기 위한 장치
- 모니터링 기능, 환경설정 제공자
- master-replica 구조에서 master가 다운시 replica를 master로 승격시키는 auto-failover를 수행
master-replica에 대해 자세히 알아보고 싶으면 이 링크를 참고하자
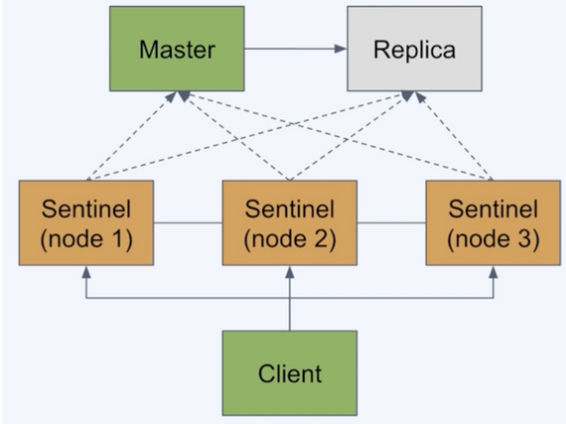
Redis Sentinel 의 실제 구상도
- Sentinel 노드는 3개 이상으로 구성(Quorum 때문에)
Quorum을 활용해 master의 down 판단(함부로 auto-failover를 하면안됨)
- Sentinel 은 서로 연결되어 있음
- Sentinel 들은 redis master와 replica를 모니터링
- client는 sentinel 을 통해 redis 에 접근
redis-cli -p 26379
Redis Cluster
레디스 클러스터는 sentinel과 비슷하게 분산환경에서 자동 장애 조치를 가능하게 해주고, sentinel 보다 조금 더 발전된 형태
여러 노드에 데이터 자동으로 분산
일부 노드의 실패나 통신단절에도 계속 동작하는 가용성
고성능을 보장하면서도 선형확장성 제공
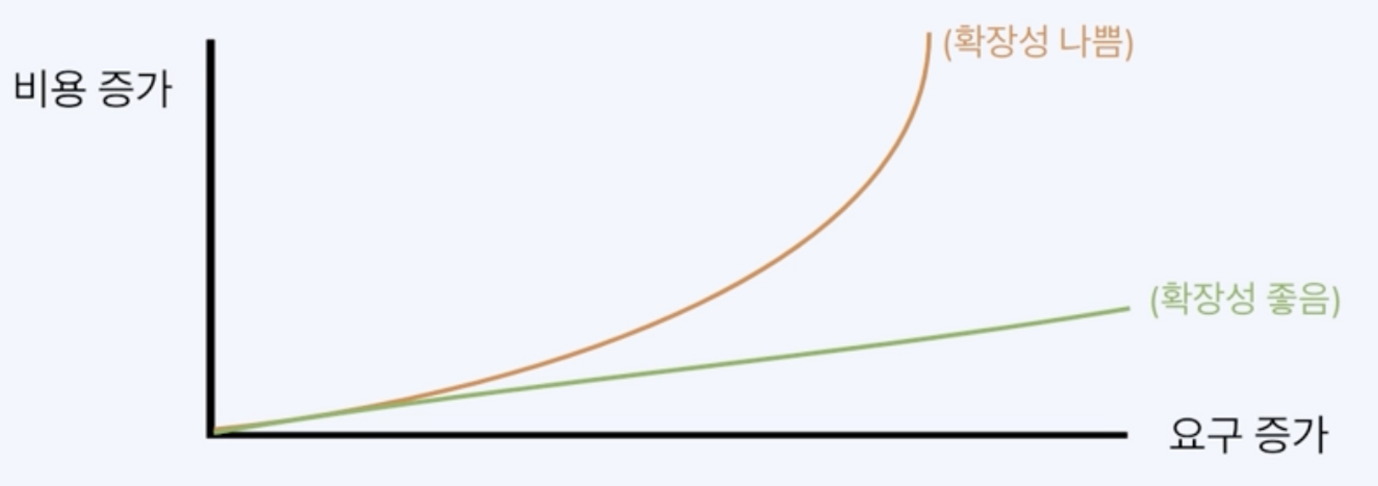
확장성과 분산을 위한 클러스터
- 확장성
- 소프트웨어나 서비스 요구 사항 수준이 증가할때 대응할 수 있는 능력
- 주로 규모에 대한 확장성(수평확장성 → 새로운 노드를 추가해나가는 것)
- scale up/ scale out
- scale out 의 문제점: 부분장애, 네트워크 실패, 데이터 동기화, 로드 밸런싱(여러개의 작업중 처리해야할 노드 선택하는 것), 개발 및 관리의 독립성
- 서비스 복잡도가 커져감에 따라 scale out 은 필요함
Redis Cluster 구조
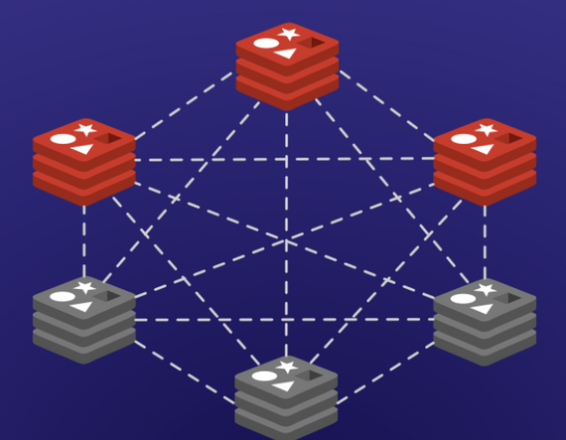
- full-mesh 구조로 통신
- cluster bus라는 추가 채널(port) 를 사용(16379 포트)
- gossip protocol 사용(중복된 정보를 수신할 때 과부하 방지)
- hash slot을 사용한 키 관리
hash slot은 Master Node에서 다른 Master Node로 이동시키기만 하여 쉬운 확장이 가능하며, 순단이 발생않고도 가능합니다
- DB0 만 사용가능
레디스는 인스턴스안에서 데이터베이스를 여러개 쓸 수 있지만 클러스터 모드에서는 디비 1개
- multi key 명령어가 제한됨
- 클라이언트는 모든 노드에 접속
sentinel 과의 차이점
- 클러스터는 데이터 분산(샤딩)을 제공함
- 클러스터는 자동 장애조치를 위한 모니터링 노드를 추가 배치할 필요가 없음(Redis sentinel 처럼 최소 3개이상의 sentinel node 가 필요없다)
- 클러스터에서는 multi key 오퍼레이션이 제한됨
sentinel 은 싱글마스터로 동작 → multi key 오퍼레이션 제한 없음
- sentinel 은 비교적 단순하고 소규모의 시스템에서 HA(고가용성) 가 필요할 때 채택
멀티 키 연산이 필요한 경우가 아닌 이상 cluster 를 사용한다고 한다
데이터분산과 키 관리
-
데이터 저장방식 - hashing

- Redis 는 16384개의 hash slot 으로 key 공간을 나누어 관리한다
- 각 키는 CRC16 해싱 후 16384 로 Modulo 연산을 해 각 hash slot 에 매핑한다
- hash slot 은 각 노드들에게 나누어 분배된다
-
클라이언트의 데이터 접근방식
클라이언트 노드는 요청이 온 key 에 해당하는 노드로 자동으로 redirect해주는 것이 아닌,
클라이언트는 Moved 에러를 받으면 해당 노드로 다시 요청해야한다
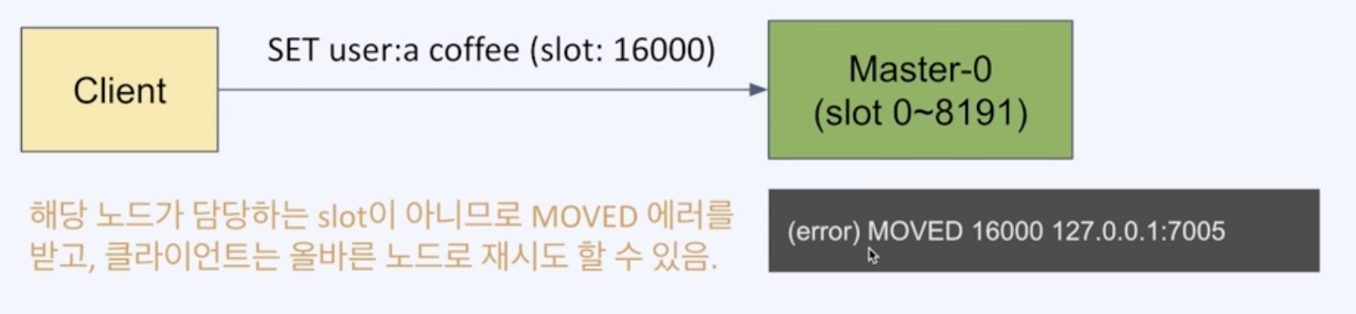
대부분의 클라이언트는 키와노드의 맵을 캐싱하고 있기 때문에 이러한 재시도는 잘 일어나지 않는다
성능과 가용성
분산시스템에서 성능은 데이터 일관성과 trade-off가 있음
Redis Cluster는 고성능의 확장성을 제공하면서 적절한 수준의 데이터 안전성과 가용성을 유지하는 것을 목표로 설계되었다
성능(데이터의 일관성 포기) - Strong consistency 보장 안함
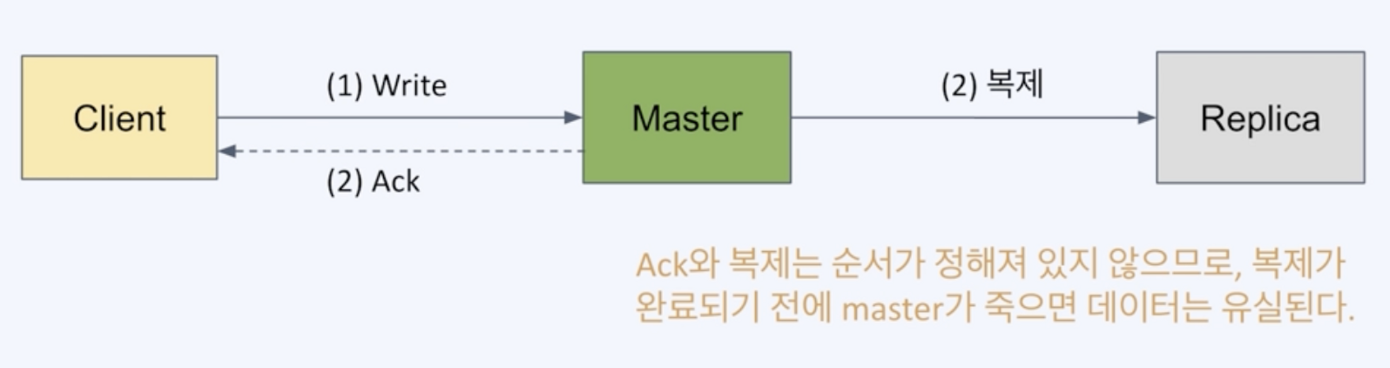
복제가 끝난 후 Ack 을 보내지 않고 비동기 복제를 수행
복제가 완료되기전에 Master 가 죽으면 데이터 일관성이 깨질 수 있다
클러스터의 가용성
- auto failover- 죽어버린 master를 replica 가 대신한다
일부 마스터 노드가 실패하더라도 과반수 이상의 master가 남아있고, 사라진 master들의 replica 가 있다면 클러스터는 failover되어 가용한 상태가 된다
node timeout 동안 과반수의 master 와 통신하지 못한 master는 스스로 error state 에 빠지고 write 요청을 받지 않는다
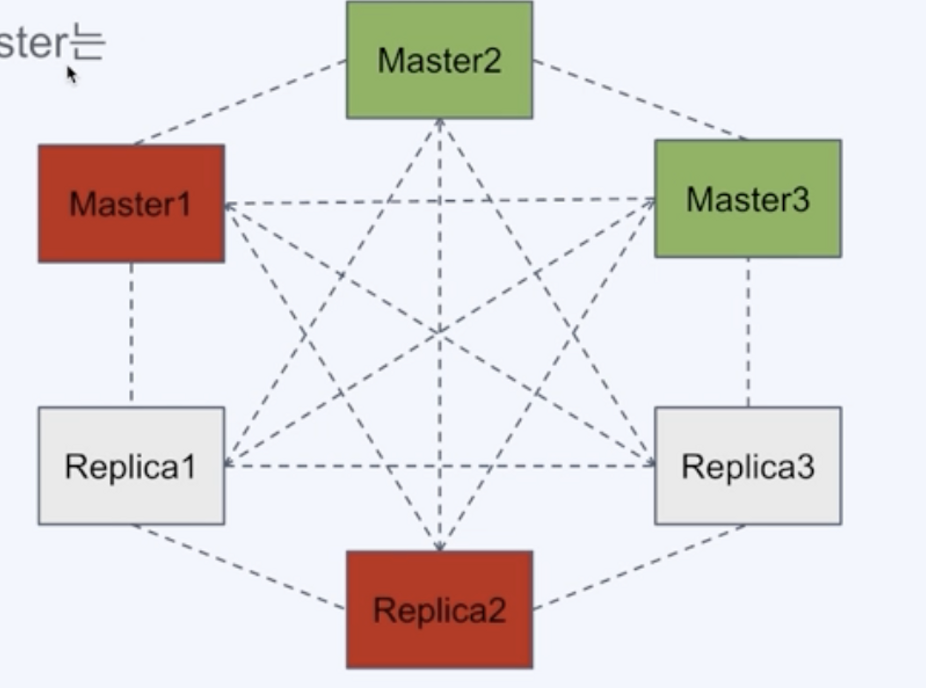
- replica migration
replica 가 다른 master로 migrate 해서 가용성을 높인다
참고
[PYTHON] Python에서 Redis를 사용 + 인메모리 캐시(Ubuntu 18.04)
