
📌 Java의 Collection
자바 컬렉션 프레임워크로 인해 자료의 삽입, 삭제, 검색 등등이 용이해지고 어떠한 자료형이라도 담을 수 있으며 크기가 자유롭게 늘어난다는 강점을 가져 많은 사람들에게 사용되고 있다
📌 Java Collection FrameWork
frame이라는 단어를 보면 틀, 뼈대가 떠오른다
기본 구조라한다면 인터페이스가 떠오른다. 인터페이스 자체가 기본뼈대(추상구조) 이기 때문이다
자바에서 제공하는 컬렉션은 크게 세가지 인터페이스로 나뉘어있다
List, Queue, Set으로 나뉜다 그리고 각 분야별로 구현된 것들이 있다
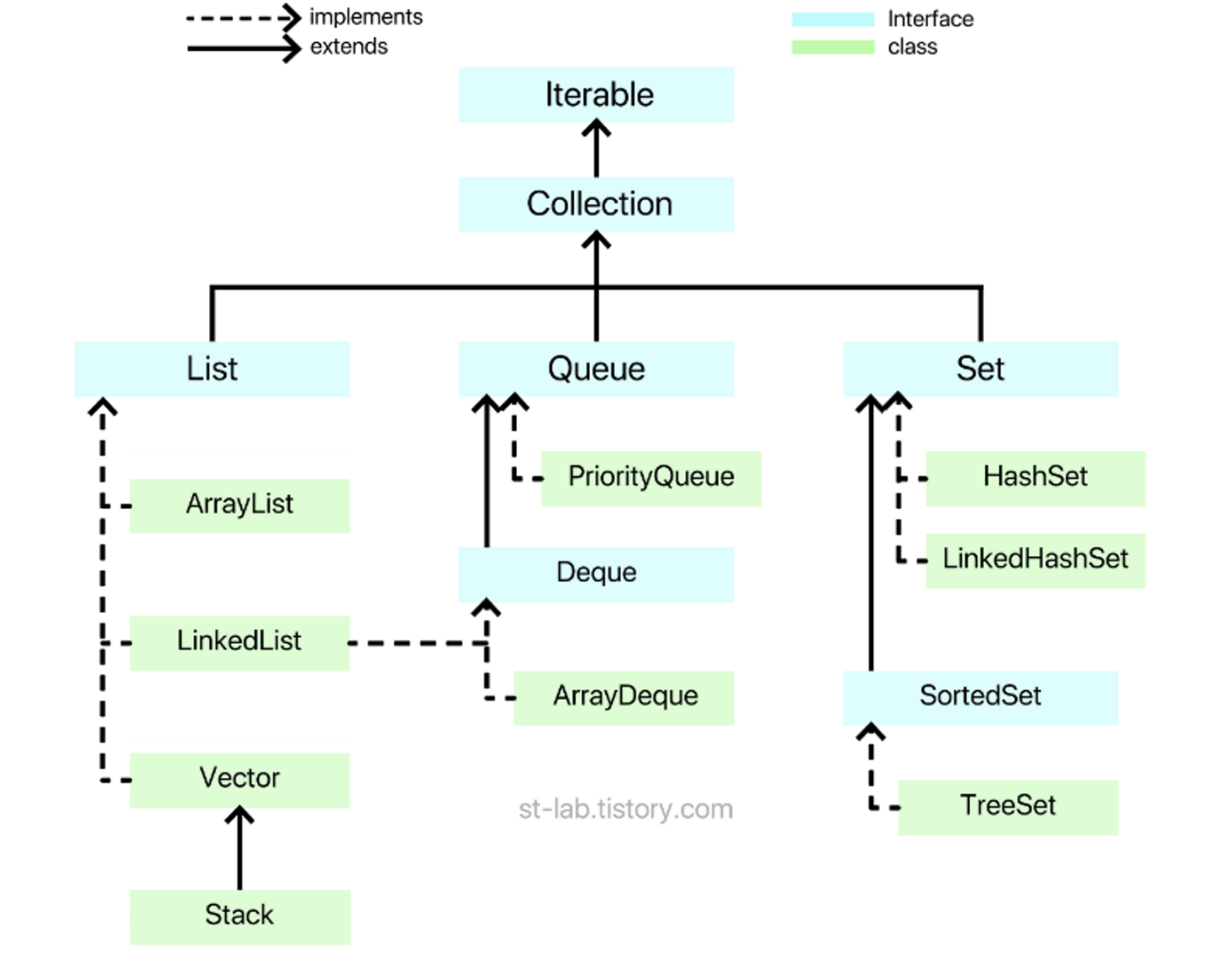
녹색🟢 부분이 구현된 자료구조이다
📌 List Interface를 구현하는 클래스
1. ArrayList
2. LinkedList
3. Vector (+ Vector를 상속받은 Stack)
📌 Queue/Deque Interface를 구현하는 클래스
1. LinkedList : 자바에서 일반적인 큐를 사용하고자 한다면 LinkedList로 선언하면 된다
Queue<T> queue = new LinkedList<>();
Deque<T> queue = new LinkedList<>();
2. ArrayDeque
3. PriorityQueue
큐의 원리는 선입선출이라는 전제 아래에 짜여있다
우선순위 큐의 경우 데이터 우선순위에 기반하여 우선순위가 높은 데이터가 먼저 나오는 원리이다
따로 정렬방식을 지정하지 않는다면 낮은 숫자가 높은 우선순위를 갖는다
pq.poll()을 수행시 가장 낮은 숫자가 큐에서 나오며, pq.offer() 을 수행시 끝에 삽입해 우선순위를 순위에 맞게 지정한다
📌 Set/SortedSet Interface를 구현하는 클래스
Set(세트)는 말그대로 집합이다. Set의 가장 큰 특징은
데이터를 중복해서 저장할 수 없는 것과입력 순서대로의 저장 순서를 보장하지 않는다는 것이다
1. HashSet
-
입력순서 보장 x, 순서도 보장 x
-
중복확인에 이용됨
-
hash에 의해 데이터의 위치를 특정시켜 해당 데이터를 빠르게 색인(search)할 수 있게 만든 것
-
hash기능과 Set 컬렉션이 합쳐진 것이 HashSet
-
그렇기에 삽입, 삭제, 색인이 매우 빠른 컬렉션이다
2. LinkedHashSet
-
중복은 허용하지 않으면서, 입력된 순서를 보장받고 싶은 경우
-
Link + Hash + Set
-
LinkedHashSet은 해시 테이블과 연결 리스트를 모두 사용하여 요소를 저장하고 이는
요소의 순서가 유지되는 것을 보장한다 -
LinkedHashSet의 탐색과 삽입 시간 복잡도는 O(1)
-
페이지를 열때, 해당 페이지가 중복될 경우 캐시는 다시 적재할 필요가 없지만, 새로운 페이지를 할당해야하는 경우 최근에 사용되지 않은 캐시를 비우고자 할 때, 가장 오래된 캐시를 비우는 현명할 것이다. 이를 LRU 알고리즘이라고 하는데, 이럴때 입력된 순서를 알아야 오래된 캐시를 비울 수 있다.
3. TreeSet
-
Set interface를 상속받은 SortedSet interface를 구현하고 있어서, 데이터의 가중치에 따른 순서대로 정렬되어 보장한다
-
TreeSet은 이진 검색 트리를 사용하여 요소를 저장하며, 요소는 자동으로 정렬된다
-
중복되지 않으면서 특정 규칙에 의해 정렬된 데이터를 유지하고 검색하는 경우에 더 빠르게 동작
-
TreeSet의 탐색 및 삽입 복잡도는 O(log n)
-
HashSet과 마찬가지로 입력 순서를 보장 x, 중복데이터도 넣지 못함
🏷️ 사용법
/*
T는 객체 타입을 의미하며 기본적으로
Integer, String, Double, Long 같은 Wrapper Class부터
사용자 정의 객체까지 가능하다.
단, primitive type은 불가능하다.
*/
HashSet<T> hashset = new HashSet<>();
LinkedHashSet<T> linkedhashset = new LinkedHashSet<>();
TreeSet<T> treeset = new TreeSet<>();
SortedSet<T> treeset = new TreeSet<>();
Set<T> hashset = new HashSet<>();
Set<T> linkedhashset = new LinkedHashSet<>();
Set<T> treeset = new TreeSet<>();📌 정리
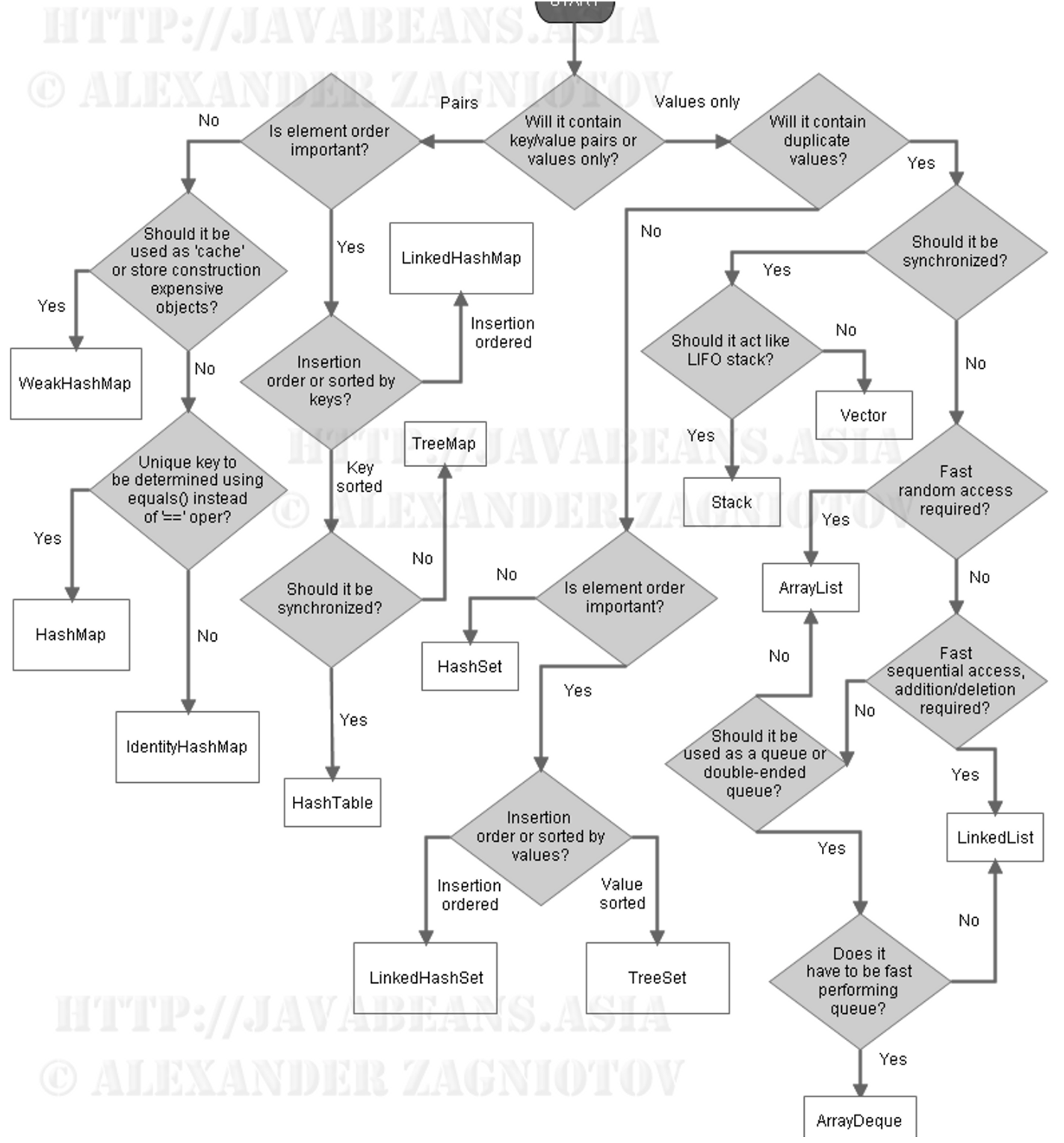
참고
