데이터베이스에서는 B-Tree 계열 자료구조를 사용한다.
특히나 MySQL의 DB engine인 InnoDB는 B+tree로 이뤄져있는데, B-tree의 확장된 개념이다.
이에 대해 자세히 알아보기 위해 먼저 각 자료구조부터 살펴보자
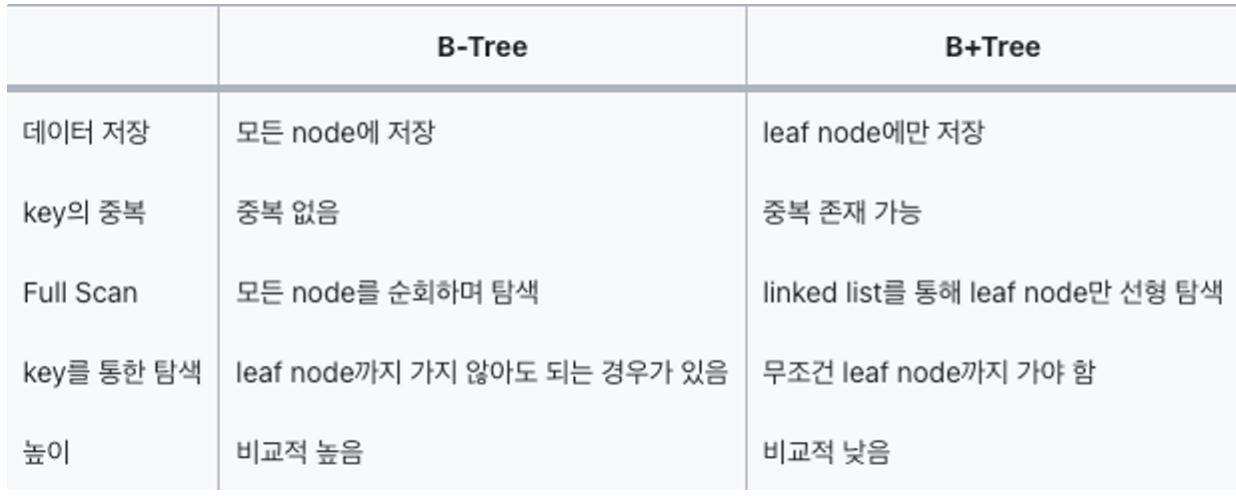
B-Tree
B-Tree는 B트리라고 부르고, 이진 트리와는 다르게 하나의 노드에 많은 정보를 가지거나, 두 개 이상의 자식을 가질 수도 있다.
이렇게 하나의 노드에 여러 정보를 담게 되고, 여러 자식을 가질 수 있게 되면서 차수라는 개념이 등장했다
하드디스크나 SSD 와 같은 외부기억장치는 블럭단위로 파일을 입출력하는데, 이때 발생하는 입출력의 비용은 파일의 크기와 상관없이 블럭과 동일하다.
따라서 이 경우 하나의 블럭에 여러 데이터들을 동시에 저장할 수 있으면 블럭을 효율적으로 사용할 수 있다. 이러한 이유로 많은 데이터베이스가 B-Tree를 사용한다
이 자료구조의 핵심은 데이터가 정렬된 상태로 유지되어있다는 것이다
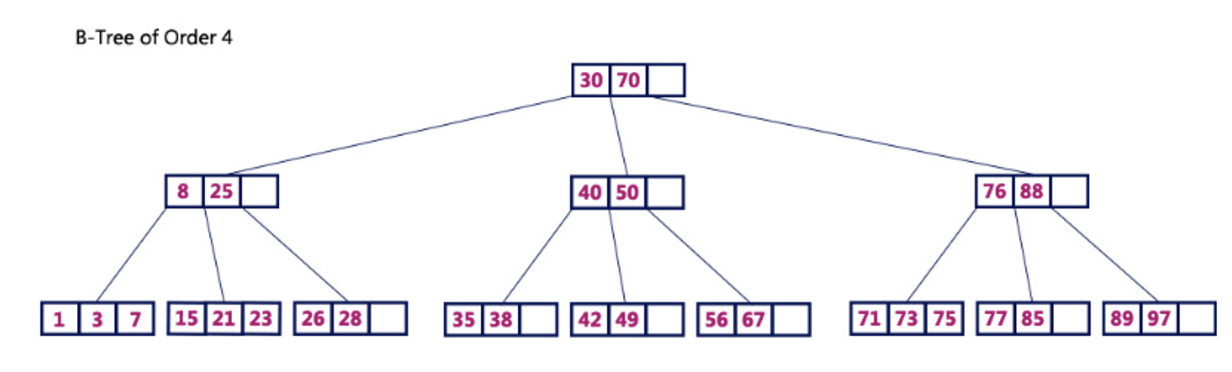
B-Tree의 장점으로 어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다는 균일성을 뽑을 수 있다.
위의 예시에서 리프노드의 15,26을 찾는 시간은 동일하다(O(logN)이라는 시간복잡도를 구할 수 있다)
만약 선형탐색인 경우에는 배열을 하나씩 체크해야되고 시간은 더욱 많이 소요된다(O(N))
B-Tree의 삽입과 삭제과정을 알고싶으면 이 블로그글을 참고하자
시간날때 정리해야겠다 😅
B+Tree
B-Tree는 탐색을 위해서 노드를 찾아서 이동해야한다는 단점이 있다.
이를 해결하기 위해 B+Tree는 같은 레벨의 모든 키 값들이 정렬되어 있고, 같은 레벨의 형제 노드를 연결리스트의 형태로 이어져있다
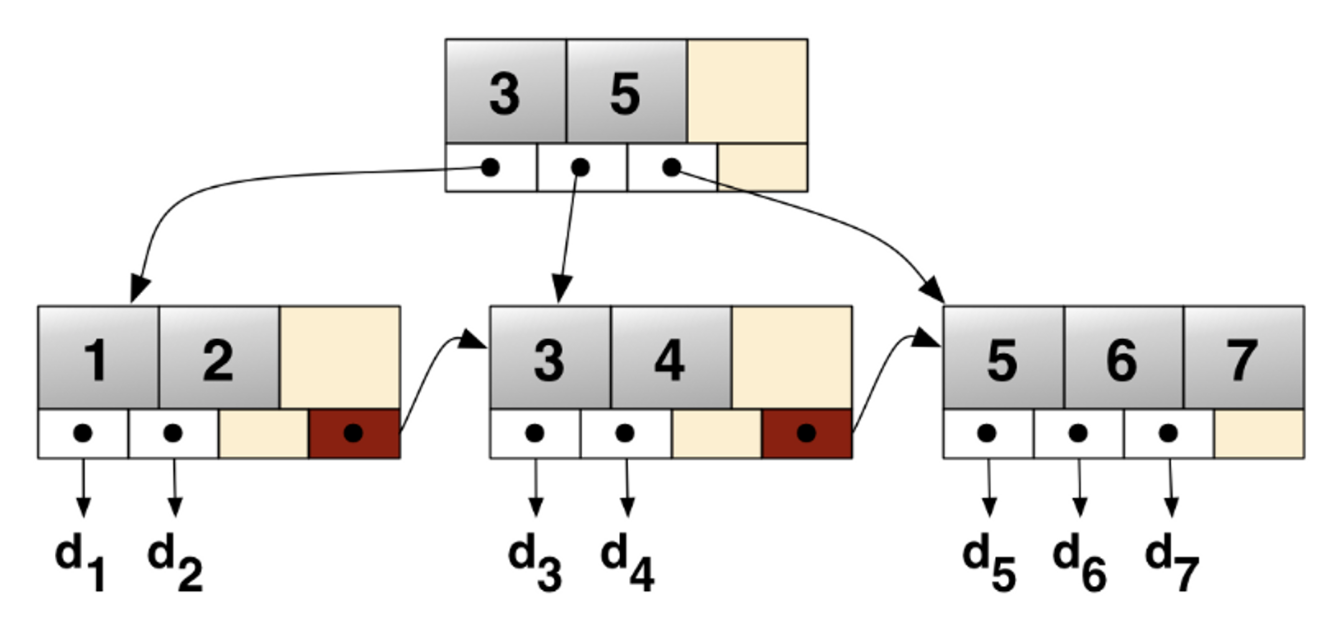
위의 그림처럼 B+Tree는 오직 leaf node에만 데이터 저장. 나머지 노드에는 자식 포인터만 저장.
leaf node끼리는 Linked list로 연결되어 있다.
장점
-
leaf node에만 데이터 저장하므로 메모리 확보. -> 하나의 node에 더 많은 포인터를 가질 수 있기 때 문에 트리의 높이가 더 낮아지므로 검색속도 높일 수 있음.
-
Full scan시, linked list로 연결된 leaf node들에 대해서만 읽기를 진행하면 되므로 시간이 단축된다.
MySQL InnoDB의 B+Tree Index 구조
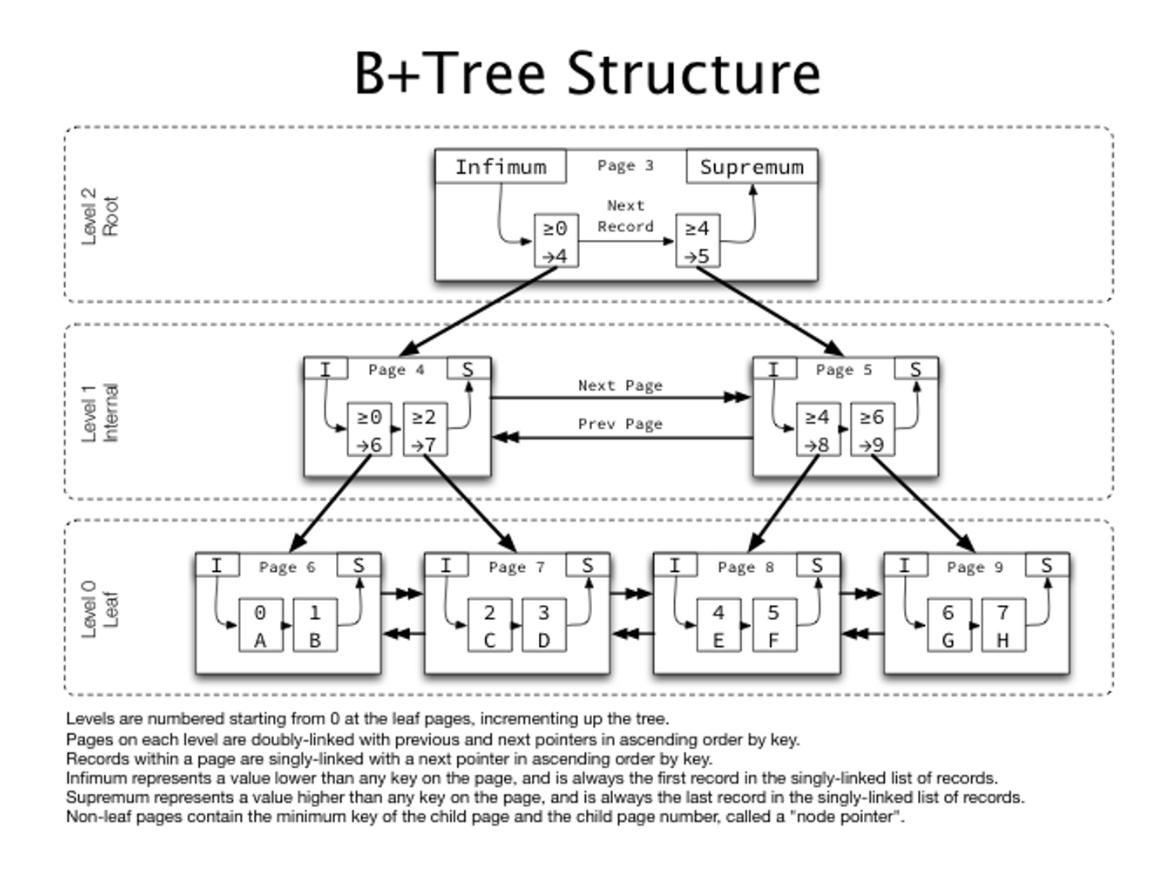
B-Tree 와 B+Tree 비교