
HTTP
인프런
모든 개발자를 위한 HTTP 웹 기본 지식
강의를 수강하며 정리하는 노트
하루에 두강씩은 듣자
IP ( Internet Protocol )
- 클라이언트의 IP 주소와 서버의 IP 주소가 필요
- 지정한 IP 주소로 데이터를 전송
- 패킷 단위로 데이터 전달
- 패킷의 구성
- 출발 IP
- 도착 IP
- 내용
- 패킷의 구성
노드들간 도착 IP으로 계속해 던지면서 도착한다.
도착IP에서 받았으면 다시 패킷을 생성해 응답한다.
IP 프로토콜만의 한계
-
비 연결성 : 패킷을 받을 대상이 없거나 서비스 불능이여도 패킷 전송
-
비 신뢰성 : 중간에 패킷이 사라지거나 순서대로 도착하지 않는 경우
-
프로그램의 구분 : 같은 IP내에서 여러 통신이 수행 중이면?
-
내용이 큰 경우 여러 패킷이 나눠지는데 1 ⇒2⇒3순으로 받는게 아닌 3⇒1⇒2 순으로 받을 수도 있다.
TCP / UDP
TCP
- 인터넷 프로토콜 스택의 4계층
| 어플리케이션 계층 | HTTP , FTP |
|---|---|
| 전송 계층 | TCP , UDP |
| 인터넷 계층 | IP |
| 네트워크 인터페이스 계층 | 하드웨어 영역 |
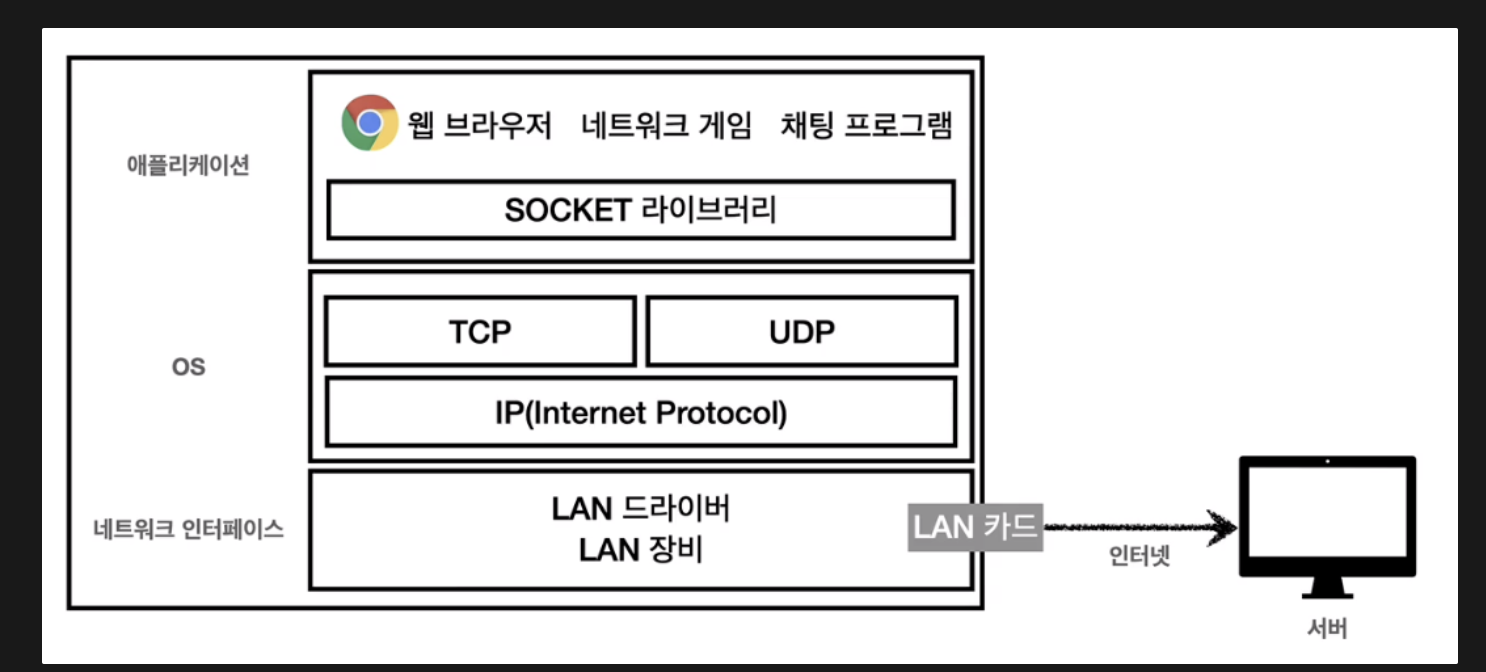
- 프로그램이 콘텐츠 생성
- 소켓 전송
- TCP 정보 생성
- IP 패킷 생성
IP 패킷 정보
- 출발지 IP
- 목적지 IP
- 기타
- TCP 세크먼트
- 출발지 PORT
- 목적지 PORT
- 전송 제어
- 순서
- 검증 정보
TCP의 특징
-
전송 제어 프로토콜
-
연결 지향 TCP 3 way handshack ( 가상 연결 )
-
데이터 전달 보증
-
순서를 보장한다.
-
신뢰할 수 있는 프로토콜
-
거의 대부분 TCP 사용
TCP 3 Way HandShake
- SYN ( 연결 과정 ) ( 클라이언트에서 전송 )
- SYN + ACK ( 접속 요청 , 요청 수락 ) ( 서버에서 전송 )
- ACK ( 요청 수락) ( 클라이언트에서 전송 )
둘 간의 검증을 하고 데이터를 전송
논리적으로만 연결된 상태
데이터 전달 보증
- 데이터 전송 후 정상 응답이 와야지만 제대로 전달된 것
- 응답 요청을 확인
순서를 보증한다
- 123순일때 132으로 오게 되면 2번 패킷부터 다시 보내길 요청한다.
- 순서를 보증한다.
전송 제어 정보와 순서 정보 전달 정보를 가지고 해결한다.
UDP
- 무기능
- 사용자 데이터그램 프로토콜
- 포트만 추가된다
- 단순하고 빠르다
- TCP에 비해 정밀도가 필요없는 경우 사용한다. == 전송 속도를 빠르게 하기 위해.
- 최근에 각광받고 있다고 한다(?)
PORT
- 클라이언트 내부의 여러 프로세스중 어디서 온 호출인지 식별하는 키
- 프로세스의 구분 번호
0 ~ 65535 : 할당 가능 범위
0 ~ 1023 잘 알려진 포트 사용을 권장하지 않는다.
- FTP 20, 21
- TELNET 23
- HTTP 80
- HTTPS 433
DNS ( Domain Name System)
- IP는 기억하기 힘들고 변경 될 수 있다. :: 정확한 주소가 될 수 없다.
- 전화번호부 같은데
- DNS 서버에서 IP Address를 관리한다.
URI / Web Browser Flow
URI ( Uniform Resource Identifier )
URI
- 로케이터(Locator) , 이름(Name) 또는 둘다 추가로 분류될 수 있다.
- 가장 큰 개념 단위
- 자원
- U : 리소스를 식별하는 통일된 방식
- R : 자원 URI로 식별할 수 있는 모든 것 ( 제한이 없다 )
- I : 다른 정보들과 식별하기 위한 정보
URL : 리소스가 있는 위치를 지저
URN : 리소스에 이름을 부연
- 위치는 변할수 있지만 이름은 변하지 않는다.
- URN만으로 리소스를 찾을 수 있는 방식이 없다.
- URL과 URI를 동일한 의미로 활용해도 괜찮다…(?)

URL 문법
| 프로토콜 | https | 어떤 방식으로 자원하고자 하는 규칙 (Http , Https , FTP)
http : 80 / https : 443 :: Http+Secure ==https |
| --- | --- | --- |
| 호스트명 | www.google.com | 도메인의 명(DNS에 등록된) IP주소 |
| 포트번호 | 443 | 생략 가능 (80 , 443등) |
| 패스 | /search | 리소스가 있는 경로 (Webapp폴더?)
계층적으로 구현 되어 있는 리소스 경로 |
| 쿼리 파라미터
쿼리 스트링 | q=hello&hl=ko | K : V 형태로 전달하는 웹서버로 전달하는 파라미터
다 문자열 형태이기 때문에 스트링이라 표현한다. |
| Fragment | [#fragment] | html 내부의 북마크등으로 활용된다 ,
서버로 전송되는 정보가 아니다 |
웹 브라우저의 요청 흐름
DNS 서버를 조회
⇒ IP 주소를 조회
- Https는 port는 생략
⇒ “웹브라우저가” HTTP 요청 메세지 생성
⇒ Socket 라이브러리를 통해 전달
⇒ A : TCP / IP 연결 ( IP / PORT )
⇒ B : 데이터 전달
⇒ 패킷 생성
- 출발지 IP.와 PORT
- 도착지 IP.와 PORT
- 웹브라우저가 생성한 HTTP 요청 메시지
⇒ 도착지의 서버가 패킷을 해석해 다시 HTTP 응답메세지를 생성 후 패킷 반환
⇒ 웹 브라우저가 패킷을 분석 후 HTTP페이지를 랜더링
HTTP 기본
HyperText Transfer Protocol
초기에는 HTML 파일만 송수신하는 프로토콜이였지만
이제는 모든 형태의 자료형을 HTTP 프로토콜을 따른다.
중요한 역사
HTTP/1.1
- 1997년
- 가장 많이 사용
- RFC2068(1997) → RFC2616(1999)→ RFC7230~7235(2014)
- 거의 모든 기반이 다 1.1에 구현
TCP 기반 구현 ( 3버전은 UDP 기반 속도 향상을 위해 정확성을 저하 성능을 향상 )
2버전과 3버전은 성능 개선이 중점
HTTP 특징
- 클라이언트 서버 구조
- Request , Response 구조
- 클라이언트는 Request ⇒ Response까지 대기
- 서버가 요청에 대한 결과를 만들어 내어 응답
클라이언트 ⇒ 요청 ⇒ 서버 || 서버 ⇒ 응답 ⇒ 클라이언트 - 클라이언트는 본인의 역할에만 집중 ( 필요한 정보를 요청후 전달받은 응답으로 목적을 수행하면 됨
- 서버는 서버의 역할에 집중 ( 요청 정보를 응답해주기만 하면됨 )
- 양쪽이 독립적
- 무상태 프로토콜(Statless)
- Stateful
- 상태를 유지
- 제품을 구매할때 한 점원이 계속 처리해주어 처음부터 설명하지 않아도 된다
- Statless
- 상태를 유지하지 않는다
- 제품을 구매할때 매번 점원이 달라져 처음부터 설명해야한다.
- 무상태는 응답서버를 쉽게 바꿀수 있다 ⇒ 무한 서버 증설 쌉 가능
- 무상태는 갑자기 요청 트래픽이 증가해도 대응 가능 ⇒ 서버증설
- 무상태의 단점은 전송되는 요청의 양이 좀더 많다.
- 사실 모든것을 무상태로 설계 할 수 있는 경우도 있지만 없는 경우도 있다.
- 로그인같은 경우 상태를 유지해야한다
- 일반적으로 쿠키와 서버세션등의 기능을 사용해 상태를 유지한다.
- Stateful
Web Application은 최대한 Stateless를 유지한다.
- 비연결성
- TCP/IP 기본적으로 연결성
- 필요한 요청과 응답만 처리하고 바로 연결은 끊어버린다
- 서버의 자원을 굉장히 Safe 할 수 있다.
- HTTP는 기본적으로 연결을 유지하지 않는 모델
- 수천명이 서비스를 이용해서 실제 서버는 동시에 처리하는 요청이 수십개 정도로 수행된다.
- 클라이언트는 브라우저 요청을 계속해서 하지 않아서
- 비연결 단점
- 새로 연결하면 다시 TCP/IP 3핸드쉐이크를 수행한다
- JS나 CSS등 추가적인 자료들도 계속 받아진다.
- 현재는 HTTP 지속 연결( Persistent Connection )으로 문제를 해결했다.
- 2버전과 3버전에서 최적화가 많이 일어났다.
- 기존에는 매번 HTML페이지 , JS파일 ,CSS을 매번 끊었버렸다 다시 연결해 가져왔다.
- 최초에 연결 후 종료시 까지 연결을 유지한다 ⇒ 지속 연결
- 정말 같은 시간에 딱 맞추어 발생하는 대용량 트래픽
- 선착순 이벤트 ( 배민 치킨 쿠폰 )
- 명절 KTX이벤트
- 수강 신청
-
HTTP 메세지
-
HTTP 메시지 구족
| start - line 시작 라인 |
|---|
| header 헤더 |
| empty line 공백 라인 ( CRLF ) |
| message body |
- Header 다음에 무조건 공백 라인이 있어야한다.
시작 라인
-
Request-line 요청 메세지
-
HTTP 메서드 ( GET : 조회 ) + 요청 대상 ( /search?q=hello&hl=ko) + HTTP Vesion
-
HTTP 메서드
- GET. : 리소스를 조회
- POST : 요청 처리
- PUT : 리소스 수정
- DELETE : 리소스 삭제
-
요청 대상
- 절대경로로 시작
- “/”으로 시작하는 경로
-
HTTP Version
- http의 버전 1.1 /2 /3
-
Status-line 응답 메세지
-
HTTP 버전
-
HTTP 상태 코드
- 200 : 성공
- 400 : 클라이언트 오류
- 500 : 서버 내부 오류
-
이유문구 : 상태코드를 나타내는 간단한 문자
HTTP Header
-
필드 네임 “ : ” OWS 필드값 OWS
-
field-name 은 대소문자 구분이 없다.
-
용도
- HTTP 전송에 필요한 모든 정보
- 메시지바디의 내용,크기,압축여부
- 인증, 요청 정보(브라우저)
- 서버,캐시관리 정보
- 표준 헤더가 너무 많다.
- 임의의 헤더 추가가 가능하다
HTTP Message Body
- 실제 전송할 데이터
- JSON
- HTML , FIle 등 모든 바이트로 표현 가능한 자료
