
이전 글에서 채용 정보의 모델(ORM)을 설계하고,
간단하게 등록 & 조회하는 API 까지 만들어 보았다.
이전 글 : 파이썬 FastAPI를 이용한 API 프로젝트 만들기 (0) - 소개 및 예제
다음으로, 채용 정보를 자동으로 스크랩하고 DB에 저장하는 예제를 알아 보도록 하자.
채용 정보의 HTML 구조 - 원티드
원티드에서 원하는 검색어(기술스택?)로 조회한 결과 페이지안에 있는 포지션 탭의 채용 정보를 스크래핑 할 것이다.
URL 패턴은 https://www.wanted.co.kr/search?query={keyword}&tab=position 이렇게 구성이 되어있는데
원하는 키워드만 URL의 쿼리 파라미터로 전달하면 될 것 같다.
다음 이미지는 “flutter” 키워드로 검색한 화면이다. - https://www.wanted.co.kr/search?query=flutter&tab=position
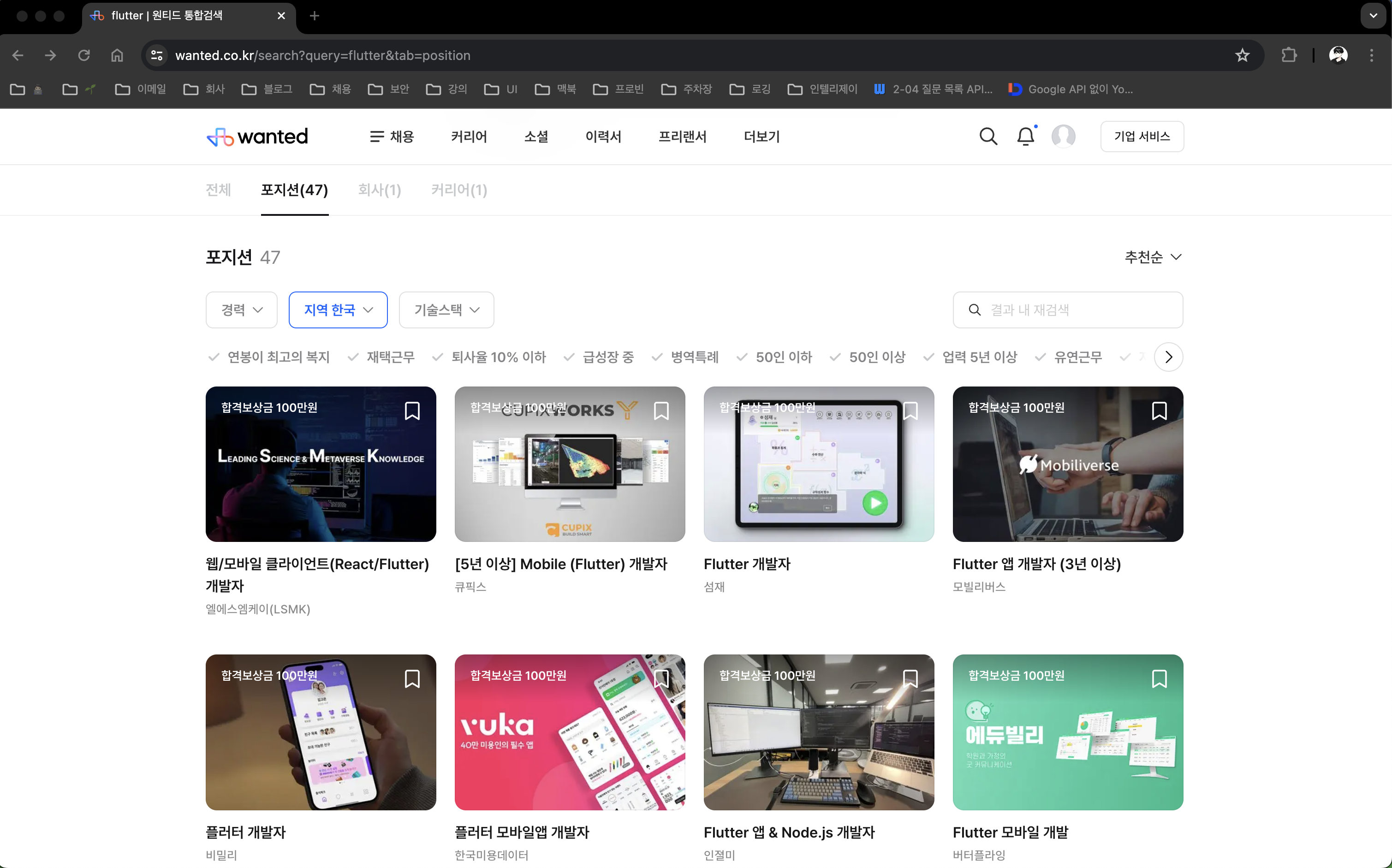
총 47개의 채용 정보가 존재하는데 위의 화면에서는 페이징이 따로 존재하지 않으며, 스크롤을 내릴 때 추가적인 채용 정보가 로드된다.
채용 정보가 전체 로드되면 스크롤을 내려도 아무런 이벤트가 없어진다.
그러면, 각 각의 채용정보를 가져오기 위한 HTML element 구조를 알아보자.
브라우저의 개발자 도구를 사용하면 보다 쉽게 구조를 쉽게 파악할 수 있다.
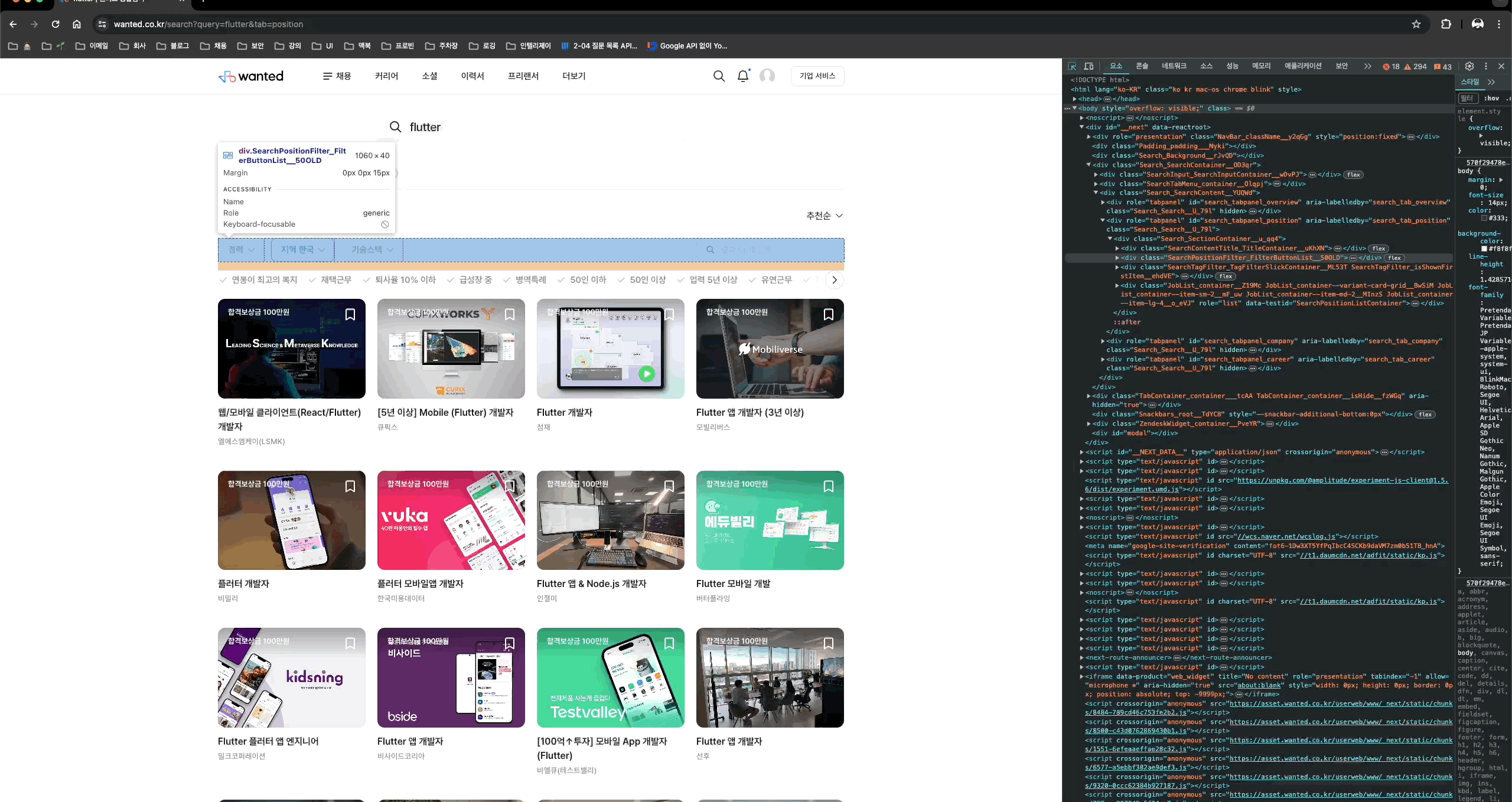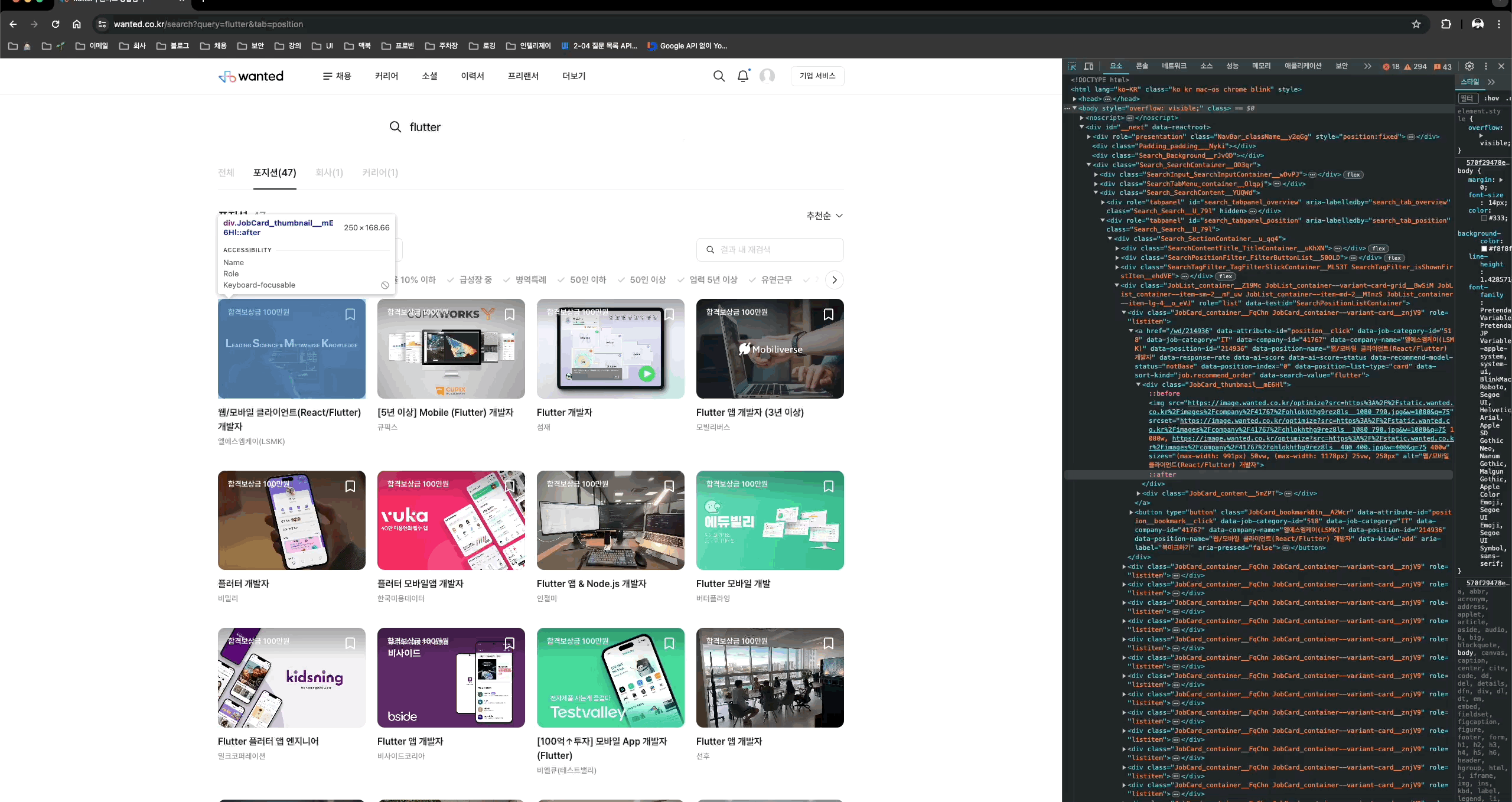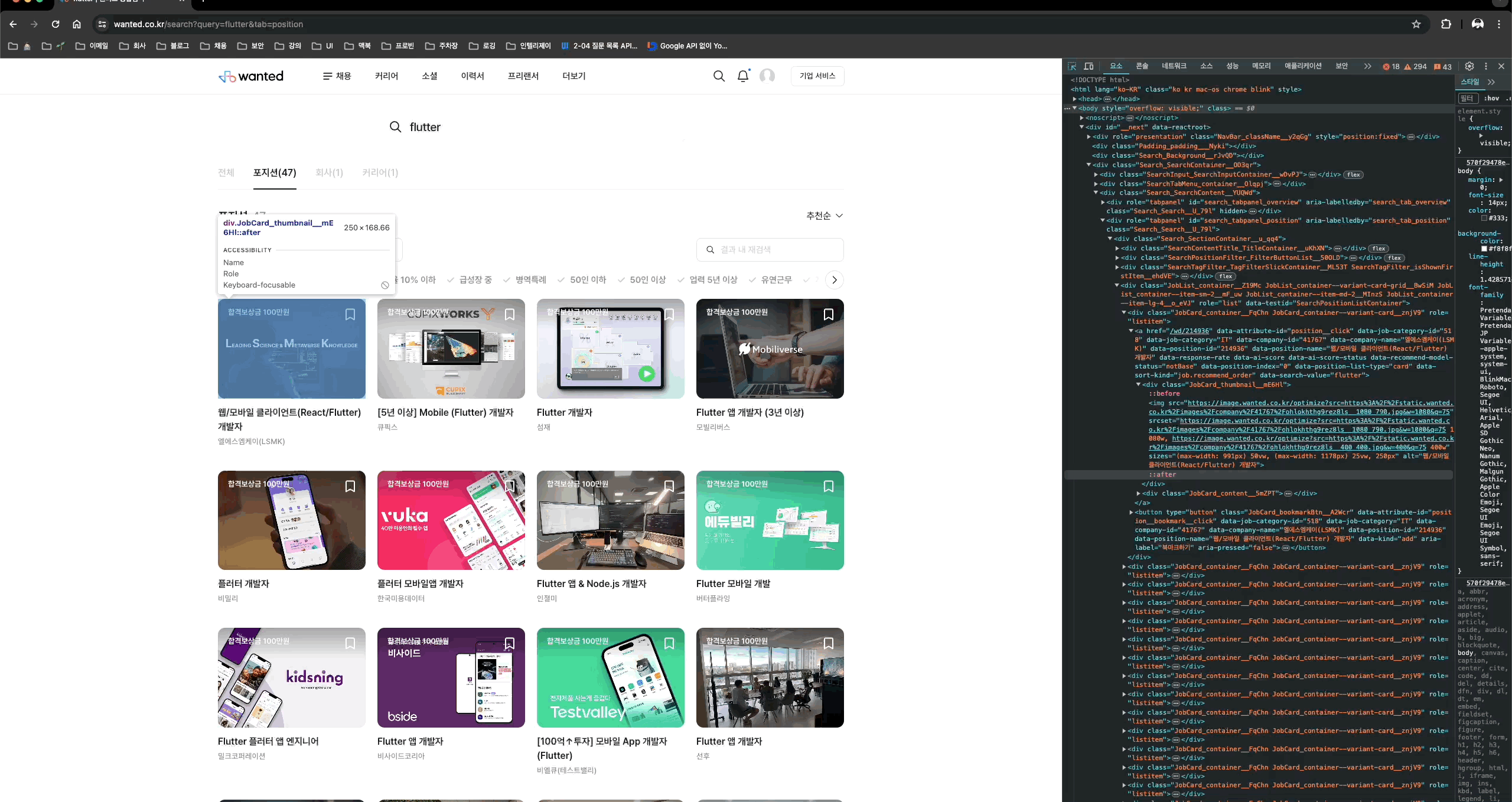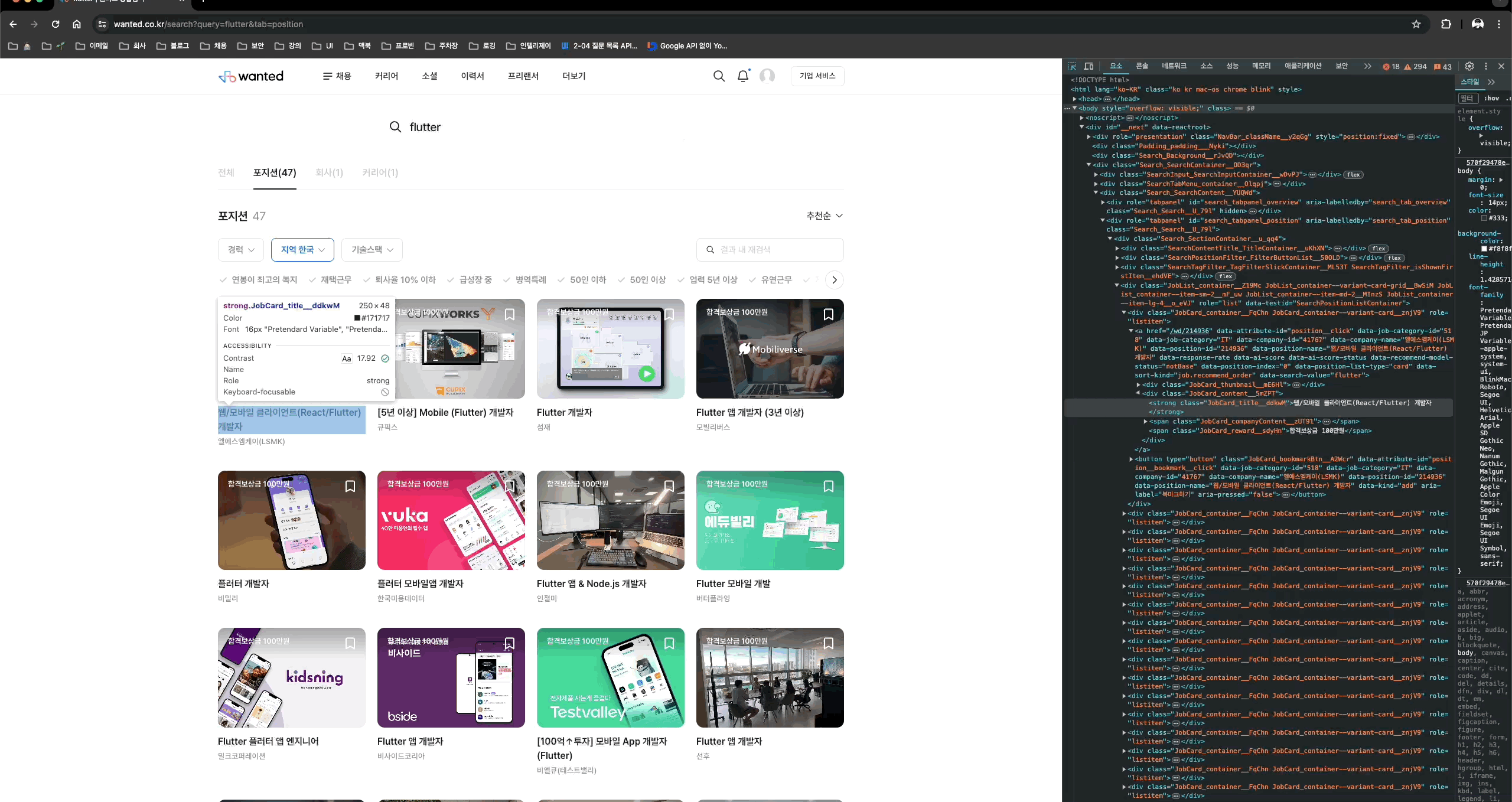
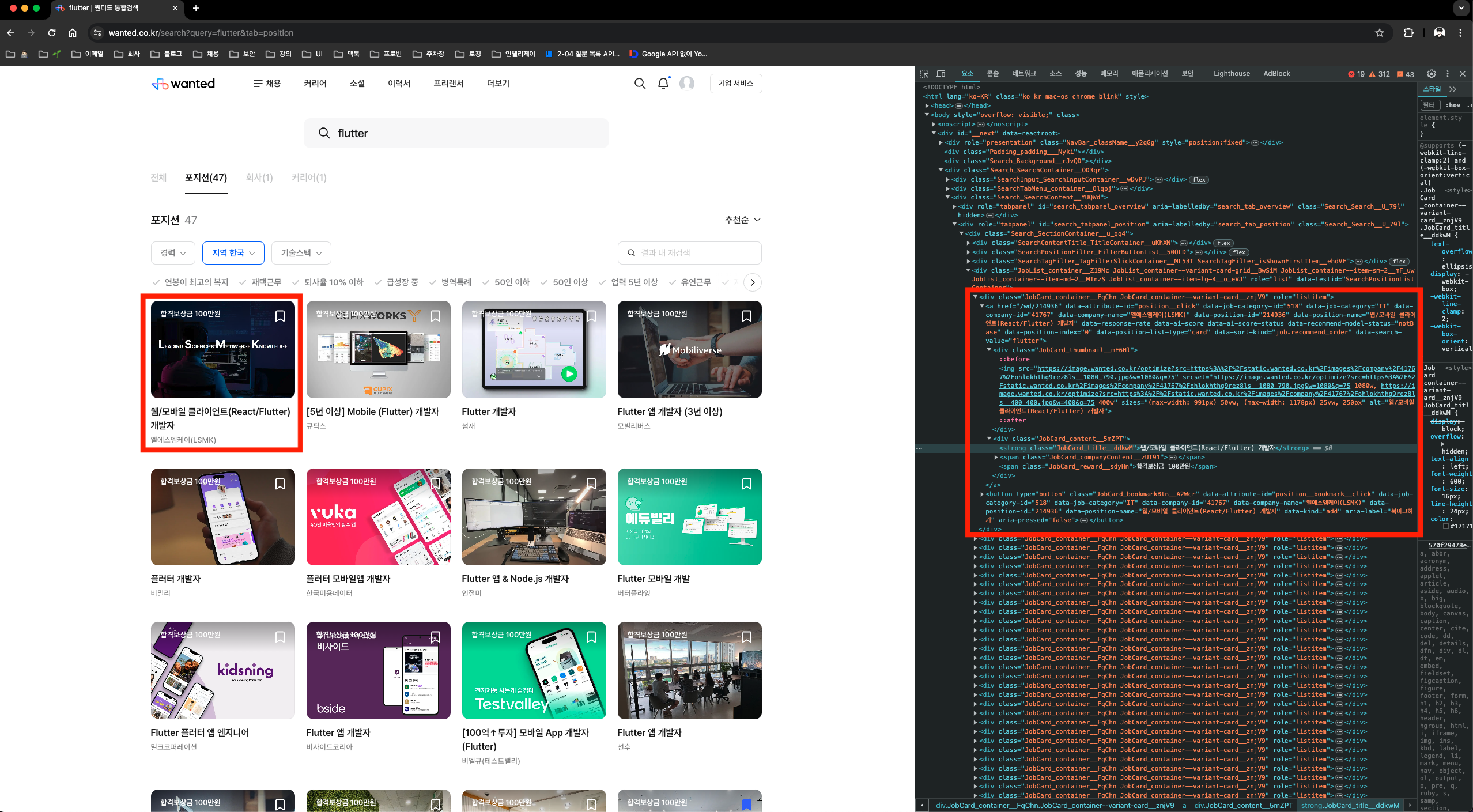
각각의 채용정보는 class명이 JobCard_container__FqChn인 div태그로 이루어져있다.
해당 div 안에
포지션은 class 명이 JobCard_title__ddkwM인 strong태그이고,
회사이름은 class 명이 JobCard_companyName__vZMqJ인 span태그이다. (생각보다 심플하다.. )
스크래핑 코드 작성
HTML 구조는 파악 했으니 실제로 원하는 데이터를 추출하는 스크래핑 코드를 파이썬으로 작성해보자
1. 패키지 설치
# HTML source를 파싱하는 패키지 설치
pip install beautifulsoup4
# 브라우저 자동화 패키지
pip install playwright이전에 작성했던 글 중 파이썬 웹 스크래핑에 사용한 브라우저 패키지는 Selenium 이였지만 이번 예제에서는 Playwright 패키지를 사용하였다.
찾아보니, Playwright가 Selenium 보다 많은 브라우저를 지원하여 크로스 브라우저 테스트를 쉽게 수행할 수 있다는 점과 성능과 안정성도 뛰어나서 이번에 사용하게 되었다.
2. 스크래핑으로 추출한 데이터 클래스 정의
# employ_schema.py 수정
... (생략) ...
# (추가) 스크래핑으로 추출한 데이터 클래스 정의
class EmployScrap:
def __init__(self, keyword, company_name, position):
self.keyword = keyword
self.company_name = company_name
self.position = position
3. 채용정보 스크래핑 신규 작성
# employ_scrap.py 작성
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
from domain.employ.employ_schema import EmployScrap
import time
# 특정 키워드로 채용 정보를 가져와 EmployScrap 값들을 리턴하는 함수 정의
def get_employ_by_wanted(keyword):
# Playwright 시작
p = sync_playwright().start()
# Chromium 브라우저 실행
browser = p.chromium.launch(headless=False)
# 새로운 페이지 열기
page = browser.new_page()
# 키워드를 이용하여 채용 정보 검색 결과 페이지 - 포지션 탭으로 이동
page.goto(f"https://www.wanted.co.kr/search?query={keyword}&tab=position")
# 페이지가 로드될 때까지 스크롤 다운 반복
for x in range(5):
time.sleep(3) # 3초 대기
page.keyboard.down("End") # End 키를 눌러 페이지의 끝까지 스크롤 다운
# 페이지의 HTML 내용 가져오기
content = page.content()
# 브라우저 닫기
browser.close()
# Playwright 종료
p.stop()
# BeautifulSoup을 사용하여 HTML 내용 파싱
soup = BeautifulSoup(content, "html.parser")
# 채용 정보가 담긴 요소들을 찾아서 jobs 리스트에 저장
jobs = soup.find_all("div", class_="JobCard_container__FqChn")
# 채용 정보를 저장할 리스트 초기화
jobs_db = []
for job in jobs:
# 채용 정보에서 포지션과 회사 이름 추출
position = job.find("strong", class_="JobCard_title__ddkwM").text
company_name = job.find("span", class_="JobCard_companyName__vZMqJ").text
# 추출된 정보를 데이터베이스에 저장할 형식으로 변환하여 jobs_db 리스트에 추가
jobs_db.append(EmployScrap(keyword, company_name, position))
# 데이터베이스에 저장할 채용 정보가 담긴 리스트 반환
return jobs_db
4. 스크래핑 데이터 쿼리 함수 정의 추가
# employ_crud.py 수정
from sqlalchemy import and_ # 추가
from domain.employ.employ_schema import EmployCreate, EmployScrap # 추가
... (생략) ...
# 채용 정보 삭제 By 키워드, 플랫폼
def employ_delete(db: Session, keyword: str, platform: str):
db.query(Employ) \
.filter(and_(Employ.keyword == keyword, Employ.platform == platform)) \
.delete(synchronize_session=False)
db.commit()
# 스크래핑 채용 정보 등록
def employ_scrap_renew(db: Session, create_request: EmployScrap, platform: str):
db.add(Employ(platform=platform,
keyword=create_request.keyword,
company_name=create_request.company_name,
position=create_request.position,
create_date=datetime.now()))
db.commit()5. 채용 정보 갱신 라우터 추가
# employ_router.py 수정
from domain.employ import employ_schema, employ_crud, employ_scrap 추가
... (생략) ...
# 채용 정보 원티드 갱신 API
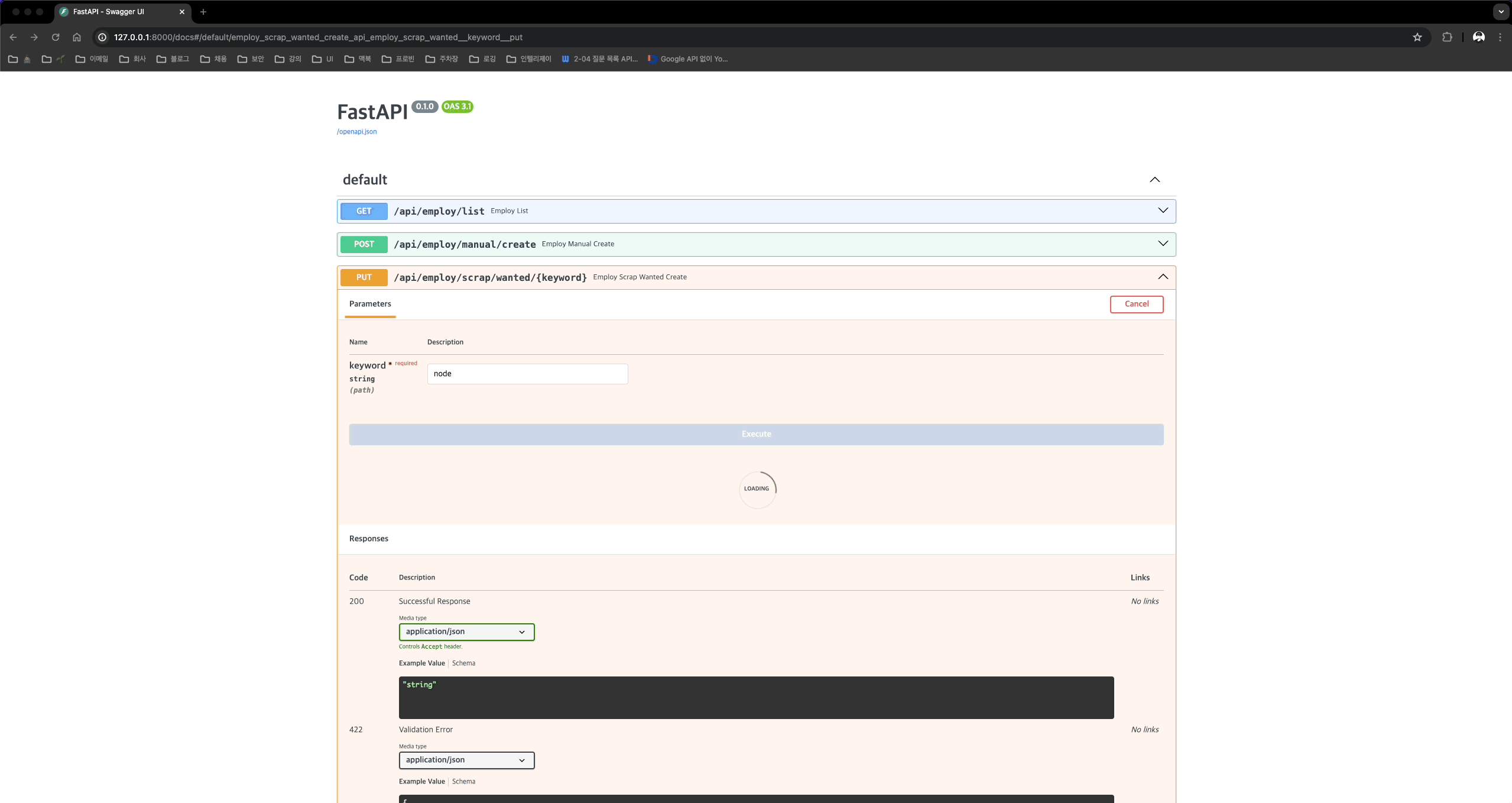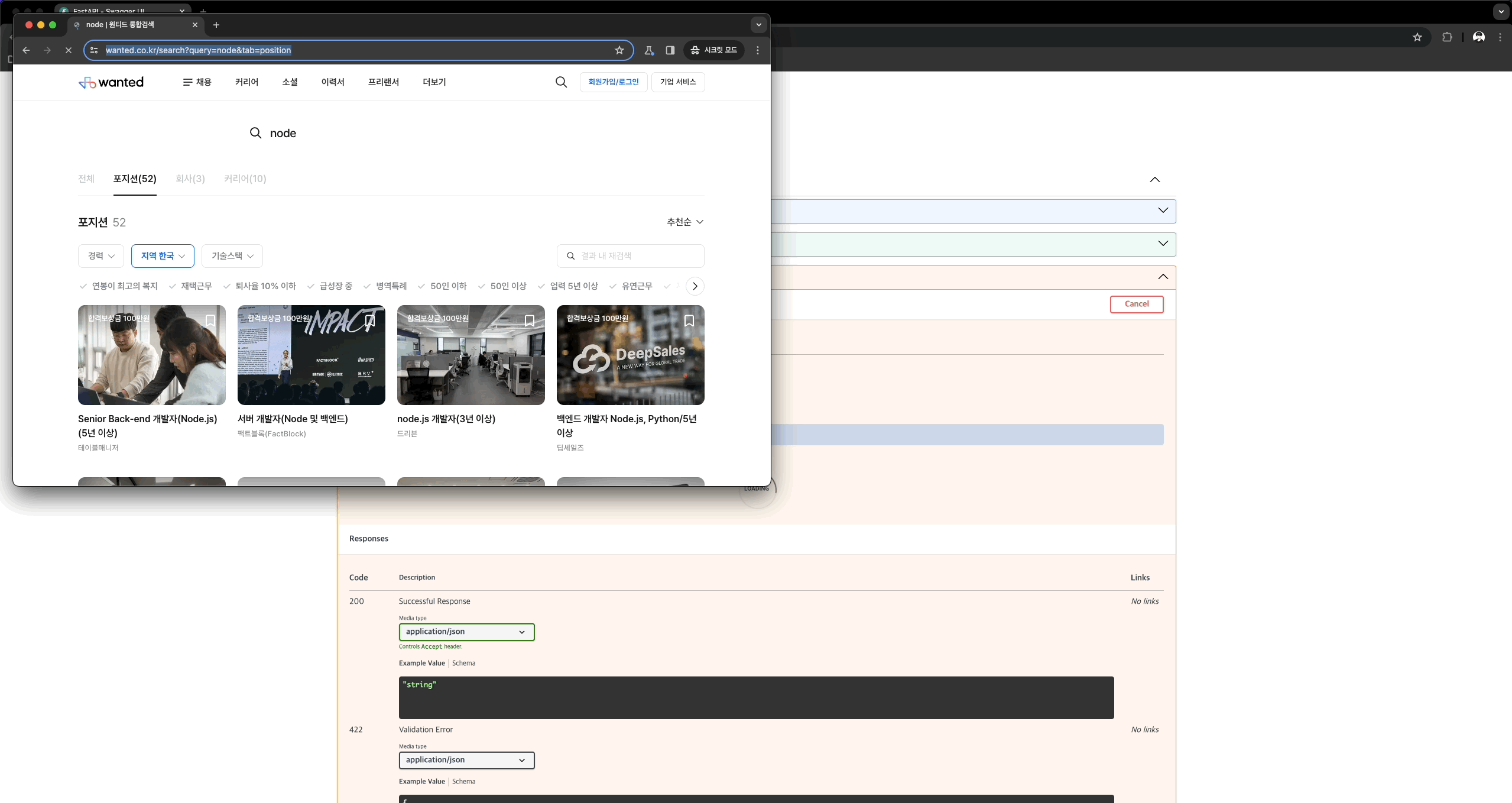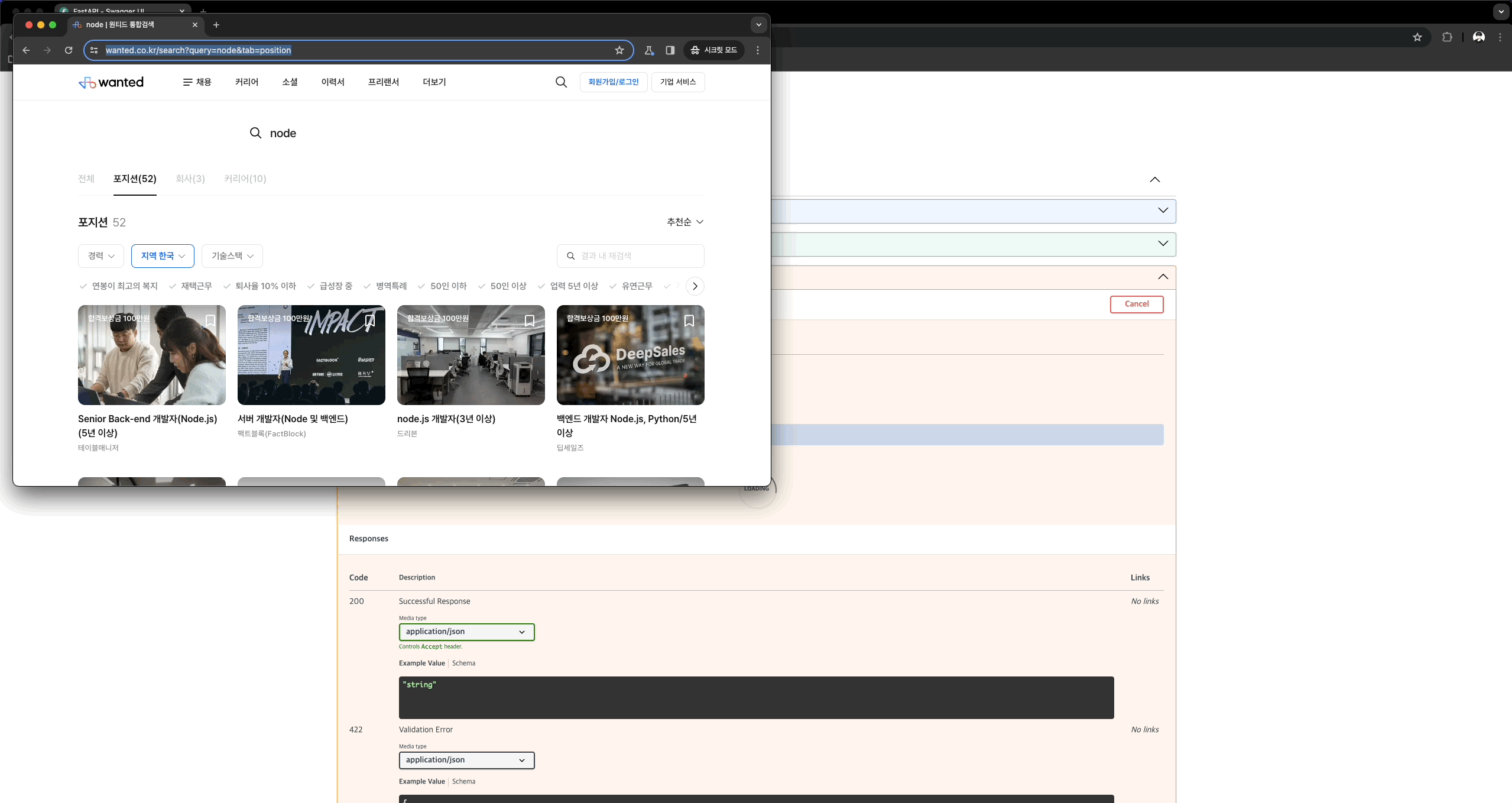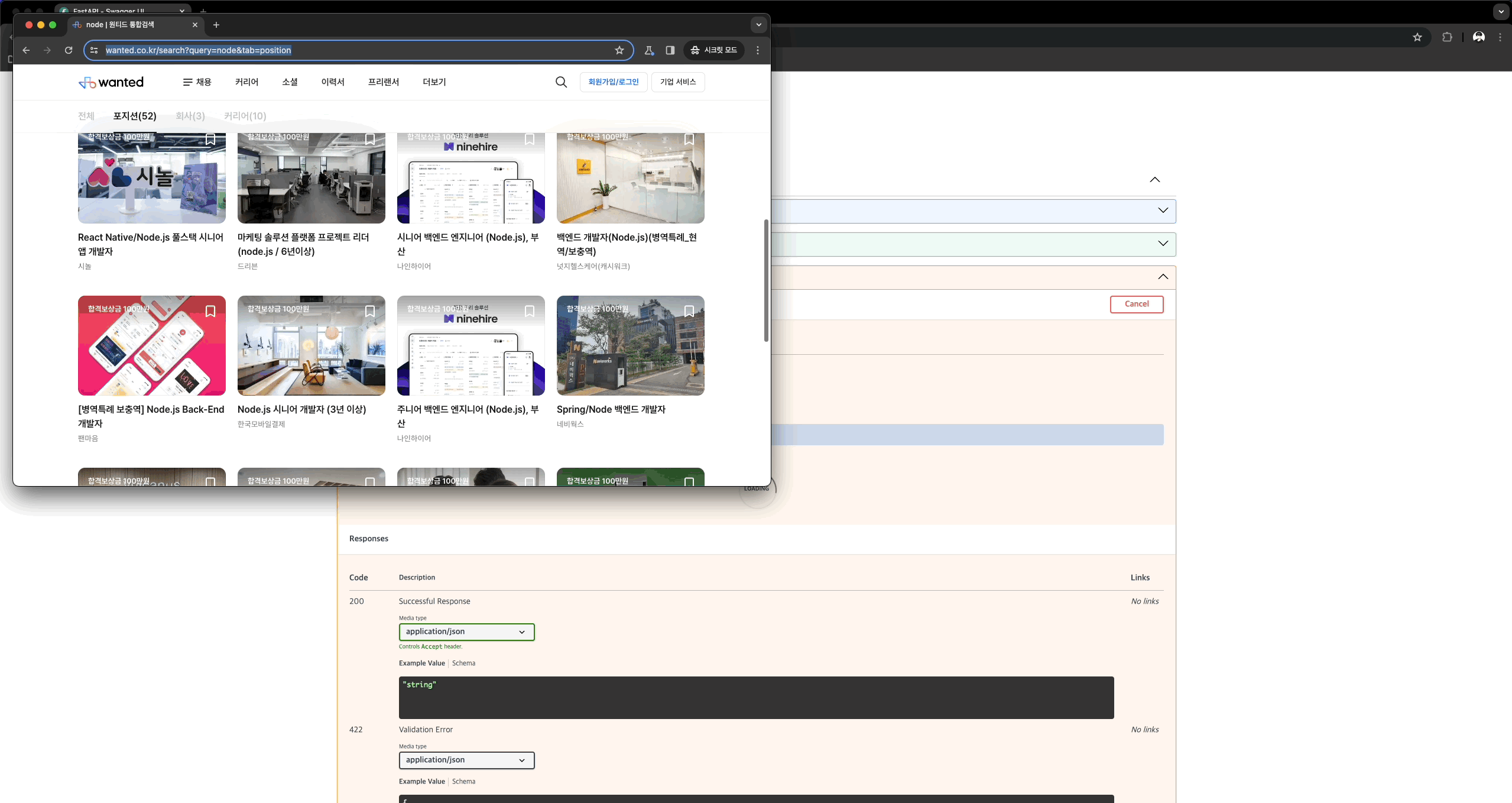
@router.put("/scrap/wanted/{keyword}")
def employ_scrap_wanted_create(keyword: str, db: Session = Depends(get_db)):
platform = "WANTED"
# 스크랩 한 원티드의 채용 정보
employs = employ_scrap.get_employ_by_wanted(keyword)
if employs:
# 갱신전, 키워드와 플랫폼으로 기존 채용 정보 삭제
employ_crud.employ_delete(db, keyword, platform)
for employ in employs:
# 스크랩한 채용 정보 저장
employ_crud.employ_scrap_renew(db, employ, platform)코드 작성은 완료 하였고, 아래 명령어를 터미널에 입력하여 서버를 실행해보자.
uvicorn main:app --reloadhttp://127.0.0.1:8000/docs 에 접속하면 채용 정보 갱신 API가 추가 된 것을 확인할 수 있다.
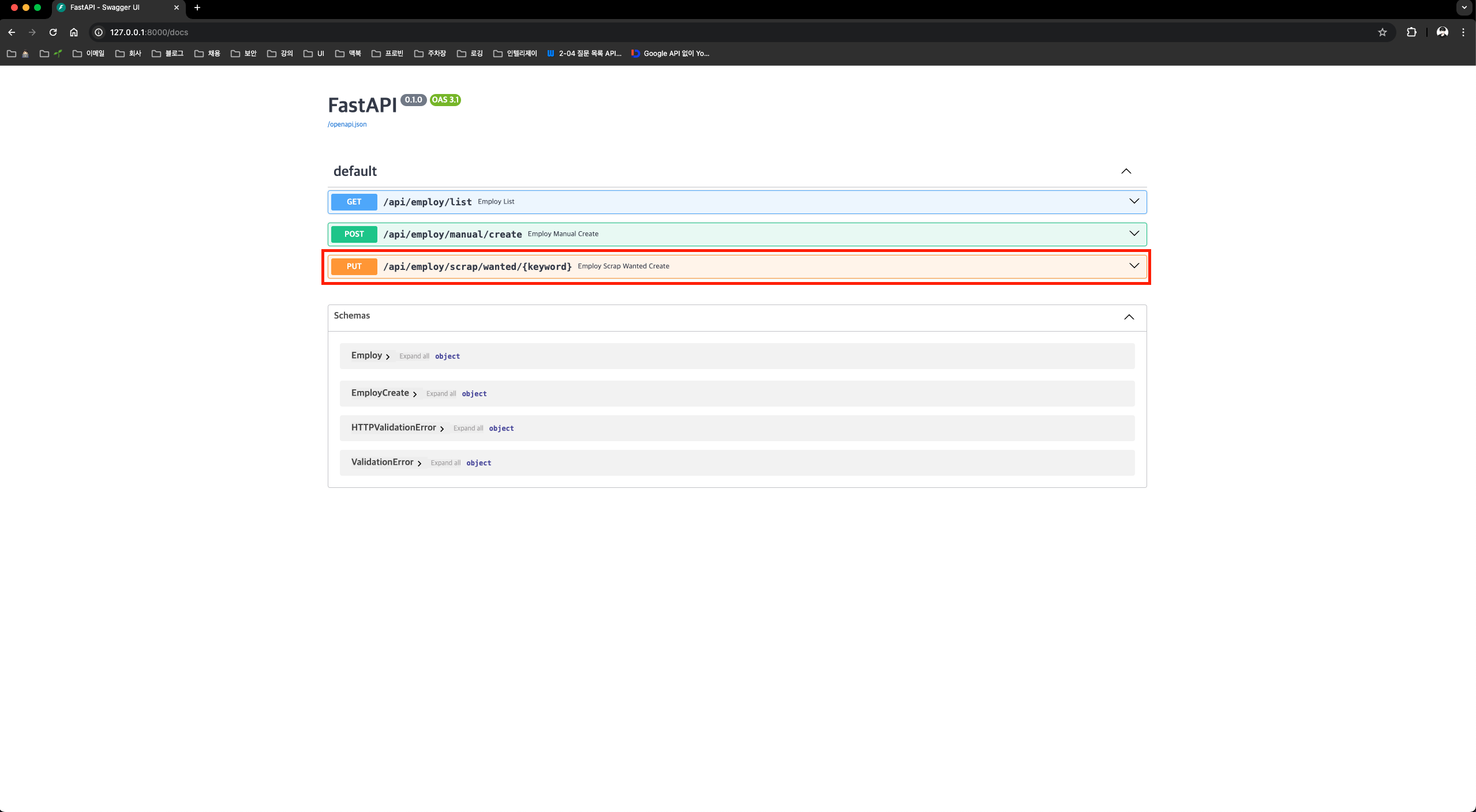
다음 이미지 처럼 keyword에 “node”라고 입력 후 Execute 버튼을 누르면 API가 호출되며,
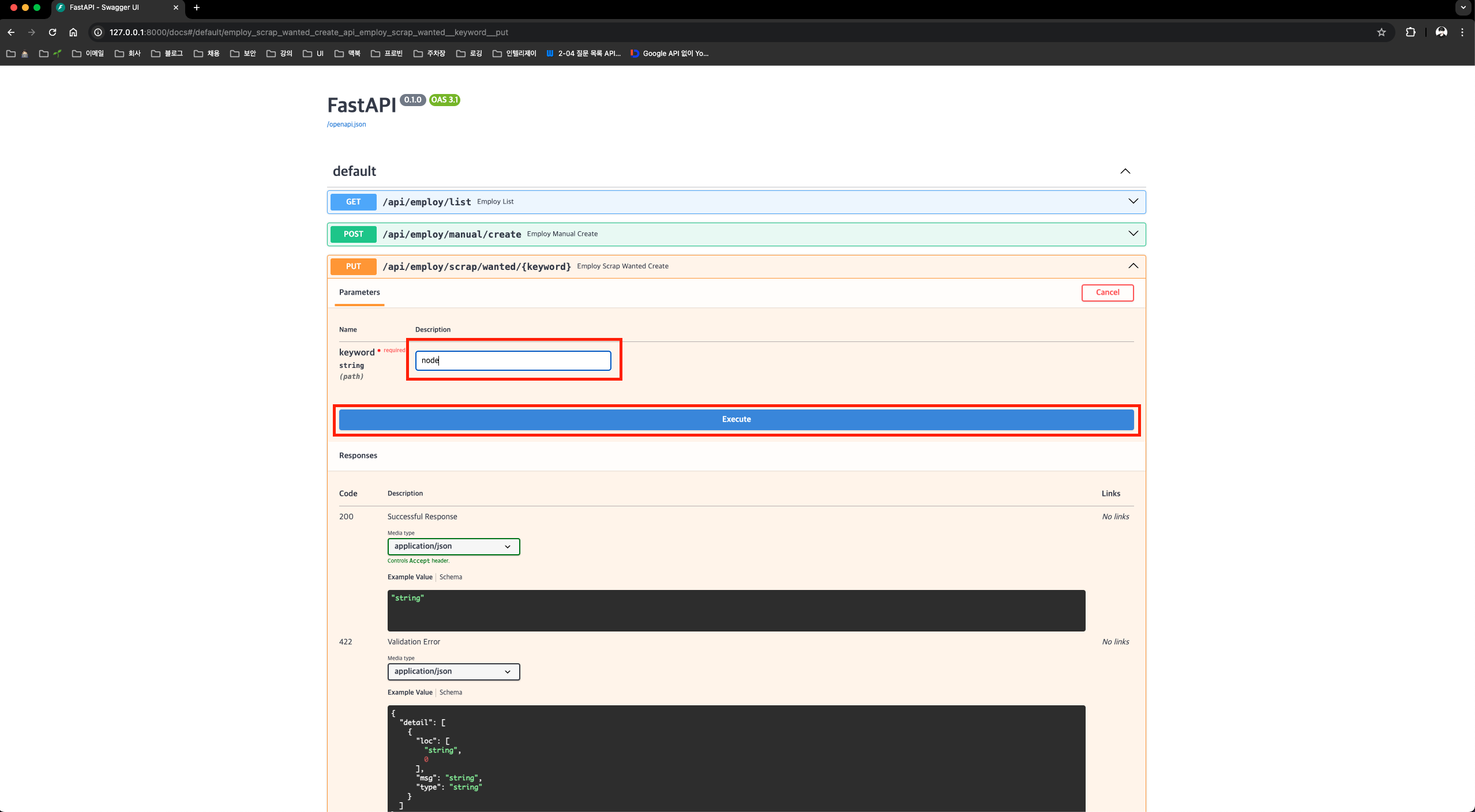
스크래핑 과정을 시각적으로 확인 할 수 있다. (브라우저 창이 뜨면서 페이지 로드 이후, 스크롤 다운 이벤트가 발생된다.)
스크래핑이 완료되면 이전에 만든 조회 API 를 통해 keyword가 node인 데이터를 확인 할 수 있다.
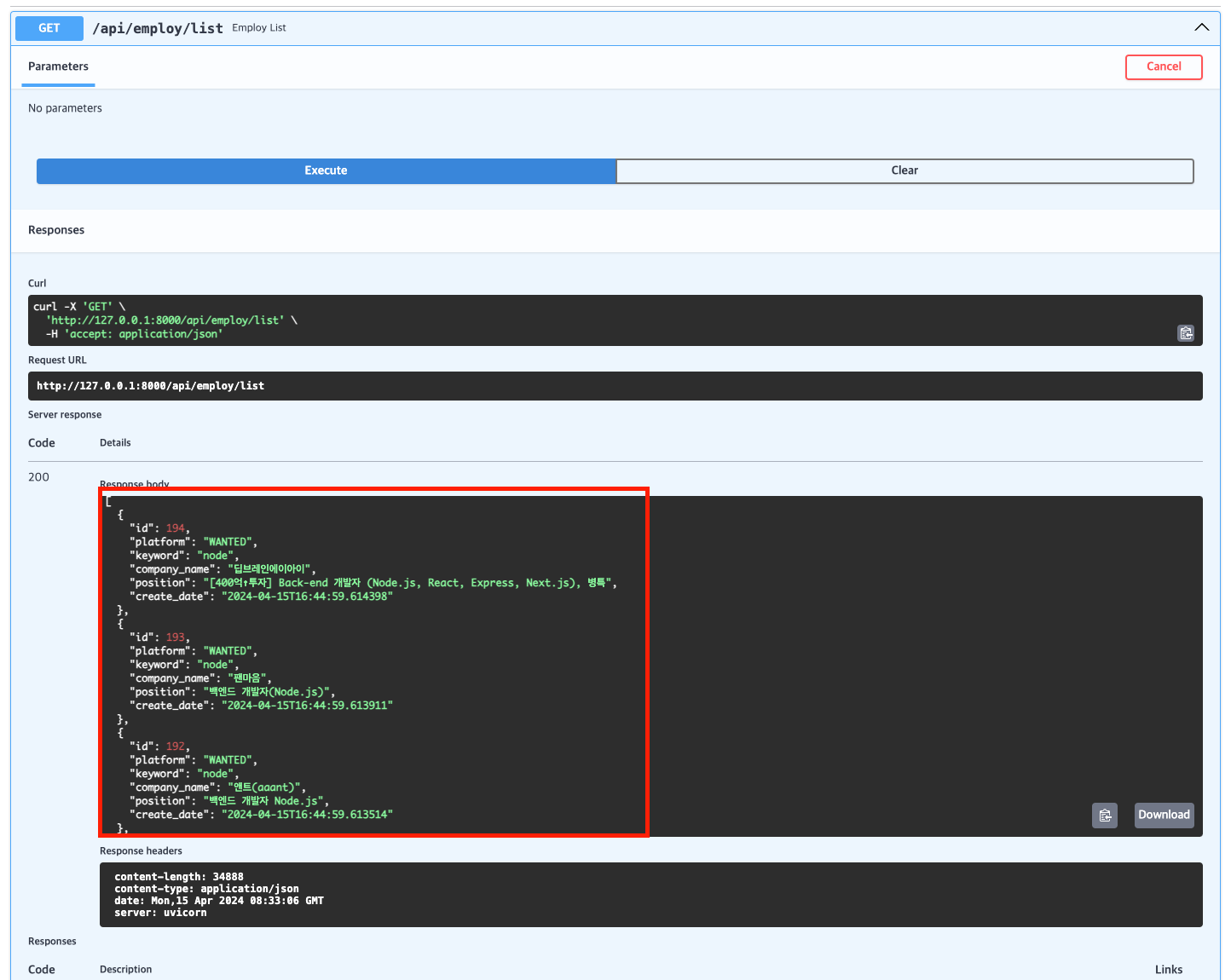
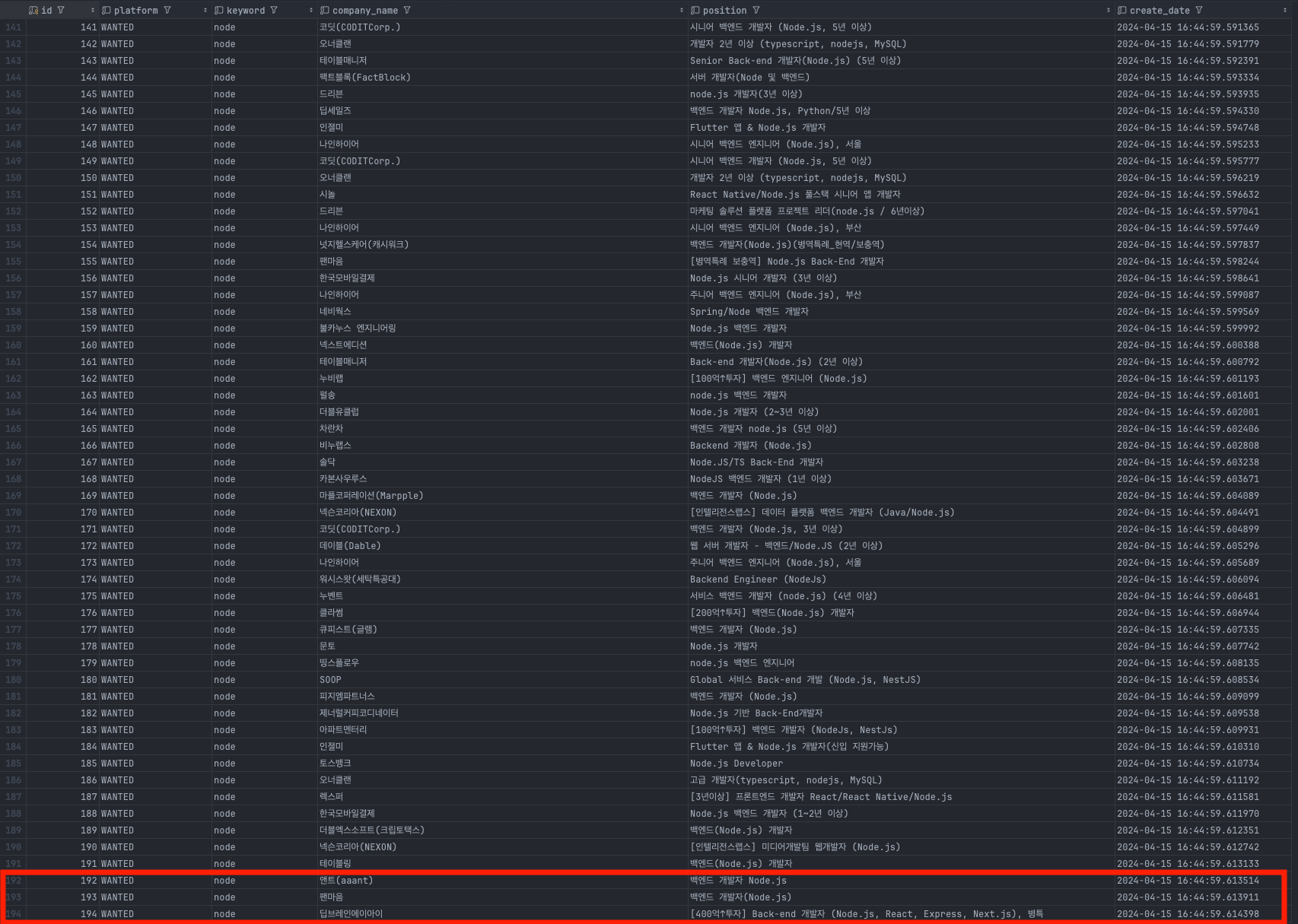
다음은, 실제 SQLite 에 저장한 DB 쿼리 조회 결과이다. API에 조회된 데이터도 같이 확인 가능하다.
마무리
이렇게 게시글 2개로 짧게나마!? FastAPI에 대해서 공부해보고 실제 토이 프로젝트도 작성해보았다.
프로젝트를 구현하면서 적절하게 패키지를 잘 활용하면 소스가 더 간결해지고 가독성도 좋아진다.
사이드 프로젝트나 토이 프로젝트에서 간단한 API 백엔드를 구성해야된다면 FastAPI를 실제로 도입해보고 사용해도 나쁘지 않을 것 같다는 생각이 들었다.
마지막은 역시나 파이썬의 재밌는 짤과 깃허브 주소와 함께 글을 마무리 해볼까 한다.

출처 : https://www.inflearn.com/pages/inflearnsnack-6-20220802
https://github.com/discphy/fastapi-scrap
[참고]
