발표가 7일 금요일로 미뤄지고 하다보니 속도가 너무 느려서 다른분들이랑 차이가 나서 수요일 부터 도움을 구하면서 하게 되었습니다.
Mariadb replication
출처 링크 mariadb 공식사이트(replication command): https://mariadb.com/kb/en/standard-replication/
https://mariadb.com/kb/en/setting-up-replication/
mariadb replication은
MASTER NODE의 DB를 SLAVE NODE의 DB에
자동 복제 할수 있도록 하는 설정이다.
그래서 여기서는 Master Node의 DB를 demo07
SLAVE NODE의 DB를 demo08로 설정하였다.
USER 생성
master에
유저를 만들고 slave권한을 부여한다
CREATE USER 'replication_user'@'%' IDENTIFIED BY 'bigs3cret';
GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'%';DB config 수정
Master node config - demo07
demo07 /etc/my.cnf.d/server.cnf

log-bin 마스터 노드에서 로깅을 실행하고
server_id는 1번
log-basename은 master1로
binlog-format=mixed 이거는 로그를 어떤 포맷으로 설정하는지를
Slave node config - demo08
demo08 /etc/my.cnf.d/server.cnf

server_id 는 2로
config 설정은 완료하면
systemctl restart mariadb적용시켜주시면 된다.
Master-slave sql command
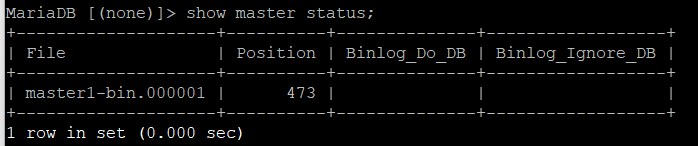
matser - master status
show master status를 통해서 마스터(demo7)의 bin-log 파일의 이름(log-basename)과 포지션을 확인하고
slave - change master
slave(demo08)에서
CHANGE MASTER TO
MASTER_HOST='192.168.203.201', # 마스터 노드 호스트명
MASTER_USER='replication_user', # 생성했던 유저이름
MASTER_PASSWORD='bigs3cret', # 비밀번호
MASTER_PORT=3306, # mariadb 포트
MASTER_LOG_FILE='master1-bin.000001', # 마스터 로그파일이름
MASTER_LOG_POS=330, # 포지션은 마스터의 status와 같은 숫자로
MASTER_CONNECT_RETRY=10; # 커넥션 재시도 시간설정
Error(replicating_do_db 옵션)
어디 블로그에서 replication 실습이 있길래 따라 하다가 틀렸는지
Replication_Do_DB 옵션에 repl_db라는 이름으로 실행 slave로 부터 master로 replication 실행하는 db를 지정하는 내용이 들어가있다.
근데 이렇게 하니까 연동이 잘 안되더라..
따라하다 에러난 실습 : https://qucdas.tistory.com/92
demo08 - slave node
slave running 둘다 NO
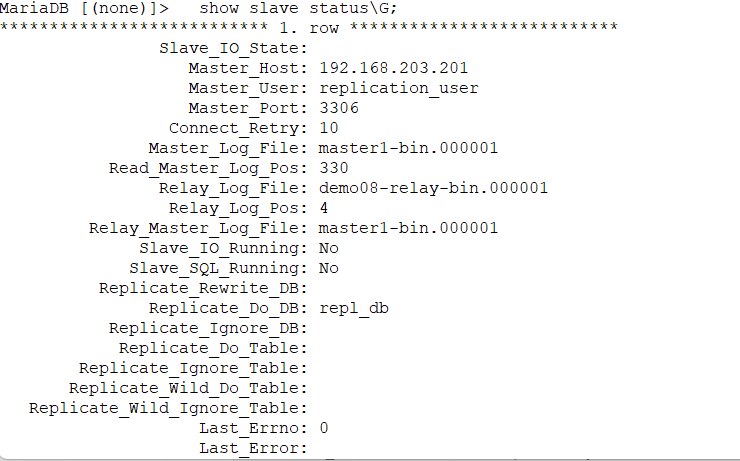
slave running sql만 YES
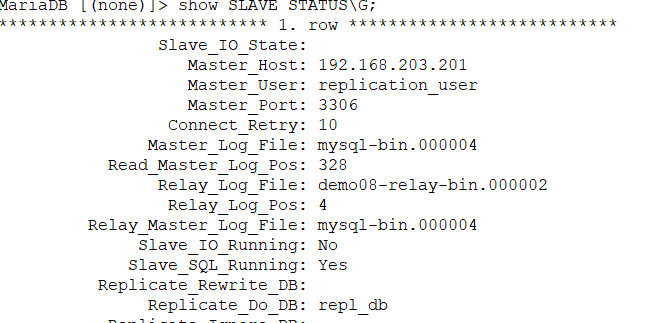
master-slave 연동이 안되는 경우가 자꾸 생겨서
demo 07
reset master;demo 08
reset all slave;master slave 설정들을 다 갈아엎고, server.cnf를 위쪽 설정으로 다시 따라하니까 된다.
아마 블로그 실습을 따라하다가
Replicate_DO_DB 에 repl_db라고 /my.cnf.d/server.cnf
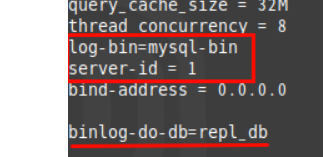
이렇게 고쳤던것이 있는데
CHANGE MASTER간에 replicate_DO_DB를 잘못해서 쿼리가 계속 Warning으로 되었던거 같다.
실행은 되지만 서로 다르니 warning을 출력하지 않았을까
자세한건 log파일을 더 보면 나올거같다.
Nginx config 수정, loadbalancing 설정
keepalive, haproxy 설정하고 실행하려는데 실행이 되지 않더라.
Nginx 포트를 80으로 설정했던것을 까먹고 haproxy restart 하다가 오류를 만났다.
haproxy listen을 80으로 두어놓고
nginx listen을 80으로 두어서 포트충돌 오류가 나는 어이없는 실수.
부랴부랴 nginx 설정을 바꾸기 위해서 켰다.
nginx loadbalancing에 관한 document 링크:
https://docs.nginx.com/nginx/admin-guide/load-balancer/http-load-balancer/
엔진 loadbalancing 하기 위해서는
또다시
/etc/nginx/conf.d/default.conf
에 해당하는 설정파일을 수정해 주어야한다.
demo07 nginx config
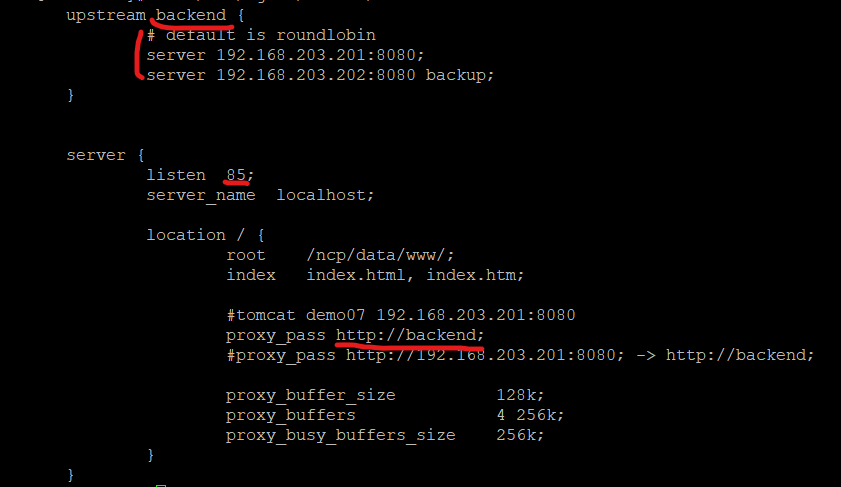
upstream backend {
# default is roundlobin
server 192.168.203.201:8080;
server 192.168.203.202:8080 backup;
}
server {
listen 85;
server_name demo07_nginx_server;
location / {
root /ncp/data/www/;
index index.html, index.htm;
#tomcat demo07 192.168.203.201:8080
proxy_pass http://backend;
#proxy_pass http://192.168.203.201:8080; -> http://backend;
proxy_buffer_size 128k;
proxy_buffers 4 256k;
proxy_busy_buffers_size 256k;
}
}
demo08 nginx config
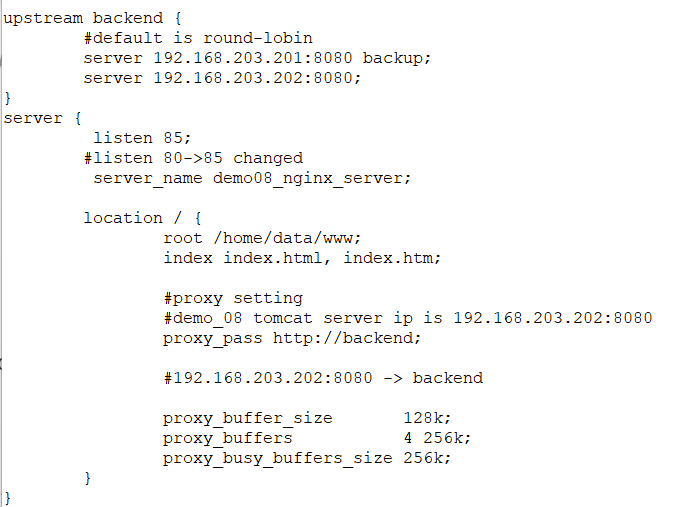
upstream backend {
#default is round-lobin
server 192.168.203.201 backup;
server 192.168.203.202;
}
server {
listen 85;
#listen 80->85 changed
server_name test-server;
location / {
root /home/data/www;
index index.html, index.htm;
#proxy setting
#demo_08 tomcat server ip is 192.168.203.202:8080
proxy_pass http://192.168.203.202:8080;
proxy_buffer_size 128k;
proxy_buffers 4 256k;
proxy_busy_buffers_size 256k;
}
}
upstream
upstream은 블럭을 만들어서 어떤 방식으로 loadbalancing 할지 설정해주고, 또 어떤 ip를 대상으로 loadbalancing을 할지를 구성하는 용도이다. 완성하면 하나의 host로 사용된다.
upstream 블럭으로 demo07,08의 tomcat server ip잡고
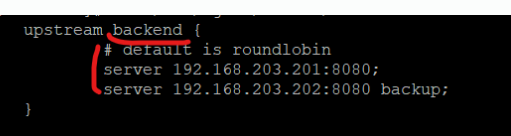
default로 설정하면 round-lobin 방식으로 밸런싱해주고
그렇지 않으면 직접 설정해야한다.
nginx에서 설정가능한 밸런싱 알고리즘 종류만 6가지이다.
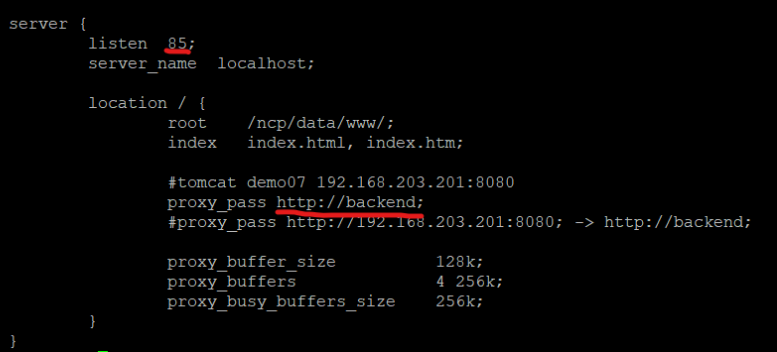
아까 실수한 listen port 80도 85로 고치고
proxy_pass 에는 backend를 넣어준다.
nginx upstream module 에 대한 다른 설명 링크:
https://faun.pub/nginx-upstream-module-part-01-e7433abcbf90
Error 포트충돌 80번
nginx
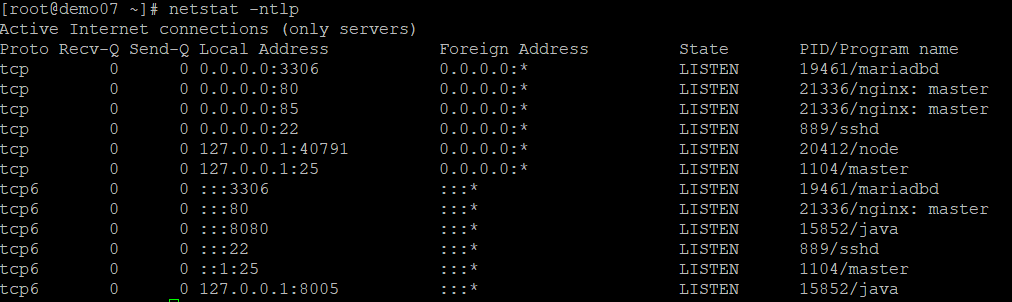
위의 config 그대로 설정하여 실행을 하니
85번 포트와 80포트가 동시에 열렸다.
nginx 끄고 haproxy 실행
나는 분명 85번만 listen 으로 했을텐데, default로 80포트가 같이 열리는 상황이 발생한거 같다.
이 링크를 보니
set header로 설정하면 nginx.conf 설정파일이 아니라 default.conf로 설정이 적용된다고 한다.
추가로 넣어줄 내용은
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
이다.
상위에서 nginx가 default Host,와 X-Real-IP에 대해서
$host와 $remote_addr로 설정이 되어있다라는 내용인데
이 내용은 /etc/nginx/nginx.conf 의 기본파일에는 없는 내용이었다.
그래서 nginx document를
nginx document passing request headers:

고치면 된다고 하는데 안되고 있다.. 04월 06일 오후 20시
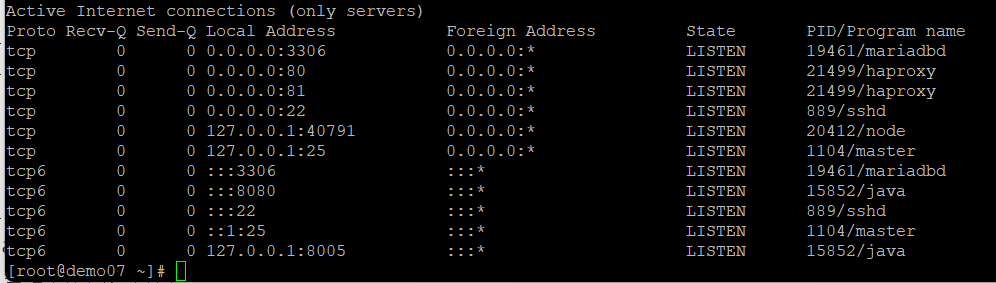
오후 10시에 에러를 잡았다.
그냥 /etc/nginx/nginx.conf 의 default 80포트를 85번 포트로 바꾸었다.
Keepalived (1.3.5)
keepalived가 뭔지도 모르고 사용하였는데 읽어보니 가상으로 네트워크 장비 및 ip를 만들어주고 관리하는 역할을 한다고 한다.
VRRP
VRRP 프로토콜은 근본적으로 router 장비의 failover(장애극복)을 위해 만들어진 프로토콜이고, 그 근간은 BFD 프로토콜로 부터 만들었다고한다.
BFD는 Bidirectional Forward Detection 의 약자로 양방향 포워딩 감지 프로토콜 이라고 한다. 하나가 포워딩이 끊기는것을 감지하는 프로토콜 이다.
/etc/sysconfig/network-scripts/
에서 직접 네트워크를 잡아주는 것을 대신 해주는 역할도 하는것 같다.
keepalived conf 설정
/etc/keepalived/keepalived.conf
demo07
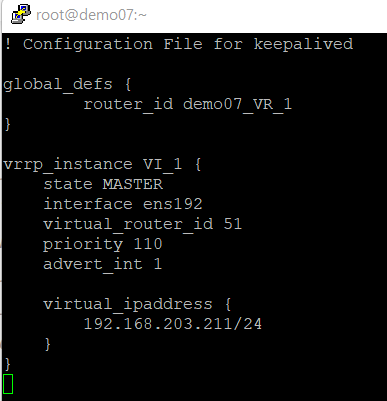
! Configuration File for keepalived
global_defs {
router_id demo07_VR_1
}
vrrp_instance VI_1 {
state MASTER
interface ens192
virtual_router_id 51
priority 110
advert_int 1
virtual_ipaddress {
192.168.203.211/24
}
}
ip a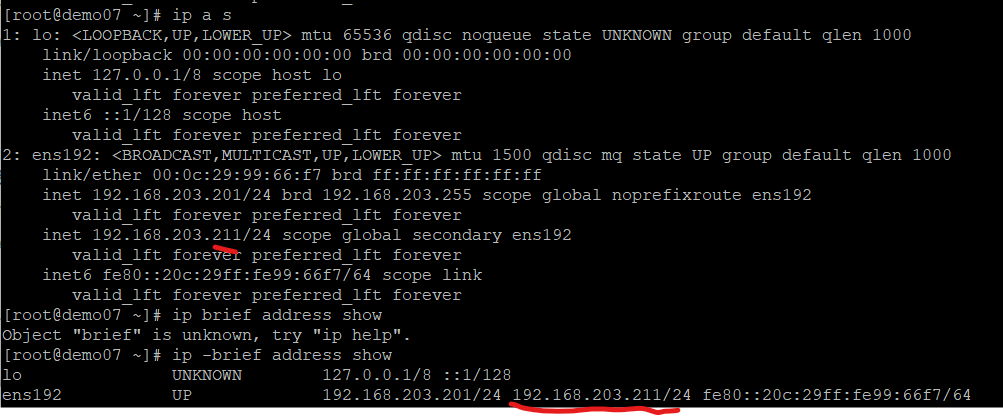
VIP로 192.168.203.211 이 생긴 것을볼 수 있다.
demo08
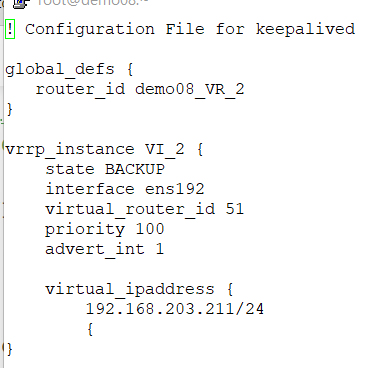
! Configuration File for keepalived
global_defs {
router_id demo08_VR_2
}
vrrp_instance VI_2 {
state BACKUP
interface ens192
virtual_router_id 51
priority 100
advert_int 1
virtual_ipaddress {
192.168.203.211/24
{
}
Haproxy(1.5.18)
Haproxy란 TCP와 HTTP로 리버스 프록시,로드밸런싱해주는 고가용성 오픈소스 프로젝트로, C로 짜져있다고 한다.
Haproxy conf 설정
/etc/haproxy/haproxy.cnf
demo07
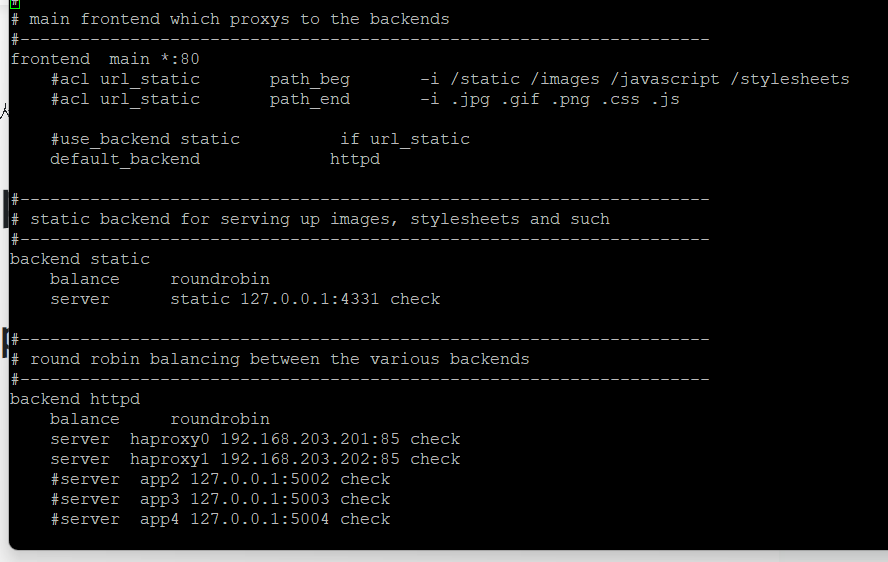
frontend main *:80
#acl url_static path_beg -i /static /images /javascript /stylesheets
#acl url_static path_end -i .jpg .gif .png .css .js
#use_backend static if url_static
default_backend httpd
#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend static
balance roundrobin
server static 127.0.0.1:4331 check
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend httpd
balance roundrobin
server haproxy0 192.168.203.201:85 check
server haproxy1 192.168.203.202:85 check
#server app2 127.0.0.1:5002 check
#server app3 127.0.0.1:5003 check
#server app4 127.0.0.1:5004 check
front로 80이 들어오면 backend 85번 포트로 내보대주는 설정이다
demo08
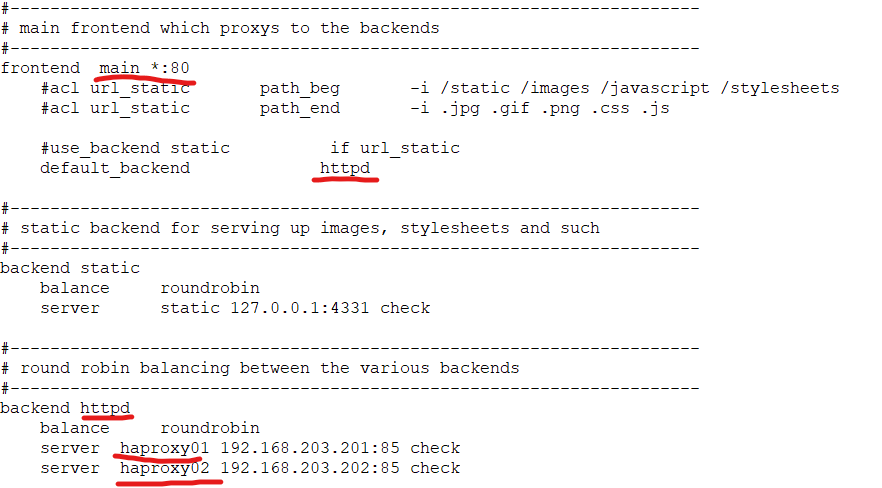
listen stats :81
mode http
log global
maxconn 10
stats enable
stats refresh 30s
stats uri /haproxy.stats
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main *:80
#acl url_static path_beg -i /static /images /javascript /stylesheets
#acl url_static path_end -i .jpg .gif .png .css .js
#use_backend static if url_static
default_backend httpd
#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend static
balance roundrobin
server static 127.0.0.1:4331 check
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend httpd
balance roundrobin
server haproxy01 192.168.203.201:85 check
server haproxy02 192.168.203.202:85 check
VIP 테스트
keepalived 에러 - slave config 간격문제
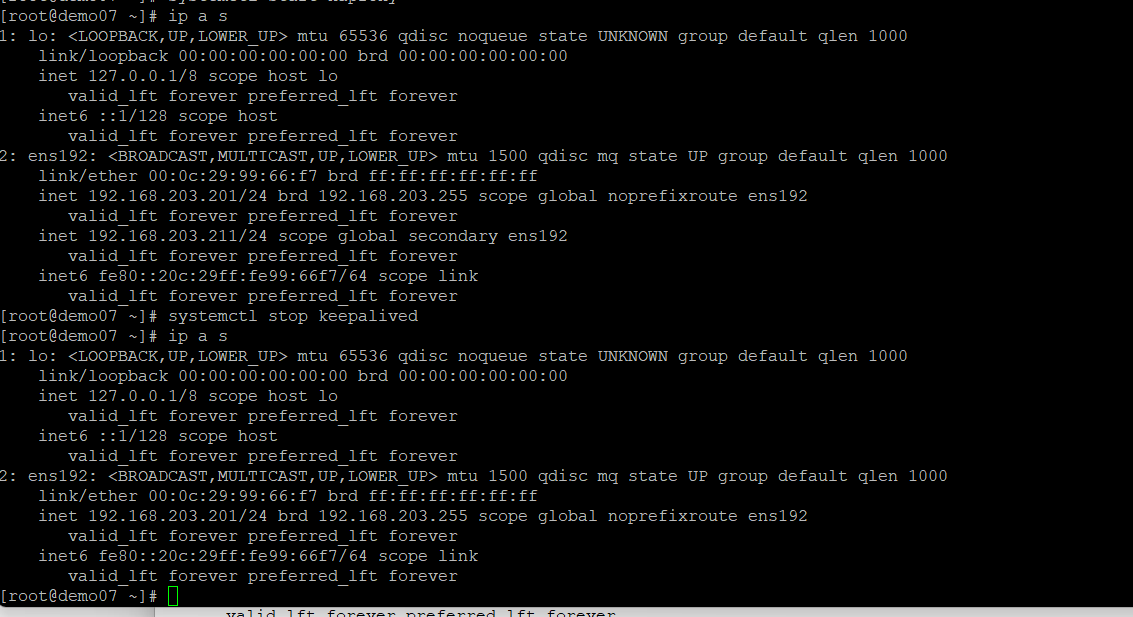
하는 도중에 에러가 났다.
11시 반
vip가 master에는 생성이 되는데
status에는 master 죽일시에 ip가 뜨지 않고 있다.
양쪽 다 작동은 정상적이나
log 파일을 보기위해서 keepalive 설정을 통해 로깅을 시켜주어야 확인이 가능할것 같다.
로깅 설정할 시간이 안되어서 수정하였다.
해결
demo 07, demo 08의 keepalived config
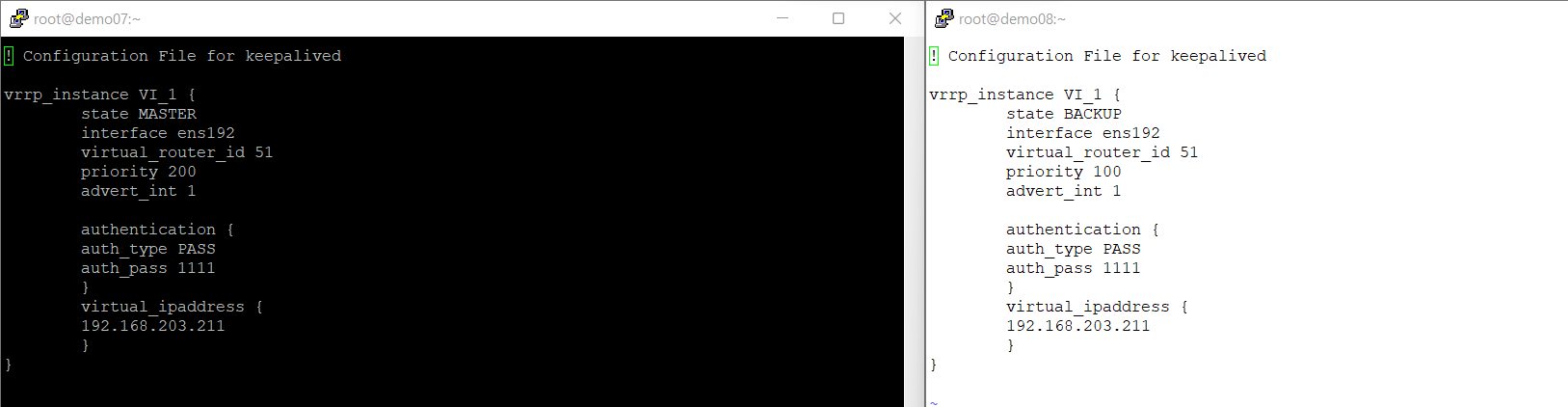
양쪽 config 파일중 demo08에 대한 keepalivd conf가 간격이 맞지 않아서 잘 작동하지 않았다.
테스트
VIP - 192.168.203.211
demo07에서 08로 ip 넘어가는것 확인
demo07,08 모두 running 상태이다.
demo07,08


demo07 대상으로
systemctl stop keepalivedkeepalived를 죽였을때
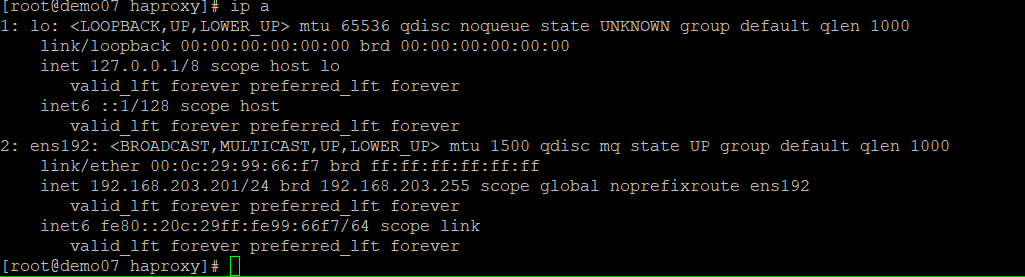
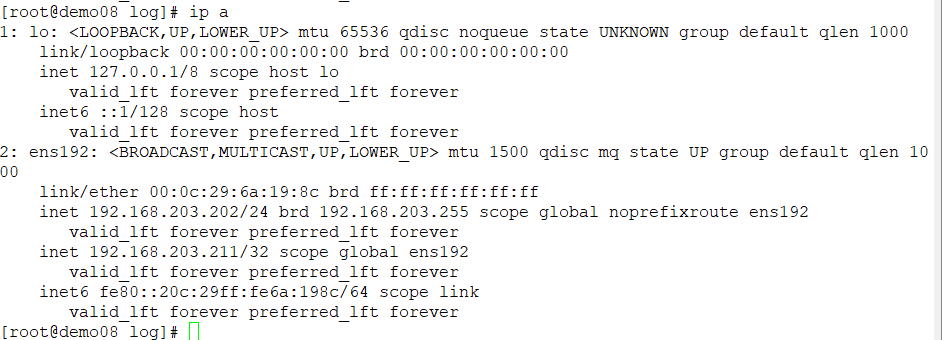
vip가 demo07에서 demo08로 넘어간 것 을 볼 수있다.
