2021115030 노어노문학과 한정화
데이터사이언스개론 태스크 (1) 4번 답안
- 개요
파라미터수는

사이에서,
learning rate는
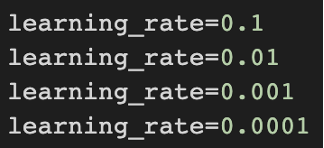
사이에서 변화시키며 총 24번 training loop를 돌려보았다. 이를 통해 accuracy와 model complexity의 관계, loss와 learning rate의 관계에 관한 유의미한 결과를 확인 할 수 있었다. 또한, accuracy와 loss 사이에는 관계가 없다는 것을 확인할 수 있었다.
1. accuracy와 model complexity
첫째, model complexity가 높으면 test accuracy가 오히려 낮아질 수 있다. 이번 태스크의 경우, model complexity는 parameter의 개수가 많아짐에 따라 결정되었다. parameter가 필요 이상으로 많으면, 모델이 높은 variance를 갖게 되고, 높은 variance는 모델이 민감하기 때문에 데이터에 대한 예측값들 사이의 편차가 크다는 의미가 된다. 예측값들 사이의 편차가 크다는 것은 training 데이터에 overfitting 했다는 의미로, 새로운 데이터셋(test dataset)에 대해서는 부정확한 예측을 하게 된다. 따라서 test accuracy는 낮아지게 된다. 나의 경우에도 실제로 parameter 수가 많아질 수록 test accuracy가 더 이상 늘지 않거나, 오히려 낮아지는 경우를 발견하게 되었다.
- learning rate=0.001에 대하여

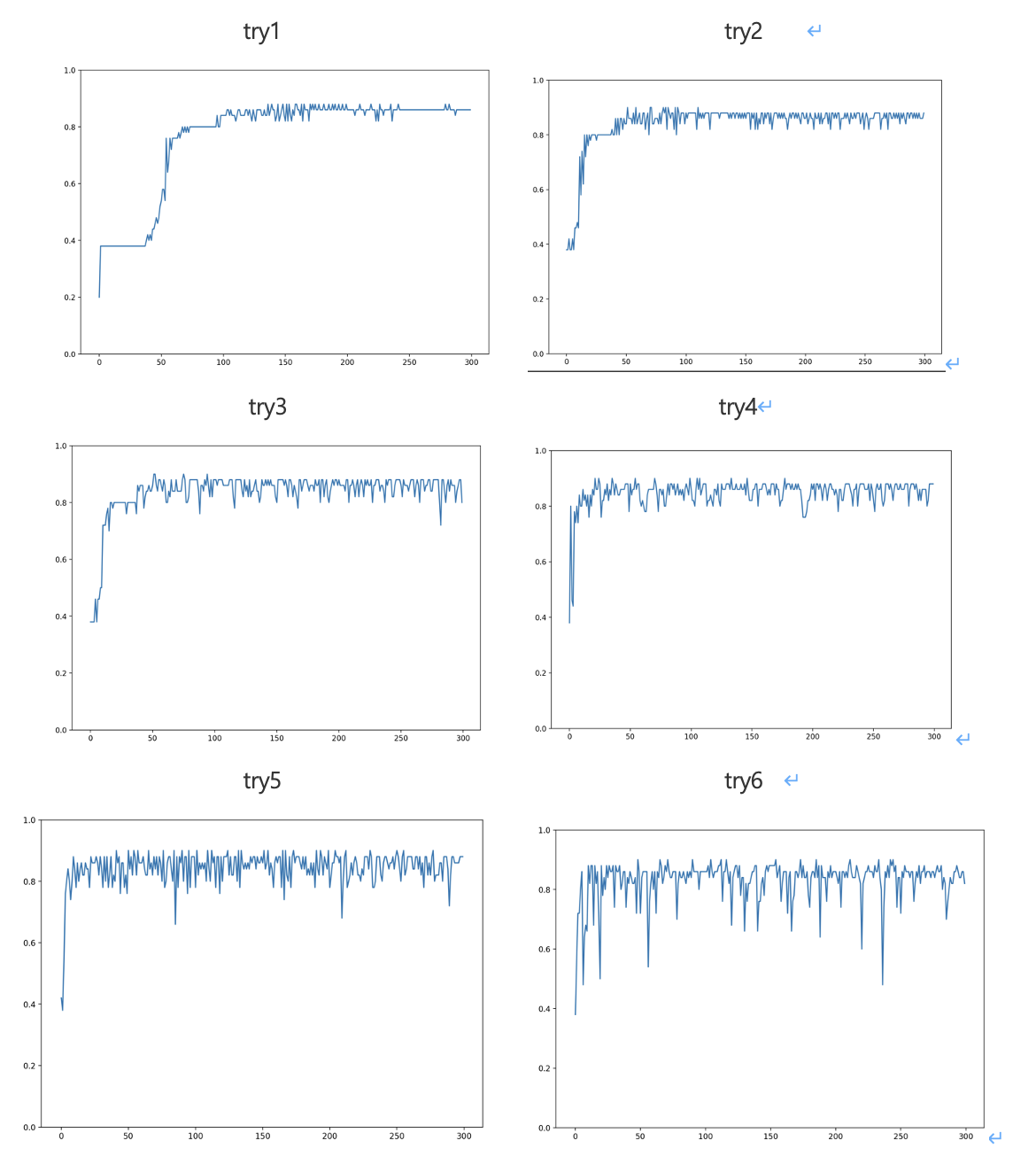
- learning rate=0.01에 대하여

2. loss와 learning rate
둘째, learning rate가 지나치게 작거나 지나치게 높으면 loss가 더 커질 수 있다. learning rate가 너무 낮으면, loss를 최소화하기 위한 parameter를 찾을 때 변화하는 step이 작다는 의미이므로, 최적의 paramenter를 찾는 데에 오랜 시간이 걸린다. 따라서 300 epoch가 끝나기 전에 loss의 최저점까지 도달하지 못할 수도 있다.
나의 경우 learning rate가 0.01 정도일 때 최대 loss 0.219를 제외하고는 모두 0.17~0.18 정도로 loss가 작았던 반면, learning rate가 0.0001일 때 최대 loss는 0.85 정도로 매우 컸고, 나머지 경우에서도 전부 0.2 미만의 loss까지 도달하지 못했다.

learning rate가 낮으면 최적의 parameter까지 도달하는 시간이 오래 걸린다는 이론이 옳은지 확인하기 위해, learning rate 0.0001에 대하여 epoch를 400으로 늘려보았다. 그러자 대부분의 경우에서 loss가 서서히 감소하는 것을 확인할 수 있었다.

반대로 learning rate가 지나치게 높으면, step size가 너무 커서 loss가 무질서하게 튕기게 되고, 이전 epoch보다 오히려 커질 수도 있다. 나의 경우 learning rate를 0.1로 하자, learning rate가 0.01때보다 모든 경우에서 loss가 커졌다. 최대 loss는 1.018이었다.

3. accuracy와 loss
마지막으로, loss와 accuracy에는 특별한 관계가 없음을 확인할 수 있었다. 일반적으로 loss는 작을수록, accuracy는 클수록 좋은 것이므로 둘 사이에는 반비례 관계가 성립한다고 생각할 수도 있다. 하지만, 나의 경우 accuracy가 높아졌는데 loss도 커진 경우, loss가 감소했는데 accuracy도 낮아진 경우 모두 존재하였다.
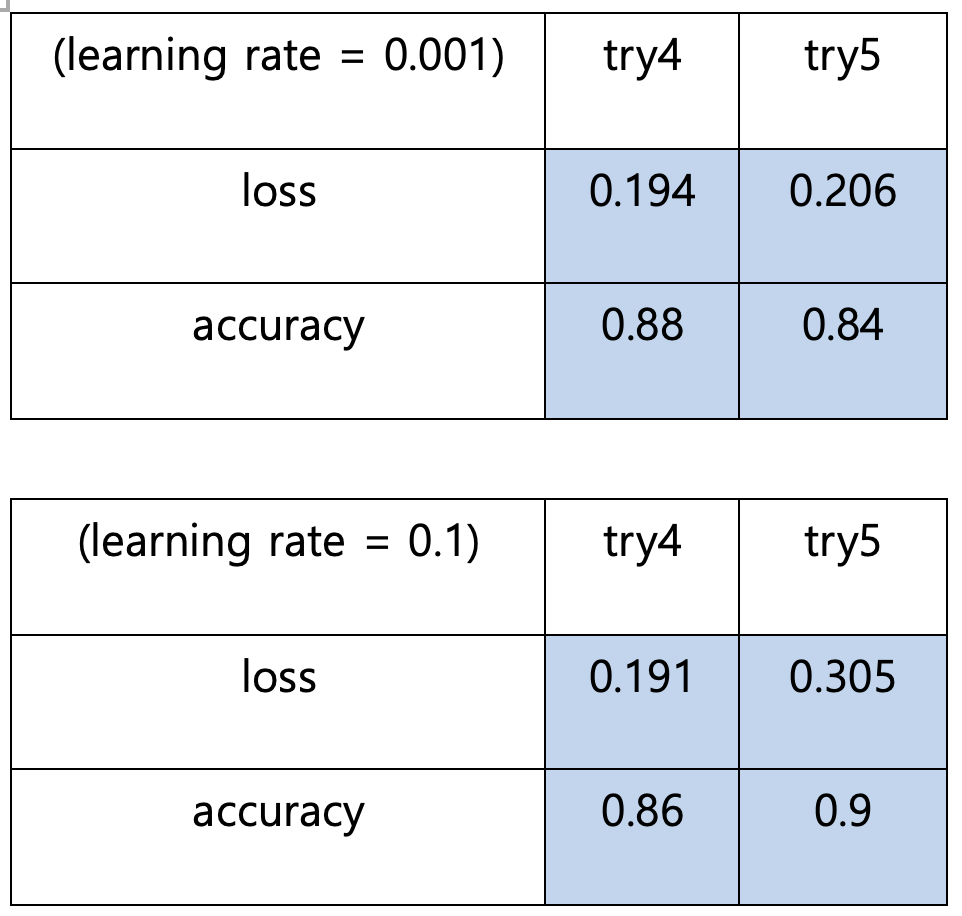
그 이유는 loss와 accuracy 사이에 큰 상관관계가 없기 때문일 것이다. accuracy는 예측을 잘못한 개수를 세는 것이고 loss는 모델이 예측한 값과 정답 사이의 차이 값의 합계이므로, 사실 수학적으로 연관 되어있지 않다. 예를 들어, A모델이 정답을 더 많이 맞혔지만, 틀린 경우에 대하여 예측값과 정답 사이의 차이가 훨씬 크고, B 모델이 정답은 더 많이 틀렸으나, 틀린 경우에 대하여 예측값과 정답 사이의 차이가 별로 크지 않다면 A가 B보다 accuracy도 높고 loss도 클 수 있는 것이다. 따라서 loss와 accuracy 간의 반비례 관계가 성립한다면 그것은 운이 좋은 것일 뿐이고, 그 관계가 항상 성립하는 것은 아니라는 것을 알 수 있었다.
