#230213 월
머신러닝 공부하고 싶은데요.. 전 안 될 것 같아요. 이제 시작하기엔 너무 늦지 않았나요?
라는 말만 500번째 하는 중인데 맨날 미련이나 가지느니 일단 시작이라도 해보자 싶어가지고 한 번 사봤다. 어차피 내 인생 개발자로 가느냐 쿨하게 실력 부족 인정하고 러시아어로 튀거나 둘 중 하나인 것 같은데 망할 거면 시작이라도 해보고 망하는 게 낫겠죠?
이것저것 벌려 놓은 일이 많으니 몰아서 읽으라고 해봤자 못해낼 것 같고 매일 한 챕터씩 꾸준히 읽는 것을 목표로 하기로 했다.
1) 딥러닝을 소개합니다 : 머신러닝 기본 용어
2) 최소한의 도구로 시작합니다~ : 코랩, 넘파이, 맷플롯립 기초
1. 딥러닝을 소개합니다~
1) 머신 러닝의 기본 용어
인공지능 : 특정 영역에서 사람의 지능처럼 작업을 수행하는 시스템이나 프로그램
머신러닝 : 기계학습
딥러닝 : 인공신경망 알고리즘을 사용하는 기계학습
학습과 훈련 : 데이터의 규칙을 컴퓨터가 스스로 찾아내고 수정하는 것
- 지도 학습 : 입력과 타깃으로 구성된 훈련 데이터로 학습함
입력에 대한 타깃(일종의 정답)이 주어져있기 때문에 지도 학습이라고 함 - 비지도 학습 : 타깃이 없는 훈련 데이터로 학습함
ex) 군집 분석(clustering) - 대상을 분류하기 위한 기준이 정해진 바가 없는 상태에서 특성을 분석하고 분류해 군집 내의 유사성과 군집 간의 상이성을 밝혀내는 것
모델 : 훈련을 통해 하급된 머신러닝 알고리즘. 새로운 입력에 대한 답을 예측할 수 있다.
에이전트 : 강화학습에서 훈련되는 프로그램. 에이전트는 수행에 따라 주어지는 보상을 바탕으로 최대한 많은 보상을 받기 위해 또 수행한다. 학습을 마친 에이전트를 모델이라고 볼 수도 있겠다. 하지만 에이전트라는 말보다 모델이라는 말을 주로 쓰는 것 같다.
규칙 : 모델 파라미터. 가중치와 절편으로 이루어져있다. 입력 데이터에 얼마를 곱하고(가중치) 얼마를 더해야(절편) 타깃을 얻을 수 있는지 알고리즘은 학습 과정에서 알게 된다. 알고리즘은 스스로 가중치와 절편을 수정하며 값을 찾기 때문에 인간은 파라미터를 수정할 수 없다.
손실 함수 : 학습 과정에서 모델의 예측값과 타깃값이 얼마나 다른지를 계산하는 함수이다. 즉, 모델이 찾은 규칙(가중치와 절편)을 얼마나 수정해야 하느냐는 것이다.
최적화 알고리즘 : 손실 함수의 최솟값을 효율적으로 찾는 방법
2) 딥러닝
머신 러닝 알고리즘에는 선형 회귀, 로지스틱 회귀, 인공신경망 알고리즘 등 다양한 알고리즘이 있다. 딥러닝은 이 중에서 인공신경망 알고리즘을 여러 겹 쌓은(?) 알고리즘이다. 그래서 엄밀히 말하면 둘은 다른 거지만, 딥러닝이 인공신경망 알고리즘을 사용해 만들기 때문에 나같은 응애 난이도에서는 거의 구분되지 않는 것 같다. (책에서도 그렇다고 말했다)
딥러닝은 머신러닝의 한 종류이지만, 둘이 가장 대표적으로 다뤄진다는 느낌을 받는 이유는 실제로 그것이 맞기 때문이다. 다른 머신 러닝에서 처리하기 어려운 데이터들 중 딥러닝이 더 잘 처리하는 경우가 있다.
| 딥러닝 | 머신러닝 | |
|---|---|---|
| 데이터 형태 | 비정형 데이터 | 정형 데이터 |
| 데이터 종류 | 이미지, 영상, 소리, 텍스트 | 엑셀, 데이터베이스, 레코드파일 |
| 예시 | 번역 | 환자의 검진 데이터, 매출 데이터와 관련된 문제들 |
비정형 데이터는 데이터에 정해진 규칙이 없어 값의 의미를 쉽게 파악하기 어려운 데이터이고, 정형데이터는 값의 의미를 쉽게 파악할 수 있는 데이터이다.
2. 최소한의 도구로 시작합니다~
1) Google Colab
우리가 쓸 최소한의 도구 첫 번째는? 바로바로 코랩입니다~
구글 코랩.. 써보기야 당연히 써봤다. 그것도 안 써보고 저 머신러닝 공부해보고 싶습니다. 할 만큼 바보천치는 아닙니다. 하지만 교수님이 쓰라고 하셔서 그냥 넵! 하고 쓴 거지(대충 나의 7년차 친구 그램 같은 놈에게도 서버를 제공해주는 어떤 좋은 곳..이라고만 추측해왔다) 뭔 진 잘 모르므로 열심히 읽어봤다.
코랩은 구글이 제공하는 주피터 노트북이다. 주피터 노트북은 브라우저에서 파이썬을 실행해 볼 수 있는 도구이다(이 정도는 안다). 코랩을 사용하면 우리는 브라우저에서 파이썬 코드를 작성하고, 코드는 구글 클라우드의 가상 서버에서 실행된다. 그래서 노트북 성능이 구려도 된다(?). 코랩에서 저장한 코드 파일은 구글 드라이브에 저장된다.
코랩에서 새 노트북을 열면 텍스트 셀을 수정할 수 있다.

예전에는 그냥 교수님이 주로 저렇게 쓰시길래 저렇게 썼는데, 이젠 벨로그를 시작하면서 마크다운 언어가 뭔지 알게 됐기 때문에 다 이해할 수 있다~ 우와 성장했다!
2) NumPy
넘파이는 파이썬의 과학 패키지이다. 넘파이도 당연히 뭔지 알지만 파이썬 안 쓴지 오래돼서 다 잊어버렸기 때문에 그냥 책에서 시키는 대로 다 했다.
- 배열 만들기
파이썬 리스트로 만든 배열은 크기가 커질수록 성능이 떨어진다는 단점이 있는 반면, 넘파이는 저수준 언어로 다차원 배열을 구현했기 때문에 크기가 커져도 성능은 높다.
// 파이썬 리스트로 2차원 배열
lst = [[10, 20, 30], [40, 50, 60]]
print(lst[1][2])
//실행 결과
60// 넘파이로 2차원 배열
import numpy as np
lst = np.array([[10, 20, 30], [40, 50, 60]])
print(lst)
//실행결과
[[10 20 30]
[40 50 60]]넘파이로 배열 출력하면 행, 열 맞춰져 있는 거 넘나 기특한 것
- 넘파이 내장 함수 sum
//파이썬 리스트로 2차원 배열의 모든 원소의 합 출력하기
sum = 0;
for i in range(2) :
for j in range(3) :
sum+= list[i][j]
print(sum)
//출력 결과
210//넘파이의 내장 함수 sum
np.sum(lst)
//출력 결과
210 음~ 너무 심플해
3) Matplotlib
맷플롯립은 파이썬 표준 그래프 패키지이다.
- 선 그래프
[1,2,3,4,5]가 x축 값이고, [1,4,9,16,25]가 y축 값이다.import matplotlib.pyplot as plt plt.plot([1,2,3,4,5], [0, 1, 2, 8, 9]) plt.show()
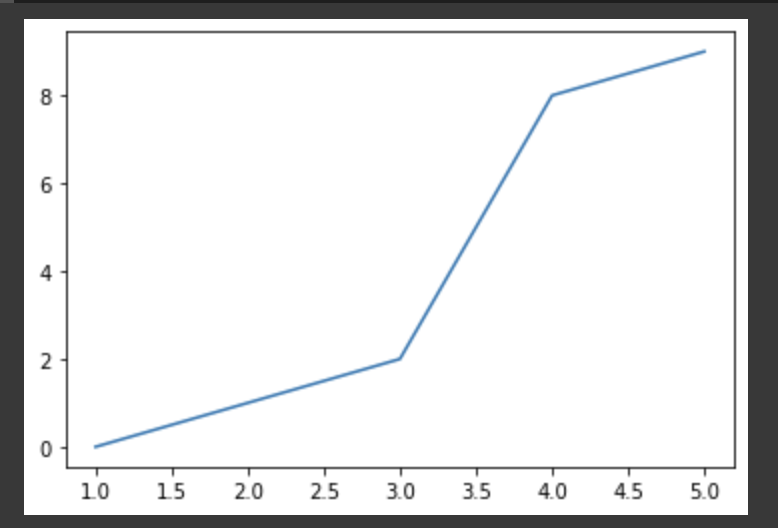
- 산점도 그리기
plt.scatter([1,2,3,4,5], [0, 1, 2, 8, 9]) plt.show()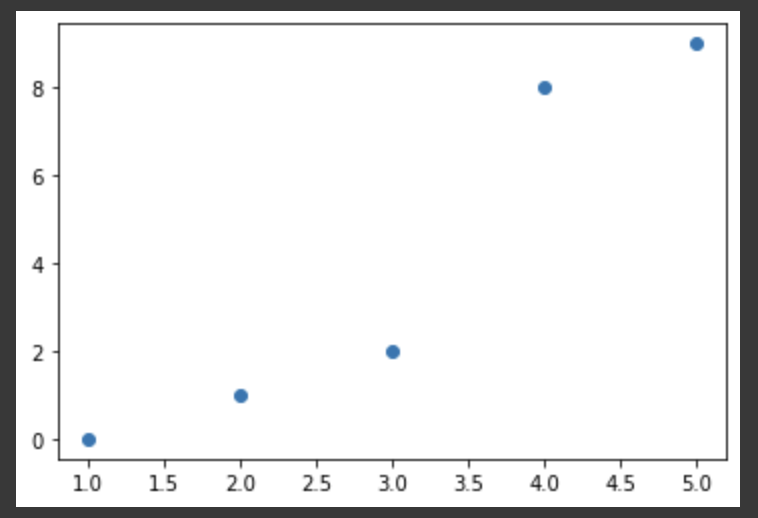
- 넘파이로 산점도 그리기
x = np.random.randn(5) y = np.random.randn(5) plt.scatter(x, y) plt.show()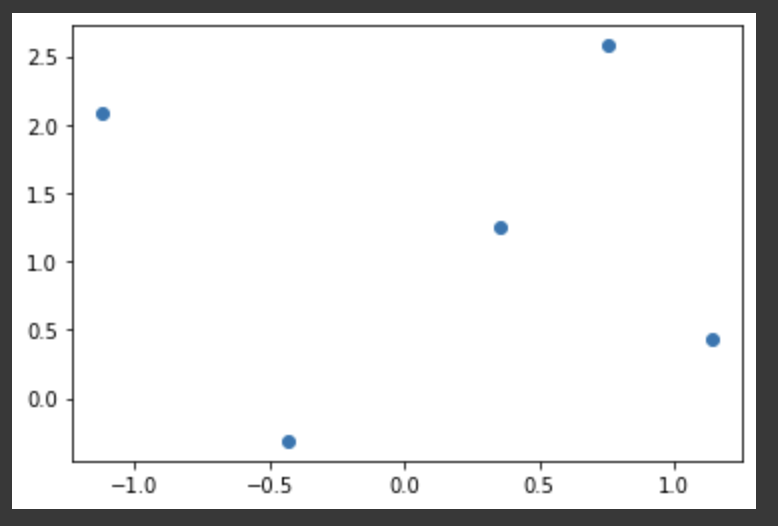
출처 : 정직하게 코딩하며 배우는 딥러닝 입문 DO it!
