#230210 금~#230211 토
Hugging face를 공부하다보면 교환 가서 영어로 공부할 것을 미리 연습하는 기분이 든다. 아무래도 딥러닝에 대해 조금이라도 아는 게 있으면 문맥 보고 단어의 뜻을 알 수 있을 것 같은데 하나도 아는 게 없으니 일일이 찾아보게 된다. 설명은 친절하게 떠먹여주는데 내가 다 뱉는 느낌으로다가,, 예를 들어 본문에 checkpoint가 나왔을 때 '체크 포인트가 체크 포인트지 뭐 별 게 더 있나..' 하다가도 괜히 잘 이해가 안 가서 찾아보니 모델이 training에서 사용한 모든 매개변수의 집합이라고 하고, 그럼 또 나는 '오메! ..매개변수는 뭐죠?' 하고 있는 것이다(물론 매개변수 자체가 무슨 뜻인지 정도는 안다.. 정화 바보 아니다) 고작 한 문장 읽는데 끝없이 이어지는 서치ㅎ
네 제가 뉴비입니다
하여튼 오늘도 힘내본다.. 오늘 DP도 하고(꼬박 5시간을 했다 젠장) 유니티도 하고 허깅코스도 하니 다 끝나면 구구덕해야지~ 결말 : 허깅코스도 못하고 구구덕도 못함 그래서 결국 토요일로 넘어왔다..ㅋ~
0. chapter 1 복습
챕터 1에서는 transformer의 파이프라인 함수(데이터 처리와 분류에 사용되는 함수)의 종류와, transformer의 기본적인 architecture에 대해 알 수 있었다. 챕터 2에서는 pretraining된 모델을 transformer를 사용해 전이학습시킬 우리가 알아야할 내용들에 대해 배운다. 파이프라인 함수가 작동하는 원리라던가,
1. 파이프라인 함수의 작동 과정
파이프라인 함수를 사용하면 함수의 input(평문)은 크게 세 가지 과정을 지나가게 된다.
- 전처리 preprocessing
- transformer 모델 통과 passing inputs through model
- 후처리 postprocessing
후처리까지 지나면 우리는 input 텍스트에 대한 파이프라인 함수의 outputs를 얻을 수 있다. 예를 들어, 챕터 1에서 살펴본 zero-shot classification를 이용할 때
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier("I love you") 에서 [positive, score : 0.9590389..]라는 outputs를 얻기까지 위 세 과정이 필요하다는 것이다. 그 세 과정을 도표로 표현하면 다음과 같다.
1) 전처리 (평문->IDs)
transformer 모델은 평문을 바로 해석할 수는 없다. 따라서 전처리 과정에서 평문을 수로 구성된 ID로 바꿔주어야한다. 이때 tokenizer가 사용된다. tokenizer는
- 평문 input을 token(단어, 서브워드, 심볼)으로 구분하고
- 각 token을 정수로 반환해주며
- 유용한 입력이 있다면 추가로 입력
한다. 서브워드는 단어의 뜻을 이루는 요소들을 말하는 건데, 한국어로 예를 들면 춤추기는 '춤추(다)'와 '(~하)기', 두 서브워드로 구분할 수 있다. 그러면 기초, 등급, 학교는 모두 서브워드가 된다. 심볼은 구두점, 느낌표, 반점 등의 기호를 의미한다. 단어, 서브워드, 심볼은 모두 tokenizer에 의해 token으로 인식되어 각각 정수 ID로 반환된다.
그런데 이러한 전이학습의 전처리 과정은 우리가 쓰려는 모델이 pretrained 될 때의 전처리 과정과 똑같아야한다. 따라서 transformer에는 pretraining 모델의 tokenizer를 가져오는 기능이 존재한다. autotokenizer 함수이다.
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)autotokenizer 함수는 pretrained 모델의 체크포인트 이름을 인자로 넘겨주면 tokenizer와 관련된 데이터들을 찾아 저장한다. 이때 체크포인트란 모델이 training에서 사용한 매개변수의 집합이다. 매개변수란 모델이 학습되는 과정에서 내면적으로 결정되는 변수들로, 사용자가 마음대로 조정할 수 없다. 딥러닝에서 매개변수는 주로 가중치이다.
어쨌든 이렇게 정수 ID들의 list를 얻고 나면 tensor로 반환하는 과정이 필요하다. Transformer 모델은 tensor 형식만 인식할 수 있기 때문이다. tensor 또한 배열 타입이지만 일반 list와는 다르다. tensor로 변환하면 전처리 과정이 끝이 난다. 이 과정에서는 pytorch나 tensorflow가 활용된다. 내가 듣는 세미나는 pytorch로 쓰니까 pytorch의 tensor 변환 함수를 사용하게 될 것 이다. 나는 pytorch를 잘 몰라서 일단 코드는 패스~
2) transformer 모델 통과
우선 tensor를 transformer 모델에 통과시키려면 1)에서 tokenizer를 가져온 것처럼 pretraining 모델도 가져와야한다.
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)이 함수는 pretraining model의 checkpoint를 바탕으로 사용할 모델을 인스턴스화한다. 이렇게 인스턴스화된 모델들은 다음 사진과 같은 transformer 모델의 인풋이 된다. (model input)
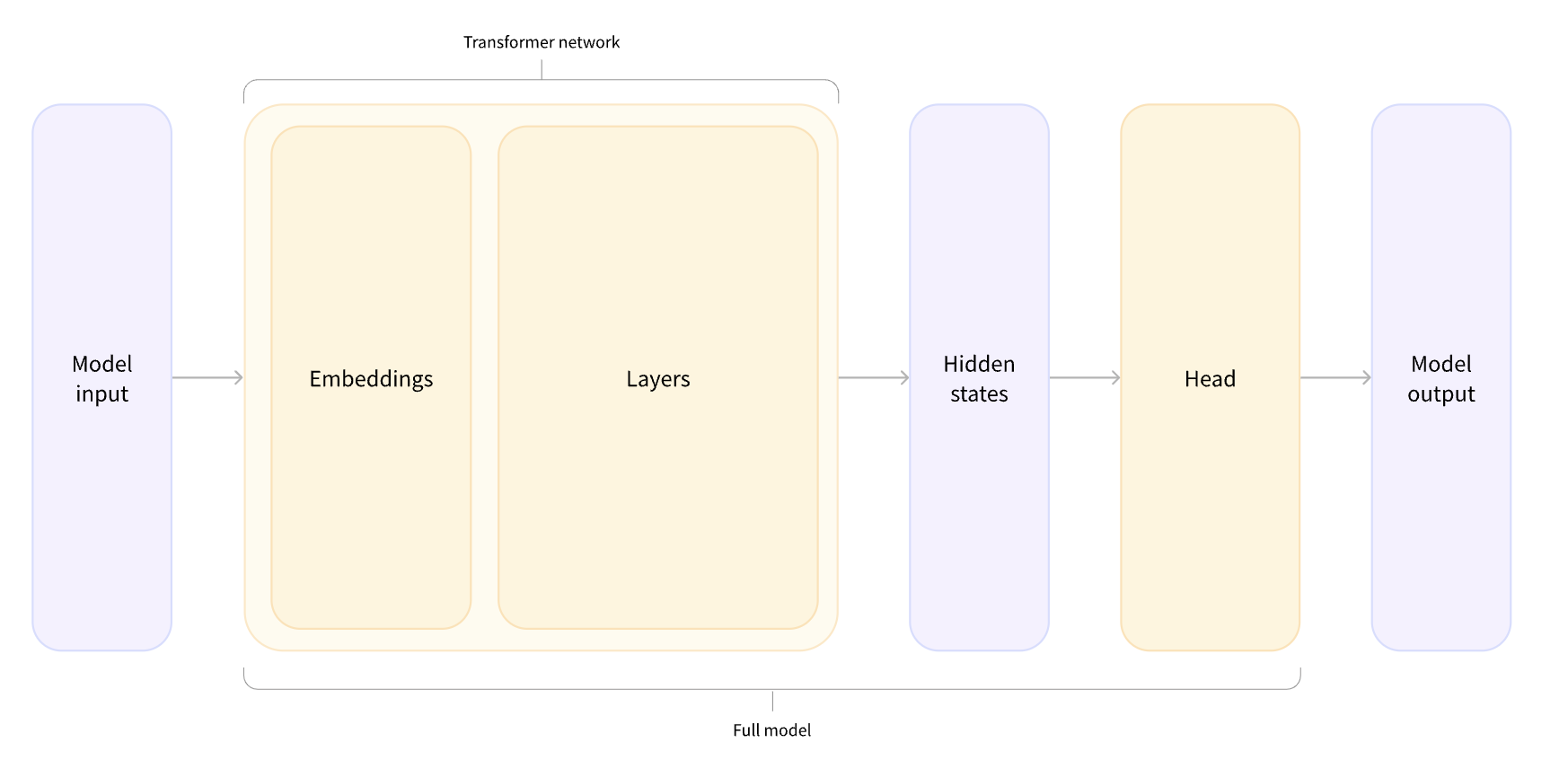
그러면 transformer 모델 각 구조에 대해 순서대로 알아보자.
우선 Embedding 층에서는 1)에서 만든 ID tensor들을 vector로 만든다. 이 벡터는 주로 3차원으로 되어있다.
- batch size (한 번에 인식할 시퀀스의 개수를 배치 사이즈라고 한다)
- 시퀀스 ID의 길이
- hidden size (각 인풋 모델 vector의 차원, 이 hidden size가 hidden states 벡터의 사이즈를 를 결정한다. hidden states는 feature라고 주로 불리며, 예측에 필요한 데이터의 특징들을 의미한다.)
Embedding 다음으로 보이는 Layers는 vector에 attention 매커니즘을 적용해주는 층이다.
transformer 모델의 head는 선형계층을 여러 개 가지고 있다. head는 hidden states를 갖고 있는 vector를 인풋으로 받고, vector는 head의 선형계층을 통과하며 다른 차원을 가진 vector로 변환된다.
이러한 과정을 통해 model은 최종적으로 필요한 차원의 vector를 얻게 되며, 이를 logits이라고 한다.
3) 후처리
2)에서 반환된 logits는 우리가 원하는 결과물을 가지고 있지만, 우리에게 필요한 형태는 아니다.
예를 들어, 문장 classification에서 우리는 입력된 두 문장에 대해
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
)다음과 같은 예측(결과)을 얻고 싶다.
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
First sentence: NEGATIVE: 0.0402, POSITIVE: 0.9598
Second sentence: NEGATIVE: 0.9995, POSITIVE: 0.0005
하지만 후처리가 되지 않은 logits들을 출력해보면
print(outputs.logits)다음과 같은 형태로 출력된다.
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)후처리 과정에서는 softmax layer를 통해 logits을 prediction(우리의 최종 목표)로 바꿔준다.
softmax 함수를 사용하면
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)다음과 같은 결과가 나온다.
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)여기에 negative label을 인덱스 0, positive lael을 인덱스 1로 적용시켜주면 원했던 결과물
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
First sentence: NEGATIVE: 0.0402, POSITIVE: 0.9598
Second sentence: NEGATIVE: 0.9995, POSITIVE: 0.0005
을 얻을 수 있을 것이다.
2. pretraining 모델 사용하기
1.파이프라인 함수의 작동 과정 을 내용 정리 할 때, 2)모델 통과 에서 'pretraining 모델'을 가져와서 'transformer 모델에 인풋으로 넣어줄 모델'들로 인스턴스화하는 과정 이 좀 추상적이라서 이해가 잘 안 갔다. 이번에는 그 내용을 BERT 모델을 바탕으로 좀 더 구체적으로 살펴보자.
1) BERT의 configuration 객체 가져오기
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)가져온 configuration은 모델을 만드는데 필요한 여러 요소들을 가지고 있다. print(config)해보면
BertConfig {
[...]
"hidden_size": 768,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
[...]
}다음과 같은 요소들을 살펴볼 수 있다. (너무 많아서 사이트에도 축약되어 있다..ㅋㅋ) hidden size는 1.2)에서 살펴본 feature 벡터의 차원(사이즈)이다.
2) configuration을 바탕으로 모델 생성하고 랜덤값으로 초기화
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)3) pretraining 모델 가져오기
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
이는 1.에서 언급하였든 checkpoint를 가져오기 위함이다.
4) 모델 저장
model.save_pretrained("directory_on_my_computer")저장하면 두 개의 파일을 얻게 되는데,
ls directory_on_my_computer
config.json pytorch_model.binconfig.json은 모델의 architecture를 알 수 있고, pytorch_model.bin에서는 모델의 매개변수(가중치)를 알 수 있다.
5) 모델을 가져왔으니 1.1)에서 살펴본 것처럼 이제 tokenizer가 평문을 ID로 인코딩한다.
만약 인코딩 결과값이 궁금하면 출력해볼 수도 있다.
sequences = ["Hello!", "Cool.", "Nice!"]에 대해 tokenizer는
encoded_sequences = [
[101, 7592, 999, 102],
[101, 4658, 1012, 102],
[101, 3835, 999, 102],
]이와 같은 ID를 반환한다.
하지만 1.1)에서 말했듯 transformer 모델은 tensor 형식만 input으로 받을 수 있다. 따라서 array를 torch로 바꿔준다.
import torch
model_inputs = torch.tensor(encoded_sequences)이제 이 tensor는 transformer 모델에 model input으로 들어가 1.2)의 과정을 거치게 될 것이다.
output = model(model_inputs)3. tokenizer
이번에는 tokenizer의 작동 원리를 좀 더 구체적으로 살펴보자. 1.1)과 2.5)에서 설명했듯 transformer 모델은 평문을 input으로 받을 수 없기 때문에 평문을 숫자 ID로 바꿔줘야하며, 이 역할을 tokenizer가 한다. 숫자 ID를 만들 때 막 만드는 것은 아니며, 당연히 단어들의 유의미한 특성들을 확인한 후 이를 ID로 만든다.
1) word-based tokenizer
이 타입의 tokenizer는 만들기도 쉽고, 결과도 매우 정확하게 나온다. 단어는 띄어쓰기와 punctuation 등으로 쉽게 구분되기 때문이다.
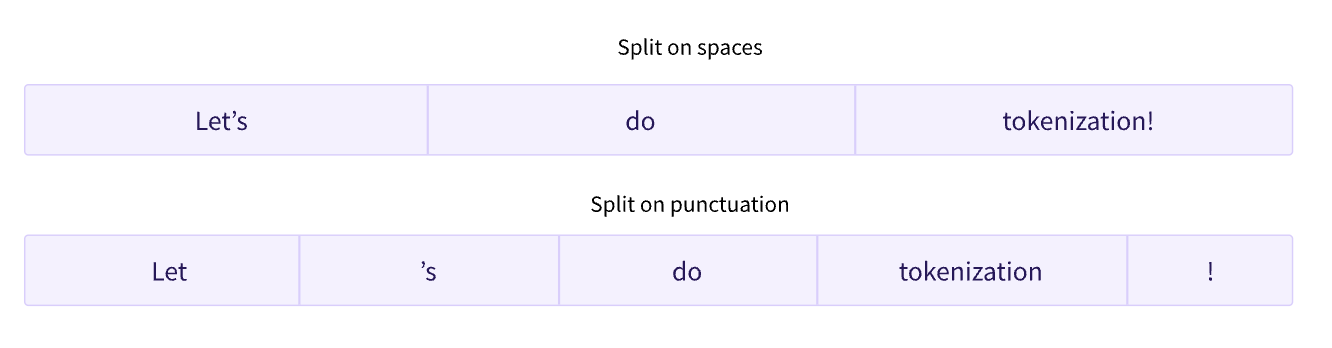
띄어쓰기로 구분하면 함수는 다음과 같이 쓸 수 있다.
tokenized_text = "Jim Henson was a puppeteer".split()
print(tokenized_text)결과물 ['Jim', 'Henson', 'was', 'a', 'puppeteer']에 대하여 tokenizer는 각각 숫자 ID 배열을 반환한다(map).
word-based tokenizer만으로는 한계가 있다. 우선 세상에는 수많은 단어가 있으므로, 각 단어를 관리할 식별자가 너무 많아진다. 또한, 'person'과 'people', 'book'과 'books'의 연관성을 모델이 인식하지 못할 것이라는 한계도 있다. 그리고 만약 tokenizer가 알지 못하는 단어가 평문에 포함되어있다면, 이 단어들은 unknown token으로 분류된다. tokenizer가 unknown token으로 분류하는 단어가 아주 적도록 하는 것이 중요하다,
2) character-based tokenizer
이 타입의 tokenizer는 word-based와 다르게
- 각 캐릭터를 관리할 식별자가 적으며(예를 들어 영어 단어는 수만 수억 개가 있지만 알파벳은 24개밖에 안 된다)
- unknown token으로 분류될 일이 거의 없다(대부분의 단어와 문장들은 character로 구성되기 때문이다)
는 장점을 가지고 있다.

character-based tokenizer는 글자 하나하나가 의미를 가지는 언어(예를 들어 한자, 중국어)에서는 의미가 크지만, 개별 알파벳에는 뜻이 부여되지 않는 언어(예를 들어 영어, 러시아어, 라틴어)들에서는 유의미한 tokenizer라고 할 수 없다.
또한, character로 분류하게 되면 (단어 하나가 token 하나가 되는 word-based와 달리) 단어 하나가 너무 많은 token을 갖는다는 단점을 가지고 있다.
그렇다면.. 어쩌라고?
뭘 어쩌긴 어째 원래 각각 장단점을 가진 메소드가 있으면 합치는 게 짱이다.
3) subword tokenization
1.1)에서 언급하였 듯이 subword는 어떤 단어를 구성하고 있는 유의미한 요소들을 의미한다. 예를 들어 춤추기는 '춤추(다)'와 '(~하)기'의 결합이다.
subword tokenization의 규칙은
자주 쓰이는 단어는 subword로 나누지 않고, 거의 쓰이지 않은 단어는 서브워드로 쪼갠다.
4) tokenizer를 불러오고 저장하기
1.1)에서 언급하였듯 어떤 모델에 tokenizer를 사용하려면 pretraining에서 사용했던 tokenizer를 불러와야한다. 두 개가 똑같이 작용해야 하기 때문이다.
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")혹은
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")를 사용할 수 있다.
이렇게 불러온 tokenizer를 1.1)과 2.5)에서처럼 사용해보면
tokenizer("Using a Transformer network is simple")다음과 같은 결과가 출력된다.
{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}input_ids는 tokenizer가 만든 숫자 ID들이다. token_type_ids나 attention_mask는 후에 더 다룬다고 하니 우선 넘어간다. (다 읽고 나서 정리 중인 게 아니라 읽으면서 정리 중이라 벨로그를 쓰고 있는 지금의 나도 아직 모른다..)
tokenizer를 저장하려면
tokenizer.save_pretrained("directory_on_my_computer")
로 저장할 수 있다.
<정리>
-입력 :
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
-출력 :
['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']-입력 :
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)-출력 :
[7993, 170, 11303, 1200, 2443, 1110, 3014]5) 이렇게 tokenizer가 숫자 ID로 인코딩한 token들은 다시 텍스트로 디코딩 할 수도 있다.
-입력 :
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)-출력 :
'Using a Transformer network is simple'3. 다중 시퀀스
multiple sequence가 정확하게 뭐라고 설명하긴 어렵지만, transformer 모델이 하나의 입력 평문에 대해서 두 개 이상의 입력을 인식했다는 의미이다. 예를 들어, "I've been waiting for a HuggingFace course my whole life." 라는 하나의 입력 평문에 대해서
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."다음을 실행해보면,
tokenized_inputs = tokenizer(sequence, return_tensors="pt")
print(tokenized_inputs["input_ids"])이와 같은 결과가 출력된다.
tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,
2607, 2026, 2878, 2166, 1012, 102]])자세히 보면 '['가 두 개씩 있다.
