#230208 수
익명 | 15:02
파이토치 모르고 Transformer 공부하러 가는 사람 어때? 호감 or 비호감인지 말해줘!
ㄴ익명 2 당연히 비호감 아님?
holy~
왜 그랬지? 요즘 들어 과제로 내주신 강의를 틀면 "~를 모르면 먼저 듣고 오세요"로 시작하는 경우가 많은 것 같다. 그리고 당연히 나는 ~이 뭔지 모른다. 하지만 일단 박치기 하고 보는 내 자신 ..너무 박치기를 해서 자고 일어날 때마다 두통이 있는 건가(아님) 모닝커피 없인 해결할 수 없는 내 두통 누가 들고 가~
1. Transformer란?
딥러닝을 이용한 NLP 모델 중 하나이다. 매우매우 유명하고 성능이 좋은, 을 곁들인 . . . 이번에 듣는 세미나는 Transformer를 이용해 파이썬 실습을 해보는 것이다. 그 이전에 Huggingface Course 사이트에서 공부를 해오라고 하셔서 정리해봤다.
2. Transformer의 Architecture
transformer를 이해하려면 우선 다음 친구들을 이해해야 한다.
-
pretraining과 fine-tuning :
pretraining은 사전 지식(?)이 없는 모델이 가중치를 랜덤하게 바꿔가며 학습하는 과정이다. 따라서 대형 데이터일 수록 학습이 잘 될 가능성이 높다. transformer의 pretraining는 평문(raw text, encode하지 않은 자연어 그대로의 텍스트)을 자기지도학습하는 과정이다. 자기지도학습하는 모델은 label(일종의 정답지..랄까?)을 인간이 정해주지 않고 스스로 분류하여 label을 만든다.
하지만 pretraining으로 만들어진 모델은 범용 모델(general pretrained language model)이므로, transformer를 활용하려는 개인의 목적에 맞게 dataset을 고르고 가중치를 좀 더 조정하며 training을 해야 최적화된 모델을 얻을 수 있다. 이 과정을 fine-tuning이라 하고, pretrained model을 이용해 두 번째 training에서는 더 쉽게 최적화를 이루도록 하는 방식을 transfer learning(전이학습)이라고 한다. -
encoder와 decoder : 딥러닝 모델에서 입력 시퀀스를 처리하는 부분을 encoder, 출력 시퀀스를 처리하는 부분을 decoder라고 한다. 시퀀스는 별 게 아니고 단어가 나열된(예를 들어 문장) 것이다. encoder는 input을 이해하는 데에 최적화되어있으므로, encoder-only model은 sentence classification(평서문, 감탄문..)이나 name entity recognition(개체 이름 인식)에 쓰인다. 출력 시퀀스를 관리할 필요 없이 입력 데이터만 이해하고 분류하면 되기 때문이다. decoder는 output을 생성하는 데에 최적화되어있으므로, decoder-only model은 text generation(문장 이어쓰기)에 쓰인다. encoder-decoder model은 번역이나 요약처럼 input sequenced와 output sequence를 모두 처리해야하는 경우에 쓰인다. 따라서 sequence to sequence라고도 불린다.
-
attention layer : 입력된 문장들에 대하여 어떤 특정 단어들에 attention을 둬야하는지 모델에게 알려주는 layer이다. (layer가.. model에게 말을 걸었다.. 여기에 집중하면 돼..! model이 답했다.. 고마워 친구..!) 모델이 집중해야할 단어들이라는 것은 주로 문맥에 따라 의미가 달라지거나 생성되는 단어들이다. 인코더와 디코더는 모두 이 attention layers를 가지고 있따. attention layer에 대해서는 추후에 다시 구체적으로 나온다고 했으니(내가 생각해도 1장부터 딥하게 다룰 간단한 내용은 아닐 것 같다) 우선 개념 정도만 이해하고 패스하기로 했다.
이 요소들을 바탕으로 transformer의 architecture를 간단하게 알아보자. transformer의 architecture는 기본적으로 번역을 위해 설계된 것이기 때문에 사이트서도 translation 과정을 예로 설명하고 있었다. 나는 지금 아무것도 모르는 상태에서 가르쳐주는 모든 것을 그대로 흡수하는 중이므로 이해한 그대로 정리해보겠다(나머지는 실습하면서 알게 되겠지..)
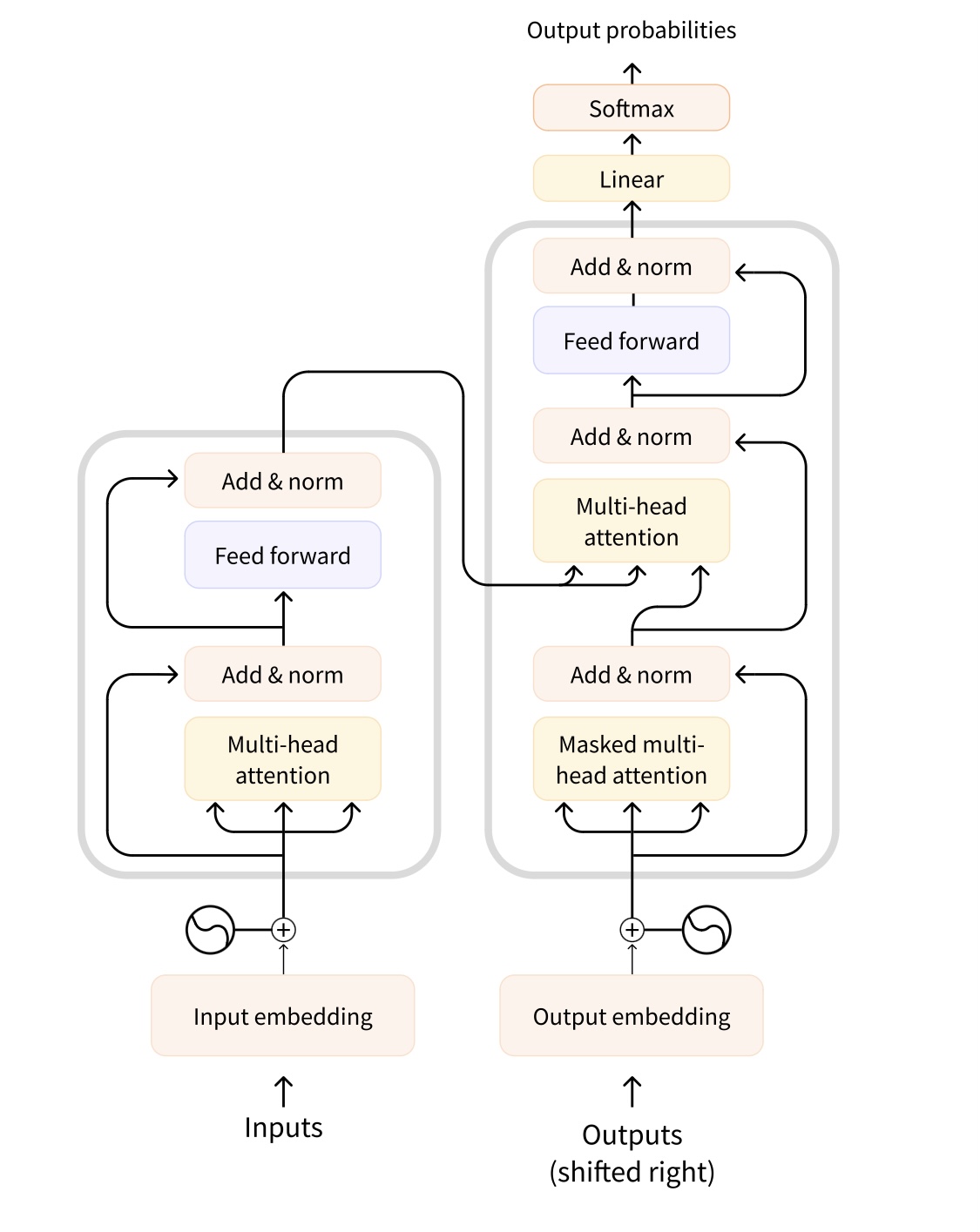
(사진 출처 : Course Documentation <How do Transformers work?>, Huggingface course)
인코더와 디코더는 여러 attention layers로 구성되어있다. training 과정에서 인코더의 attention layers는 입력 언어로 된 문장을 처리하는데, 문장의 각 단어들을 번역할 때 앞뒤의 다른 단어들을 모두 사용할 수 있다. 이렇게 하는 이유는 앞서 attention layer를 설명할 때 말했듯, 어떤 단어들은 다른 단어들과의 관계(문맥)에 따라 뜻이 달라지기 때문이다. 반대로, 디코더의 attention layers는 전체 target 문장들을 받아오는 첫 번째 attention layer 층을 제외하고는 인코더에서 번역한 결과물만 사용할 수 있다. 즉, 디코더가 처리하고 있는 단어보다 뒤에 나오는 단어들을 사용할 수 없으며, 앞에 나오는 단어들(인코더에 의해 이미 번역 처리가 끝난 단어들)만 활용해서 현재 단어의 의미를 예측할 수 있다. 그렇게 하는 이유는 training의 속도를 빠르게 하기 위함이다.
3. Encoder-only model
encoder-only model은 3.에서도 얘기하긴 했지만, architecture에서 양방향 얘기가 나오면서 추가로 덧붙일 내용이 생겼다. 3.에서 transformer의 인코더는 앞뒤로 있는 모든 단어를 이용해 현재 단어의 의미를 파악할 수 있다고 하였다. 따라서 encoder-only model은 bi-directional attention (양방향 처리) 방식을 이용한다고도 표현된다.
4. Decoder-only model
decoder-only model도 3.에서 얘기하긴 했지만 덧붙여보면, decoder model은 auto-regressive model(자기회귀 모델)이라고도 한다. 자기회귀는 과거의 변수값으로 현재를 예측하는 것이다. 3.에서 transformer의 디코더는 이미 번역된 단어들로만 현재 단어의 의미를 파악해 생성할 수 있다고 하였다. 따라서 decoder-only model은 자기회귀 모델이라고 할 수 있다.
5. Encoder-decoder models (sequence-to-sequence models)
encoder-only model과 decoder-only model의 합이다.. 1장에서는 명확한 설명보다는 말로 풀어쓰는 설명 위주라 뭐 더 말할 게 없다.
6. 한계(limitations)
huggingface에서 'bias and limitations'라는 말을 처음 봤을 때 bias가 weight & bias에서의 그 편향인 줄 알고 '편향과 한계'라는 부제로 적었다가 방금 지운 건 안 비밀..ㅎ
huggingface에 의하면 중립적인(neutral, 편견이나 사회적 통념을 최대한 배제한) 자료들을 바탕으로 데이터를 수집하였음에도 불구하고, 방대한 양의 데이터를 수집하는 과정에 의해 transformer가 생성한 결과물이 인종차별적, 성차별적, 성소수자 혐오적인 콘텐츠를 포함할 수도 있다고 한다. 그건 뭐.. 어쩔 수 없다. 인간이 나쁜 걸 어떡해요 (아바타 2 이후로 잊을 수 없는 인생 최고의 문장 : '인간이 나빴어..') fine-tuning 과정에서 잘 거르는 수밖에 없다.
7. pipeline() function란?
전처리(데이터를 모델 학습에 사용될 데이터 형태로 가공하는 과정)를 위해 데이터 처리 및 분류에 사용되는 유용한 함수이다.
1) zero-shot classification
zero-shot은 모델이 training 과정에서 학습하지 못한 작업을 수행하는 것이라고 한다. transformer에서 zero-shot classification란 pretrained 모델에서 label이 분류되지 않은 텍스트를 분류하는 것이다.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier("I love you") 를 실행하면 파이프라인 함수는 I love you에 사용될 만한 적절한 label과 정확도를 우리에게 반환해준다(ex- positive, score : 0.9590389..)
우리가 원하는 label를 적용해주고 싶다면 입력으로 넣어주는 것도 가능하다.
classifier("I love you", candidate_labels=["friend", "stranger", "earth"])를 실행하면 파이프라인 함수는 각 label과의 정확도(얼마나 연관이 있는지)를 출력해줄 것이다. (ex- 0.924, 0.1123, 0.435343)
2) Text generation
우리가 어떤 prompt를 입력하면 transformer 모델이 나머지 텍스트를 자동으로 완성해준다.
from transformers import pipeline
generator = pipeline("text-generation)
generator("I love watching") 3) Text completion (mask filling)
mask로 가려진(?) 문장이나 단어를 모델이 찾아 채워주는 것이다. 빈칸 채우기 같은 것이다.
unmasker = pipeline("fill-mask")
unmasker("I love watching <mask>.", top_k=3) top_k=2는 모델이 띄워주길 바라는 가능한 후보의 개수가 2개라는 의미이다. 예를 들어 모델은
[{'sequence': "I love watching movies.", 'score': 0.34556, 'token': 30562, 'token_str': 'movies'}, {sequence': "I love watching people fighting.", 'score': 0.10556, 'token': 34852, 'token_str': 'people fighting'}]를 출력해줄 수 있다.
4) Question answering
주어진 맥락에서 모델이 질문에 대한 답을 그 맥락 안에서 찾아 알려주는 것이다. 물론 입력으로 주어지는 맥락 안에 있는 단어들 중에서만 답을 찾을 수 있다.
question_answerer = pipeline('question-answering')
question answerer(
question = "Who I love?",
context = "There are lots of k-pop stars nowadays. Well, I love Jung Seunghwan.",)
그러면 모델은 정답과 정확도(그것이 정답일 확률), 입력 문자열에서의 정답 문자열의 처음과 끝 인덱스를 출력해서 알려줄 것이다. ex) {'score': 0.87395', 'start' : 51, 'end' : 64, 'answer' : 'Jung Seunghwan'}
5) Summarization
보자마자 뭐하는 친구인지 알겠어서 행복했던 친구이다-!
summarizer = pipeline("summarization")
summarizer(
"""
~~~~~
"""
) 모델은 입력된 텍스트에 대한 요약본 [{'summary_text' : '~~~~~~'}]을 출력할 것이다.
6) Translation
얘도 summarization처럼 뭐하는 친구인지 알겠어서 행복했긴 했는데 이걸 진짜 하는구나.. 싶어서 급 우울해짐 갑자기 냅다 현실 직시한 사람 됨. 인공지능은 나보다 러시아어를 잘한다.... 아니 GPT가 나보다 코딩 문제도 잘 풀고 transformer가 나보다 번역을 잘하는데 내가 뭣하러 프로그래밍 언어를 공부하고 러시아어를 공부하는가.. 미친 세상이야
translator = pipeline("translation", model="translation_kr_to_ru")
translator("안녕하세요 저는 멍청이입니다.") 를 모델에 입력하면 [{translation_text': 'Здравствуйте, я глуп!'}]를 출력해줄 것이다. 물론 모델은 다른 모델을 가져올 수도 있다.
끝!
내용 출처 : Huggingface Course <1. TRANSFORMER MODELS>
