gc : garbage collecter
Class class 선언의 의미
-
Circle class{}와 같은 특정 클래스에 대한 정보를 갖고 있는 class- 특정 클래스에 대한 정보
: Circle class와 같이class명,package명,field명,constructor명,method명등의 이름 정보를 갖고 있음.
- 특정 클래스에 대한 정보
-
Object class에
getClass()메소드 사용하기클래스 정보를 알고 싶은 특정 클래스에(이 방법은 비추함.)new로 인스턴스를 만든 후 사용하는 방법- Class class의 static method인
forName()을 사용함Class.forName("특정 패키지명 + 클래스명");형식
Action action;
String sendName = "p06.class_class_practice.SendAction";
String recvName = "p06.class_class_practice.ReceiveAction";
String name;
try {
// name = sendName;
name = recvName;
Class cls = Class.forName(name);
action = (Action) cls.newInstance(); // 예외 모두 처리
action.excecute();
} catch (ClassNotFoundException e) {
System.out.println("해당 클래스명을 찾을 수 없음");
} catch (InstantiationException e) {
System.out.println("new로 인스턴스 생성 실패");
} catch (IllegalAccessException e) {
System.out.println("new로 인스턴스 생성 불가");
}Class class의 newInstance() 메소드
- 힙메모리에 인스턴스를 만들려면
new를 사용해야함.newInstance()매소드를 사용해도 힙메모리에 인스턴스 생성 가능함.
->new SendAction();
-
new를 사용한 것과newInstance()메소드를 사용한 것의 차이점new를 사용한 것은 소스 코드에서 인스턴스를 만들 클래스가 이미 결졍됨.newInstance() 메소드를 사용하면, 프로그램 내부에서 가변적으로 인스턴스를 만들어 클래스 변경 가능함.- Spring framework에서 사용하는 방식
-
newInstance()메소드를 사용하명서 처리해야하는 예외(exception)InstantiationException: 클래스가 abstract 이거나 interface인 경우 발생IllegalAccessException: 클래스 modifier가 인스턴스를 만들수 없는 경우(private) 접근제한자인 경우 예외 발생
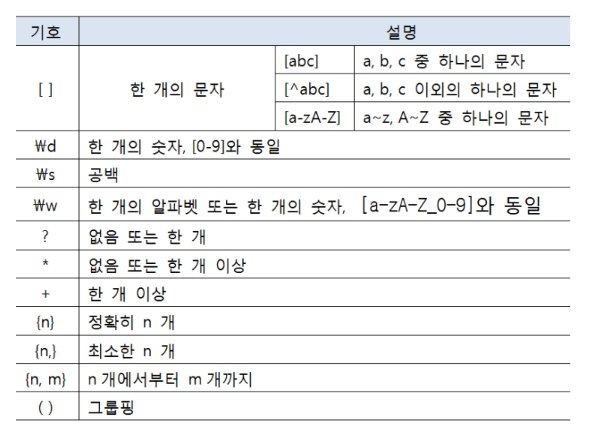
System.in.read(bytes)
- 키보드에서 byte[]배열로 문자들을 읽어와, byte 배열에 집어 넣음.
- 키보드의 각 문자는 바이트 단위로 저장됨.
- 한글(UTF-8)인 경우, 1개의 문자는 3개 바이트로 변환해 저장됨.
byte[] bytes = new byte[100];
System.out.print("입력 : ");
int readByteNo = System.in.read(bytes);
System.out.println("readByteNo : " + readByteNo);
String str = new String(bytes, 0, readByteNo-2);
// readByteNo-2 --> 엔터키(\r,\n)제외한 값
System.out.println(str);-
read()메소드의 return 값은 키보드로 읽어진 총 바이트 갯수- 읽어진 바이트에는 엔터키(
\r\n)도 포함됨.
- 읽어진 바이트에는 엔터키(
-
new String(bytes, 0, readByteNo-2)에서readByteNo-2는 엔터키(\r\n)를 제외한 갯수로 -2를 함.
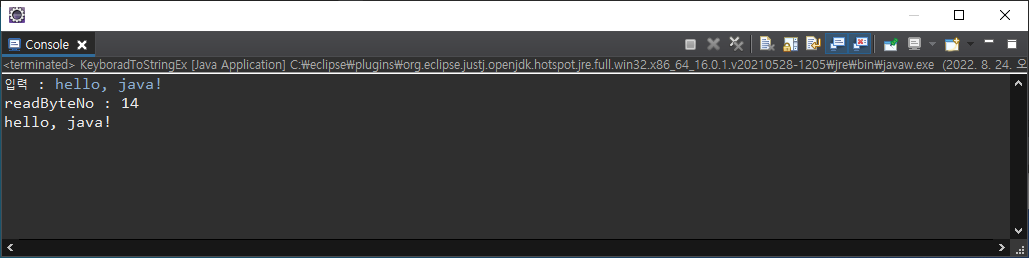
문자열 encoding과 decoding
- 일반적으로 인코딩(encoding)은 암호화 하는 것, 디코딩(decoding)은 암호를 해독하는 것
인코딩이란,
: 특정 문자 set으로 코드 변환한 것.
ex) UTF-8, MS949, EUC-KR
- '가'를 유니코드(2byte)에서 utf-8(3byte)로 변환
str.getBytes();- IDE에서 지정된 기본 encoding 방식임.
(windows eclipse에서 utf-8로 설정을 바꿔주는 이유임.)
- IDE에서 지정된 기본 encoding 방식임.
str.getBytes("EUC-KR");- EUC-KR 문자 set으로 encoding
str.getBytes("UTF-8");- UTF-8 문자 set으로 encoding
디코딩이란,
: 특정문자 set으로 변환된 바이트 배열을 원래 문자로 복구하는 것.
new String(b1);- IDE에서 지정된 기본 decoding 방식
new String(b2, "EUC-KR");- UTF-8로 encoding된 것을 유니코드로 decoding
new String(b3, "UTF-8");- EUC-KR로 encoding된 것을 유니코드로 decoding
!!! : 자바는 내부적으로 모든 문자를 유니코드(2byte)로 변환해 관리하고 있음.
ex) '가'의 유니코드 값은 '\uAC00'
-
한글 한 글자는 utf-8은 3byte, euc-kr은 2byte임.
-
결론, 현재 가장 보편적인 인코딩 방식은 UTF-8을 사용함
(web programing에서도 de facto standard로 인정)
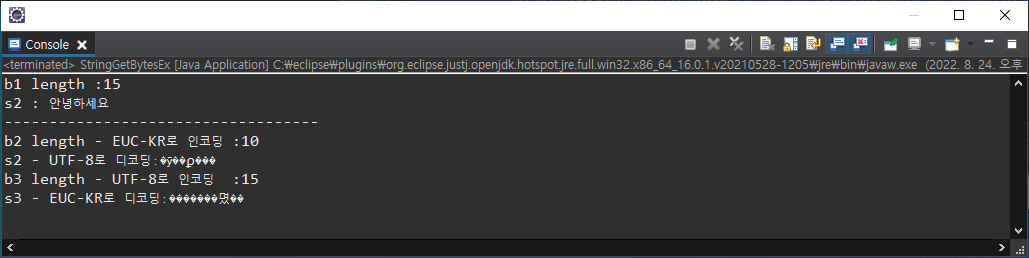
String str = "안녕하세요";
byte[] b1 = str.getBytes();
System.out.println("b1 length :" + b1.length);
String s1 = new String(b1);
System.out.println("s2 : " + s1);try {
byte[] b2 = str.getBytes("EUC-KR"); // EUC-KR 인코딩(encoding)
System.out.println("b2 length - EUC-KR로 인코딩 :" + b2.length);
String s2 = new String(b2, "UTF-8"); // UTF-8 디코딩(decoding)
System.out.println("s2 - UTF-8로 디코딩 : " + s2);
byte[] b3 = str.getBytes("UTF-8"); // UTF-8 인코딩(encoding)
System.out.println("b3 length - UTF-8로 인코딩 :" + b3.length);
String s3 = new String(b3, "EUC-KR"); // EUC-KR 디코딩(decoding)
System.out.println("s3 - EUC-KR로 디코딩 : " + s3);
} catch (UnsupportedEncodingException e) {
System.out.println("Java에서 지원하지 않는 encoding 방식 Exception 발생");
}
프로그램밍에서 인코딩/디코딩이 나온 이유
- 통신망을 통해 데이터를 주고(encoding) 받을(decoding) 때 사용함.
- 파일을 저장(encoding)하고 읽을(decoding) 때 사용함.
trim()
trim()은 문자열 앞 뒤의 공백을 제거하는 메소드
String tel1 = " 02 ";
String tel2 = "123 ";
String tel3 = " 2134 ";
String tel = tel1 + tel2 + tel3;
System.out.println(tel);
System.out.println();
tel = tel1.trim() + tel2.trim() + tel2.trim();
System.out.println(tel);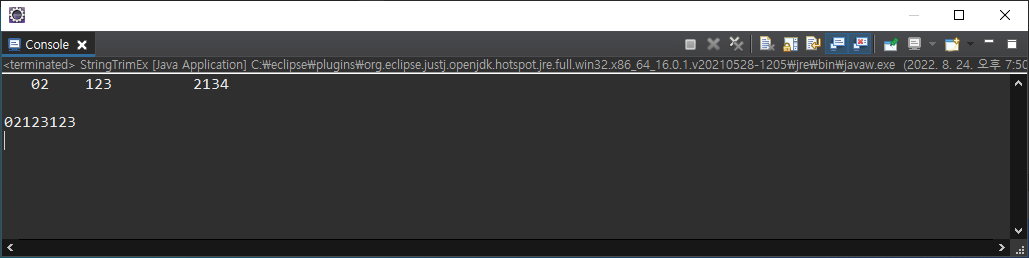
valueOf()
valueOf()method는 primitive data type을 문자열로 변환
String str1 = String.valueOf(10);
String str2 = String.valueOf(10.5);
String str3 = String.valueOf(false);
System.out.println(str1); // "10"
System.out.println(str2); // "10.5"
System.out.println(str3); // "false"
System.out.println(str1.length()); // 2
System.out.println(str2.length()); // 4
System.out.println(str3.length()); // 5split() 문자열 분할
split()은 String 클래스의 메소드임.split("&|,|-");설명&or,or-로 분할하라는 의미임.
- 웹 크롤링할 때 사용함.
ex)- 모든 웹사이트를 대상으로 특정 문자열로 검색할 때
- 검색 결과가 특정 문자열이 포함된 string데이터로 넘어옴
- 찾으려고 하는 키워드로 분할함(split)
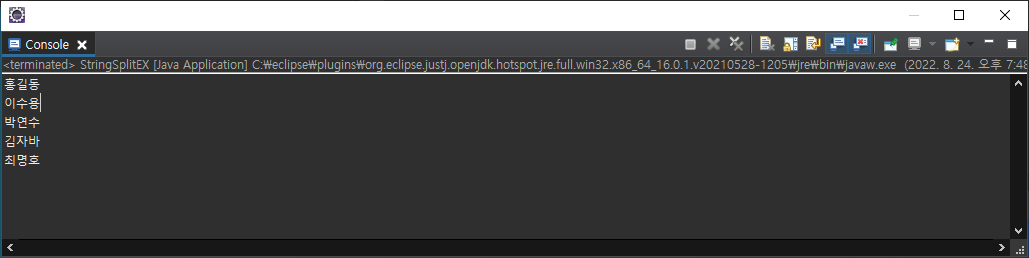
String text = "홍길동&이수용,박연수,김자바-최명호";
String[] names = text.split("&|,|-");
for (String name : names) {
System.out.println(name);
}
StringTokenizer(), nextToken()
StringTokenizer(읽어올 문자열, 나눌 문자열);형식
ex) StringTokenizer(text, "/");nextToken()은 메모리에서 해당 데이터를 제거 후 읽어옴.- Oracle 등 table에서 데이터를 읽어오거나, java collection등 framework에서도 사용함.
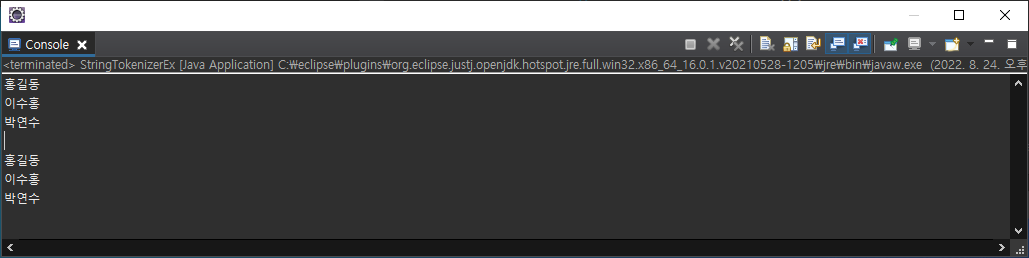
String text = "홍길동/이수홍/박연수";
StringTokenizer st = new StringTokenizer(text, "/");
int countTokens = st.countTokens(); // token으로 나눠진 전체 갯수
for (int i = 0; i < countTokens; i++) {
String token = st.nextToken(); // nextToken()
System.out.println(token);
}
System.out.println();
// 현재 st는 비어있음.
st = new StringTokenizer(text, "/");
// 같은 st를 만드는 이유는
// nextToken()이 힙메모리에 "홍길동/이수홍/박연수"문자열을 모두 버렸기 때문
while (st.hasMoreElements()) {
String token = st.nextToken();
System.out.println(token);
}!!! : 결과를 가져오고 하나씩 읽어내고 읽어낸 결과는 제거해 메모리를 바로 비우는 형식
-> 오라클(Oracle) 등 table에서 데이터를 읽어오거나, java collection 등 framework에서도 사용함.
StringBuilder class
!!! : String 문제점 : 새로운 문자열이 생길 때마다, 기존 문자열과 함께 힙메모리에 새로 만들어짐.(사라지지 않음, 프로그램 무거워짐.)
-> StringBuilder class는 String 클래스의 문제점 해결함.
- 문자열 연산을 하더라도 힙메모리에 한 개의 문자열로 관리가 됨.
- 내부적으로
StringBuilder클래스가 byte[] 배열을 초기에 넉넉한 크기로 만듦.
// new byte[1000];
// --> 내부적으로 StringBuilder 클래스가 byte[] 배열을 초기에 넉넉한 크기로 만듦.
StringBuilder sb = new StringBuilder();
// sb = ""; --> sb는 빈 문자열
sb.append("Java_");
sb.append("Programming study");
//.append()는 문자열 끝부터 입력받은 문자열 넣기.
System.out.println(sb);
sb.insert(4, "2");
// 문자열길이 4번째 "2" 넣기
System.out.println(sb);
sb.setCharAt(4, '6');
// 문자열길이 4번째 '6' char type 넣기
System.out.println(sb);
sb.replace(6, 13, "Book");
// 문자열길이 6번째에서 13번째를 "Book"으로 바꾸기.
System.out.println(sb);
sb.delete(4, 5);
// 문자열길이 4번째에서 5번째를 지우기.
System.out.println(sb);
System.out.println("총문장수 : " + sb.length());
System.out.println(sb.toString());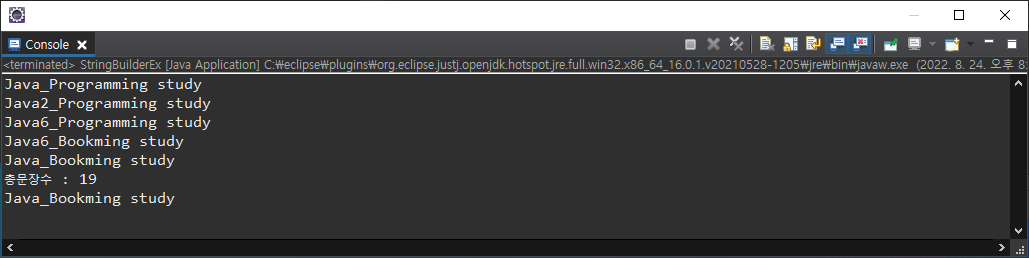
정규표현식(regular expression)
- mini programming language 같은 것.
- 문법을 이해하고 외워야 사용할 수 있다는 단점 있음.
- 표현 대상은 문자열(String)
- 사용 목적은 특정문자열 검색, 추출, 삭제 등 문자열 연산 관련, 다양한 방식으로 사용할 수 있음.
정규표현식으로 pattern 검색하기
: 위 예제는 해당하는 pattern이 맞는지 검색하는 프로그램
String regExp = "(02|010)-\\d{3,4}-\\d{4}";
// 전화번호에 관한 regular expression
String data = "010-123-5678";
boolean result = Pattern.matches(regExp, data);
if (result) {
System.out.println("정규식이 일치함");
} else {
System.out.println("정규식이 일치하지 않음");
}
regExp = "\\w+@\\w+\\.\\w+(\\.\\w+)?";
// 이메일 주소에 관한 regular expression
data = "angel@naver.co.kr";
result = Pattern.matches(regExp, data);
if (result) {
System.out.println("정규식이 일치함");
} else {
System.out.println("정규식이 일치하지 않음");
}-
100page 문서(문자열)에서 전화번호에 해당하는 모든 것을 추출
-
정규표현식
"(02|010) - \\d{3,4}-\\d{4}"설명(02|010)-> 02 or 010
--> '-'문자열 나옴
\d-> d는 digit(숫자 0~9)을 의미함(MS windows에서는 \를 \로 표현함.)
{3,4}-> 연속하는 3자리 문자열이나 4자리 문자열 들어옴, \d{3,4}는 3자리나 4자리 숫자 있음
{4}-> 연속하는 4자리 문자열 들어옴,\d{4}는 4자리 숫자 있음
-
-
100page 문서(문자열)에서 이메일에 해당하는 모든 것을 추출
- 정규표현식
"\\w+ @ \\w+ \\. \\w+ (\\. \\w+)?";설명
\w-> 영어 알파벳 대소문자 들어옴
+-> 1개 이상 있음
@-> '@' 이 있음
\.-> '.'이 있음
?-> 0번 또는 1번있음,(\\.\\w+)있을 수도 있고 없을 수도 있다는 의미
- 정규표현식
정규 표현식 Pattern 클래스