프로세스와 스레드
프로세스
운영체제로부터 자원을 할당받은 작업의 단위이다.
프로세스는 프로그램을 실행시켜 정적인 프로그램이 동적으로 변하여 프로그램이 돌아가고 있는 상태를 말한다. 즉, 컴퓨터에서 작업중인 프로그램을 의미한다.
모든 프로그램은 운영체제가 실행되기 위한 메모리 공간을 할당해줘야 실행될 수 있다. 프로그램을 실행하는 순간 파일은 컴퓨터 메모리에 올라가게 되고, 운영체제로부터 시스템 자원(CPU)을 할당받아 프로그램 코드를 실행시켜 우리가 서비스를 이용할 수 있게 된다.
스레드
프로세스가 할당받은 자원을 이용하는 실행 흐름의 단위이다.
스레드는 하나의 프로세스 내에서 동시에 진행되는 작업 갈래, 흐름의 단위이다.
스레드끼리 프로세스의 자언을 공유하면서 프로세스 실행 흐름의 일부가 되기 때문에 동시 작업이 가능한 것이다.
예를 들자면, 크롬을 실행하면 프로세스 하나가 실행 될 것이다. 그런데 우리는 브라우저에서 동영상을 틀어놓고 온라인 쇼핑을 즐기면서 게임을 하기도 한다.

이것은 하나의 프로세스 안에서 여러가지 작업들 흐름이 동시에 진행되기 떄문에 가능한 것이다. 이러한 일련의 작업 흐름들을 스레드라고 하며 여러 개가 있다면 이를 멀티 스레드라고 부른다.
프로세스 & 스레드의 메모리
프로세스의 자원 구조
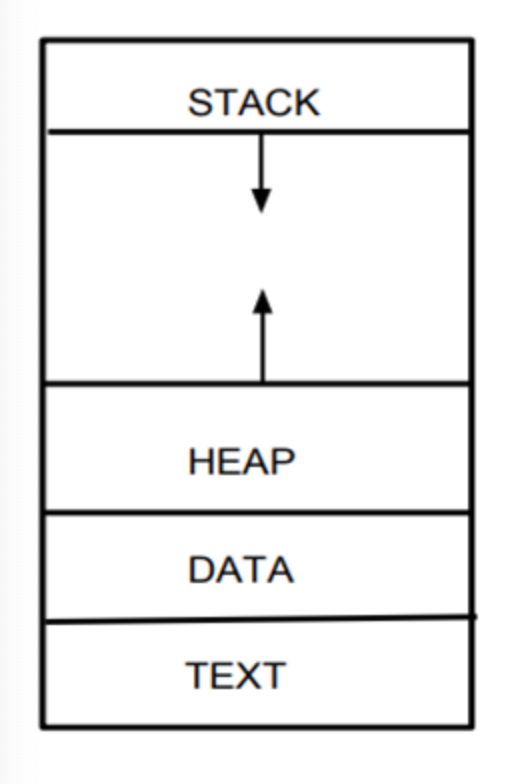
1) 코드 영역(Code / Text) - 프로그래머가 작성한 프로그램 함수들의 코드가 CPU가 해석 가능한 기계어 형태로 저장되어 있다.
2) 데이터 영역(Data) - 코드가 실행되면서 사용하는 전역 변수나 각종 데이터들이 모여있다.
3) 스택 영역(Stack) - 지역 변수와 같은 호출한 함수가 종료되면 되돌아올 임시적인 자료를 저장하는 독립적인 공간이다. Stack은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸된다.
4) 힘 영역(Heap) - 생성자, 인스턴스와 같은 동적으로 할당되는 데이터들을 위해 존재하는 공간이다. 사용자에 의해 메모리 공간이 동적으로 할당되고 해제된다.
위 그림에서 Stack과 Heap 영역이 위아래로 화살표가 그려진 이유는 코드영역, 데이터 영역은 정적 영역이지만, Stack, Heap은 프로세스가 실행되는 동안 크기가 동적으로 변하기 때문이다.
스레드의 자원 구조
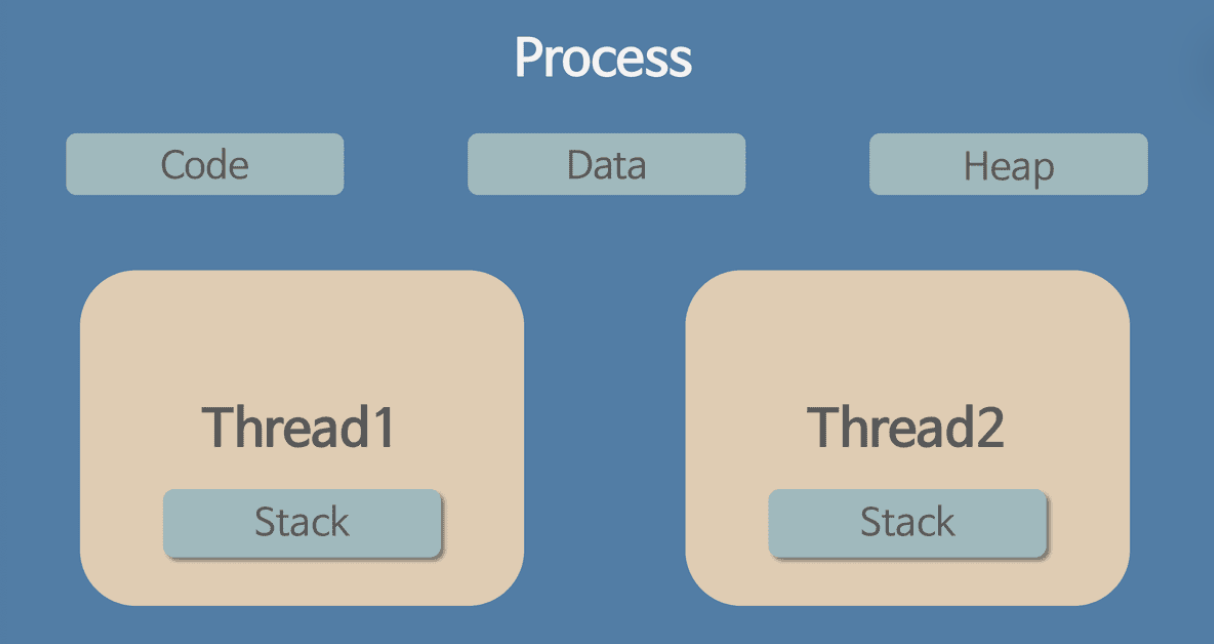
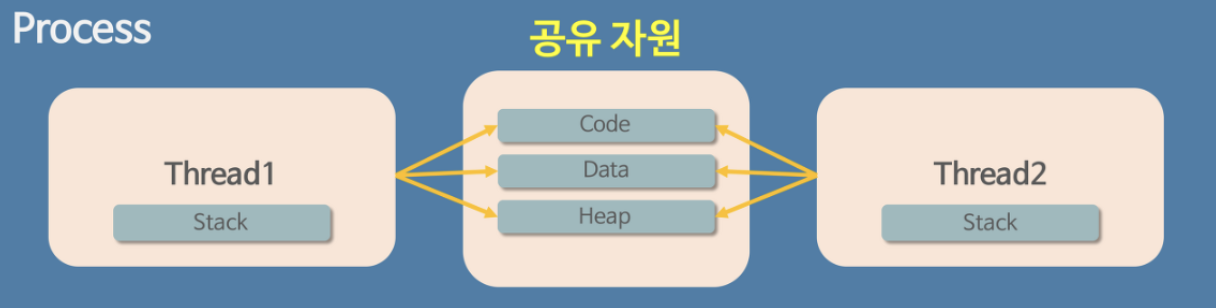
스레드는 프로세스의 4가지 메모리 영역 중 Stack만 할당받아 복사하고 Code, Data, Heap은 프로세스 내의 다른 스레드들과 공유된다.
독립적인 스택을 가졌다는 것은 독립적인 함수 호출이 가능하다는 의미이다. 또한, 독립적인 함수 호출이 가능하다는 것은 독립적인 실행 흐름이 추가된다는 말이다.
즉, Stack을 가짐으로써 스레드는 독립적인 실행 흐름을 가질 수 있게 되는 것이다.
Base64
Base64란 Binary Data를 Text로 바꾸는 Encoding의 하나로써 Binary Data를 Character Set에 영향을 받지 않는 공통 ASCII 영역의 문자로만 이루어진 문자열로 바꾸는 Encoding이다.
인코딩
문자나 파일을 약속도니 규칙에 따라 컴퓨터가 이해하는 언어로 이루어진 코드로 바꾸는 것을 통틀어 일컫는다. 즉, 인코딩이란 정해진 규칙에 따라 코드화, 암호화, 부호화 하는 것을 말한다. 이렇게 인코딩 하는 이유는 정보의 형태 표준화, 보안, 저장 공간 절약 등을 위해서이다.
디코딩
디코딩이란 인코딩의 역과정으로, 이진 형식의 데이터를 사람이 해석할 수 있는 데이터로 변환하는 작업이다.
BCryptPasswordEncoder
스프링 시큐리티 프레임워크에서 제공하는 클래스 중 하나로 비밀번호를 암호화하는 데 사용할 수 있는 메서드를 가진 클래스이다.
BCryptPasswordEncoder는 PasswordEncoder 인터페이스를 구현한 클래스이다.
BCryptPasswordEncoder는 BCrypt 해싱 함수를 사용해서 비밀번호를 인코딩 해주는 메서드와 사용자에 의해 제출된 비밀번호와 저장소에 저장되어 있는 비밀번호의 일치 여부를 확인해주는 메서드를 제공한다.
encode 메서드는 솔트(salt)를 지원한다. 똑같은 비밀번호를 해당 메서드를 통하여 인코딩하더라도 매번 다른 인코딩 된 문자열을 반환한다.
입력받은 패스워드에 랜덤하게 생성된 salt를 더해서 해싱한 값을 데이터베이스 저장하므로, 가능한 모든 문자열 조합을 해시함수에 넣어서 결과를 저장한 테이블인 Rainbow Table을 활용한 브루트 포스 공격을 막는다.
String encode = bCryptPasswordEncoder.encode(password);
$2a$10$areHbojzw3eHObSfiKGay.66OFxaJiEKy8d.n5CqvCyjY25ZVIfha
String encode2 = bCryptPasswordEncoder.encode(password);
$2a$10$m1pTFfDjNTpgx9RgR7dnr.4/KTRSRMHSbrtXrTYlUd4LFHCWaQXtW같은 값에 대해 2번의 encode 결과는 서로 다르다.
그럼 이 salt값은 어디에 저장되어 있는 것인가?
salt 값은 해시값에 이어붙여서 함께 저장되고 있다.
$2a$10$7EqJtq98hPqEX7fNZaFWoOeX3ZrloBHZEE5pcT9N/0GbE3Kw6hJD.구성
- 알고리즘 버전
10 - cost factor (반복 횟수)
7EqJtq98hPqEX7fNZaFWoO - 솔트 값
eX3ZrloBHZEE5pcT9N/0GbE3Kw6hJD. - 해시 값
matches 메서드는 암호화된 값에서 추출한 솔트를 사용하여 평문 비밀번호를 다시 해싱한다. 이때, 동일한 알고리즘(BCrypt)과 동일한 cost factor를 사용해 비밀번호를 처리한다.
배열과 리스트
배열 (Array)
배열은 원소들을 연속적인 메모리 공간에 저장하는 자료구조이다. 배열의 크기는 고정되어 있으며, 선언 시에 크기를 지정해야 된다.
리스트 (List)
리스트는 원소들을 연결하여 저장하는 자료구조이다. 원소의 개수가 가변적이며, 삽입과 삭제가 자유롭다.
차이점
1) 메모리 할당
배열은 연속적인 메모리 공간에 할당되고, 리스트는 비연속적인 메모리 공간에 할당된다.
2) 크기
배열은 크기가 고정되어 있으며, 리스트는 가변적이다.
3) 접근 방법
배열은 인덱스를 통한 빠른 접근이 가능하지만, 리스트는 순차적으로 접근해야 된다.
Java에서 ArrayList는 인덱스를 통한 접근이 가능하지만, LinkedList와 같은 경우에만 순차적으로 접근해야 된다.
4) 삽입과 삭제
배열은 삽입과 삭제가 번거롭고 시간이 오래 걸리지만, 리스트는 삽입과 삭제가 빠르다.
LinkedList
데이터 요소(Node)들이 링크(포인터)로 연결되어 선형 자료구조를 형성하는 자료구조이다.
인덱스를 통한 접근이 힘들기 때문에, 순차적으로 탐색해야 된다. 최악의 경우 시간 복자도는 O(n)이다.
Node에 데이터 뿐만 아니라 포인터도 저장해야 되기 때문에 추가적인 메모리 공간이 필요하다.

컴파일러 VS 인터프리터
컴퓨터는 고급 언어로 작성한 코드를 바로 인식하지 못하기 때문에 이를 번역하는 과정이 컴파일이다.
컴파일러
컴파일러는 프로그램 전체를 스캔하여 이를 모두 기계어로 변역한다. 전체를 스캔하기 때문에 컴파일러는 초기 스캔 시간이 오래 걸린다. 하지만 전체 실행 시간만 따지고 보면 인터프리터 보다 빠르다.
컴파일러는 초기 스캔을 마치면 실행파일을 만들어 놓고 다음에 실행할 때 이전에 만들어 놓았던 실행파일을 실행하기 때문이다.
단점으로는 컴파일러가 인터프리터 보다 더 많은 메로리를 사용한다. 컴파일러가 고급 언어로 작성된 소스를 기계어로 번역하고 이 과정에서 오브젝트 코드라는 파일을 만드는데 이 오브젝트 코드를 묶어서 하나의 실행 파일로 다시 만드는 링킹이라는 작업을 해야 되기 때문이다.
인터프리터
인터프리터는 컴파일러와 다르게 프로그램 실행시 한 번에 한 문장씩 번역한다. 그렇기 때문에 한번에 전체를 스캔하고 실행파일을 만들어서 실행하는 컴파일러보다 실행시간이 더 걸린다. 한 문장 읽고 번역하여 실행시키는 과정을 반복하는게 만들어 놓은 실행파일을 한 번 실행시키는 것보다 빠르긴 힘들다.
인터프리터는 메모리 효율이 좋다. 링킹 과정을 거치지 않기 때문이다. 인터프리터는 메모리 사용에 컴파일러보다 더 효율적인 모습을 보인다.
정리
컴파일러
1) 전체 파일을 스캔하여 한꺼번에 번역한다.
2) 초기 스캔시간이 오래 걸리지만, 한 번 실행 파일이 만들어지고 나면 빠르다.
3) 기계어 번역과정에서 더 많은 메모리를 사용한다.
4) 전체 코드를 스캔하는 과정에서 모든 오류를 한꺼번에 출력해주기 때문에 실행 전에 오류를 알 수 있다.
인터프리터
1) 프로그램 실행 시 한 번에 한 문장씩 번역한다.
2) 한 번에 한 문장씩 번역 후 실행 시키기 때문에 실행 시간이 느리다.
3) 오브젝트 코드 생성과정이 없기 때문에 메모리 효율이 좋다.
4) 프로그램을 실행시키고 나서 오류를 발견하면 바로 실행을 중지 시킨다. 실행 후에 오류를 알 수 있다.
Java는 컴파일러? 인터프리터?
Java는 컴파일 시 전체 코드를 바이트 코드로 변환한 뒤, 클래스 로더를 통해 관리한다. 필요한 시점에 해당 코드를 JVM의 메모리 영역에 올려 사용한다. JVM은 바이트코드를 OS에 맞게 번역해 실행한다.
그럼 Java는 과연 컴파일러일까 인터프리터일까?
정답은 자바는 컴파일러와 인터프리터 둘 다 사용하는 것으로 간주된다고 한다.
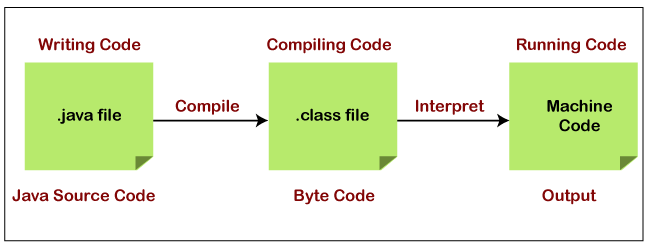
자바 컴파일러가 소스 코드를 자바 바이트 코드로 컴파일하고, 자바 인터프리터는 바이트 코드를 기계어가 이해할 수 있는 기계코드로 변환하거나 번역한다.
바이트 코드를 기계 코드로 변환하기 위해 JVM에 .class 파일을 배포하면 JVM은 자바 인터프리터를 사용하 여 그 코드를 기계 코드로 변환하거나 변역한다.
- 빌드란? - 빌드란 소스 코드 파일을 실행 가능한 소프트웨어 산출물로 변환하는 과정이다. 이 과정에서는 소스 코드 파일을 컴파일하고, 링크를 거쳐 실행 파일이나 라이브러리 파일 등을 생성한다. 즉, 빌드는 소스 코드 파일을 실행 가능한 형태로 변환하는 과정으로, 컴파일 이후 링크 과정을 포함한다.
빌드하면 JAR 파일 생성됨. 빌드 툴로는 Maven과 Gradle이 있음
인터페이스
인터페이스는 추상 메서드와 상수만을 가질 수 있는 기본 설계도이다.
public interface TestInterface {
public final int a = 10;
void test();
}인터페이스를 사용하는 이유는?
1) 개발 기간을 단축 시킬 수 있다.
인터페이스를 사용하면 이 틀을 사용해서 프로그램을 작성할 수 있다.
2) 표준화가 가능하다.
인터페이스로 틀을 잡아놓고 개발 하면 여러 명의 개발자가 작업을 할 때도 일관된 틀 안에서 그 안의 내용을 구현하면서 개발이 진행되므로 정형화된 작업이 가능하다.
단점은?
1) 인터페이스의 모든 메서드를 구현해야 된다.
만약 인터페이스의 추상화가 제대로 이루어지지 않은 경우에는 불필요한 메서드까지 구현해야 될 수 있다.
2) 변경이 어렵다.
인터페이스를 많은 클래스에서 사용하고 있는 상태에서 인터페이스에 메소드가 추가된다면 해당 인터페이스를 사용하는 모든 클래스를 수정해야 된다.
디자인 패턴
싱글톤(Singleton) 패턴
인스턴스가 프로그램 전체에서 단 하나만 생성되도록 보장하는 디자인 패턴이다.
싱글톤 패턴의 특징
1) 전역 접근 가능 - 클래스의 유일한 인스턴스에 대해서 전역 접근을 제공한다.
2) 리소스 공유 - 여러 부분에서 동일한 객체를 공유할 수 있어 리소스 사용을 최적화 할 수 있다.
3) 상태 유지 - 프로그램 실행 중 객체를 일관되게 유지할 수 있다.
싱글톤 패턴의 장점
싱글톤 패턴을 사용함으로써 얻을 수 있는 이점 중 하나는 메로리 낭비를 방지할 수 있다.
같은 객체 여러개를 만들 필요 없이 하나의 객체만을 생성하여 사용한다.
싱글톤 패턴의 단점
모든 곳에서 같은 상태를 가지기 때문에 값의 변경에 대해 민감해진다. 변수를 수정하게 될 경우 다른 코드에 의도하지 않은 영향을 줄 수 있다.
팩토리(Factory) 패턴
팩토리 패턴은 객체 생성을 처리하는 디자인 패턴이다.
이 패턴은 객체 생성 로직을 클라이언트 코드에서 분리하여 유연성을 높이고 코드 재사용성을 향상시킨다.
팩토리 패턴의 특징
1) 객체 생성 로직을 캡슐화한다.
2) 구체적인 클래스에 의존하지 않고 인터페이스를 통해 객체를 다룬다.
3) 새로운 제품 유형을 쉽게 추가할 수 있다.
팩토리 패턴의 장점
1) 코드의 유연성과 확장성이 향상된다.
2) 객체 생성 로직과 사용 로직을 분리하여 결합도를 낮춘다.
3) 코드 재사용성이 증가한다.
팩토리 패턴의 단점
새로 생성할 객체가 늘어날 때마다 Factory 클래스에 추가해야 되기 때문에 클래스가 많아짐
//인터페이스
public interface IsSpeaker {
void speak();
}
//구현체
@Service
public class EnglishSpeaker implements IsSpeaker{
@Override
public void speak(){
System.out.println("I'm english speaker");
}
}
@Service
public class GermanSpeaker implements IsSpeaker{
@Override
public void speak(){
System.out.println("I'm German Speaker");
}
}
@Service
public class KoreanSpeaker implements IsSpeaker{
@Override
public void speak(){
System.out.println("I'm Korean Speaker");
}
}
//ENUM
public enum Language {
ENGLISH, GERMAN, KOREAN
}
//Factory
public class SpeakerFactory {
public static IsSpeaker createSpeaker(Language language){
switch(language){
case ENGLISH -> {
return new EnglishSpeaker();
}
case GERMAN -> {
return new GermanSpeaker();
}
case KOREAN -> {
return new KoreanSpeaker();
}
default -> {
throw new ApplicationContextException("Unsupported language " + language);
}
}
}
}
파사드(Facade) 패턴
파사드 패턴은 객체를 생성하는 패턴이 아닌, 강력한 결합 구조를 해결하기 위해 코드의 의존성을 줄이고 느슨한 결합으로 구조를 변경한다.
메인 시스템과 서브 시스템 중간에 위치하여, 새로운 인터페이스 계층을 추가하며 시스템 간 의존성을 해결한다. 인터페이스 계층은 메인 시스템과 서브 시스템의 연결 관계를 대신 처리한다.
서브 시스템을 호출, 결합할 수 있는 인터페이스를 제공한다. 인터페이슨느 한 개일 수 있고 여러 개일 수도 있다.
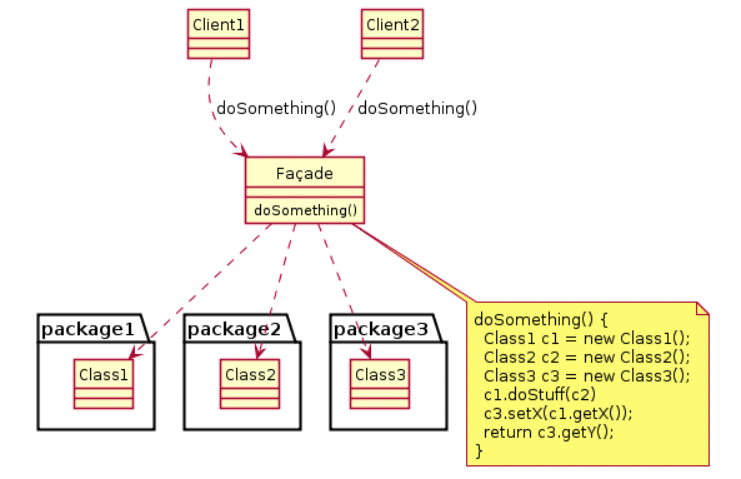
클라이언트가 특정 회사에 어떠한 작업을 의뢰한다고 생각하자.
클라이언트가 직접 디자이너, 밑그림 작업자, 채색자 등의 작업 순서를 알고 통제할 필요가 없다.
클라이언트는 단순히 특정 회사에 의뢰하는 인터페이스를 호출하도록 하는 것이 좋을 것이다.
파사드 패턴의 장점
1) 복잡성 감소 - 클라이언트 코드의 복잡성을 크게 줄인다.
2) 유지보수 용이성 - 서브시스템의 변경이 클라이언트에 미치는 영향을 최소화한다.
3) 코드 재사용 - 파사드를 통해 서브 시스템을 다양한 컨텍스트에서 쉽게 재사용할 수 있다.
4) 의존성 감소 - 클라이언트가 저체 서브시스템이 아닌 파사드에만 의존하게 된다.
파사드 패턴의 단점
1) 유연성 제한 - 파사드가 제공하는 인터페이스로 인해 서브시스템의 세부 기능에 대한 접근이 제한될 수 있다.
2) 파사드 클래스의 복잡성 - 서브시스템이 매우 복잡한 경우, 파사드 클래스 자체가 복잡해질 수 있다.
@Component
public class Designer {
public void analysis() {
System.out.println("디자이너가 요구사항 분석중");
}
public void design() {
System.out.println("디자이너가 초안 구상중");
}
}
@Component
public class Drawer {
public void draw() {
System.out.println("드로어가 밑그림 그리는 중");
}
public void linePick() {
System.out.println("드로어가 선 따는 중");
}
}
@Component
public class Painter {
public void colorScheme() {
System.out.println("채색자가 배색하는 중");
}
public void paint() {
System.out.println("채색자가 칠하는 중");
}
}
@Service
@RequiredArgsConstructor
public class FacadeCompany {
private final Designer designer;
private final Drawer drawer;
private final Painter painter;
public void work(){
designer.analysis();
designer.design();
drawer.draw();
drawer.linePick();
painter.colorScheme();
painter.paint();
}
}
public void facadeTest(){
facadeCompany.work();
}프록시(Proxy) 패턴
프록시 패턴은 대상 원본 객체를 대리하여 대신 처리하게 함으로써 로직의 흐름을 제어하는 행동 패턴이다.
프록시의 사전적 의미는 대리인이라는 뜻이다. 누군가에게 어떤 일을 대신 시키는 것을 의미한다.
OOP에 접목해보면 클라이언트가 대상 객체를 직접 쓰는게 아니라 중간에 프록시를 거쳐서 쓰는 코드 패턴이다.
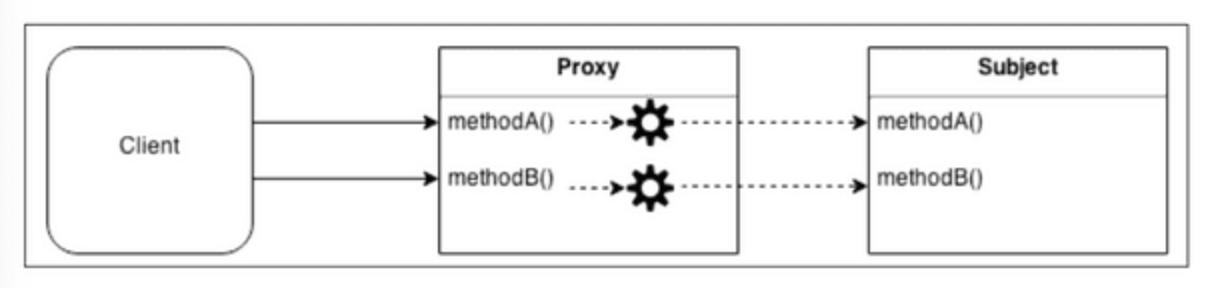
대상 클래스가 민감한 정보를 가지고 있거나 인스턴스화 하기에 무겁거나 추가 기능을 넣고 싶은데, 원본 객체를 수정할 수 없는 상황일 때를 극복하기 위해서 사용한다.
1) 보안 - 프록시는 클라이언트가 작업을 수행할 수 있는 권한이 있는지 확인하고 검사 결과가 긍정적인 경우에만 요청을 대상으로 전달한다.
2) 캐싱 - 프록시가 내부 캐시를 유지하여 데이터가 캐시에 존재하지 않는 경우에만 대상에서 작업이 실행되도록 한다.
3) 데이터 유효성 검사 - 프록시가 입력을 대상으로 전달하기 전에 유효성을 검사한다.
접근을 제어하거나 기능을 추가하고 싶은데, 기존의 특정 객체를 수정할 수 없는 상황일때 사용된다.
프록시 패턴의 장점
1) 개방 폐쇄 원칙(OCP) 준수 - 기존 객체를 수정하지 않고 일련의 로직을 프록시 패턴을 통해 추가할 수 있다.
2) 단일 책임 원칙(SRP) 준수 - 대상 객체는 자신의 기능에만 집중 하고, 그 이외 부가 기능을 제공하는 역할을 프록시 객체에 위임하여 다중 책임을 회피할 수 있다.
프록시 패턴의 단점
1) 코드의 복잡도가 증가한다. 로직이 난해해져 가독성이 떨어질 수 있다.
2) 성능이 저하될 수 있다. 객체를 생성할 때 한 단계를 거치게 되므로, 빈번한 객체 생성이 필요한 경우
public interface ISubject {
void action();
}
@Component
public class RealSubject {
public void action(){
System.out.println("action");
}
}
@Service
@RequiredArgsConstructor
public class Proxy implements ISubject{
private final RealSubject realSubject;
public void action(){
System.out.println("데이터 전처리 또는 보안 관련 로직 수행");
realSubject.action(); // 위임
System.out.println("Proxy action");
}
}
public void testProxy(){
proxy.action();
return ResponseEntity.ok().build();
}대상 객체와 Proxy 클래스에서 인터페이스를 Implements한다.
병렬 프로그래밍
병렬 프로그래밍은 여러 스레드를 사용하여 작업을 동시에 수행하는 것을 의미한다. 자바에서는 쓰레드와 실행자(Executor)를 사용하여 병렬 프로그래밍을 구현할 수 있다.
병렬성 VS 동시성
동시성 - 하나의 시스템이 여러 작업을 동시에 처리하는 것처럼 보이게 하는 것이다.

동시성은 스레드, 비동기 프로그래밍 등의 방법을 사용하여 구현된다.
여러 작업을 번갈아가며 처리하므로 작업이 빠르게 완료될 수 있다.
병렬성 - 여러 작업을 실제로 동시에 처리하는 것이다.
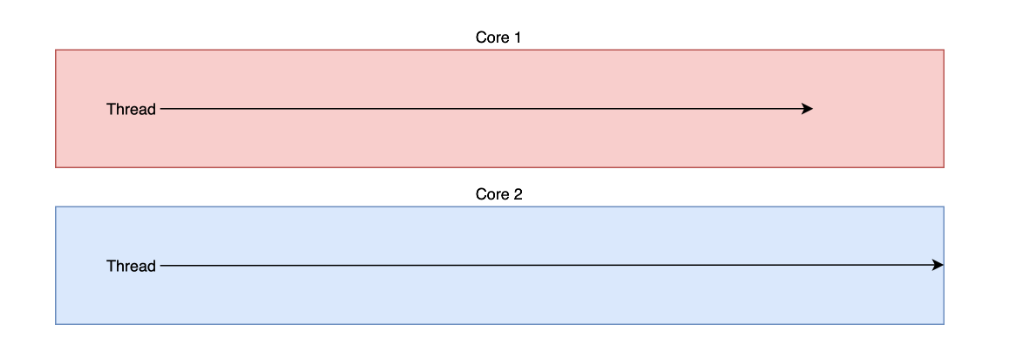
병렬로 처리할 작업들은 병렬처리기에서 실행되며, 각각의 작업은 별도이 프로세스나 스레드에서 실행된다.
병렬처리기는 여러 개의 CPU 또는 CPU 코어가 있어서, 각각의 작업이 서로 다른 CPU 또는 CPU 코어에서 병렬적으로 실행된다.
병렬성은 여러 작업이 동시에 실행되는 것이지만, 작업들은 각각이 독립적으로 실행되며 서로 영향을 주지 않는다.
동시성은 서로 다른 작업들이 서로 영향을 주면서 동시에 실행되는 것처럼 보인다.
동시성은 싱글 코어에서 멀티 쓰레드를 동작 시키는 방식,
병렬성은 멀티 코어에서 멀티 쓰레드를 동작 시키는 방식이다.
동기 통신 VS 비동기 통신
동기 통신은 요청 후 결과 응답을 기다렸다가 받고, 비동기 통신은 요청 후 결과 응답을 기다리지 않고 나중에 받거나 생략합니다.
결과를 나중에 받는 방법은 이벤트 리스너를 등록하는 방법이 있다.
동기 통신
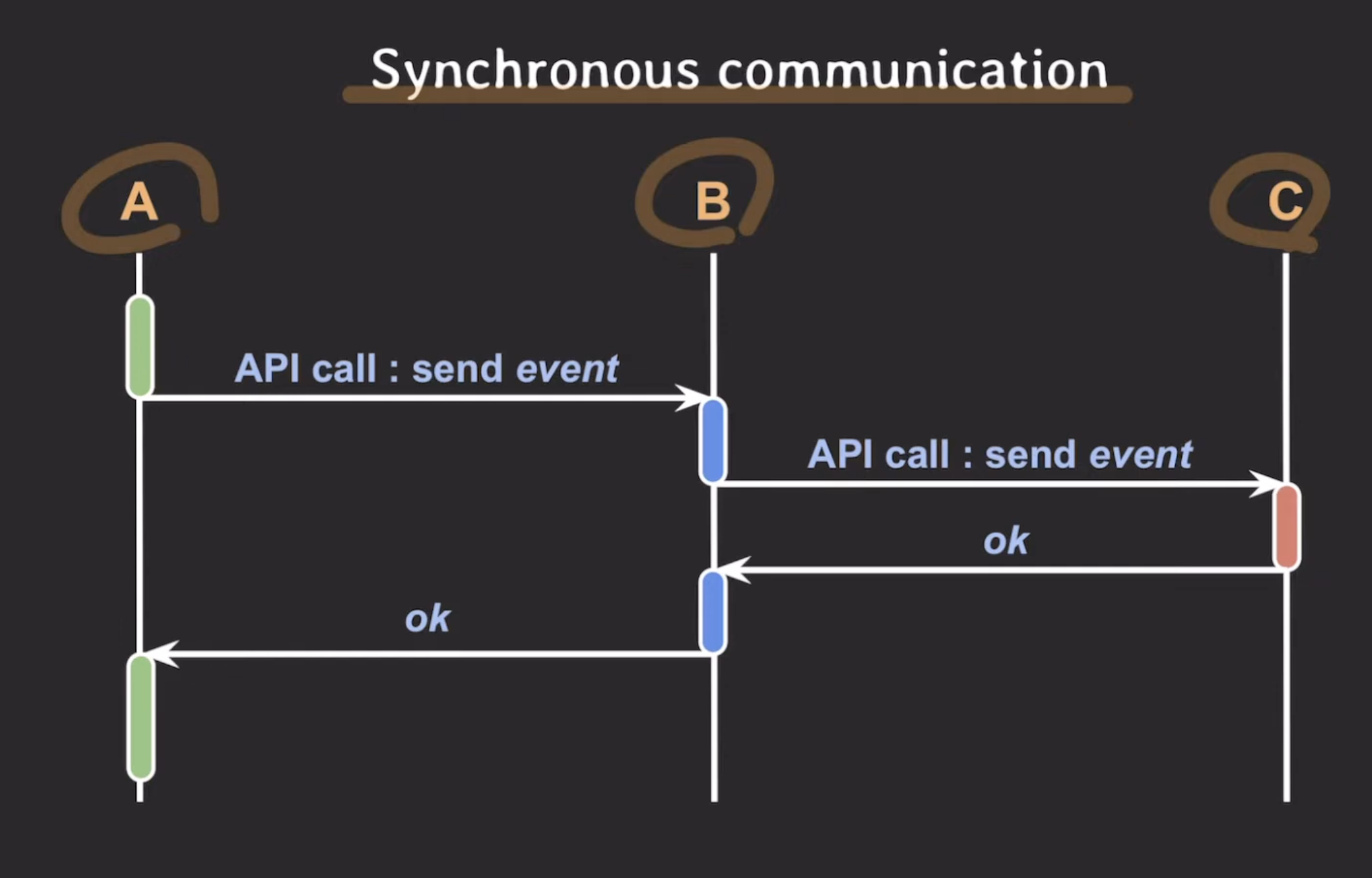
동기 통신에서는 A는 B에게 직접 요청을 보내고 해당 작업이 완료될 때까지 기다려야된다.
이떄 A는 B의 작업이 완료될 때까지 다른 작업을 수행할 수 없으며, B도 C에게 요청을 동기 통신으로 작업 요청을 한 상태이기 때문에 C의 작업이 완료될 때까지 기다려야된다.
동기 통신의 단점 중 하나는 장애 전파에 대한 취약성이다.
여러 개의 서비스가 동기적으로 의존하고 있는 상황에서 하나의 서비스가 장애를 겪으면 이로 인해 전체 시스템에 장애가 전파될 수 있다.
예를 들어, B가 C에게 요청을 보낸 상황에서 에러가 발생한다면 A까지 B에게 보낸 작업 요청까지 장애가 전파된다. 결과적으로 전체 시스템의 가용성과 안정성이 저하될 가능성이 있다.
비동기 통신
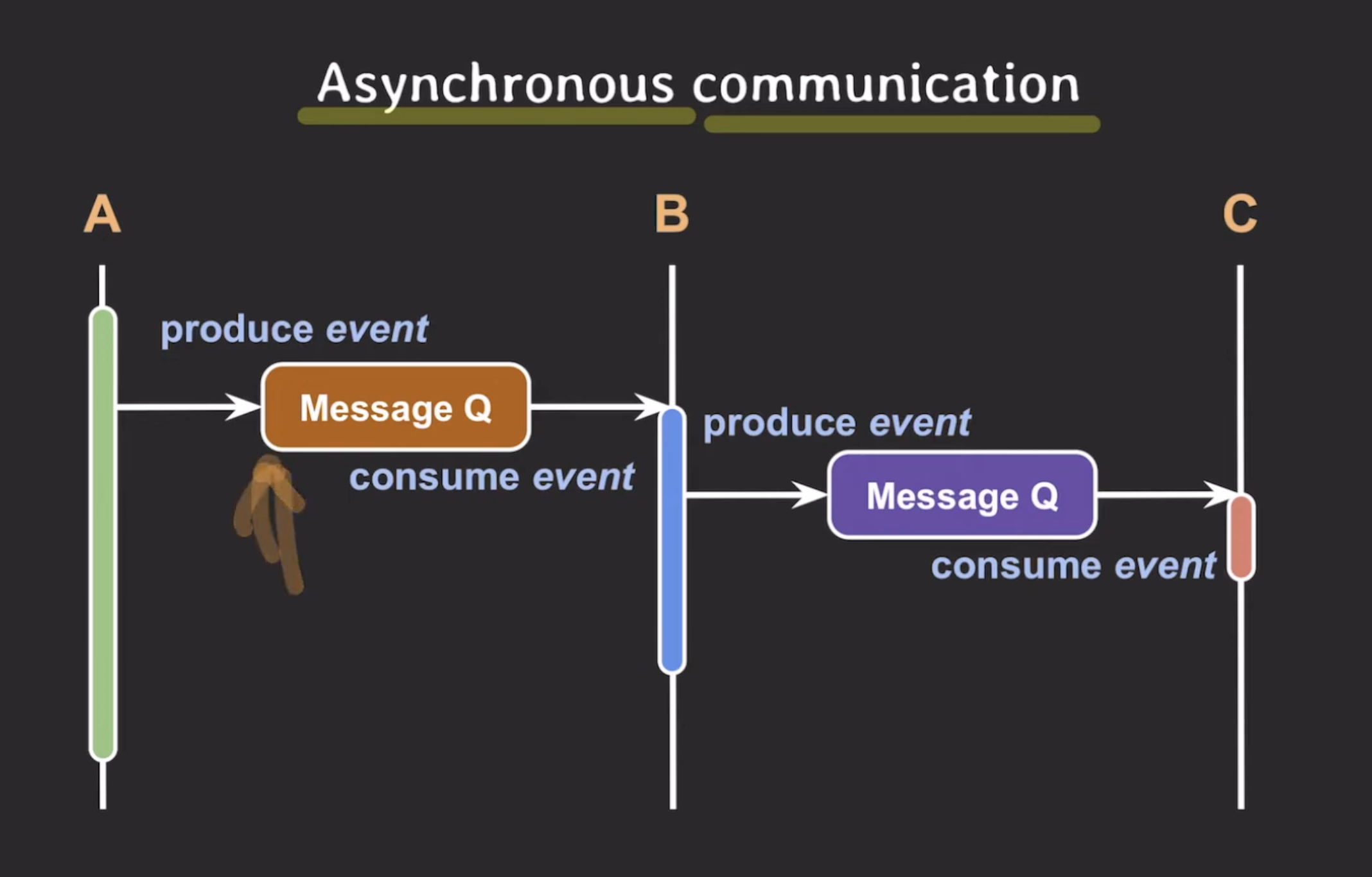
비동기 통신에서는 A가 작업을 수행하다가 B에게 작업 요청을 보낼 때, 해당 요청(이벤트)을 Message Q에 넣어둔다. A는 이후 작업을 계속 이어나가고 B는 Message Q를 주기적으로 확인하여 새로운 이벤트가 있는 경우 작업을 수행한다.
이와 같은 방식으로 각 서비스는 독립적으로 작업을 수행하면서 중간에 Message Q를 통해 정보를 교환한다.
이러한 비동기 통신의 장점은 장애가 발생해도 다른 서비스에 영향을 미치지 않을 가능성이 높다는 것이다.
하지만 비동기 통신만을 사용하는 것은 옳은 선택은 아니다. 동기적인 작업이 필요한 경우나 응답이 필요한 경우에는 API 호출과 같은 동기적인 방식을 사용하는 것이 적절하다.
이벤트를 한쪽으로 전달만 하면 되는 경우에는 Message Q를 두는 것이 더 안정적인 서비스 운영을 위한 서버 아키텍쳐가 될 수 있다.
블로킹 / 논블로킹
다른 요청의 작업을 처리하기 위해 현재 작업을 Block(차단, 대기) 하냐 안하냐의 유무를 나타내는 프로세스의 실행 방식이다.
동기/비동기가 전체적인 작업에 대한 순차적인 흐름 유무라면, 블로킹/논블로킹은 전체적인 작업의 흐름 자체를 막냐 안막냐로 볼 수 있다.
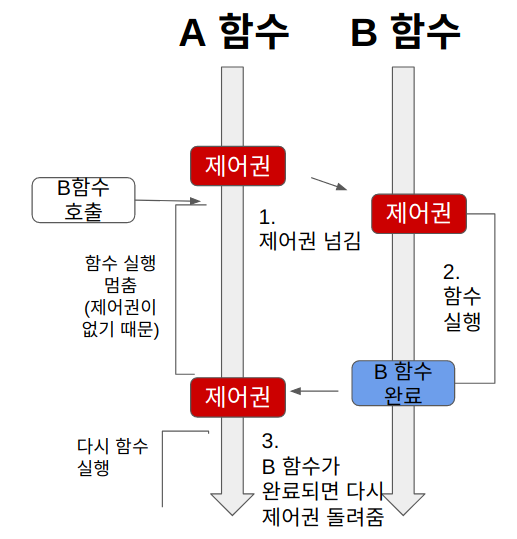
블로킹
블로킹은 A함수가 B함수를 호출하면, 제어권을 A가 호출한 B함수에 넘겨준다.
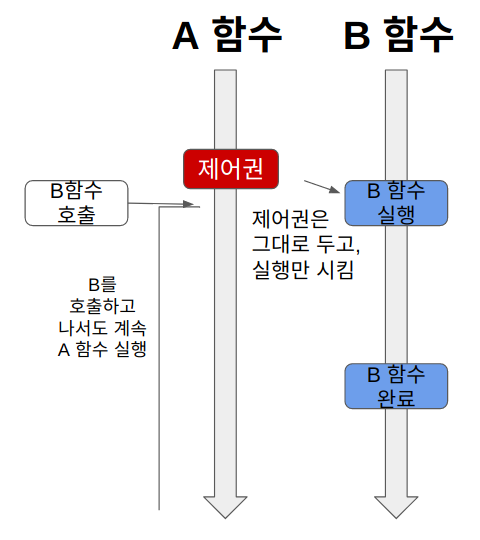
논블로킹
논블로킹은 A함수가 B함수를 호출해도 제어권은 그대로 자신이 가지고 있는다.
동기 비동기, 블로킹 논블로킹
블로킹 / 논블로킹이 현재의 작업 상태에 따라 동작이 결정되는 것이라면, 동기 / 비동기는 결과를 기다리는 주체가 누구인가에 대한 이야기이다.
동기는 결과를 기다리는 주체가 요청을 호출한 스레드이다. 해당 스레드는 요청에 대한 결과가 돌아오기까지 아무것도 하지 않게 될 것이다.
위에 있는 블로킹과 논블로킹은 사실 동기인 경우를 가정하여 설명한 것이다.
1) Sync+Blocking
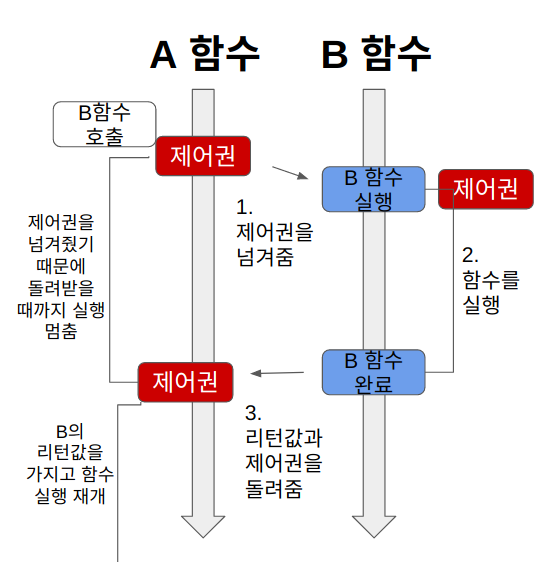
함수 A는 함수 B의 리턴값을 필요로 한다(동기). 그래서 제어권을 함수 B에게 넘겨주고, 함수 B가 실행을 완료하여 리턴값과 제어권을 돌려줄때까지 기다린다(블로킹).
2) Sync+Non_Blocking
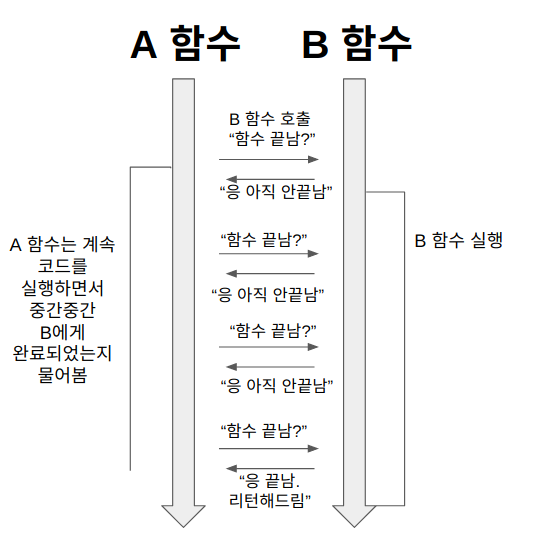
A 함수는 B 함수를 호출한다. 이때 A함수는 B함수에게 제어권을 주지 않고, 자신의 코드를 계속 실행한다(논블로킹).
그런데 A함수는 B함수의 리턴값이 필요하기 때문에, 중간중간 B함수에게 함수 실행을 완료했는지 물어본다(동기).
3) Async+Blocking
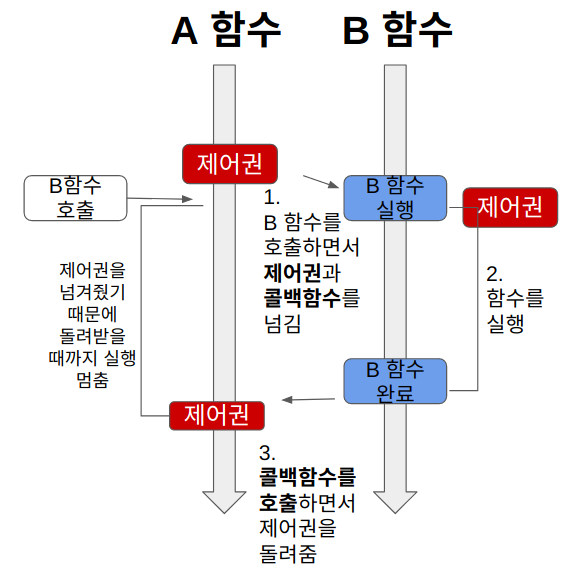
A함수는 B함수의 리턴값에 신경쓰지 않고, 콜백함수를 보낸다(비동기)
근데, B함수의 작업에 관심없음에도 불구하고, A함수는 B함수에게 제어권을 넘긴다(블로킹).
그래서, A함수는 관련없는 B함수의 작업이 끝날 때까지 기다려야 된다.
4) Async+Non_Blocking
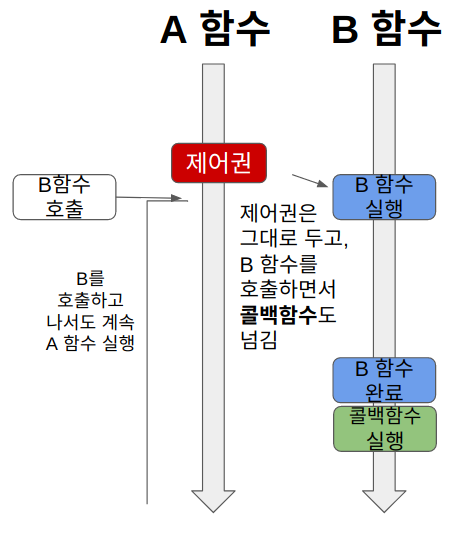
A함수가 B함수를 호출한다. 제어권은 B함수에게 주지 않고, 자신이 계속 가지고 있는다(논블로킹).
따라서 B함수를 호출한 이후에도 멈추지 않고 자신의 코드를 계속 실행한다.
그리고 B함수를 호출할 때 콜백함수를 함께 준다. B함수는 자신의 작업이 끝나면 A함수가 준 콜백 함수를 실행한다(비동기).
네트워크
HTTP
HTTP(Hyper Text Transfer Protocol)란 데이터를 주고 받기 위한 프로토콜이며, 서버/클라이언트 모델을 따른다.
HTTP는 상태 정보를 저장하지 않는 Stateless의 특징과 클라이언트의 요청에 맞는 응답을 보낸 후 연결을 끊는 Connectionless의 특징을 가지고 있다.
HTTP 메서드
GET - 데이터 조회
조회할 때 POST도 사용할 수 있지만, GET 메서드는 캐싱이 가능하기에 GET을 사용하는 것이 유리하다.
바디를 가질 수 없음. 쿼리스트링을 통해서 데이터를 전달한다
POST - 요청 데이터 처리, 주로 등록에 사용된다.
PUT - 리소스를 대체(덮어쓰기), 해당 리소스가 없으면 생성
PATCH - 리소스를 부분 변경 (PUT이 전체 변경, PATCH는 일부 변경)
DELETE - 리소스 삭제
GET은 URL에 데이터가 노출되므로 보안적으로 중요한 데이터를 포함해서는 안된다.
POST가 완전히 안전하다는 것은 아니지만, URL에 데이터가 노출되지 않아 GET보다는 안전하다.
HTTPS
HTTP는 평문 데이터를 전송하는 프로토콜이기 때문에, HTTP로 중요한 정보를 주고 받으면 제 3자에 의해 조회될 수 있다.
이러한 문제를 해결하기 위해 HTTP에 암호화가 추가된 프로토콜이 HTTPS이다.
HTTPS는 SSL의 껍질을 덮어쓴 HTTP라고 할 수 있다.
SSL(Secure Socket Layer) - 인터넷을 통해 전달되는 정보를 보호하기 위해 개발한 통신 규약
HTTP는 원래 TCP와 직접 통신했지만, HTTPS에서 SSL과 통신하고, SSL이 TCP와 통신함으로써 암호화와 증명서, 안전성 보호를 이용할 수 있게 된다.
www.naver.com에 접속하는 과정
1) 사용자가 브라우저에 URL을 입력한다.
2) DNS 서버에 도메인 네임으로 서버의 진짜 주소(IP)를 찾는다.
3) 찾은 IP 주소로 웹 서버에 TCP 3 handshake로 연결을 수립한다.
4) 클라이언트는 웹 서버로 HTTP 요청 메시지를 보낸다.
5) 웹 서버는 HTTP 응답 메시지를 보낸다.
6) 도착한 HTTP 응답 메시지는 웹 페이지 데이터로 변환되고, 웹 브라우저에 의해 출력된다.
TCP와 UDP
TCP와 UDP는 데이터를 보내기 위해 사용하는 프로토콜이다.
TCP
1) 연결 지향 방식으로 패킷 교환 방식을 사용한다.
2) 3-way handshaking 과정을 통해 연결을 설정하고 4-way handshaking을 통해 해제된다.
3) 높은 신뢰성을 보장한다.
4) UDP보다 속도가 느리다.
5) 전송 순서를 보장한다.
6) 수신 여부를 확인한다.
UDP
1) 비연결형 서비스이다.
2) 3-way handshaking 과정을 통해 연결을 설정하고 해제하는 과정이 존재하지 않는다.
3) UDP헤더의 CheckSum 필드를 통해 최소한의 오류만 검출한다.
4) 신뢰성이 낮다.
5) TCP보다 속도가 빠르다.
6) 전송 순서를 보장하지 않는다.
7) 수신 여부를 확인하지 않는다.
TCP 연결 및 연결 해제 과정
연결 3-way HandShaking
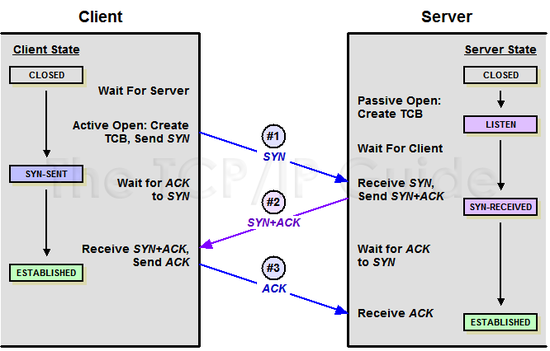
#1. Client -> Server : 들림?
#2. Server -> Client : 잘 들림 내 말은 들리나?
#3. Client -> Server : 잘 들림
SYN(synchronize sequence numbers) - 연결 확인을 보내는 무작위의 숫자 값
ACK(acknowledgements) - 클라이언트 혹은 서버로부터 받은 SYN에 1을 더해 SYN을 잘 받았다는 ACK
1) 클라이언트가 SYN를 보내고 SYN_SENT 상태로 대기한다.
2) 서버는 SYN_RECEIVED 상태로 바꾸고 SYN과 응답 ACK을 보낸다.
3) SYN과 응답 ACK를 받은 클라이언트는 ESTABLISHED 상태로 변경하고 서버에게 응답 ACK를 보낸다.
4) 응답 ACK를 받은 서버는 ESTABLISHED 상태로 변경한다.
해제 4-way HandShaking
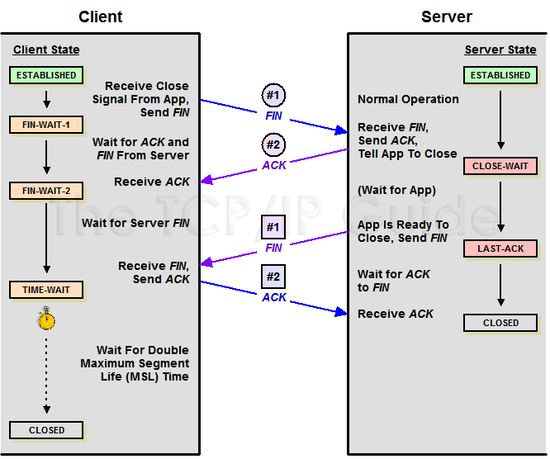
#1. Client -> Server : 다 보냄 끊자
#2. Server -> Client : ㅇㅋ
#3. Server -> Client : 나도 끊을게
#4. Client -> Server : ㅇㅋㅇㅋ
1) 데이터를 다 보낸 클라이언트가 FIN(연결 끊음)을 보내고 FIN-WAIT-1 상태로 대기한다.
2) 서버는 CLOSE_WAIT로 바꾸고 응답 ACK를 전달한다. 동시에 해당 포트에 연결되어 있는 애플리케이션에게 close를 요청한다.
3) ACK를 받은 클라이언트는 상태를 FIN-WAIT-2로 변경한다.
4) close 요청을 받은 서버 애플리케이션은 종료 프로세스를 진행하고 FIN을 클라이언트로 보낸 LAST_ACK 상태로 바꾼다.
5) FIN을 받은 클라이언트는 ACK를 서버에 다시 전송하고 TIME-WAIT로 상태를 바꾼다.
TIME-WAIT에서 일정 시간이 지나면 CLOSE된다. ACK를 받은 서버도 포트를 CLOSED로 바꾼다.
OSI 7계층
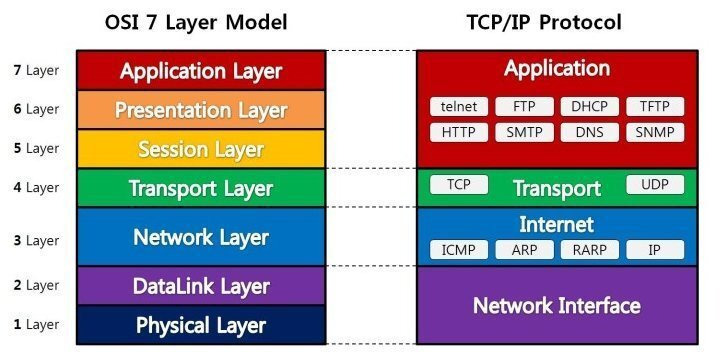
7계층(응용 계층) - 사용자에게 통신을 위한 서비스 제공. 인터페이스 역할을 한다.
6계층(표현 계층) - 데이터의 형식을 정의하는 계층 (코드 간의 번역을 담당)
5계층(세션 계층) - 컴퓨터끼리 통신을 하기 위해 세션을 만드는 계층
4계층(전송 계층) - 최종 수신 프로세스로 데이터의 전송을 담당하는 계층(TCP, UDP)
3계층(네트워크 계층) - 패킷을 목적지까지 가장 빠른 길로 전송하기 위한 계층(Router)
2계층(데이터링크 계층) - 데이터의 물리적인 전송과 에러 검출, 흐름 제어를 담당하는 계층(이더넷)
1계층(물리 계층) - 데이터를 전기 신호로 바꾸어주는 계층(케이블, 리피터, 허브)
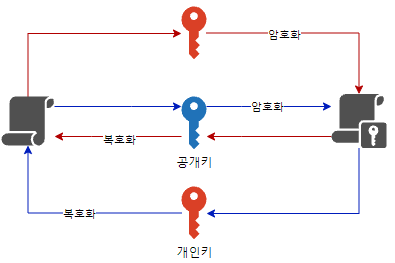
대칭키와 비대칭키 암호화
대칭키와 비대칭키는 양방향 암호화 방식이다.
대칭키
대칭키는 암호화와 복호화에 같은 암호 키를 쓰는 알고리즘이다.
이는 중간에 누군가 암호 키를 가로채면 암호화된 정보가 유츌될 수 있다는 단점이 있는데, 이런 문제를 보완한 새로운 방식이 비대칭키(공개키)이다.

비대칭키
암호화와 복호화에 서로 다른 키를 사용하는 암호화 알고리즘이다.
타인에게 노출되어서는 안되는 개인키(Private Key)와 공개적으로 개방되어 있는 공개키(Public Key)를 쌍으로 이룬 형태이다.
부인방지 기능
보내는 사람이 자신의 Private Key로 데이터 암호화해서 PublicKey와 함께 보내면 받는 사람이 암호화된 문서를 PublicKey로 복호화 한다.
보낸 사람은 자신이 보낸게 아니라고 부인할 수 없다.
기밀성 보장
보내는 사람이 받는 사람의 PublicKey로 암호화 해서 보내면 받는 사람은 자신의 PrivateKey로 복호화한다.
이때는 이걸 받는 사람 외에는 문서를 열 수 없음
Connection Timeout과 Read Timeout
서버 자체에 클라이언트가 어떤 사유로 접근을 실패했을 시 적용되는 것이 Connection Timeout이다.
즉, 접근을 시도하는 시간 제한이 Connection Timeout 되는 것을 말한다.
클라이언트가 서버에 접속을 성공 했으나 서버가 로직을 수행하는 시간이 너무 길어 제대로 응답을 못 준 상태에서 클라이언트가 연결을 해제하는 것이 Read Timeout이다.
이 경우는 클라이언트는 해당 상황을 오류로 인지하고, 서버는 계속 로직을 수행하고 있어 성공으로 인지해 양 사이드 간 싱크가 맞지 않아 문제가 발생할 확률이 높다.
공인 IP와 사설 IP의 차이
공인 IP는 ISP(인터넷 서비스 공급자)가 제공하는 IP주소이며, 외부에 공개되어 있는 IP주소이다.
공인 IP는 전세계에서 유일한 IP 주소를 갖는다.
공인 IP 주소가 외부에 공개되어 있기에 인터넷에 연결된 다른 PC로부터의 접근이 가능하다. 따라서 공인 IP주소를 사용하는 경우에는 방화벽 등의 보안 프로그램을 설치할 필요가 없다.
사설 IP는 일반 가정이나 회사 내에 할당된 네트워크 IP주소이며, IPv4 주소 부족으로 인해 서브넷팅 된 IP이기 때문에 라우터(공유기)에 의해 로컬 네트워크 상의 PC나 장치에 할당된다.
사설 IP 주소는 주소대역으로 고정되어 있다.
Class A : 10.0.0.0 ~ 10.255.255.255
Class B : 172.16.0.0 ~ 172.31.255.255
Class C : 192.168.0.0 ~ 192.168.255.255
사설 IP 주소만으로는 인터넷에 직접 연결할 수 없고, 라우터를 통해 1개의 공인 IP를 할당하고, 라우터에 연결된 개인 PC는 사설 IP를 각각 할당 받아 인터넷에 접속할 수 있다.
💻➡🌏 : 사설 IP를 할당받은 스마트폰 혹은 개인 PC가 데이터 패킷을 인터넷으로 전송하면, 라우터(공유기)가 해당 사설 IP를 공인 IP로 바꿔서 전송한다.
🌏➡💻 : 인터넷에서 오는 데이터 패킷의 목적지도 해당하는 사설 IP로 변경한 후 개인 스마트폰 혹은 PC에 전송한다.
인터넷 상에서 서버를 운영하고자 할 때는 공인 IP를 고정 IP로 부여해야 한다.
공인 IP를 부여받지 못하면 다른 사람이 내 서버에 접속할 수 없고, 고정 IP를 부여하지 않으면 내 서버가 아닌 다른 사람의 서버로 접속이 될 수도 있기 때문이다.
집에서 사용하는 인터넷 서비스 업체는 각 가정마다 공인 IP를 유동 IP로 부여하고, 공유기 내부에서는 사설 IP를 유동 IP로 부여하는 것이 일반적이다.
Restful API
RESTful은 자원을 이름으로 구분해 해당 자원의 상태를 주고 받는 모든 것을 의미하는 REST의 설계 규칙을 잘 지켜서 설계된 API를 RESTful한 API라고 한다.
Rest
자원을 이름으로 구분해 해당 자원의 상태를 주고 받는 모든 것을 의미한다.
Rest의 구성요소
1) 자원 - URI
모든 자원에는 고유한 ID가 존재하고, 이 자원은 Server에 존재한다.
자원을 구별하는 ID는 '/example?exampleId=1'와 같은 HTTP URI이다.
2) 행위 - Method
HTTP 프로토콜을 GET, POST, PUT, PATCH, DELETE의 Method를 제공한다.
3) 표현 - Representation of Resource
Client와 Server가 데이터를 주고받는 형태로 JSON, XML등이 있다.
Rest API
REST의 특징을 기반으로 서비스 API를 구현한 것
REST API의 가장 큰 특징은 각 요청이 어떤 동작이나 정보를 위한 것인지를 그 요청의 모습 자체로 추론이 가능한 것이다.
Rest API 설계 규칙
1) URI는 명사를 사용한다.
2) 슬래시(/)로 계층 관계를 표현한다.
3) URI 마지막 문자로 슬래시(/)를 포함하지 않는다.
4) 밑줄( _ )을 사용하지 않고, 하이픈(-)을 사용한다.
5) URI는 소문자로만 구성된다.
Call By Value와 Call By Reference의 차이
Call By Value(값에 의한 호출)
인자로 받은 값을 복사하여 처리하는 방식이다.
장점 - 값을 복사하여 처리하기 때문에 원래의 값이 보존된다.
단점 - 복사하기 때문에 메모리 사용량이 증가한다.
Call By Reference(참조에 의한 호출)
인자로 받은 값의 주소를 참조하여 직접 저장해 값에 영향을 주는 방식이다.
장점 - 복사하지 않고 직접 참조하기에 빠르다.
단점 - 직접 참조를 하기에 원래의 값이 영향을 받는다.
자바는 기본적으로 모든 전달 방식이 Call By Value이다.
나도 Call By Reference라고 생각했다.
근데 "주소값"이 아닌 "주소를 가리키는 참조값"이다.
주소값 자체를 "복사 없이" 인자로 전달하는게 아니라 자기 자신이 갖고 잇는 값을 복사해서 전달한다.
CORS
CORS란 도메인이 서로 다른 2개의 사이트가 데이터를 주고 받을 때 발생하는 문제이다.
예를 들어 domainA.com과 domainB.com이 데이터를 주고받을 시 따로 설정하지 않으면 CORS 에러를 마나게 된다.
브라우저는 보안 상의 이유로, 스크립트에서 시작한 교차 출처 HTTP 요청을 제한한다.
다른 서버의 리소스를 불러오기 위해서는, 그 출처에서 CORS에 대한 내용을 Response의 헤더에 추가해줘야 된다.
1) Access-Control-Allow-Origin - 요청을 보내는 페이지의 출처(도메인) Defaul: null
2) Access-Control-Allow-Methods - 요청을 허용하는 메서드 Default: GET, POST
3) Access-Control-Allow-Headers - 요청을 허용하는 헤더
절차지향 VS 객체지향
절차지향 프로그래밍
기능중심으로 바라보는 방식으로 "무엇을 어떤 절차로 할 것인가?"가 핵심이 되며, 어떤 기능을 어떤 순서로 처리하는가에 대해 초점을 맞춘다. 대표적으로 C언어가 있다.
객체지향 프로그래밍
기능이 아닌 객체 중심으로 바라보는 방식으로 "누가 어떤 일을 할 것인가?"가 핵심이며, 객체를 도출하고 각각의 역할을 정의해 나가는 것에 초점을 둔다. 대표적으로 Java가 있다.
절차지향 언어가 컴퓨터의 처리구조와 유사해 실행속도가 더 빠르고, 객체지향 언어는 절차지향 언어보다 실행속도가 느리다.
동적쿼리
동적 쿼리란 실행시에 특정 조건이나 실행에 따라 쿼리 문장이 변경되어 실행되는 쿼리문을 말한다.
컴파일시에 SQL문장을 확장할 수 없는 경우에 사용된다. 실행 시점에 따라 where절에 조건이 달라질 때 사용된다.
CSRF
사이트 간 요청 위조의 약자로 웹 애플리케이션 취약점 중 하나로 공격자가 의도한대로 사용자가 행동하게 하여 특정 웹페이지를 보안에 취약하게 한다거나 수정, 삭제 등의 작업을 하게 만드는 공격 방법을 의미한다.
1) 사용자의 요청에 referrer를 확인하여 도메인이 일치하는지 확인하는 방법으로 공격을 방어
요청 헤더에서 referrer 정보를 확인할 수 있다. (같은 도메인에서 들어오는 접속은 허용하나 다른 도메인에서 호출할 때는 차단하는 개념이다)
2) 상탤글 변화시키는 POST, PUT등의 요청에 대해 csrf 토큰이 포함되어야만 요청을 처리하여 공격을 방어
<img src="http://auction.com/changeUserAcoount?id=admin&password=admin" width="0" height="0">이미지를 누르면 저 src안에 있는 주소로 요청이 날라가게됨
REST API를 이용한 서버라면, session 기반 인증과는 다르게 stateless하기 때문에 서버에 인증정보를 보관하지 않는다. REST API에서 Client는 권한이 필요한 요청을 하기 위해서는 요청에 필요한 인증 정보(JWT)를 포함시켜야 된다.
따라서 서버에 인증정보를 저장하지 않기 때문에 굳이 불필요한 csrf 코드들을 작성할 필요가 없다.
TDD(Test-Driven-Development)
TDD란 작은 단위의 테스트 케이스를 작성하고 그에 맞는 코드를 작성하여 테스트를 통과한 후에 상황에 맞게 리팩토링 하는 테스트 주도 개발 방식을 말한다.
TDD 사이클
1) Red - 어떠한 기능을 검증하는 테스트가 실패하는 코드를 작성하고, 실제로 실패하는지 확인한다.
2) Green - 어떠한 기능을 검증하는 테스트가 통과하는 코드를 작성하고, 실제로 성공하는지 확인한다.
3) Refactor - 앞에 실패하는 테스트와 성공하는 테스트를 모두 검증했다면, 작성한 코드를 꺠끗하고 가독성 좋게 고친다.
4) Repeat - 이 세가지 과정을 반복하여 프로그램을 완성한다.
TDD를 하는 이유
1) 기능의 추가, 변경, 삭제로 인한 영향도를 쉽게 파악 가능
2) 예상하지 못한 오류에 대한 피드백을 위해
3) 좋은 설계로 작성되게끔 코드를 유도
DDD(Domain-Driven-Design)
Domain이란 영역 또는 집합이다.
객체와 도메인의 차이
"고양이는 사과를 먹는다."
객체의 관점에서는 "고양이"와 "사과"를 표현할 수 있고, "먹는다."는 객체가 하는 행위이다.
도메인의 관점에서는 "고양이","사과","먹는다","고양이는 사과를 먹는다." 모두 각각 도메인이라고 할 수 있다.
객체는 현실 그대로를 표현하고 있고, 도메인은 사용자가 바라보는 관점에 따라 각각을 구분하거나 전체라고 할 수 있다.
1) 표현 계층(Presentation Layer) - 사용자의 요청에 대해 해석하고 응답하는 일을 책임지는 계층(Controller)
Client로부터 Request를 받고 Response를 return 하는 API 정의
2) 응용 계층(Application Layer) - 비즈니스 로직을 정의하고 정상적으로 수행될 수 있도록 도메인 계층과 인프라스트럭처 계층을 연결해주는 역할을 하는 계층(Service)
Transaction 관리, DTO 변환, 모듈간의 연계를 진행
3) 도메인 계층(Domain Layer) - 비즈니스 규칙, 정보에 대한 실질적인 도메인에 대한 정보를 가지고 있으며 이 모든것을 책임지는 계층 (Entity)
Entity를 활용하여 도메인 로직이 진행된다.
4) 인프라스트럭처 계층(Infrastructure Layer) - 외부와의 통신(ORM, DB, NoSQL)을 담당하는 계층 (Repository)
해당 계층에서 얻어온 정보를 응용 계층 또는 도메인 계층에 전달하는 것을 주 역할로 담당
