Spring Framework
스프링 프레임워크는 자바 개발을 편리하게 해주는 오픈소스 프레임워크이다.
- 경량 컨테이너로서 자바 객체를 직접 관리
- 각각의 객체 생성, 소멸과 같은 라이프 사이클을 관리하며 스프링으로부터 필요한 객체를 얻어올 수 있다.
- 제어의 역전(IoC)이라는 기술을 통해 어플리케이션의 느슨한 결합을 도모
- 사용할 객체를 직접 생성하지 않고, 객체의 생명주기 관리를 스프링 컨테이너(IoC 컨테이너)에 위임
IoC란 모든 객체의 생성, 라이프사이클 등의 제어권을 개발자가 아닌 스프링 컨테이너에게 넘기는 것을 말한다.
스프링이 스프링 컨테이너에 등록된 객체끼리 의존성을 주입(DI)하는 역할을 한다.
- 의존성 주입(DI)을 지원
- 제어의 역전 방법 중의 하나로, 사용할 객체를 직접 생성하지 않고 스프링 컨테이너에 등록된 객체를 주입받아 사용하는 방식을 말한다.
의존성 주입을 통해 객체간의 결합도를 줄이고 코드의 재사용성을 높일 수 있다.
빈 등록 시, 필요한 의존성들은 빈 생성 시점에 미리 주입된다.
@Autowired를 붙이면 IoC 컨테이너에서 관리하는 빈을 자동으로 주입해주는 역할을 한다.
기본적으로 타입을 기준으로 매핑하여 빈을 찾는다.
의존성 주입 방법 - 생성자를 통한 의존성 주입, 필드 객체 선언을 통한 의존성 주입, Setter를 통한 의존성 주입
스프링에서 가장 권장하는 방법은 생성자를 통한 의존성 주입이다. 그 이유는 1. 순환 참조를 방지 2. 불변성을 가짐 3. 테스트에 용이하기 때문이다.
@RequiredArgsConstructor 어노테이션을 사용한 생성자 주입 방법도 있다.
생성자 코드를 만들지 않고도 롬복을 사용하여 간단하게 생성자 주입 방식의 코딩을 할 수 있다.
final 키워드나 @NotNull이 붙은 필드의 생성자를 자동 생성해주는 것이다.
@RequiredArgsConstructor 주의할점
테스트 환경에서 @RequiredArgsConstructor로 생성된 생성자를 직접 호출하려면, 필요한 의존성을 모두 제공해야 된다. 테스트에서 Mock 객체를 생성하여 생성자에 전달하거나, @MockBean과 같은 테스트용 어노테이션을 활용하여 해결하면 된다.
- 관점 지향 프로그래밍(AOP)을 지원
- 관점을 기준으로 묶어서 개발하는 방식을 의미하며 AOP를 사용하면 부가 기능의 코드 중복을 줄이고, 유지보수성을 높일 수 있다.
프레임워크와 라이브러리의 차이 - 제어의 흐름(코드를 호출하는 주체)
프레임워크는 제어의 흐름을 프레임워크가 주도한다. 하지만 라이브러리는 제어의 흐름을 개발자가 주도한다.
프레임워크 - 프로그램을 개발하기 위해 사용되는 틀을 제공하는 프로그램 (기본적인 틀이 제공되기 때문에 효율적이다. 시간 절약 가능)
라이브러리 - 특정 기능을 개발하기 위해 필요한 것들을 다른 개발자가 미리 구현한 도구 또는 함수들의 집합
Spring Boot와 Spring Framework의 차이
가장 큰 차이점은 Auto Configuration의 차이인 것 같다. Spring은 프로젝트 초기에 다양한 환경설정을 해야 하지만, Spring Boot는 설정의 많은 부분을 자동화하여 사용자가 편하게 스프링을 활용할 수 있도록 돕는다.
Spring Boot Starter Dependency만 추가해주면 설정은 끝나고, 내장된 톰캣을 제공해 서버를 바로 실행할 수 있다.
Spring Boot 2 -> 3
주요 차이점
1) Java 버전 요구사항
Spring Boot 2.x - 최소 Java 8을 요구하며, 일부 기능은 Java 11을 지원
Spring Boot 3.x - 최소 Java 17을 요구한다. 최신 Java 기능을 활용하여 성능과 보안이 개선된 애플리케이션을 개발할 수 있게 된다.
2) Jakarta EE로 전환
Spring Boot 2.x - Java EE 8을 기반으로 한다.
Spring Boot 3.x - Jakarta EE 9 이상으로 전환되었다. 패키지 이름 또한 javax에서 jakarta로 변경되었다.
3) 성능 및 최적화
Spring Boot 2.x - 전통적인 JVM 기반 애플리케이션 성능 최적화를 제공
Spring Boot 3.x - AOT 컴파일과 GraalVM 네이티브 이미지를 통해 성능 최적화가 이루어졌다. 이로 인해 애플리케이션의 메모리 사용량이 줄어들고, 시작 시간이 단축 되었다.
AOT 컴파일러 - 실행 전에 바이트코드를 기계어로 변환하여 배포하여 실행 시점의 컴파일 지연을 없애고 성능을 개선함
GraalVM - Oracle이 만든 JVM과 JDK로 애플리케이션 성능과 효율성의 향상을 제공하는 고성능 런타임이다.
GraalVM이 Java 애플리케이션을 더 빠르고 효율적으로 실행하기 위해 AOT 컴파일러를 활용할 수 있는 도구와 기능을 제공한다.
WS와 WAS
Web Server(WS)는 정적인 웹 리소스를 서비스하는데 특화된 서버 소프트웨어를 의미한다.
웹 서버는 클라이언트의 HTTP 요청을 받아 해당 요청에 맞는 정적 컨텐츠를 반환한다.
웹 서버는 주로 웹 애플리케이션의 비즈니스 로직을 처리하지 않고, 단순히 클라이언트에게 정적인 웹 페이지를 제공하는데 사용된다.
웹 서버는 리버스 프록시로 동작하여 클라이언트의 요청을 웹 애플리케이션 서버(WAS)로 전달하는 역할을 할 수 있다.
* 리버스 프록시 - 클라이언트가 인터넷에 데이터를 요청하면 리버스 프록시가 이 요청을 대신 받아서 서버와 통신 하고 클라이언트에 전달
Web Application Server(WAS)는 클라이언트의 요청에 따라 동적인 웹 페이지를 생성하고 데이터베이스와의 상호작용, 트랜잭션 처리, 보안, 세션 관리 등 웹 애플리케이션의 핵심 비즈니스 로직을 수행하는 역할을 담당한다.
Spring Boot는 빌드시 내장된 Tomcat으로 Was를 실행하고 ServletContiner에 Spring의 DispatcherServlet을 등록한다.
WAS는 특정 포트에서 동작한다. 예를 들어 Spring 애플리케이션을 8080 포트로 실행하면, 해당 포트에서 WAS가 동작하게 된다.
서블릿(Servlet)
간단히 말해 서블릿은 자바를 사용하여 웹을 만들기 위해 필요한 기술이다.
클라이언트가 어떠한 요청을 하면 그에 대한 결과를 다시 전송해주어야 하는데, 이러한 역할을 하는 자바 프로그램이다. 이러한 웹 기반의 요청에 대해 동적으로 처리해주는 역할로서 Server Side에서 작동(WAS)한다.
Servlet의 특징
클라이언트의 요청에 대해 동적으로 작동하는 웹 애플리케이션 컴포넌트, MVC 패턴에서 Controller로 이용된다.
서블릿 컨테이너
서블릿은 요청을 받거나 내보낼 때, 자신이 알아서 하는 것이 아니라 서블릿을 실행시키는 주체인 서블릿 컨테이너라는 것을 이용한다.
즉, Servlet을 관리하는 Servlet Container는 어떤 요청에 대해 어떤 Servlet을 실행할 것인지 제어하는 것이다.
서블릿 컨테이너는 웹 서버가 전달한 요청을 받아서 적절한 서블릿을 사용해 요청을 처리합니다.
웹 서버로부터 전달된 HTTP 요청을 받아서 서블릿이 처리할 수 있는 형태로 바꿔준다.
대표적인 서블릿 컨테이너는 Tomcat이다.
JSP
서블릿은 자바 소스코드 속에 HTML 코드가 들어가 있는 형태인데, JSP는 반대로 HTML 소스코드 안에 자바 코드가 들어가는 구조를 갖는 웹 애플리케이션 프로그래밍 기술이다.
Dispatcher Servlet
클라이언트가 요청을 보내면, Sevlet Container가 요청을 받는다. 이때 제일 앞에서 서버로 들어오는 모든 요청을 처리하는 Front Controller라는 것을 Spring에서 정의하였고, 이를 Dispatcher Servlet이라고 한다.
Dispatcher Servlet이 애플리케이션에 들어오는 모든 요청을 핸들링 해주면서 공통 작업을 처리해주기 때문에 상당히 편리하게 이용할 수 있다.
Spring MVC
애플리케이션을 개발할 때 사용하는 디자인 패턴 중 하나로, 개발 영역을 Model, View, Controller로 구분하여 각 역할에 맞게 코드를 작성하는 개발 방식이다.
MVC를 사용하는 이유 - 각 컴포넌트가 서로 분리되어 각자의 역할에 집중할 수 있기 때문에 시스템 결합도를 낮출 수 있다. 또한, 유지보수가 쉬우며, 중복 코드를 제거할 수 있고, 애플리케이션의 확장성 및 유연성이 증가한다.
Model - 클라이언트에게 응답으로 돌려주는 작업의 처리 결과 데이터를 Model이라고 한다.
View - 화면에 보이는 리소스를 제공한다.
Controller - 클라이언트 측의 요청을 전달받아 비즈니스 로직을 거친 후, Model 데이터가 만들어지면 이 Model 데이터를 View로 전달하는 역할을 한다.
Spring MVC 구조의 요청 처리 순서
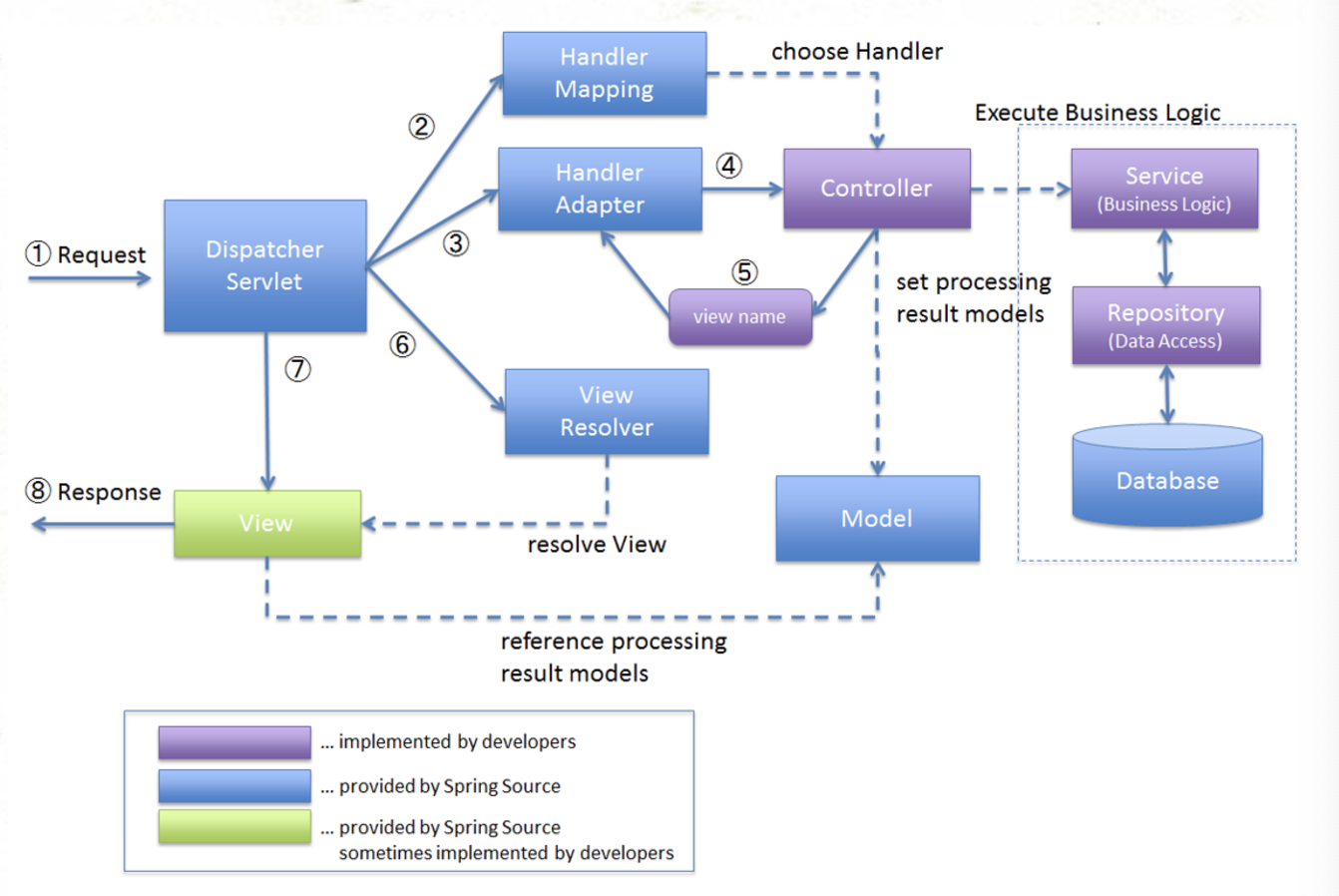
구성요소
- Dispatcher Servlet - 클라이언트의 요청을 전달받아 요청에 맞는 응답을 생성
- Handler Mapping - 클라이언트의 요청 URL을 어떤 컨트롤러가 처리할지 결정
- Hanlder Adapter - 위에서 결정한 Hanlder(Controller)를 호출
- Handler(Controller) - 클라이언트의 요청을 처리한 뒤 결과를 Dispatcher Servlet에 반환
- ModelAndView - 컨트롤러가 처리한 결과 정보 및 뷰 선택에 필요한 정보를 담음
- ViewResolver - 컨트롤러의 처리 결과를 생성할 뷰를 결정
- View - 컨트롤러의 처리 결과 화면을 생성(JSP, Thymleaf 등 사용)
처리 순서
- 클라이언트가 서버에 요청을 보내면 Dispatcher Servlet이 요청을 가로챈다.
- 들어온 요청을 Handler Mapping에 위임하여 해당 요청을 처리할 Hanlder(Controller)를 탐색한다.
- 해당 핸들러를 실행할 수 있는 핸들러 어댑터를 핸들러 어댑터 목록에서 찾는다.
- HandlerAdapter는 요청에 매핑된 Handler가 있다면 @RequestMapping 안에 있는 값(즉, URL 경로나 HTTP 메서드 정보)을 통해 요청을 처리할 특정 메서드를 찾는 것
- Controller -> Service -> Repository -> DB -> Repository -> Service -> Controller 순으로 로직이 진행
- 결과물을 받은 Controller는 필요에 따라 Model 객체에 결과물을 넣거나, View 정보를 담아 DispatcherServlet에 보낸다.
- DispatcherServlet은 ViewResolver에게 받은 뷰에 대한 정보를 넘긴다.
- ViewResolver는 해당 View를 찾아 DispatcherServlet에 알려준다.
- DispatcherServlet은 응답할 View에게 Render를 지시하고 View는 응답 로직을 처리한다.
- DispatcherServlet이 클라이언트에게 렌더링된 View를 응답한다.
만약 HTTP로 응답하는 경우에는 6번에서 JSON, XML 등으로 HTTP 응답을 만들고 DispatcherSevler에 이를 보낸다.
Spring Filter와 Interceptor
필터는 말 그대로 요청과 응답을 거른 뒤 정제하는 역할을 한다.
스프링 컨테이너가 아닌 톰캣에서 관리가 되는 것이고, 스프링 범위 밖에서 처리된다.
Dispatcher Servlet에 요청이 전달 되기 전/후에 URL 패턴에 맞는 모든 요청에 대해 부가 작업을 처리할 수 있는 기능을 제공한다.
Filter는 보안 및 인증/인가 관련 작업, 모든 요청에 대한 로깅 또는 검사, Spring과 분리되어야 하는 기능에 대해서 사용된다.
인터셉터는 요청에 대한 작업 전/후로 가로채 요청과 응답을 참조하거나 가공하는 역할을 한다.
필터와 달린 인터셉터는 스프링 컨텍스트에서 동작한다.
Dispatcher Servlet이 Controller를 호출하기 전/후에 인터셉터가 끼어들어 요청과 응답을 참조하거나 가공할 수 있는 기능을 제공
Interceptor는 세부적인 보안 및 인증/인가 공통 작업, API 호출에 대한 로깅 또는 검사, Controller로 넘겨주는 데이터의 가공에 대해서 사용된다.
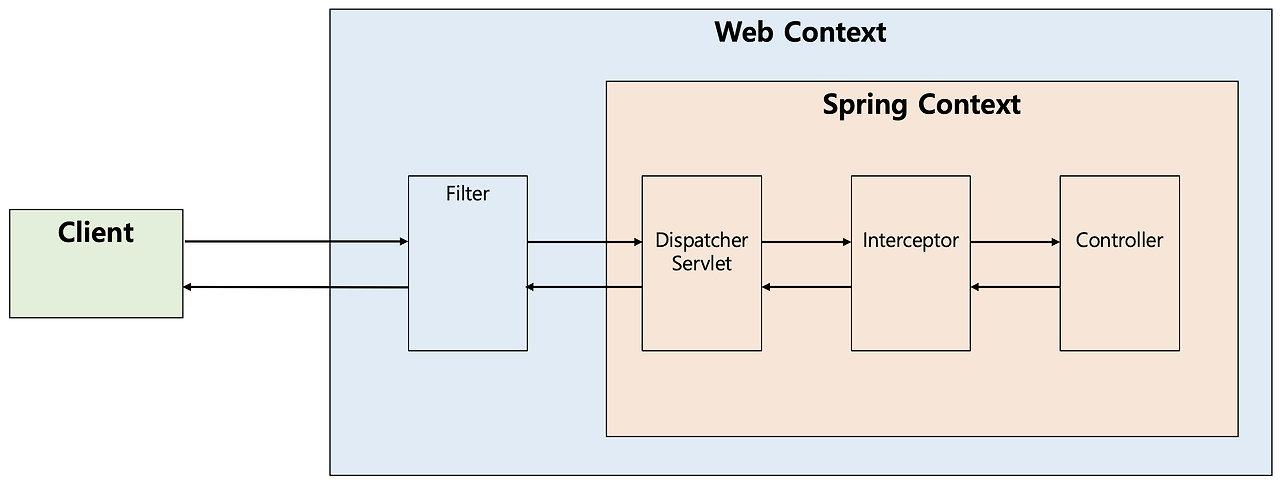
그림과 같이 실제로 Interceptor가 Controller에 요청을 위임하는 것은 아니다.
AOP와 Interceptor의 차이
AOP에서는 HttpServletRequest/Response 객체를 얻기 어렵지만 인터셉터에서는 파라미터로 넘어온다.
AOP (관점지향 프로그래밍)
AOP는 핵심 비즈니스 로직에 있는 공통 관심사항을 분리하여 각각을 모듈화 하는 것을 의미하며 공통 모듈인 인증, 로깅, 트랜잭션 처리에 용이하다.
핵심 비즈니스 로직에 부가기능을 하는 모듈이 중복되어 분포되어 있을 경우 사용할 수 있다.(예를 들어 요청에 대한 로깅)
AOP의 가장 큰 특징이자 장점은 중복 코드 제거, 재활용성의 극대화이다.
@Transactional
데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위로, 더이상 분할이 불가능한 명령들의 모임이다.
스프링에서는 @Transactional을 활용한 선언적 트랜잭션 관리와, 직접 트랜잭션 매니저를 이용해 트랜잭션 코드를 작성하는 프로그래밍 방식 트랜잭션 관리가 있다.
실제로는 두 가지 방법 중 대부분 @Transactional을 활용한 선언적 트랜잭션 관리를 사용한다.
프로그래밍 방식 트랜잭션 관리의 단점
트랜잭션의 일반적으로 1. 트랜잭션의 시작 2. 비즈니스 로직 3. 커밋/롤백 의 순서를 가진다.
여기에서 프로그래밍 방식 트랜잭션 관리는 2가지 문제가 있다.
- 개발자가 매번 트랜잭션과 관련된 로직을 작성해야된다.
- 비즈니스 로직과 트랜잭션과 관련된 코드가 분리되지 않는다.
@Transactional은 앞서 제시된 2가지 문제점을 Proxy 객체를 활용해 해결한다.
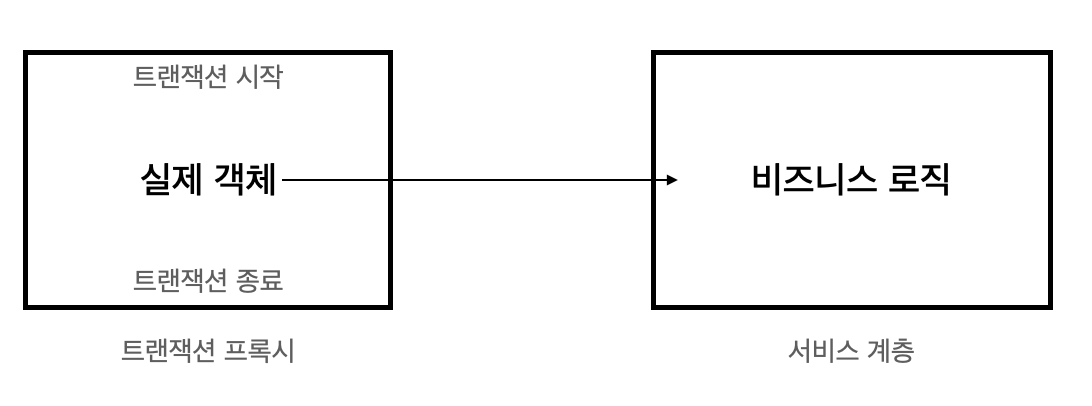
트랜잭션을 시작하고 종료하는 부분은 모두 프록시에서 실행되기 때문에, 서비스 계층은 순수한 비즈니스 로직 코드만을 유지할 수 있다.
프록시 객체란? 실제 Entity의 정보를 갖고 있는 가짜 Entity 객체
비즈니스 로직 코드의 실행은 프록시가 실제 대상 객체를 가지고 있기 때문에 호출되는 형태로 동작한다.
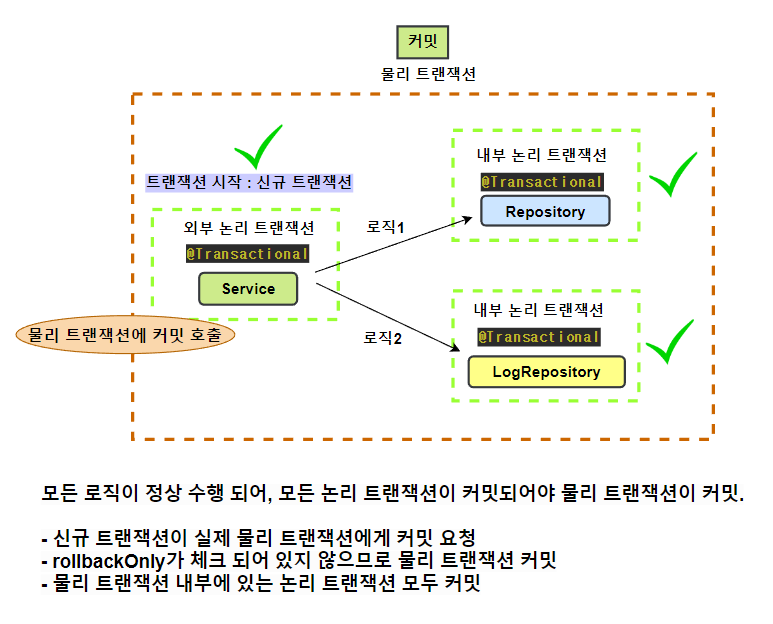
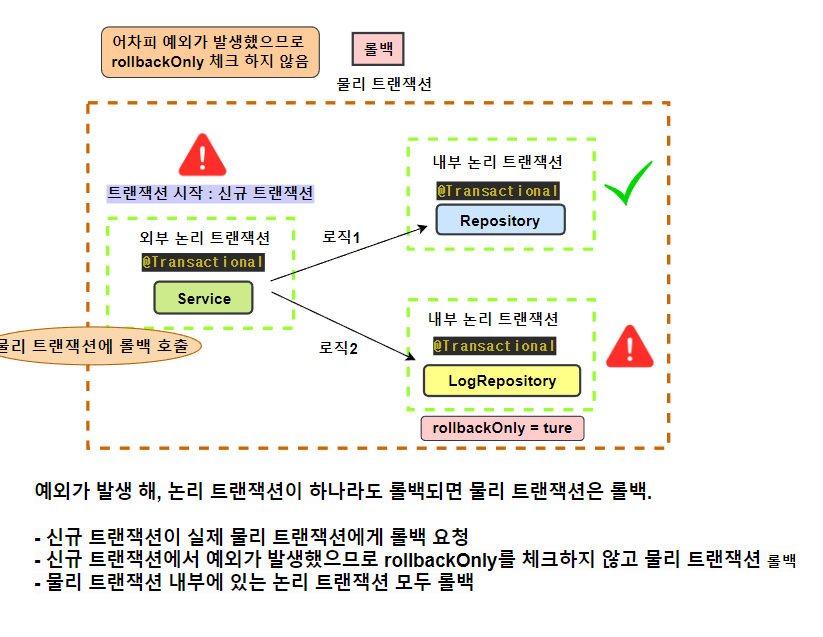
물리 트랜잭션 - 실제 데이터베이스에 적용되는 트랜잭션 실제 커넥션을 통해 트랜잭션이 시작하고, 실제 커넥션을 통해 커밋, 롤백하는 단위
논리 트랜잭션 - 트랜잭션 매니저를 통해 트랜잭션을 사용하는 단위
-
모든 로직이 정상 수행되었을 경우
-
논리 트랜잭션에서 예외가 발생했을 경우
@Transactional에 readOnly 속성을 사용하는 이유
트랜잭션 안에서 수정/삭제 작업이 아닌 readOnly 목적인 경우에 주로 사용되며, 영속성 컨텍스트에서 엔티티를 관리할 필요가 없기 때문에 readOnly를 추가하는 것으로 메모리 성능을 높일 수 있다.
또한, 데이터 변경 불가능 로직임을 코드로 표시할 수 있어 가독성이 높아진다는 장점이 있다.
영속성 컨텍스트
애플리케이션과 데이터베이스 사이에서 객체를 보관하는 가상의 데이터베이스 같은 역할을 한다.
앤티티 매니저는 Entity를 관리하는 역할을 한다.
영속성 컨텍스트는 엔티티 매니저를 생성할 때 하나 만들어진다.
엔티티 매니저를 통해서 영속성 컨텍스트에 접근하고 관리할 수 있다.
영속성 컨텍스트는 엔티티를 식별자 값으로 구분한다.
엔티티의 생명주기
1) 비영속 - 영속성 컨텍스트와 전혀 관계가 없는 상태 (엔티티 객체를 생성했지만 아직 영속성 컨텍스트에 저장되지 않은 상태)
2) 영속 - 영속성 컨텍스트에 저장된 상태
3) 준영속 - 영속성 컨텍스트에서 저장되었다가 분리된 상태
4) 삭제 - 삭제된 상태
영속성 컨텍스트의 장점
1) 1차 캐시 - 영속성 컨텍스트 내부에 캐시가 있다. DB에서 조회 전 식별자 값으로 캐시에서 우선 검색
2) 쓰기 지연 - 바로 값을 저장하는 것이 아닌 엔티티 매니저는 트랜잭션을 커밋하기 직전까지 내부 쿼리 저장소에 Insert SQL을 모아뒀다가 커밋할때 모아둔 쿼리를 DB에 보낸다.
쓰기 지연을 통해 생성한 엔티티의 값이 변경되면 변경된 값을 반영한 단일 Insert 쿼리가 실행된다.
성능 최적화와 일관성 유지를 위해 사용된다.
3) 변경감지(더티체킹) - 엔티티를 조회하면, JPA는 엔티티를 1차 캐시에 저장한다. 동시에 조회된 엔티티의 초기 상태(스냅샷)을 저장한다. 애플리케이션 코드에서 엔티티 필드 값을 변경하면, 커밋시 초기 스냅샷과 1차 캐시에 저장되어 있는 엔티티를 비교하여 엔티티가 변경됐다면 그 정보를 DB에 동기화한다.
변경감지는 영속 상태의 엔티티만 적용된다.
플러시란?
플러시는 영속성 컨텍스트의 변경 내용을 DB에 반영한다. 영속성 컨텍스트의 엔티티를 지우는게 아니라 변경 내용을 DB에 동기화하는 것이다.
Spring Data JPA는 JpaRepository를 사용하는 경우 내부적으로 EntityManager를 생성하고 관리한다.
Spring의 트랜잭션 관리 덕분에, JpaRepository 메서드를 호출하면 자동으로 EntityManager가 트랜잭션 범위 내에서 작동한다.
@Transactional로 선언된 메서드에서 EntityManager가 트랜잭션을 시작하고, 작업이 끝난 이후 트랜잭션을 커밋하거나 롤백한다.
JPA에서는 기본키 값을 변경할 수 없고, 기본키 값을 변경하고자 한다면 JDBCTemplate나 MyBatis등으로 변경해야된다.
스프링에서 Bean을 등록하는 방법
@Component가 붙으면 컴포넌트 스캔 대상이 된다.
-
@Component 어노테이션을 사용한다.
@Controller, @Service, @Repository, @Configuration은 모두 @Component를 포함하고있다. -
설정(Config) 클래스를 따로 만들어 @Configuration 어노테이션을 붙이고, 내부에서 빈으로 등록할 메서드를 만들어 @Bean 어노테이션을 붙여주면 자동으로 해당 리턴 타입의 빈 객체가 생성된다.
Component Scan
@Component를 가진 모든 대상을 가져와서 빈에 등록하기 위해 찾는 과정
@ComponentScan은 @Component가 붙은 모든 클래스를 스프링 빈으로 등록한다.
스프링 Bean의 라이프사이클
스프링 IoC 컨테이너 생성 -> 스프링 Bean 생성 -> 의존관계 주입 -> 초기화 콜백 메서드 호출 -> 사용 -> 소멸 전 콜백 메서드 호출 -> 스프링 종료
리플렉션
구체적인 클래스 타입을 알지 못해도 그 클래스의 메소드, 타입, 변수들을 접근할 수 있도록 해주는 자바 API이다.
컴파일 시점이 아닌 런타임에 동적으로 특정 클래스의 정보를 추출해낼 수 있는 프로그램 기법이다.
자바는 컴파일 시점에 타입을 결정하는 정적 언어인데, 동적으로 클래스를 사용해야 될 때 리플렉션이 사용된다.
즉, 작성 시점에는 어떤 클래스를 사용해야 할지 모르지만 런타임 시점에서 클래스를 실행해야 될 경우 사용된다.
대표적인 예시로, 스프링이 리플렉션을 이용해서 런타임 시점에 개발자가 등록한 빈을 어플레케이션에서 가져와 사용할 수 있도록 한다. DI에 사용된다.
리플렉션을 사용하면 클래스 정보, 필드, 몌서드, 생성자, 접근 제어자와 같은 다양한 정보들에 접근할 수 있다. 또한, 리플렉션으로 클래스가 가지고 있는 부모 클래스, 인터페이스와 같은 정보들에도 접근 가능하다.
DI가 낮은 결합도를 가지는 이유
직접 객체 생성
객체가 자신이 필요한 다른 객체를 직접 생성하면, 구체적인 클래스와 강하게 결합된다.
즉, A 객체가 B 객체를 사용하려면, A는 반드시 B의 구체적인 구현을 알아야 된다.
class ServiceA {
private ServiceB serviceB;
public ServiceA() {
this.serviceB = new ServiceB(); // ServiceA가 ServiceB를 직접 생성
}
public void doSomething() {
serviceB.doTask();
}
}DI
의존성 주입을 사용하면 객체가 필요한 의존성을 외부에서 주입받아 사용한다.
즉, A는 B의 구체적인 구현을 몰라도 동작할 수 있다.
class ServiceA {
private final ServiceBInterface serviceB;
// 의존성 주입: 생성자를 통해 주입
public ServiceA(ServiceBInterface serviceB) {
this.serviceB = serviceB;
}
public void doSomething() {
serviceB.doTask();
}
}예제
직접 객체 생성
내부 ServiceB만 갈아끼우지 못함 ServiceA 자체에서 수정 필요함
class Main {
public static void main(String[] args) {
ServiceA serviceA = new ServiceA(); // ServiceA는 ServiceB에 강하게 결합
serviceA.doSomething();
}
}의존성 주입
객체 생성시 전달하는 ServiceBInterface의 구현체만 변경하면 됨
class Main {
public static void main(String[] args) {
ServiceBInterface serviceB = new ServiceB(); // 구체적인 구현체는 외부에서 생성
ServiceA serviceA = new ServiceA(serviceB); // ServiceA는 인터페이스만 의존
serviceA.doSomething();
}
}DI의 장점
1) 유연성이 증가한다.
의존성을 쉽게 교체할 수 있어 다양한 구현체를 사용하거나 확장이 용이하다.
2) 테스트 용이성
Mock 객체를 중비하여 테스트할 수 있으므로 다누이 테스트 작성이 쉽다.
3) 단일 책임 원칙 준수
객체 생성과 사용 책임이 분리되므로 클래스의 책임이 명확해진다.
Spring의 싱글톤 패턴
스프링은 스프링 컨테이너를 통해 직접 싱글톤 객체를 생성하고 관리한다.
요청이 들어올 때마다 매번 객체를 생성하지 않고, 이미 만들어진 객체를 공유하기 때문에 효율적인 사용이 가능하다.
ORM, JPA, Hibernate
ORM
ORM이란 객체와 DB의 테이블이 매핑을 이루는 것을 의미한다. 즉, 객체가 테이블이 되도록 매핑 시켜주는 것을 말한다.
예를 들어 User 테이블의 데이터를 출력하기 위해서는 MySQL에서는 SELECT * FROM user; 라는 쿼리를 실행해야 하지만, ORM을 사용하면 User테이블과 매핑된 user라 할 때, user.findAll()이라는 메서드 호출로 데이터 조회가 가능하다.
query를 직접 작성하지 않고 메서드 호출만으로 query가 수행되다 보니, ORM을 사용하면 생산성이 매우 높아진다.
JPA
JPA란 자바 ORM 기술에 대한 API 표준 명세를 의미한다.
JPA는 ORM을 사용하기 위한 인터페이스를 모아둔 것이며, JPA를 사용하기 위해서는 JPA 구현체인 Hibernate, ElipseLink, DataNucleus같은 ORM 프레임워크를 사용해야 된다.
Mybatis
ORM 기술을 제공하는 JPA와는 다르게 SQL Mapper 기술을 제공하는 것이 Mybatis이다.
반복적인 JDBC 프로그래밍을 단순화하여, 불필요한 Boilerplate 코드를 제거하고, Java 코드에서 SQL문을 분리하여 별도의 XML파일에 SQL문을 작성하고, 이 둘을 서로 연결시켜주는 기능을 제공한다.
단점 - 유사한 CRUD SQL 반복 작업
Hibernate의 장/단점
- 장점
- 생산성 (SQL 반복 작업을 하지 않으므로 생산성이 매우 높다.)- 유지보수 (테이블 컬럼이 하나 변경 되었을 경우, 따로 수정 할 필요가 없음)
- 단점
- 성능 (메서드 호출로 쿼리를 실행한다는 것은 내부적으로 많은 동작을 하기 때문에 직접 쿼리를 작성하는 것보다 성능이 나오지 않음)- 세밀함 (객체간의 매핑이 잘못되거나 JPA를 잘못 사용하여 의도하지 않은 동작을 할 수도 있음)
JPA가 SQL을 작성하지 않는다고 해서 JDBC API를 사용하지 않는 것은 아니다.
Hibernate가 지원하는 메서드 내부에서는 JDBC API가 동작하고 있으며, 단지 개발자가 직접 SQL을 작성하지 않을 뿐이다.
- JPA 자체는 정적인 상황에서 사용하는 것을 권장하기 때문에 복잡한 쿼리와 동적인 쿼리에 대한 문제는 JPQL과 QueryDSL을 사용하는 것을 권장한다.
Save, SaveAll, Bulk Insert
10만건의 User 정보를 저장하는 테스트를 구현해서 시간이 얼마나 걸리나 보자.
Save
@Test
@DisplayName("Save")
public void save(){
long before = System.currentTimeMillis();
for(User user : userList){
userRepository.save(user);
}
System.out.println("Save 소요 시간 = " + String.valueOf(System.currentTimeMillis()-before));
}미리 만들어둔 10만건의 User 정보를 저장하는데 걸린 시간은 Save 소요 시간 = 1461 이다.
save() 메서드는 @Transactional로 감싸져 있어 프록시 기반 동작을 한다. 그렇기 때문에, 10만번의 save() 메서드가 호출될 때 불필요한 프록시 과정이 발생할 수 있다.
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (this.entityInformation.isNew(entity)) {
this.entityManager.persist(entity);
return entity;
} else {
return this.entityManager.merge(entity);
}
}saveAll()
@Test
@DisplayName("SaveAll")
public void saveAll(){
long before = System.currentTimeMillis();
userRepository.saveAll(userList);
System.out.println("SaveAll 소요 시간 = " + String.valueOf(System.currentTimeMillis()-before));
}SaveAll 소요 시간 = 63
save()보다 훨씬 빠르게 완료하는 것을 볼 수 있다.
@Transactional
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null");
List<S> result = new ArrayList();
Iterator var4 = entities.iterator();
while(var4.hasNext()) {
S entity = (Object)var4.next();
result.add(this.save(entity));
}
return result;
}saveAll()은 save()와 다르게 한 번의 트랜잭션을 생성하고, save()를 여러번 호출하여 같은 인스턴스에서 내부 호출을 하기 때문에 프록시 로직을 타지 않게 된다.
따라서 대량의 데이터를 insert 할 때는 save()보다는 saveAll()이 훨씬 효과적이다.
하지만 Save, SaveAll 모두 단건 삽입이다.
단건삽입?
Hibernate:
/* insert for com.example.testserver.Domain.User */
insert into user (name) values (?)
insert into user (name) values (?)
insert into user (name) values (?)Bulk 삽입
Hibernate:
/* insert for com.example.testserver.Domain.User */
insert into user (name)
values
(?),
(?),
(?),
(?)이렇게 여러 건의 삽입을 할 때 여러 개의 쿼리가 나가는게 단건 삽입이다.
하나의 쿼리로 나가는게 Bulk 삽입이다.
쿼리를 던지고 응답을 받은 뒤 다음 쿼리를 전달하기 때문에 Insert의 경우에는 지연이 많이 발생하짐나 하나의 트랜잭션으로 묶이는 Batch Insert는 하나의 쿼리문으로 수행되기 때문에 성능이 좋다.
MySQL에서 AutoIncrement를 사용한다면 대부분 Entity에서 IDENTITY 전략으로 PK 값을 자동으로 증가시켜 생성하는 방식을 사용한다.
하지만, 이 IDENTITY 방식을 사용하면 Batch Insert를 JPA에서 사용할 수 없다.
이유는 DB에 Insert가 되어야 id값을 알 수 있다는 JPA의 쓰기지연 특성 때문이다. 이 특징은 id값을 알아야 하는 Batch 특성과 출돌한다.
그래도 Spring JDBC를 이용하면 Batch Insert를 실행할 수 있다.
JdbcTemplate에는 Batch를 지원하는 batchUpdate() 메서드가 있는데, 이 메서드는 기본적으로 IDENTITY 컬럼의 값들을 반환하지 않기 때문이다.
url: jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=trueDB 설정에서 url 값 뒤에 /batch_test?rewriteBatchedStatements=true를 추가한다.
@Repository
@RequiredArgsConstructor
public class BulkInsertRepository {
private final JdbcTemplate jdbcTemplate;
public void bulkInsert(List<User> userList) {
String sql = "insert into User (name) values(?)"; // 테이블 이름 소문자 확인
jdbcTemplate.batchUpdate(sql,
userList,
userList.size(),
(PreparedStatement ps, User user) -> {
ps.setString(1, user.getName());
});
}
}@Test
@DisplayName("bulkInsert")
public void bulkInsert(){
long before = System.currentTimeMillis();
List<User> userList = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
User user = User.builder()
.name(String.valueOf(i))
.build();
userList.add(user);
}
BulkInsertRepository.bulkInsert(userList);
System.out.println("bulkInsert 소요 시간 = " + String.valueOf(System.currentTimeMillis()-before));
}bulkInsert 소요 시간 = 58
대규모 데이터를 삽입해야 할 경우에는 JPA를 사용하기 보다는 Bulk Insert를 사용하는 것이 더 좋은 것 같다.
JPA에서는 왜 BulkInsert를 지원하지 않는가
정확히는 JPA에서도 BulkInsert를 지원하고 있다.
하지만 PK가 IDENTITY인 경우. 즉, DB에서 자동으로 증가된 값으로 저장되는 AutoIncrement인 경우에는 사용이 제한된다.
IDENTITY 전략에서는 ID 값이 DB에 Insert 시점에 자동 생성된다.
하지만 BulkInsert는 여러 엔티티를 한 번에 저장하는 방식이므로 각 엔티티에 대해 개별적으로 ID 값을 설정하거나 확인할 수 없기 때문에 IDENTITY 전략과 호환되지 않는다.
IDENTITY 전략을 선택한 이유
IDENTITY 전략은 DB가 자동으로 ID 값을 생성하고 관리하기 때문에 개발자가 별도의 작업을 하지 않아도 된다.
특히, MySQL처럼 기본적으로 AutoIncrement를 지원하는 DB와 잘 맞아떨어져 간단히 사용할 수 있다.
SEQUENCE전략은 별도의 시퀀스 객체롤 생성해야 되고, 이 객체를 관리하는 비용이 있다.
SEQUENCE 전략은 주로 Oracle, PostgreSQL 같은 DB와 사용된다.
JPA N + 1 문제
N+1이란 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것을 의미한다.
해결 방법은 여러 방법이 있찌만 가장 많이 사용되는 방법은 Fetch Join 방법이다.
N+1 문제가 발생하는 이유는 연관관계를 가진 엔티티를 조회할 때 한 쪽 테이블만 조회하고 연결된 다른 테이블은 따로 조회하기 때문인데(1:N 관계에서 1을 조회할 때 발생), Fetch Join을 사용하면 미리 두 테이블을 Join하여 한 번에 모든 데이터를 가져오기 때문에 N+1 문제를 막을 수 있다.
또는 Batch Size를 사용하여 한 번의 쿼리로 여러개의 연관된 엔티티를 조회하는 방법도 있다.
DAO, DTO, VO
DAO
DAO는 Data Access Object의 약자로, DB의 데이터에 접근하기 위한 객체를 의미한다. DB에 접근하기 위한 로직을 분리하기 위해 사용한다. 직접 DB에 접근하여 데이터를 CRUD할 수 있는 기능을 수행한다.
MVC의 Model에 속한다.
Repository는 데이터 접근 뿐만 아니라, 도메인 모델을 다루는 비즈니스 로직과 연결될 수 있다.
이 말은 즉, 단순히 데이터를 가져오고 저장하는 역할을 넘어서 도메인 모델의 상태와 동작을 관리하고 비즈니스 요구사항에 맞는 데이터를 제공하는 역할을 한다는 뜻이다.
DAO와 Repository는 서로 다르며 둘 다 데이터베이스 접근을 캡슐화하는 역할을 한다.
DTO
DTO는 Data Transfer Object의 약자로, 계층 간 데이터 교환을 위한 Java Bean을 의미한다. DTO는 로직을 가지지 않는 데이터 객체이고 Getter, Setter 메서드만 가진 클래스를 의미한다.
- Spring에서는 Jackson2HttpMessageConverter를 사용하여 ObjectMapper Class의 함수인 readValue를 사용하여 요청의 body를 DTO로 변환한다.
VO
VO는 Value Object의 약자로, Read-Only 속성을 가진 값 오브젝트이다. 자바에서 단순히 값 타입을 표현하기 위하여 불변 클래스를 만들어 사용한다. 따라서 Getter 기능만 존재한다.
// VO 예시
public enum CommunityExceptionType implements ExceptionType {
COMMUNITY_NOT_FOUND(404, "글을 찾을 수 없습니다.");
private int errorCode;
private String errorMessage;
CommunityExceptionType(int errorCode, String errorMessage){
this.errorCode = errorCode;
this.errorMessage = errorMessage;
}
@Override
public int getErrorCode() { return errorCode; }
@Override
public String getErrorMessage() { return errorMessage; }
}RequestBody, RequestParam, PathVariable
@RequestBody
클라이언트가 전송하는 JSON 형태의 HTTP Body 내용을 MessageConverter를 통해 Java Object로 변환시키는 역할을 한다. (내부적으로 ObjectMapper를 사용하여 변환한다.)
@RequestParam
HTTP 요청에서 1개의 파라미터를 받기 위해 사용한다. @RequestParam은 필수 여부가 true이기 때문에, 반드시 해당 파라미터가 전송되어야 된다. 전송하지 않으면 400 Error가 발생한다.
만약, 반드시 필요한 변수가 아니라면 required의 값을 false로 설정해줘야 된다.
@PathVariable
URL 경로에서 변수 값을 추출하는 데 사용된다.
주로 RESTful 웹 서비스에서 사용자가 전달한 경로의 일부를 동적으로 추출하는데 사용된다.
예를 들어, user/{userId}와 값은 URL 패턴에서 {userId} 부분을 추출하여 매개변수로 사용한다.
PathVariable 여러개를 사용
@GetMapping("/test/{testId}/pass/{passId}")
public String test(@PathVariable int testId, @PathVariable int passId) {
return "testId=" + testId + ", passId=" + passId;
}ResponseEntity
ResponseEntity는 HttpEntity를 상속받아 구현된 클래스이다.
HttpEntity는 HTTP 요청 혹은 응답에 해당하는 HttpHeader와 HttpBody를 포함하는 클래스이다.
ResponseEntity는 HttpStatus, HttpHeaders, HttpBody를 포함한다.
주요 HTTP Status Code
1) 200 OK
요청이 성공적으로 완료됨
2) 201 Created
리소스 생성 요청이 성곰함
3) 204 No Content
요청에 대해서 보내줄 수 있는 컨텐츠가 없다. 하지만 헤더는 의미 있을 수 있다.
4) 400 Bad Request
잘못된 문법으로 인하여 서버가 요청을 이해할 수 없음을 의미
5) 401 Unauthorized
서버가 클라이언트가 누군지 모르는 상태. 즉, 로그인 되지 않은 사용자의 요청에 대한 응답
6) 403 Forbidden
401과는 다르게 서버가 클라이언트가 누군지는 알고있다. 하지만 접근 권한이 없음
7) 404 Not Found
서버가 요청받은 리소스를 찾지 못했다. 리소스 없음
8) 500 Internal Server Error
서버가 처리 방법을 모르는 상황이 발생했다. 서버 에러
어노테이션
프로그램에 추가적인 정보를 제공해주는 메타 데이터라고 볼 수 있다.
메타 데이터란 어플리케이션이 처리할 데이터가 아니라 컴파일 과정과 런타임에서 코드를 어떻게 컴파일하고 처리할 것인지에 대한 정보를 말한다.
어노테이션 자체가 동작을 수행하는 것이 아닌(코드의 동작에 직접적으로 영향을 주지 않는다.), 이를 기반으로 로직을 구현해야된다.
어노테이션은 옵션에 따라 컴파일 전까지만 유효하도록 처리될 수도 있고, 컴파일 시기에 처리될 수도 있고, 런타임 시기에 처리될 수도 있다.
1) 컴파일 전(RetentionPolicy.SOURCE)
어노테이션이 컴파일 시점까지만 유효하며, 컴파일 이후 클래스 파일에 포함되지 않는다.
주로 코드 가독성이나 문서화, IDE 지원을 위해 사용된다.
@Getter, @Setter, @Override가 여기에 포함된다.
2) 컴파일 시(RetentionPolicy.CLASS)
어노테이션이 클래스 파일에 포함되지만, 런타임 시에는 JVM이 읽지 않는다.
주로 컴파일러 플러그인이나 바이트코드 조작 도구에서 사용된다.
@Deprecated, @Generated가 여기에 포함된다.
3) 런타임(RetentionPolicy.RUNTIME)
어노테이션이 클래스 파일에 포함되며, 런타임 시 JVM에서 읽을 수 있다.
리플렉션을 통해 어노테이션 정보를 동적으로 분석하거나 활용한다.
@Entity, @RequestMapping, @Autowired가 여기에 포함된다.
Annotation 속성
1) @Target
Annotation이 어디에 위치할 수 있는지 제한한다.
2) @Retention
코드를 실행할 때 언제 이 Annotation이 없어질지 결정하는 meta-annotation이다.
3) @AliasFor(annotation = Component.class) String value() default "";
@Component의 value 속성과 연결
4) @Inherited
특정 어노테이션을 상속 가능하도록 만들 때 사용된다.
클래스 수준의 어노테이션에만 적용 가능하다. 메서드나 필드 수준의 어노테이션에는 적용되지 않는다. 인터페이스 사용해도 구현체에는 상속되지 않는다.
@Inherited
@Retention(value = RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface MyInheritedAnnotation {
}
@MyInheritedAnnotation
public class Parent {
// 커스텀 어노테이션을 사용하는 클래스
}
//여기에 @MyInheritedAnnotation가 있는 것과 같음
public class Child extends Parent {
// 커스텀 어노테이션을 사용하는 클래스를 상속 받음.
}리플렉션과 어노테이션
리플렉션으로 클래스가 가지고 있는 어노테이션 정보 또한 확인할 수 있다.
하지만, 리플렉션은 런타임에 정보를 가져오는 것이기 때문에 커스텀 어노테이션에 RetentionPolicy가 RUNTIME이어야 된다.
스프링은 리플렉션으로 @Autowired, @Qualifier, @Component와 같은 어노테이션을 확인하여 의존성을 주입한다.
커스텀 어노테이션
이름을 변수로 받는 Test 어노테이션을 만들어보자
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnnotation {
String name() default "";
}테스트
@TestAnnotation(name = "HIHI")
class CustomAnnotation{}
@Test
@DisplayName("Custom Annotation Test")
public void CustomAnnotationTest() {
Annotation[] annotations = CustomAnnotation.class.getAnnotations();
for(Annotation annotation : annotations) {
TestAnnotation testAnnotation = (TestAnnotation) annotation;
System.out.println(testAnnotation.name());
}
}커스텀 어노테이션 사용 이유
1) 코드의 가독성과 재사용성 향상
로깅, 유효성 검사, 권한 검사 등을 처리하는 공통 로직을 어노테이션으로 분리
2) 중복 코드 제거
런타임에 리플렉션이나 프레임워크가 동작하면서 어노테이션에 선언된 정보를 기반으로 로직을 실행한다.
3) 동적 동작 지원
특정 조건에서 메서드 실행을 제한하는 로직을 작성할 수 있다.
롬복은 어떻게 동작할까?
롬복이란 @Getter, @Setter, @Builder 등의 어노테이션과 어노테이션 프로세서를 제공하여 표준적으로 사용하는 라이브러리이다.
개발을 하면서 반복적이고 공통적인 코드작성을 어노테이션을 통해 자동화해주는 라이브러리라고도 할 수 있다.
어노테이션 프로세서?
어노테이션 프로세서는 컴파일 시점에 끼어들어 특정한 어노테이션이 붙어있는 소스코드를 참조해서 새로운 소스코드를 만들어 낼 수 있는 기능이다.
어노테이션 프로세서를 따로 구현을 해야된다.
@AutoService(Processor.class)
public class MagicMojaProcessor extends AbstractProcessor {자바에서 제공하는 AbstractProcessor를 상속받아서
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) process 메서드 내부에서 내가 커스텀한 어노테이션이 붙어있는 경우에 대해서 특정 로직을 수행하도록 하면 된다.
process 메서드의 반화타입은 boolean이고 true를 반환하면 다음 프로세서에게 해당 어노테이션을 처리하라고 부탁하지 않는다.
컴파일러가 소스 코드를 컴파일하면서 어노테이션 프로세서를 호출하며, 어노테이션이 적용된 코드에 대한 정보를 제공한다.
AbstractProcessor는 여러 라운드에 걸쳐서 작업을 처리한다. 컴파일러로부터 제공된 정보를 바탕으로 소스 코드 또는 다른 파일을 생성하거나 검증 작업을 수행한다.
라운드마다 프로세서가 해당 어노테이션이 적용된 엘리먼트(클래스, 메서드, 필드 등)을 찾아 작업을 수행한다.
프로세서가 새로 생성한 소스 파일이 있다면, 다음 라운드에서 다시 컴파일 되고 관련 어노테이션이 처리된다.
만약, 새로 생성된 소스 파일이 없다면, 마지막 라운드로 넘어간다.
각 라운드는 "주어진 어노테이션에 의해 처리해야 될 요소"를 처리하는 단위이다.
@Controller와 @Service의 차이
스프링에서 타고 들어가면 @Controller와 @Service는 똑같은 코드를 가지고 있어서, 누군가 이 클래스가 컨트롤러인지 서비스인지 알기 쉽게 구분해주는 역할이라고 생각했는데, 둘은 다른것이다.
@Controller
컨트롤러 어노테이션은 해당 클래스가 웹 애플리케이션 요청을 처리하는 컨트롤러임을 나타내는 어노테이션이다.
@Controller의 특징
1) 웹 애플리케이션에서 클라이언트의 요청을 처리하는 컨트롤러의 역항을 한다.
2) @RequestMapping 어노테이션으로 컨트롤러에서 처리하는 요청의 기본 경로를 지정 가능하다.
3) 메서드 수준에서 어떤 경로의 요청을 처리할지 지정 가능 ex) GetMapping("ww"), PostMapping("/asda")
@RestController는 @Controller와 @RequestBody를 가짐
@Service
서비스 어노테이션은 해당 클래스가 비즈니스 로직을 담당하는 서비스 계층 구성 요소임을 알려주는 어노테이션이다.
@Service의 특징
1) 주로 Service Layer 클래스에 사용된다.
2) 스프링 컨테이너에 해당 클래스를 빈으로 등록한다.
3) 스프링의 트랜잭션 관리를 받는다. -> @Service가 붙은 클래스나 그 내부의 메서드에 @Transactional이 추가되면, 스프링 트랜잭션 관리 기능을 사용할 수 있다.
4) 비즈니스 로직을 가지고 있는다.
@RequestMapping("/test/service")
public class UUIDTestService {
@GetMapping
public ResponseEntity<Void> test(){
return ResponseEntity.ok().build();
}
}@Service가 붙은 클래스는 비즈니스 로직을 처리하는 빈(Bean)으로 스프링 컨텍스트에 등록되지만, HTTP 요청을 처리하는 컨트롤러 역할로는 인식되지 않는다. 따라서 해당 클래스에 @RequestMapping과 @GetMapping 메서드를 작성해도 요청을 매핑하지 못하며, 404 Not Found 에러가 발생한다.
@Controller나 @RestController를 붙여 IoC 컨테이너에 빈으로 등록하면, DispatcherServlet이 이를 HTTP 요청 처리 대상으로 인식한다. 이후 Spring MVC는 해당 빈의 요청 매핑 정보를 기반으로 HTTP 요청 처리 로직을 추가로 적용하여, 요청-응답 흐름을 관리합니다.
정리 (확실하지 않음)
스프링 어노테이션 -> 리플렉션(런타임)
롬복, 커스텀 어노테이션 -> 어노테이션 프로세서
