
스프링 부트 애플리케이션의 성능을 극대화하는 방법을 알아보자
1. 캐싱
캐시 사용은 자주 요청되지만 변경은 적은 데이터 또는 계산 비용이 높은 데이터 (통계 데이터)에 적합하다.
캐싱은 반복적인 데이터 조회나 연산 결과를 메모리에 저장해 나중에 동일한 요청이 들어올 때 빠르게 응답할 수 있도록 하는 기법이다.
캐싱을 적절히 활용하면 DB 요청 수를 줄이고 애플리케이션의 응답 속도를 크게 향상시킬 수 있다.
스프링 부트에서 캐싱을 사용하려면 애플리케이션 클래스에 @EnableCaching 애너테이션을 추가하고, 재시를 적용할 메서드에 @Cacheable 애너테이션을 사용한다.
@CacheEvict 애너테이션을 사용하여 캐시를 명시적으로 제거할 수도 있디.
스프링 부트는 캐시 추상화를 통해 다양한 캐시 제공자(EhCache, Redis, Caffeine 등)를 지원하며, 애플리케이션 요구에 맞게 캐시 전략을 선택할 수 있다.
Cache Hit - Redis에 데이터가 있을 경우 바로 가져옴 (빠르다)
Cache Miss - Redis에 데이터가 없을 경우 DB에서 가져옴 (느리다)
캐시 전략
캐시 읽기 전략
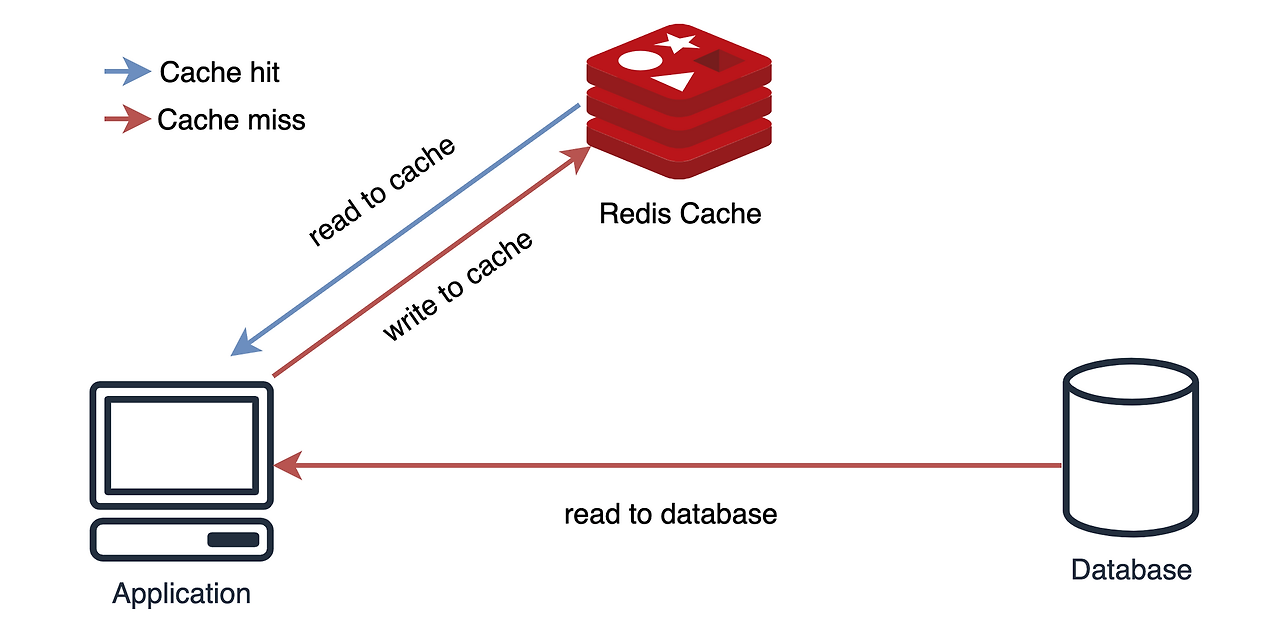
1) Look Aside 패턴
데이터를 찾을 때 우선 캐시에 저장된 데이터가 있는지 확인 후 없다면 DB에서 조회한다.
반복적인 읽기가 많은 호출에 적합하다.
만약 Redis가 다운 되더라도 DB에서 데이터를 가져올 수 있어서 서비스 자체는 문제가 없다.
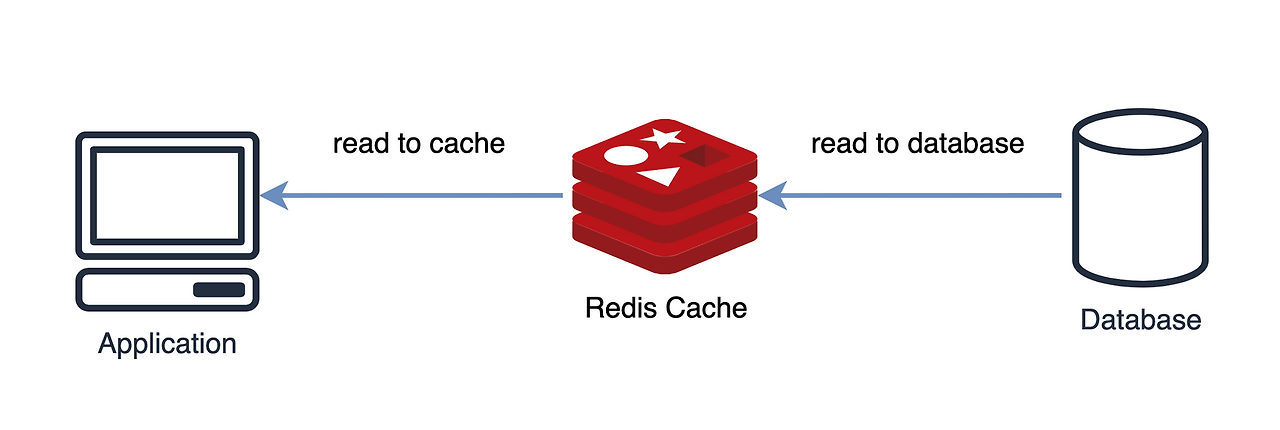
2) Read Through 패턴
캐시에서만 데이터를 읽어오는 전략
캐시에 데이터가 없을 경우 캐시가 직접 DB에서 데이터를 조회하여 자체 업데이트한다.
따라서 데이터를 조회하는데 있어 전체적으로 속도가 느리다.
Redis가 다운될 경우 서비스 이용에 차질이 생긴다.
대신 캐시와 DB 간의 데이터 동기화가 항상 이루어져 데이터 정합성 문제에서 벗어날 수 있다.
캐시 쓰기 전략
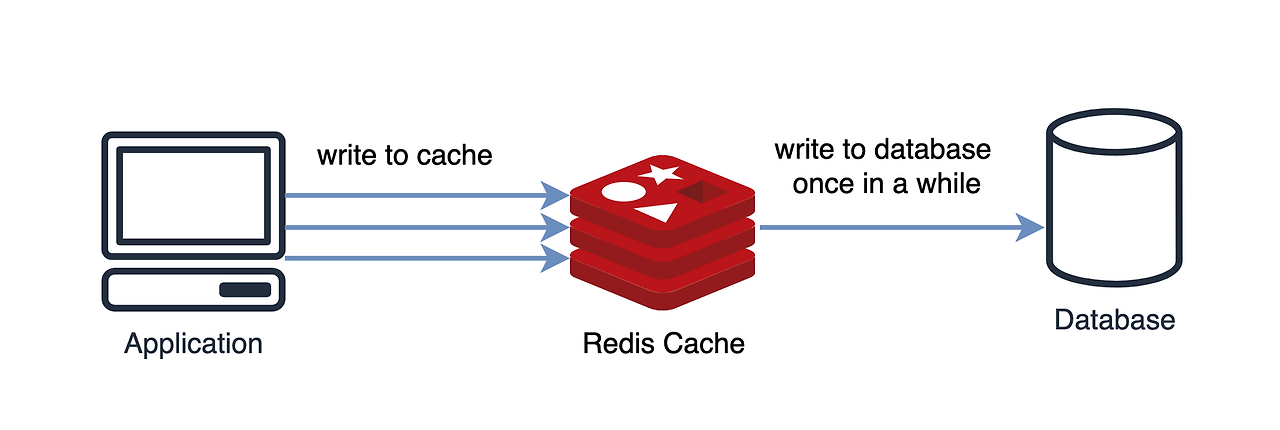
1) Write Back 패턴
캐시와 DB 동기화를 비동기하기 때문에 동기화 과정이 생략된다.
데이터를 저장할 때 DB에 바로 쿼리하지 않고, 캐시에 모아서 일정 주기 배치 작업을 통해 DB에 반영
모아뒀다가 DB에 쓰기 떄문에 쓰기 쿼리 회수 비용과 부하를 줄일 수 있다.
Write가 빈번하면서 Read를 하는데 많은 양의 리소스가 소모되는 서비스에 적합하다.
다만 캐시에서 오류가 발생하면 데이터를 영구 소실한다.
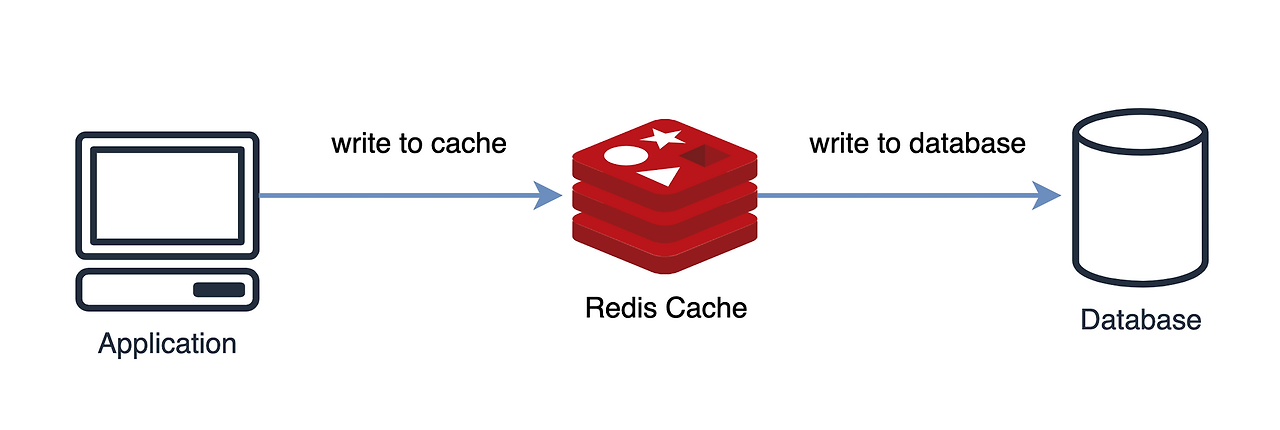
2) Write Through 패턴
DB와 캐시에 동시에 데이터를 저장한다.
캐시에 먼저 저장하고 바로 DB에 저장한다. 캐시에 먼저 저장하는 이유는 데이터를 읽는 요청은 캐시를 먼저 읽기 떄문이다.
데이터 유실이 발생함녀 안되는 상황에 적합하다.
다만 매 요청마다 2번의 Write가 발생하여 성능 이슈가 발생한다.
3) Write Around 패턴
Write Through 보다 훨씬 빠르다.
모든 데이터는 캐시를 저장하지 않고 DB에 저장한다.
Cache Miss가 발생하는 경우에만 캐시에도 저장
캐시와 DB의 데이터가 불일치 할 가능성이 높다.
DB 데이터가 수정되는 경우에 캐시에 있는 데이터를 수정 또는 삭제하는 방법으로 해결 해야된다.
Write Around 패턴은 Look Aside + Read Through로 사용된다.
캐시 읽기 + 쓰기 전략 조합
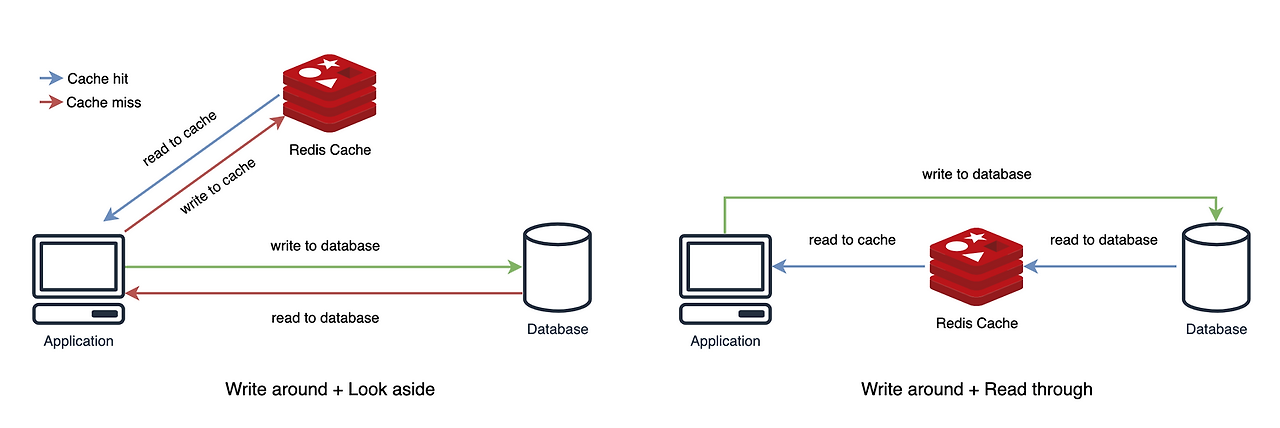
1) Look Aside + Write Around 조합
가장 일반적으로 자주 쓰이는 조합이다.
2) Read Through + Write Around 조합
항상 DB에 쓰고, 캐시에서 읽을 때 항상 DB에서 먼저 읽어오기 때문에 데이터 정합성 이슈에 대한 완벽한 안전 장치를 구성할 수 있다.
3) Read Through + Write Through 조합
데이터를 쓸 때 항상 캐시에 먼저 쓰기 때문에 읽어올 때 최신 캐시 데이터를 보장한다.
데이터를 쓸 때 항상 캐시에서 DB로 보내기 때문에, 데이터 정합성을 보장한다.
2. 데이터베이스 최적화
데이터베이스는 애플리케이션 성능에 큰 영향을 미친다.
1) 쿼리 최적화
불필요한 쿼리를 줄이고, 필요한 데이터만 조회하도록 쿼리를 최적화 해야된다.
반환 자체를 Entity가 아닌 DTO로 받는 방법이 있다. 이러면 내가 필요한 필드만 받아올 수 있다.
2) 지연로딩을 사용
JPA의 Lazy Loading을 활용하면, 실제로 필요한 시점에만 데이터를 로딩하도록 설정한다.
실제 사용되는(필요한) 시점에 쿼리가 나가도록 할 수 있다는 것이다. 사용하지 않으면 쿼리가 나가지 않음
이는 불필요한 데이터 로딩을 방지하고 성능을 최적화하는 데 도움이 된다.
즉시로딩 - 데이터를 조회할 때, 연관된 모든 객체의 데이터까지 한 번에 불러오는 것이다.
3) 인덱스 사용
테이블에 적절한 인덱스를 설정하여 데이터 조회 속도를 높일 수 있다.
인덱스는 자주 조회되는 필드에 적용하고, 복합 인덱스도 고려해야 된다.
3. 비동기 처리와 멀티쓰레딩
1) 비동기 처리
비동기 처리는 멀티스레드를 사용하여 작업을 분리하고, 작업이 끝날 때까지 대기하지 않고 다른 작업을 처리할 수 있다.
애플리케이션 클래스에 @EnableAsync를 붙이고 비동기로 실행할 메서드에 @Async를 붙이면 된다.
@Async 메서드가 붙은 메서드는 별도의 스레드에서 실행되므로 메인 스레드에서 캐치를 할 수 없기 때문에 예외가 발생해도 호출자에게 전파가 되지 않는다.
2) 멀티쓰레딩
하나의 프로세스 내에서 여러 스레드가 동시에 작업을 수행하는 것이다.
멀티쓰레딩을 활용하면 CPU 자원을 최대한 활용할 수 있다.
스프링의 ThreadPoolTaskExecutor를 사용해 쓰레드 풀을 구성하고 효율적으로 작업을 분배할 수 있다.
ThreadPoolTaskExecutor를 사용해야 매 비동기 작업마다 새로운 스레드를 생성하지 않고, 제한된 리소스를 사용하는 스레드풀을 사용하여 리소스를 낭비하지 않을 수 있다.
요청이 동시에 굉장히 많이 들어오면 서버는 쓰레드 풀에서 처리 할 수 있는 만큼만 동시에 스레드를 생성하여 작업을 처리하고 나머지 요청들은 대기큐에 쌓여서 처리가 가능한 시점까지 기다린다.
프로파일링 및 모니터링
1) 스프링 부트 액추에이터
애플리케이션의 상태를 모니터링하고, 메트릭스를 제공하여 성능을 최적화할 수 있는 유용한 도구이다.
이를 통해 애플리케이션의 상태, 메모리 사용량, HTTP 요청 처리 속도 등을 실시간을 확인할 수 있다.
액추에이터가 제공하는 기능은 우리 애플리케이션 내부 정보를 너무 많이 노출하기 때문에, 외부 인터넷망이 공개된 곳에 액추에이터의 엔드포인트를 공개하는 것은 보안상 좋지 않다.
(액추에이터를 다른 포트에서 실행하거나 엔드포인트 경로 변경 등으로 해결)
2) APM(Application Performance Monitoring) 도구 사용
DataDog와 같은 APM 도구를 사용하여 애플리케이션 성능을 모니터링 하고, 병목 현상을 발견할 수 있다.
트랜잭션 추적, 메모리 및 CPU 사용량 모니터링, 오류 보고 등 다양한 기능을 제공한다.
의존성 관리 및 애플리케이션 경량화
1) 필요하지 않은 의존성 제거
필요하지 않은 의존성 을 제거하여 애플리케이션을 경량화 한다면 애플리케이션의 성능을 높일 수 있다.
불필요한 라이브러리는 애플리케이션 시작 시간과 메모리 사용량에 악영향을 미칠 수 있다.
2) JVM 튜닝
애플리케이션 성능을 높이기 위해 JVM의 가비지 컬렉션 정책이나 힙 메모리 크기 등을 튜닝할 수 있다.
스프링 프로파일 사용
1) 프로파일 정의
스프링 부트는 개발, 테스트, 프로덕션 환경에 맞게 설정을 분리할 수 있도록 프로파일 기능을 제공한다.
각 환경에 최적화된 설정을 사용하면 성능을 크게 개선할 수 있다.
2) 프로파일 활성화
application.properties 또는 환경 변수에서 spring.profiles.active 값을 설정하여 활성화할 프로파일을 지정한다.
