JavaScript에 대해서 많이 들어본 소리 중 하나는 single thread일 것이다. JavaScript는 정말 single thread일까? 왜 그런 소문이 났고, 어떻게 문제없이 널리 쓰이고 있는 것일까?
Call Stack
JavaScript Engine(이하 JSE)의 동작 방식을 다시 한 번 기억해보자. 파일이 들어오면 위에서부터 순차적으로 읽어들인다고 했다. 그리고 그것을 낱말 단위로 파싱한 후 AST를 생성한다. Interpreter는 이 AST를 Bytecode로 변환하고 실행하는 역할을 한다.
예를 들어 아래와 같은 코드가 들어왔다고 생각해보자.
function a() {
return "This is A data";
}
function b() {
const aData = a();
return aData
}
function c() {
const bData = b();
return bData;
}
c()하나의 함수에서 다른 함수를 부르는 이런 nested 구조는 흔하게 볼 수 있는 구조이다. Interpreter는 이것을 function c -> function b -> function a 순서대로 실행할 것이다.
하지만 어떻게 a의 실행 결과를 b에게, b의 실행 결과를 c에게 넘겨줄 수 있는 것일까? 여기서 등장하는 개념이 Call Stack이다. 이것은 Chrome 개발자 도구에서 쉽게 확인해볼 수 있다.
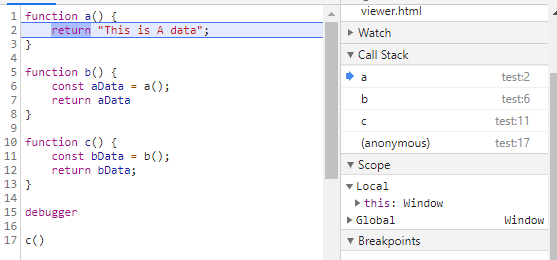
순서는 이렇다.
- function c가 호출되면 Call Stack에 c를 집어 넣는다.
- c 안의 연산에서 function b가 호출되었으니 Call Stack에 b를 집어 넣고 b로 이동한다.
- b 안의 연산에서 function a가 호출되었으니 Call Stack에 a를 집어 넣고 a로 이동한다.
- a의 연산이 끝나면 Call Stack에서 a를 빼낸다.
- Call Stack의 맨 위에 b가 있으니 a에서 return 받은 결과를 가지고 b로 돌아가 이후의 연산을 마저 끝낸다. b의 작업 역시 끝났으니 Call Stack에서 b를 빼낸다.
- Call Stack의 맨 위에 c가 있으니 b에서 return 받은 결과를 가지고 c로 돌아가 이후의 연산을 마저 끝낸다. c의 작업 또한 끝났으니 Call Stack에서 c를 빼낸다.
즉! 새로운 하나의 작업을 만날 때마다 Call Stack에 집어넣고, 끝날 때마다 Call Stack에서 빼내는 것이다. 현재 작업해야 하는 위치는 Call Stack의 맨 위를 보면 확인할 수 있다.
이렇게 현재 코드의 실행하고 있는 부분을 트래킹하는데, JSE는 이것을 1개만 두고 사용한다. 1개만 두고 사용하기 때문에 어떤 함수가 현재 실행중이라면 다른 함수는 실행될 수 없음을 의미하고 그래서 JavaScript는 single thread다라는 말이 나오게 된 것이다.
Stack Overflow
여기서 잠시 주의해야하는 점이 생긴다. Stack에는 한정된 크기가 주어지기 마련이다. 이 한정된 크기를 넘어서 더 사용하게 되면 오류가 발생하는데 이를 Stack Overflow라 한다.
간단하게 자기 자신을 계속해서 호출하는 재귀함수가 있고 이를 실행해보자.
function myself() {
myself()
}
myself()Call Stack을 확인해보면 다음과 같을 것이다. 물론 이는 debugger를 이용하여 중간에 멈춘 것이고 실제로는 Stack 안에 myself가 계속 쌓일 것이다.
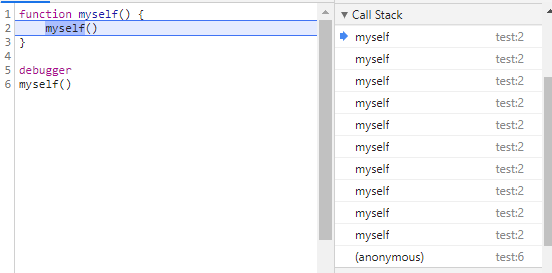
쌓이고 쌓이다가 결국 정해진 크기를 넘어서면 오류가 발생하는 것을 볼 수 있다.
$ node test.js
...
RangeError: Maximum call stack size exceeded
at myself (D:\project\test.js:24:16)
at myself (D:\project\test.js:25:5)
at myself (D:\project\test.js:25:5)
at myself (D:\project\test.js:25:5)
at myself (D:\project\test.js:25:5)
at myself (D:\project\test.js:25:5)때문에 흔지 않지만 이런 부분도 주의해야 한다.
JavaScript Runtime
다시 돌아와서, JSE는 Call Stack을 하나만 사용한다고 했다. 만약 어떤 함수가 Call Stack의 최상단에 있으면서 10분씩 걸린다면 어떤 일이 발생할까? 프로그램에 다른 어떤 요청을 처리해달라고 요청하려면 10분씩 기다려야만 한다는 것이다. 간단한 작업이라도 여러 사람이 동시에 요청하게 되면 늦게 요청한 사용자는 자기 순서가 올 때 까지 기다릴 수 밖에 없다는 문제가 발생한다.
인터넷을 예로 들면, 내가 큰 파일을 다운로드 받는 동안 다른 작업은 수행할 수 없다는 의미가 된다. 하지만 우리가 사용하는 인터넷은 그런적이 없다. 이를 해결하기 위해서 JavaScript Runtime을 구성하여 사용하기 때문이다. 아래 사진의 구성을 하나씩 알아보자.
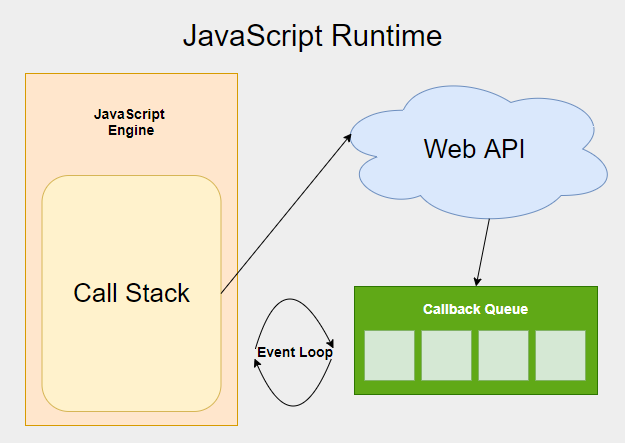
Asynchronous - web api, libuv ...
Chrome에서는 window
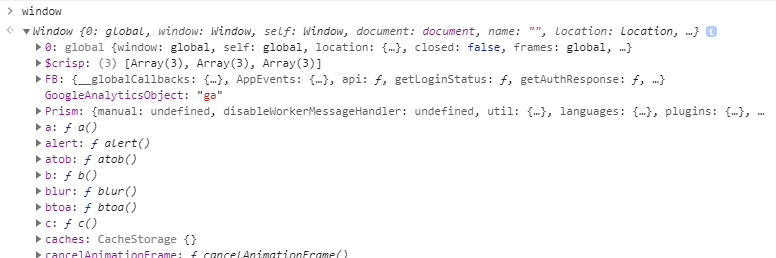
NodeJS에서는 global
로 확인할 수 있다. 이것들이 JSE에서 오래걸리는 작업을 대신 맡길 수 있는 리스트이다. 가장 쉬운 예로 리스트를 확인하다보면 setTimeout을 볼 수 있다. JSE가 요청을 수행하다가 setTimeout을 만나면 자신이 처리하지 않고 "이것좀 처리해줘!" 하고 넘길 수 있다는 것이다.
이렇게 오래걸리는 일을 맡아주는 녀석을 Chrome에서는 Web API라고 하고, NodeJS에서는 LIBUV라고 한다. 오래걸리는 작업을 맡겨두고 JSE는 다른 일을 처리할 수 있게 되었는데, 이런 방식을 비동기(asynchronous) 방식이라고 한다.
Callback Queue
자 여태까지 Call Stack에 작업들이 쌓이고, JSE는 그것들을 처리하다가 Web API에서 할 수 있는 일을 만나면 Web API에게 맡기고 다른 일을 처리한다는 것까지 봤다. 그럼 Web API는 일을 처리한 후에 어떻게 할까?
Web API는 백그라운드에서 작동한다. 즉, 사용자와 커뮤니케이션하는 부분이 아닌 것이다. 따라서 Web API가 요청받은 일을 다 끝내더라도 사용자에게 바로 "나 일 다했으니 확인해봐!"라고 하지 않는다는 것이다.
왜 일까? 사용자의 요청은 js의 어떤 function일 것이고, 이 function은 처리 과정에 따라 JSE가 처리하고 있을 것이다. 사용자와 이렇게 소통하고 잇는 부분이 있는데 갑자기 옆에서 Web API가 뛰쳐나와 얘기에 끼어들면 모양이 이상해지기 때문이다.
즉, 중간에 끼어들지 않고 Web API는 마무리한 일을 Callback Queue에 넣는다.
Event Loop
Web API는 끝난 일을 Callback Queue에 넣고 작업을 마무리하기 때문에 JSE는 여전히 요청한 일이 끝났는지 안 끝났는지 알 수 없는 상태이다. 이 작업을 또 누군가는 처리해야만 하는데, 그 녀석이 바로 Event Loop이다.
이제 이 예제의 결과물을 예상해볼 수 있다.
setTimeout(() => console.log("first output"), 1000)
setTimeout(() => console.log("second output"), 1500)
console.log("third output")JSE는 위 js 파일을 위에서부터 순차적으로 읽어들일 것이다. 맨 첫 줄의 setTimeout을 만나면 "어? 얘는 Web API 역할이야" 하고 넘길 것이고, 두 번째 줄도 마찬가지일 것이다. 그 다음 세 번째 줄을 만나서야 직접 작업을 할 일을 찾았기에 "third output"을 로그에 남길 것이다.
그 다음 Web API는 setTimeout 요청들을 받아서 처리할 것이고, 처리가 끝난 순서대로 Callback Queue에 first output 로그를 남겨야해와 second output 로그를 남겨야해를 넣을 것이다.
그리고 Event Loop는 Callback Queue를 보고 있다가 일이 생겼음을 감지하고 JSE에게 "이거 처리하면 된대!" 라며 마무리 작업을 요청한다. 따라서 결과물은 아래 순서처럼 된다.
third output
first output
second output그럼, 이건 어떨까?
setTimeout(() => console.log("first output"), 0)
setTimeout(() => console.log("second output"), 0)
console.log("third output")여기서 알아야 마지막으로 한 가지 더 알아야 할 것은 Event Loop는 2가지 조건을 충족할 때를 기다린다는 것이다.
1. Page Load가 완전히 끝난 후
2. Call Stack이 비어있을 때
따라서 Web API에게 setTimeout 요청을 보냈을 때 delay가 0ms이기 때문에 즉시 완료된다고 하더라도, 페이지 로딩이 끝나야 하기 때문에 "third output" 로그를 먼저 남긴다. 그리고 나서 나머지 작업을 순차적으로 진행하게 되기에 결과는 위와 같아진다.
Result
간혹 JavaScript Engine과 JavaScript Runtime을 헷갈리곤 한다. 하지만 둘은 전혀 다른 것이다. JSE는 Runtime을 구성하는 일부일 뿐이다. JSE와 Web API, Callback Queue, Event Loop를 모두 묶어서 JavaScript Runtime이라는 것을 잊지 말자.
이 모든 작동 방식을 정리하면 여기에서 눈으로 확인할 수 있다. 여러가지 직접 테스트해보면 더 잘 기억에 남을 것이다.
