Abstract
scalability를 고려하여 후보생성 + 랭킹모델 구조로 딥러닝기반 추천모델 제안
Introduction
유튜브에서는 매순간 새로운 영상이 업데이트 되고, 이에 따라 수억명 사용자들의 다양한 interaction이 발생한다. 이에 따라 유튜브는 세가지 관점에 집중해 영상 추천을 진행한다.
- Scale
- 엄청난 규모의 아이템과 사용자 수
- Freshness
- 매초마다 업데이트되는 아이템과 그에 따른 사용자의 반응을 다뤄야 함
- Noise
- implicit feedback, sparsity, 외부요인 등으로 사용자의 진정한 취향을 파악하기 어려움.
이런 문제들에서 robust한 추천모델을 구축하는 것이 목표.
System overview
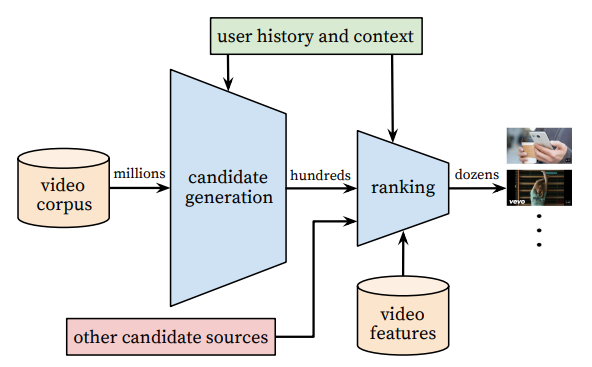
- scalability를 고려한 candidate generation model + ranking model로 구성
candidate generation model
- 엄청난 규모의 영상 corpus에서 사용자의 취향에 맞는 수백개의 영상 후보를 고르는 것이 목표. (high precision)
ranking model
- 수백개의 후보 동영상 중 사용자가 볼 확률이 큰 영상 순위를 매기는 모델. (high recall)
Candidate generation
-
이부분은 inference, output layer에 대한 이야기
-
엄청난 규모의 영상 corpus에서 사용자의 취향에 맞는 수백개의 영상 후보를 고르는 것이 목표.
-
이러한 추천 task(후보생성)를 multiclass classification으로 바라봄.
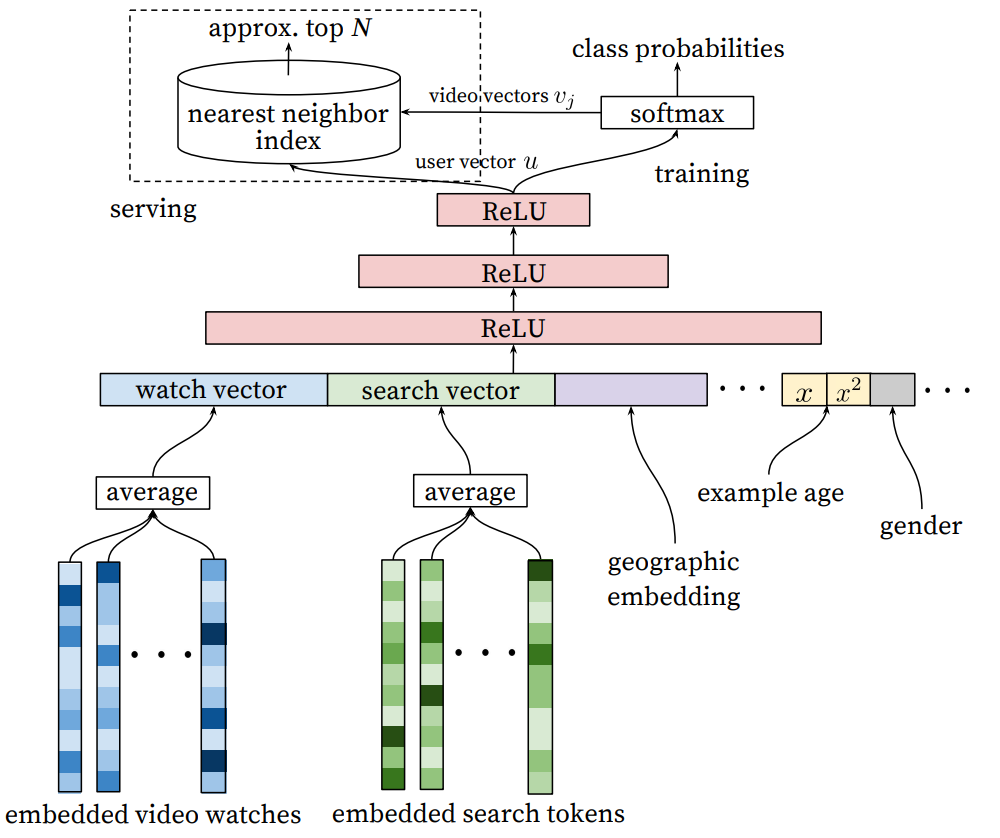
Efficient Extreme Multiclass
class가 너무 많기 때문에 class를 nagetive sampling (skip gram negative sampling)하여
Extreme multiclass classification 효율적으로 어떻게 구현?
Offline에서는 (즉, 미리 계산)
negative class를 샘플링 (i.e., skip-gram negative sampling)
loss function으로는 각 class (비디오)마다 (binary) cross-entropy를 사용
대략 수천개정도의 negative sample 이용
hierarchical softmax는 (이런저런 이유로) 사용하지 않음.
at serving time (추천을 실시간으로 할때는)
드디어 사용자에게 추천을 N개의 비디오를 고르는 시간
기존에는 [24]처럼 hashing을 사용했고 이번에도 마찬가지.
최종적으로는 (위의 식처럼) dot-product space에서 가장 가까운 아이템 (nearest neighbour)를 찾는 과정.
A/B test 결과 nearest neighbour 알고리즘간에 추천성능 차이는 없음
Feature engineering
-
이부분은 모델의 input feature에 대한 이야기
-
사용자가 봤던 동영상, 검색했던 search query, demographic info, example age 를 input feature로 사용함
사용자의 히스토리 시퀀스
-
동영상, search query는 모두 embedding vector로 표현.
-
사용자가 시청한 동영상들의 embedding vector를 평균내어 하나의 embedding vector를 input으로 넣어줌, search query도 동일한 방법 적용.
- 이러한 방법은 영상을 본 순서, 검색어 입력 순서를 뭉개버리는 행위
- 다음에 어떤 영상을 볼 지 맞히는 task여서, 만약 시퀀스를 유지한 체 영상과 검색어를 넣어주게 된다면 추천되는 영상은 마지막 쿼리에만 영향을 받게 될 것이라 추측.
- '먹방'을 검색하고 먹방 영상을 보고, 'BTS'를 검색하고 BTS 영상을 보는 패턴들이 있기 때문에 모델이 마지막 검색어 쿼리를 보고 해당 쿼리에 대응하는 영상을 추천할 것이라 추측.
- 그렇기에 모델이 마지막 검색어 쿼리에 의존하지 않도록 이런 방법을 적용함.
demographic information
- 사용자의 성별, 나이, 위치 등을 feature로 넣어줌 -> cold user에게 유용
example age
-
영상의 나이를 feature로 넣어줌
-
동영상의 인기도는 non - stationary하고, 유튜브 환경은 새로운 영상이 계속해서 만들지며새로운 영상들을 추천해 주고 싶음
-
머신러닝 모델은 과거에 인기있는 영상을 새로 인기있을 만한 영상보다 추천하는 경향을 지님(과거로 현재를 예측하기 때문)
-
그렇기에 동영상의 나이를 input feature로 사용
-
Label and context selection
- trainig data의 구성에 대한 이야기
dataset(context)구성
-
유튜브 내에서 시청된 영상 외에도 다른 사이트에서 본 유튜브 영상 기록까지 train data에 포함시킴
-
헤비유저의 영향력을 고려하여 모든 사용자의 시청 기록을 동일한 길이로 잘라 train data로 사용
label 구성
-
CF의 경우 label을 기준으로 과거, 미래 시점의 context(시청기록)을 모두 이용.(그림 (a))
-
에피소드 시리즈 같이 순차적으로 소비되는 케이스를 고려해주기 위해 그림 (b)와 같이 label 기점으로 과거 시점의 context만을 사용해서 학습.
-
즉, 과거 데이터로 다음에 사용자가 어떤걸 볼 지 맞히는 task에 초점을 두고 학습시킴.
Ranking model
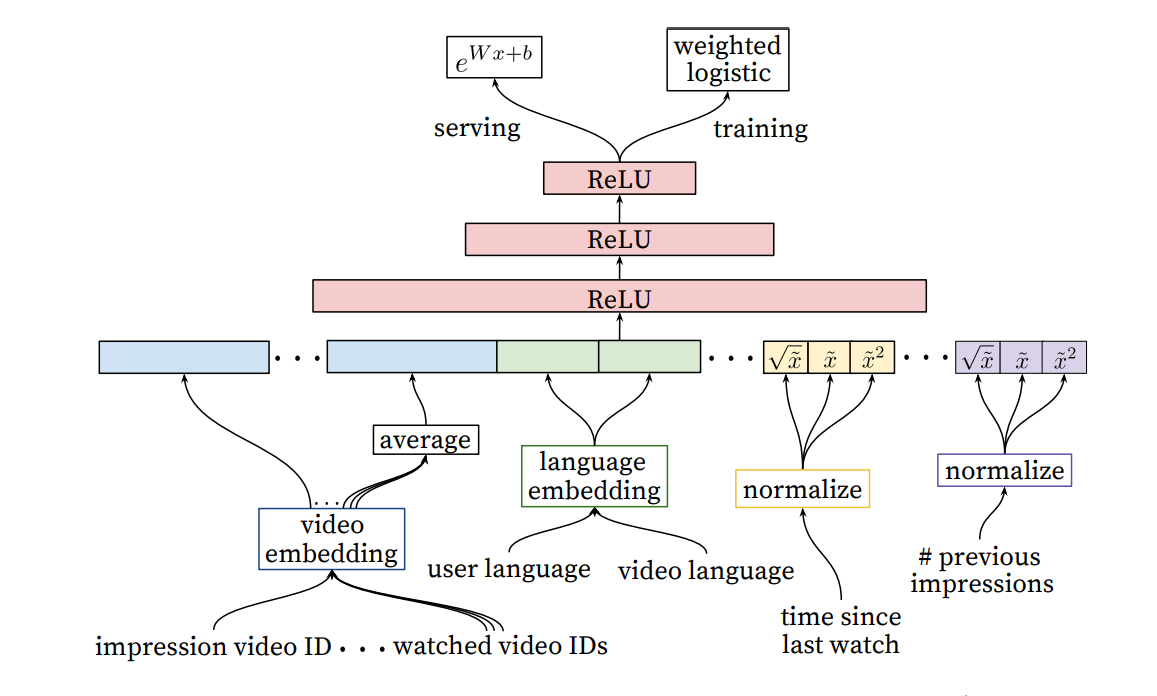
-
수백개의 후보 동영상 중 사용자가 볼 확률이 큰 영상 순위를 매기는 모델.
-
사용자의 히스토리에서 사용자의 video impression을 뽑아내는 데 초점.
-
video set의 cardinality가 너무 커서 video embedding matrix를 가지고 있기 어려움. -> 클릭빈도가 높은 상위 영상을 남기고 나머지는 제거.
