
2024년 9월 11일
✏️ DBMS
: DataBase Management System
- 데이터베이스 : 데이터를 구조화해 관리함으로써 데이터 중복을 막고, 효율적이고 빠른 데이터 연산을 가능하게 함
- 데이터베이스를 운영하고 관리하기 위해 사용
- 우리가 요즘 생각하는 데이터베이스를 DBMS라고 함
- DBMS의 종류 : oracle, mysql, mariadb, postgreSQL, mongoDB 등
✏️ RDBMS
: Relational DMBS
- 관계지향적 데이터베이스
- 데이터베이스 연관관계
- 데이터끼리 연관해서 찾을 수 있음(=마인드맵)
- 데이터의 힌트(연관된 데이터)를 통해 원하는 값을 찾을 수 있음
✏️ PK, FK, 데이터 정규화
💡 PK
: Primary Key(기본키) -> 해당 테이블의 각 row(행)을 unique(유일)하게 구별할 수 있는 key값
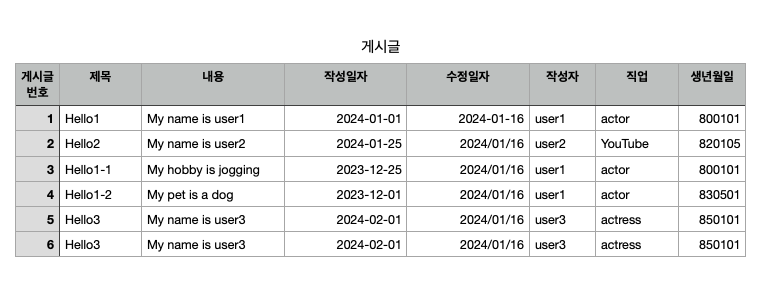
- 게시글 번호 : PK => 게시글 번호가 key이고, 나머지 데이터들은 value가 되는 것임
❗️❗️❗️
한 사람이 여러 게시글을 쓸 수 있어서 중복되는 글이 많을 수 있음 -> 이런 경우를 해결해주는것이 RDBMS임!!
데이터 중복 -> 데이터 부화, 비용 up
따라서, 데이터를 정규화 시켜주어야함 (서로의 키값을 통해 원하는 데이터를 찾는 것임)
💡 데이터 정규화
: 테이블 분리
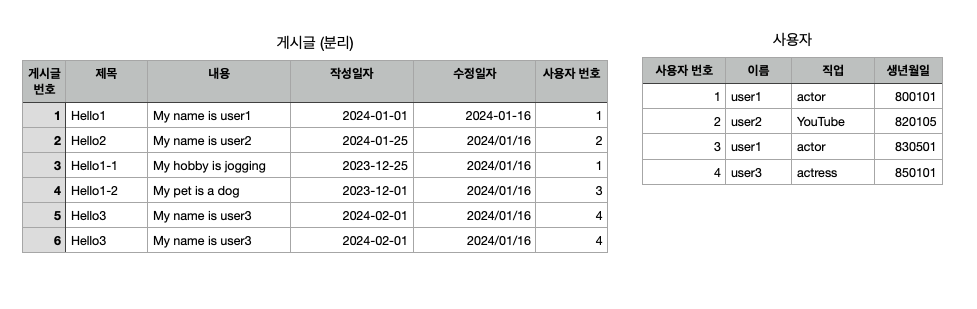
- 데이터들이 하나의 테이블 안에서 중복되어 있었지만, 테이블을 분리해서 중복을 없애고, 테이블 간의 관계를 만들어서 데이터를 쉽게 찾을 수 있게 했다
💡 FK
: Foregin Key(외래키) -> A테이블에서 B테이블의 데이터를 찾아가고 싶을 때, 사용하는 key값
-
만약, 중복되는 FK값이라면 원하는 데이터값을 찾아 갈 수 없으므로(모든 row값을 유일하게 보지 못함) → 따라서, PK를 FK로 사용함
-
최대한 B테이블의 PK값을 A테이블의 FK로 쓰는 것이 이상적 (서로의 키값을 통해 원하는 데이터를 찾는 것임)
-
테이블 분리 후의 KEY를 살펴보면,
- 게시글 테이블 : 게시글 번호: PK / 사용자 번호: FK
- 사용자 테이블 : 사용자 번호: PK
-
단점은 한 번에 테이블을 보고 데이터를 찾지 않아서 단계를 거쳐야하는 것이지만 이것도 나중에 해결된다고했음
✏️ 생년 월일 바꿔보기, 연관관계
-
분리되지 않은 테이블에서는 한 명의 생년월일을 바꿀 때, 그사람의 생년월일을 각각 바꿔줘야 하지만, 분리된 테이블에서는 사용자 테이블의 생년월일만 바꾸면 된다
-
분리된 게시글 테이블에서는 사용자를 알 수 있지만, 사용자 테이블에서는 게시글을 무엇을 쓴지는 모른다
-
RDBMS을 보면 테이블간의 연관관계를 알 수 있다
-
데이터베이스 테이블 간 어떤 관계를 가지고 있는지에 대한 연관 관계는 1:1, 1:N, N:1, M:N이 있음
-
사용자 <-> 게시글
- 사용자 1명 : 게시글 n개 -> 1:N
- 게시글 1개 : 사용자 1명 -> 1:1
- 게시글 테이블을 보고, 사용자 데이터 확인 O
- 사용자 테이블 보고, 게시글 데이터 확인 X
- 두 개의 연관 관계를 보고 확인이 되는 관계가 맞는 연관 관계
따라서, 1:N
*연관 관계는 연습을 많이 해야 알 수 있고, 익숙해 질 수 있음!
(구현했을 때, SQL이 꼬이거나, 많은 SQL, 긴 SQL을 하게 되면 다시 설계를 고침)
✏️ 유튜브 실습
- 유튜브 회원, 채널을 가지고 RDBMS를 만들어보자
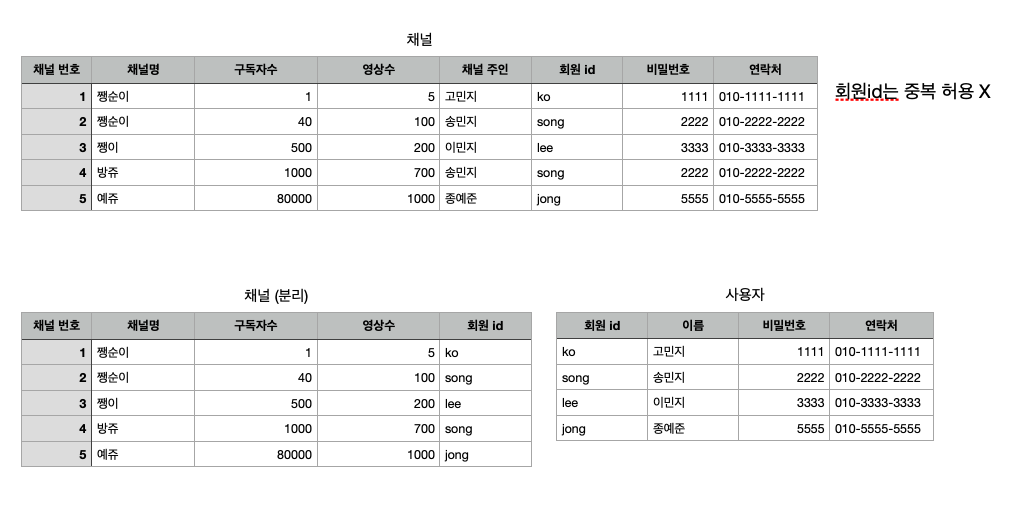
- 사용자 <-> 채널
- 사용자 1명 : 채널 n개 -> 1:N
- 채널 1개 : 사용자 1명 -> 1:1
- 채널 테이블에서는 사용자 데이터 확인 O
- 사용자 테이블에서는 채널 데이터 확인 X
따라서, 1:N 관계!
✏️ mysql workbench
- 우리는 주로 CLI를 이용해서 데이터베이스를 만들 것임
저번에 mariaDB 실행했던거 다시 상기시키자면,
- mariaDB 시작
1) docker on
2) mariadb가 있는 컨테이너 접속 : docker exec -it mariadb /bin/bash
3) mariadb 실행 : mariadb -u root -p
*데이터를 저장하는 방 : 스키마
하지만, GUI와 친해지면서 같이 실습할 예정
사용할 것 : mysql workbench
- 사이트 접속 -> 운영체제에 맞게 설치(나는 mac interchip이므로 x86선택/ apple칩은 arm)
- no thanks just start my download
- 설치 완료
🍏🍎 오늘의 느낀 점: 오늘은 RDBMS에 대해 배워보고, 직접 테이블을 만들어서 연관 관계가 있는 데이터들을 만들어서(or 사용해서) 쉽게 낚시하듯 건져올릴 수 있게 했다. 데이터베이스를 만드는 것도 많은 연습을 하면서 익숙해지는게 중요할 것 같았다. 백엔드는 로직을 잘 설계 해야 한다는 말이 어떤 말인지 잘 이해가 가지 않았는데 오늘 직접 PK, FK를 만들어보고 생각해보면서 연관 관계가 로직을 말하는 것이란 걸 알게 되었다. (맞겠지유..?) 무튼 더욱 많은 연습이 필요하다!!
