
📊 PCA - 주성분 분석
📌 PCA (Principal Component Analysis)이란?
- 정의
- 고차원 데이터세트를 저차원으로 차원 축소하여 새로운 차원의 데이터세트를 생성
- 데이터의 분산을 최대한 유지하면서 최소한의 주성분(feature)만 얻는다.
- 하나의 축을 기준으로 사영(projection) 시켜 해당 축에 모이게 된다. (차원 축소)
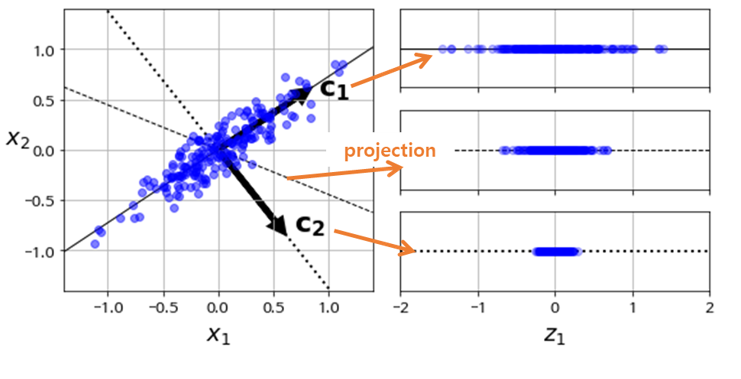
📌 사영 (projection)
- 정의
- 하나의 축을 기준으로 데이터에 빛을 쐐여 하나의 축으로 모이게 만드는 작업
- 분산이 가장 큰 축을 기준으로 사영시킨다.
📌 분산이 가장 큰 축?
- 정의
- 회귀에서 최소제곱법으로 인해 구해진 평균제곱거리를 최소화하는 회귀선을 의미한다.
C1 회귀선 : 평균제곱오차가 작으며, 데이터 분산이 크다.
C2 회귀선 : 평균제곱오차가 크며, 데이터 분산이 작다.[ 분산이 크다? ]
→ 분산 데이터 간의 거리가 멀어 개별 데이터의 성질을 잘 파악할 수 있다.[ 분산이 작다? ]
→ 분산 데이터 간의 거리가 가까워 성질을 잘 파악할 수 없다.
📌 PCA 팁
- 팁
- 차원축소(PCA)를 하기 전에, feature scaling을 한 후에 차원축소 수행 시 성능이 높아질 수 있다.
📊 PCA 분석 실습
📌 PCA 분석 실습
- 1. 라이브러리 Import
import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_iris # PCA 모듈 from sklearn.decomposition import PCA
- 2. feature 준비
x = iris.data
- 3. PCA 분석(차원 축소) 진행
- n_components 속성 : 변환할 차원 수
- 차원 개수 : feature 개수pca = PCA(n_components=2) x_low = pca.fit_transform(x) print(x_low[:3]) # [[-2.68412563 0.31939725] # [-2.71414169 -0.17700123] # [-2.88899057 -0.14494943]]
- 4. 차원 복구
x_ori = pca.inverse_transform(x_low) print(x_ori[:3], x_ori.shape) # [[5.08303897 3.51741393 1.40321372 0.21353169] # [4.7462619 3.15749994 1.46356177 0.24024592] # [4.70411871 3.1956816 1.30821697 0.17518015]] (150, 4)
- 5. 변동성 비율 확인
⭐ 전체 변동성에서 개별 PCA 결과(개별 component) 별로 차지하는 변동성 비율 확인print(pca.explained_variance_ratio_) # [0.92461872 0.05306648] # -> 결과 Component_1 이 전체 변동성의 92% 가량을 차지함 # -> 결과 Component_2 이 전체 변동성의 5% 가량을 차지함 # -> 전체 변동성은 97% 가량을 나타냄 # -> 결론 : 원본 데이터 변동성의 97% 설명력을 가진다.
- 6. 차원 축소 데이터
df = pd.DataFrame(x_low, columns=['f1', 'f2']) print(df.head(2)) # f1 f2 # 0 -2.684126 0.319397 # 1 -2.714142 -0.177001

데이터 사이언티스트를 목표로 하는 개발자