88일차 시작.... (상관관계분석)
Pandas를 사용한 공분산, 상관계수 구하기공분산과 상관계수두 독립변수의 공분산 확인과 문제점두 독립변수의 공분산, 상관계수 구하기머신러닝 Map상관계수 시각화 (scatter + heatmap)
0
[교육] Python Analysis
목록 보기
15/15

📊 머신러닝
📌 머신러닝 Map
- 머신러닝 맵
-- MachineLearning --
├── Datapreprocessing [데이터 전처리]
│ ├── missing-data
│ ├── categorical-data
│ ├── splitting-the-dataset
│ └── feature-scaling
│
├── Regression [회귀]
│ ├── simple-linear-regression
│ ├── multiple-linear-regression
│ ├── polynomial-regression
│ ├── support-vector-regression
│ ├── decision-tree-regression
│ ├── random-forest-regression
│ └── Evaluating Regression Models Performance
│
├── Classification [분류]
│ ├── Logistic Regression
│ ├── K-Nearest Neighbors (K-NN)
│ ├── Support Vector Machine (SVM)
│ ├── Kernel SVM
│ ├── Naive Bayes
│ ├── Decision Tree Classification
│ ├── Random Forest Classification
│ └── XGBoost
│ └── Evaluating Classification Models Performance
│
├── Clustering [클러스터링]
│ ├── K-Means Clustering
│ └── Hierarchical Clustering
│
├── Association Rule Learning [연관 분석]
│ └── Apriori
│
├── Reinforcement Learning [강화 학습]
│ ├── Upper Confidence Bound (UCB)
│ └── Thompson Sampling
│
├── Natural Language Processing [자연어 처리]
│ ├── Prepare for NLP
│ └── Bag of words
│
├── Deep Learning [딥러닝]
│ ├── Artificial Neural Networks
│ └── Convolutional Neural Networks
│
├── Dimensionality Reduction [차원 축소]
│ ├── Principal Component Analysis (PCA)
│ ├── Linear Discriminant Analysis (LDA)
│ └── Kernel PCA
│
└── Model Selection
📊 상관관계 분석
📌 공분산과 상관계수
- 공분산
- 두 개 이상의 독립변수 사이의 관련성을 나타내는 척도 (방향성)
- np.cov(x, y)
- 상관계수
- 공분산을 표준화한 것이다. (방향성, 관련성 크기[-1 ~ 1 사이 값])
- 등간척도 : np.corrcoef(x, y)
- 서열척도 : stats.spearmanr(x, y)
- 참고
[ 공분산, 상관계수는 비선형 데이터에 대해 적용되지 않는다. ]
📌 두 독립변수의 공분산 확인과 문제점
- 1. 두 개의 독립변수 생성
a1 = np.arange(1, 6) a2 = np.arange(2, 7) print(a1) print(a2) # [1 2 3 4 5] # [2 3 4 5 6]
- 2. 두 독립변수에 대해 공분산 구하기
# 양의 방향성 print(np.cov(a1, a2)) # [[2.5 2.5] # [2.5 2.5]] # -> 양의 관계성을 갖는다. # 음의 방향성 print(np.cov(a1, np.arange(6, 1, -1))) # [[ 2.5 -2.5] # [-2.5 2.5]] # -> 음의 관계성을 갖는다. # 관계를 갖지 않는다. print(np.cov(a1, (3,3,3,3,3))) # [[2.5 0. ] # [0. 0. ]] # -> 관계가 없다.
- 3. 공분산의 문제점 확인
print(np.cov(a1, a2)) # [[2.5 2.5] # [2.5 2.5]] # -> 양의 관계성을 갖는다. print(np.cov(np.arange(10, 60, 10), np.arange(20, 70, 10))) # [[250. 250.] # [250. 250.]] # -> 양의 관계성을 갖는다. # => 결과적으로 두 개의 예시에서는 모두 양의 관계를 갖지만 크기 차이는 정확하게 알 수 없다.
📌 두 독립변수의 공분산, 상관계수 구하기
- 1. 두 개의 독립변수 생성
x = [8, 3, 6, 6, 9, 4, 3, 9, 3, 4] print('x 평균 : ', np.mean(x)) print('x 분산 : ', np.var(x)) # x 평균 : 5.5 # x 분산 : 5.45 y = [6, 2, 4, 6, 9, 5, 1, 8, 4, 5] print('y 평균 : ', np.mean(y)) print('y 분산 : ', np.var(y)) # y 평균 : 5.0 # y 분산 : 5.4
- 2. 두 독립변수에 대해 공분산 구하기
print('x, y 공분산 : ', np.cov(x, y)[0, 1]) # x, y 공분산 : 5.222222222222222 # 양의 관계를 갖는다.
- 3. 두 독립변수에 대해 상관계수 구하기
print('x, y 상관계수 : ', np.corrcoef(x, y)[0, 1]) # x, y 상관계수 : 0.8663686463212855 # 양의 방향으로 강한 관계를 갖는다.
📌 Pandas를 사용한 공분산, 상관계수 구하기
- 1. 데이터 준비
df = pd.read_csv('../testdata/drinking_water.csv') print(df.head(3)) # 친밀도 적절성 만족도 # 0 3 4 3 # 1 3 3 2 # 2 4 4 4
- 2. pandas 공분산 구하기
print(df.cov()) # 친밀도 적절성 만족도 # 친밀도 0.941569 0.416422 0.375663 # 적절성 0.416422 0.739011 0.546333 # 만족도 0.375663 0.546333 0.686816
- 3. pandas 상관계수 구하기
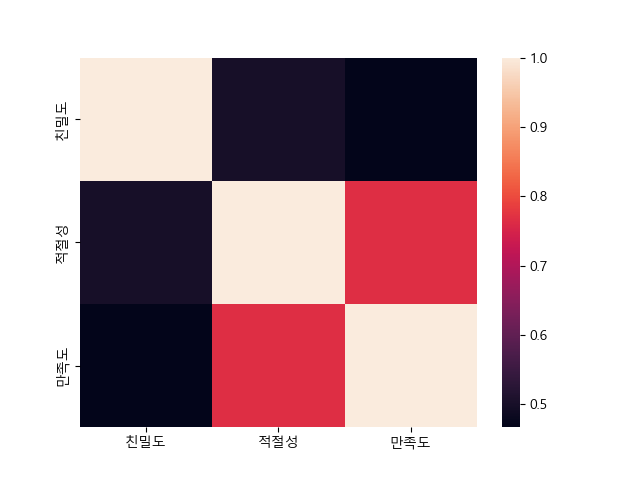
print(df.corr()) # 친밀도 적절성 만족도 # 친밀도 1.000000 0.499209 0.467145 # 적절성 0.499209 1.000000 0.766853 # 만족도 0.467145 0.766853 1.000000 # 적절성과 만족도의 관계가 양의 방향으로 강하다. # print(df.corr(method='pearson')) # 등간, 비율 척도. 정규성을 따름 # print(df.corr(method='spearman')) # 서열 척도. 정규성을 따르지 않음 # print(df.corr(method='kendall')) # spearman과 유사
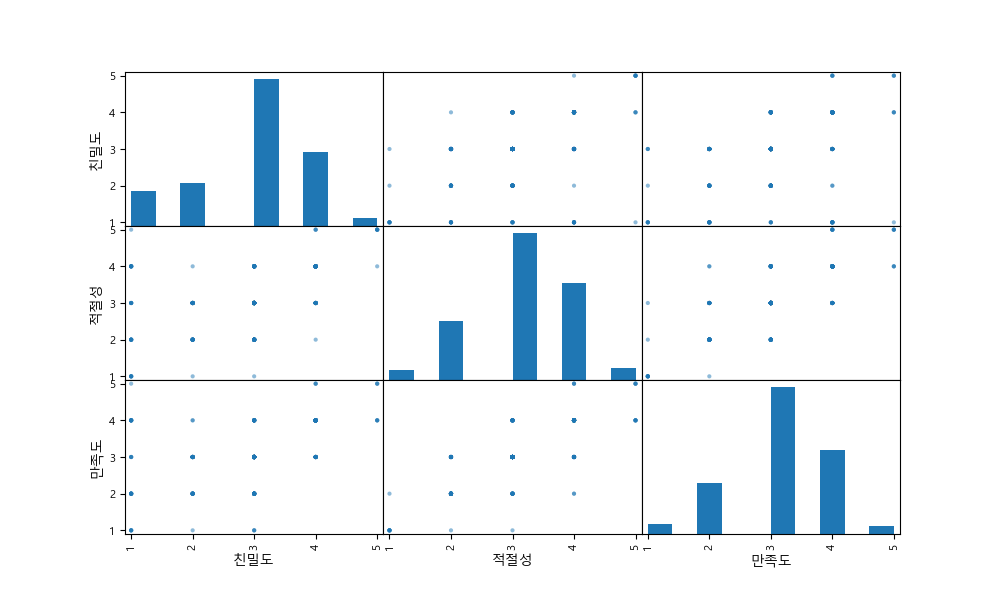
📌 상관계수 시각화 (scatter + heatmap)
- 1. scatter plot으로 시각화
from pandas.plotting import scatter_matrix attr = list(df.columns) scatter_matrix(df[attr], figsize=(10, 6)) plt.show()
- 2. heatmap으로 시각화
import seaborn as sns sns.heatmap(data=df.corr()) plt.show()

데이터 사이언티스트를 목표로 하는 개발자