Git
Git의 기초
✅ 스냅샷

큰 틀에서 봤을 때 VCS 시스템 대부분은 관리하는 정보가 파일들의 목록
- 각 파일의 변화를 시간순으로 관리하면서 파일들의 집합을 관리
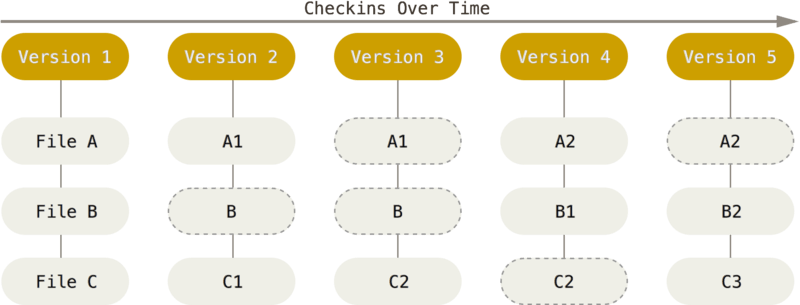
Git은 데이터를 파일 시스템 스냅샷의 연속으로 취급하고 크기가 아주 작다.
- 파일이 달라지지 않았으면 Git은 성능을 위해서 파일을 새로 저장하지 않는다.
- Git은 데이터를 스냅샷의 스트림처럼 취급
✅ 거의 모든 명령을 로컬에서 실행
거의 모든 명령이 로컬 파일과 데이터만 사용하기 때문에 네트워크에 있는 다른 컴퓨터는 필요 없다 = 빠르다.
✔️ 프로젝트의 모든 히스토리가 로컬 디스크에 있기 때문에 모든 명령이 순식간에 실행된다. (????? 이해가 안됨)
- 어떤 파일의 현재 버전과 한 달 전의 상태를 비교해보고 싶을 때도 Git은 그냥 한 달 전의 파일과 지금의 파일을 로컬에서 찾는다.
✔️ 네트워크에 접속하고 있지 않아도 커밋할 수 있다
✅ 무결성
Git은 데이터를 저장하기 전에 항상 체크섬을 구하고 그 체크섬으로 데이터를 관리한다.
- Git은 SHA-1 해시를 사용하여 체크섬을 만든다.
- 파일의 내용이나 디렉토리 구조를 이용하여 체크섬을 구한다.
- 실제로 Git은 파일을 이름으로 저장하지 않고 해당 파일의 해시로 저장한다.
✅ Git의 상태
Git에는 세가지 상태가 있다.
1) Committed : 데이터가 로컬 데이터베이스에 안전하게 저장됐다는 것
2) Modified : 수정한 파일을 아직 로컬 데이터베이스에 커밋하지 않은 것
3) Staged : 현재 수정한 파일을 곧 커밋할 것이라고 표시한 상태
-
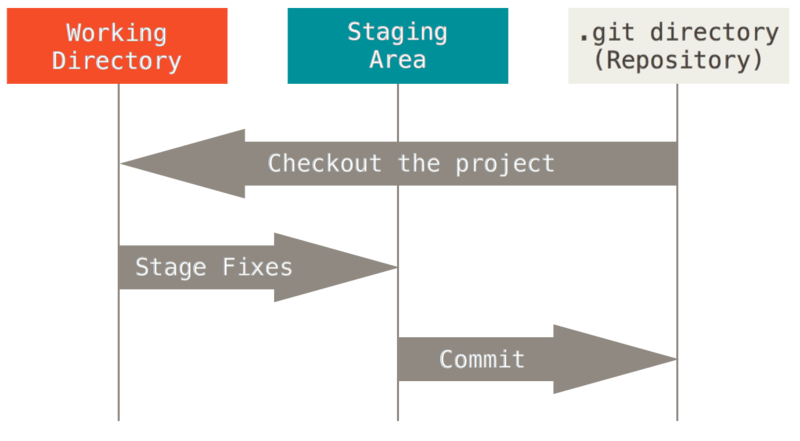
Git directory : Git이 프로젝트의 메타데이터와 객체 데이터베이스를 저장하는 곳
다른 컴퓨터에 있는 저장소를 Clone 할 때 Git 디렉토리가 만들어진다. -
Working Directory : 프로젝트의 특정 버전을 Checkout 한 것
Git 디렉토리는 지금 작업하는 디스크에 있고 그 디렉토리 안에 압축된 데이터베이스에서 파일을 가져와서 워킹 트리를 만든다.
Checkout : 내가 사용할 브랜치를 지정하는 것 -
Staging Area : Git 디렉토리에 있다. 단순한 파일이고 곧 커밋할 파일에 대한 정보를 저장
🚀 Git에서 하는 일의 순서
- 워킹 트리에서 파일을 수정한다.
- Staging Area에 파일을 Stage 해서 커밋할 스냅샷을 만든다. 모든 파일을 추가할 수도 있고 선택하여 추가할 수도 있다.
- Staging Area에 있는 파일들을 커밋해서 Git 디렉토리에 영구적인 스냅샷으로 저장한다.
Git 디렉토리에 있는 파일들은 Committed 상태이다.
-> 파일을 수정하고 Staging Area에 추가했다면 Staged이다.
-> 그리고 Checkout 하고 나서 수정했지만, 아직 Staging Area에 추가하지 않았으면 Modified이다.
수정하고 저장하기
✅ 파일의 라이프사이클

Git 저장소를 만들었고 워킹 디렉토리에 checkout도 했다
-> 파일을 수정하고 파일의 스냅샷을 커밋하고 싶을 때
워킹 디렉토리의 모든 파일은 Tracked / Untracked
- Tracked : 이미 스냅샷에 포함되어 있던 파일 = 간단히 git이 알고 있는 파일
- Modified : 수정함
- Unmodified : 수정하지 않음
- Staged : 커밋으로 저장소에 기록할 파일
- Untracked : 나머지 파일들
워킹 디렉토리에 있는 파일 중 스냅샷에도 Staging Area에도 포함되지 않은 파일이다.
ex ) 처음으로 만들어진 파일 (Stage나 Commit에 올라가지 않은 상태)
✔ 처음 저장소를 Clone 하면 모든 파일은 Tracked이면서 Unmodified 상태이다. 파일을 Checkout 하고 나서 아무것도 수정하지 않았기 때문에 그렇다
마지막 커밋 이후 아직 아무것도 수정하지 않은 상태에서 어떤 파일을 수정하면 Git은 그 파일을 Modified 상태로 인식한다. 실제로 커밋을 하기 위해서는 이 수정한 파일을 Staged 상태로 만들고, Staged 상태의 파일을 커밋한다.
git add
👏 git add . 을 하면 modified가 staged가 되는 것
- add 는 untracked 파일도 tracked/staged 상태로 바꿈
.gitignore는 이 부분을 막아주는 역할을 하는 것
-> git add 를 하면 untracked 파일을 모두 stage로 추가하는데 .gitignore 에 있는 파일들은 모두 untracked로 놔두도록 만든다는 것.
✔ 그래서 staged가 한번이라도 된 파일을 git ignore하면 영향 x
git rm -- cached 를 해서 staged 에서 파일을 지우고 untracked 상태로 바꿔줘야함
git commit
git은 staged 상태 파일들을 모아서 커밋 객체로 만든다.
✔ 커밋 객체에는
- 직전 커밋에 대한 포인터 참조
- 현재 파일 상태를 저장한 DB에 대한 포인터
- 커밋한 사람 ID와 메세지
✔ 커밋할 때
- 폴더 구조는 tree 형식으로
- 파일 데이터는 blob라는 포맷으로 별도 저장함.
-> 그래서 unmodified 파일의 경우에는 이미 똑같은 내용이 blob로 저장되어 있기 때문에 이전 커밋에서 저장해둔 blob 위치 참조를 똑같이 넣어준다.
그래서 하나의 커밋에는 변경사항만 있는게 아니라, 해당 시점의 전체 파일 데이터가 모두 들어가 있는 것
🚀 커밋이 끝나면 : unmodified 상태가 됨 (add 불가능)
🚀 조금이라도 변경이 되면 : 다시 modified 상태가 됨 -> 이 변경사항을 staged로 올려서 커밋에 포함시킬 수 있도록 함
결국
한번 tracked가 되면 staged -> unmodified -> modified -> staged 로 계속 돌게 됨
이렇게 하나의 스냅샷은 이전 커밋을 기반으로 하고 있으니까 순서대로 연결되어서 히스토리가 된다. (git log 로 확인 가능)
근데 하나의 커밋(스냅샷)을 기반으로 하는 스냅샷을 2개 이상 만들 수도 있음. 그게 브랜치이다.
브랜치
코드를 통째로 복사하고 나서 원래 코드와는 상관없이 독립적으로 개발을 진행할 수 있는데, 이렇게 독립적으로 개발하는 것을 브랜치라고 한다.
