요즘 Java를 공부하고 있습니다.
Java를 공부하기 전, Java에 대한 인식은 오래된 언어, 사장되어 가는 언어 등 부정적인 이미지를 가지고 있었습니다.
그로 인해 매력을 느끼지 못했는데 회사의 서버를 다루기 위해 Java를 시작하게 되었고
Java를 다루면서 느낀 것은 오래된 언어가 나쁜 언어는 아니라는 것입니다.
오늘은 Java의 CollectionFramework를 정리해보려고 합니다.
Java는 객체들을 효율적으로 다룰 수 있도록 interface와 implement class를 java.util 패키지에서 제공하는데 이를 총칭해서 CollectionFramework라고 합니다.
주요 interface로는 List, Set, Map이 있습니다.
1. List
1- 1. ArrayList
ArrayList 객체를 생성하면 내부에 10개의 객체를 저장할 수 있는 초기 용량을 가지게 됩니다. 저장되는 객체 수가 늘어나면 용량이 자동으로 증가합니다. 또한, 객체 삽입과 삭제에 따라 인덱스 자동으로 밀려나거나 당겨집니다.
예를 들어 4번 인덱스의 객체를 삭제한 경우, 5번부터 9번까지의 객체들의 인덱스가 4번부터 8번으로 당겨지는 것입니다.
코드로 이를 확인하면 다음과 같습니다.
import java.util.*;
public class ArrayListExample {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Java");
list.add("JDBC");
list.add("Servlet/JSP");
list.add(2, "Database");
list.add("iBATIS");
int size = list.size();
System.out.println("총 객체수: " + size);
System.out.println();
for(int i=0; i<list.size(); i++) {
String str = list.get(i);
System.out.println(i + ":" + str);
}
System.out.println();
list.remove(2); // -> 2번에 있던 Database 삭제, 그만큼 뒤에 있던 객체들이 한칸 씩 이동
list.remove(2); // -> 2번에 있던 Servlet/JSP 삭제, 그만큼 뒤에 있던 객체들이 한칸 씩 이동
list.remove("iBATIS");
for(int i=0; i<list.size(); i++) {
String str = list.get(i);
System.out.println(i + ":" + str);
}
}
}결과
총 객체수: 5
0:Java
1:JDBC
2:Database
3:Servlet/JSP
4:iBATIS
0:Java
1:JDBC1-2. Vector
Vector는 synchronized method로 구성되어 있기 때문에 멀티 스레드가 동시에 Vector의 메소드들을 실행할 수 없고,
하나의 스레드가 메소드를 완료해야만 다른 스레드가 Vector의 메소드를 실행할 수 있습니다.
이로 인해 멀티스레드 환경에서 안전하게 객체를 추가, 삭제할 수 있습니다.
1-3. LinkedList
ArrayList와 Vector의 내부구조는 같습니다. 이 둘은 내부 배열에 객체를 저장해서 관리합니다.
하지만, LinkedList는 인접 참조를 링크해서 chain 처럼 객체를 관리합니다.
다음 그림을 보면 이해가 쉽습니다.
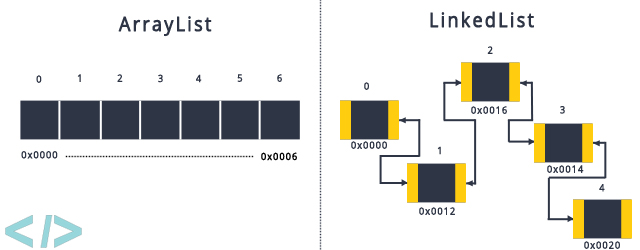
위와 같은 구조 때문에 LinkedList는 여러번 객체를 추가, 삭제하기에 좋습니다.
왜냐하면 ArrayList나 Vector의 경우, 객체를 추가 혹은 삭제하게 되면 객체들의 인덱스를 한칸씩 당겨야하니
객체들을 하나하나 옮겨야 합니다.
하지만 LinkedList의 경우, 객체를 추가 혹은 삭제하게 되면 해당 객체의 앞, 뒤 객체의 링크만 변경하면 됩니다.
만약, 위의 사진에서 3번 인덱스의 객체를 지우는 것을 그림으로 표현하면 다음과 같습니다.
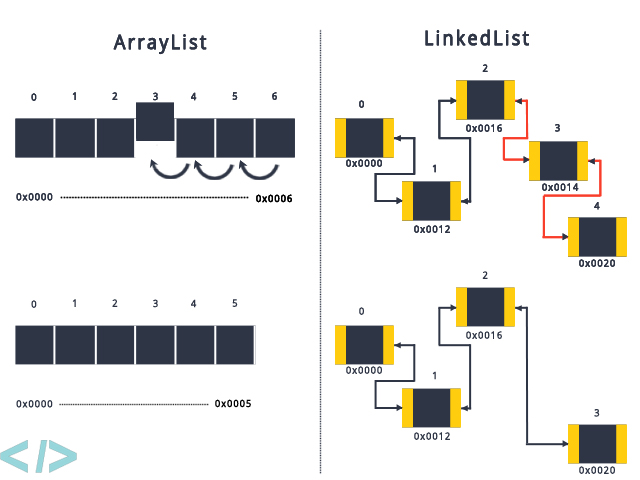
그러므로, 빈번한 객체 삽입/삭제가 일어나는 상황이라면 ArrayList 보다는 LinkedList가 성능이 더 좋습니다.
1-4. ArrayList Vs LinkedList
다음 코드는 ArrayList와 LinkedList의 성능을 비교하는 코드입니다.
각 List의 0번째 인덱스에 새로운 객체를 계속해서 추가합니다.
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class LinkedListExample {
public static void main(String[] args) {
List<String> list1 = new ArrayList<String>();
List<String> list2 = new LinkedList<String>();
long startTime;
long endTime;
startTime = System.nanoTime();
for(int i=0; i<10000; i++) {
list1.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.println("ArrayList 걸린 시간: " + (endTime-startTime) + " ns");
startTime = System.nanoTime();
for(int i=0; i<10000; i++) {
list2.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.println("LinkedList 걸린 시간: " + (endTime-startTime) + " ns");
}
}결과
ArrayList 걸린 시간: 28929203 ns
LinkedList 걸린 시간: 3202145 nsArrayList의 경우, add메서드를 실행할 때마다 객체들을 옮겨주어야 해서
LinkedList 보다 시간이 더 걸리는 것을 볼 수 있습니다.
2. Set
Set의 경우 List와 달리 순서가 없고 중복 저장이 안되며 하나의 null만 저장할 수 있습니다.
Set에는 특이한 메서드가 하나 있습니다. iterator라는 메서드입니다.
Set은 인덱스로 객체를 검색해서 가져올 수 없습니다. 그렇기 때문에 전체 객체를 대상으로 한 번씩 반복해서 가져오는 iterator를 제공합니다.
iterator 메서드를 알아 보기 전에 Iterator라는 interface에 대해 먼저 알아보겠습니다.
Iterator에 선언된 메서드들은 다음과 같습니다.
| Return Type | Method | Description |
|---|---|---|
| boolean | hasNext() | 가져올 객체가 있다면 true, 없다면 false를 return |
| E | next() | Set 컬렉션에 담겨 있는 객체를 return |
| void | remove() | Set 컬렉션에서 객체를 제거 |
Iterator를 이용해 Set에 담겨있는 객체에 접근하는 방법은 다음과 같습니다.
Set<String> set = ... ;
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
String str = iterator.next();
}Iterator를 사용하지 않더라도 for-loop을 이용해서 전체 객체를 대상으로 접근할수 있습니다.
Set<String> set = ... ;
for(String str : set) {
//do something;
}2-1. HashSet
HashSet은 객체들을 순서 없이 , 중복 없이 저장합니다.
HashSet이 판단하는 동일한 객체란 같은 인스턴스만을 뜻하는 것이 아닙니다.
HashSet에 저장하기 전에 객체의 hashCode() 메서드를 호출해서 HashSet에 저장되어 있는 객체들의 HashCode와 비교합니다.
만약, 동일한 HashCode가 있다면 equals() 메서드로 두 객체를 비교해서 true라면 동일한 객체로 판단하고 중복 저장을 하지 않습니다.
여기서 HashCode란, 주소와는 다른 개념이며 한 객체의 id 같은 고유값입니다.
String 클래스의 경우, 같은 문자열이지만 다른 인스턴스라면 어떻게 저장될까요?
import java.util.HashSet;
import java.util.Set;
public class HashSetExample {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
String java = new String("java");
String _java = new String("java");
set.add(java);
set.add(_java);
for (String str : set) {
System.out.println(str);
}
}
}결과
java다른 인스턴스인데 한번만 출력이 되었습니다. 그 이유는 String 클래스는 hashCode()와 equals() 메서드를 오버라이딩 했기 때문입니다.
다른 인스턴스이더라도 같은 내용을 가지고 있다면 같은 객체로 판단하도록 메서드를 재정의 한 것이죠.
이렇듯, 개발자가 정의하는 class의 인스턴스의 경우
다른 인스턴스이지만 같은 내용물을 가진 객체들을 같은 객체로 판단해야하는 경우가 있습니다.
예를 들어, 다음과 같은 class가 있다고 하겠습니다.
public class Person {
String name;
String registrationNumber;
public Person(String name, String registrationNumber) {
this.name = name;
this.registrationNumber = registrationNumber;
}
} 이름과 주민등록번호가 같다면 같은 사람이라고 보는 것이 일반적입니다.
그런데, java는 다음과 같이 동작합니다.
import java.util.HashSet;
import java.util.Set;
public class HashSetExample {
public static void main(String[] args) {
Set<Person> set = new HashSet<Person>();
Person person1 = new Person("zunky", "111111-1111111");
Person person2 = new Person("zunky", "111111-1111111");
set.add(person1);
set.add(person2);
for (Person person : set) {
System.out.println(person.name);
}
}
}결과
zunky
zunkyHashSet은 hashCode와 equals 메서드를 호출해 객체를 담는다고 했으니 Person의 hashCode와 equals 메서드를 재정의해보겠습니다.
public class Person {
String name;
String registrationNumber;
public Person(String name, String registrationNumber) {
this.name = name;
this.registrationNumber = registrationNumber;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Person) {
Person person = (Person) obj;
return person.name.equals(name) && person.registrationNumber.equals(registrationNumber);
} else {
return false;
}
}
@Override
public int hashCode() {
return name.hashCode() + registrationNumber.hashCode();
}
}위와 같이 Person 클래스를 재정의한 뒤, HashSetExample을 실행하게되면 하나의 객체만 담긴 것을 확인할 수 있습니다.
2-2. TreeSet
TreeSet의 경우, 데이터를 오름차순(ascending order)으로 정렬합니다.
2-3. LinkedHashSet
LinkedHashSet의 경우, 데이터가 입력된 순서대로 관리됩니다.
3. Map
key와 value로 구성된 Map.Entry 객체를 저장하는 구조를 가지고 있습니다.
Map에서 객체를 얻는 방법은 두 가지입니다.
Key를 가져온 뒤, value를 얻는 방법과
entry를 가져온 뒤, key와 value를 얻는 방법이 있습니다.
첫번째 방법은 keySet메서드를 이용하는 방법입니다.
Map<Key, Value> map = ...;
Set<Key> KeySet = map.keySet();
Iterator<Key> keyIterator = keySet.iterator();
while(keyIterator.hasNext()) {
Key key = keyIterator.next();
Value value = map.get(key);
}두번째 방법은 entrySet메서드를 이용하는 방법입니다.
Set<Map.Entry<Key, Value>> entrySet = map.entrySet();
Iterator<Map.Entry<Key, Value>> entryIterator = entrySet.iterator();
whole(entryIterator.hasNext()) {
Map.Entry<Key, Value> entry = entryIterator.next();
Key key = entry.getKey();
Value value = entry.getValue();
}3-1. HashMap
Map interface를 구현한 대표적인 Map collection중 하나는 HashMap입니다. HashMap의 키로 사용할 객체는 hashCode()와 equals() 메서드를 오버라이딩해서 동등 객체가 될 조건을 만들어줘야 합니다. 다른 인스턴스여도 동등하다면 같은 키로 간주하고 중복 저장되지 않도록 하기 위해서죠.
또한, Key와 Value의 Type은 primitive Type을 사용할 수 없습니다.
즉, byte, short, int, float, double, boolean, char를 사용할 수 없습니다.
interface와 class만이 사용 가능합니다.
한 학생의 시험성적을 HashMap을 이용해 구현해보도록 하겠습니다.
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class HashMapExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("Korean", 90);
map.put("Math", 95);
map.put("English", 85);
map.put("Physics", 90);
System.out.println("map.get() 메서드로 값을 알아내는 경우");
System.out.println("English : " + map.get("English"));
System.out.println("Korean : " + map.get("Korean"));
System.out.println("Math : " + map.get("Math"));
System.out.println("Physics : " + map.get("Physics"));
System.out.println();
System.out.println("keySet메서드로 값을 알아내는 경우");
Set<String> keySet = map.keySet();
Iterator<String> keyIterator = keySet.iterator();
while(keyIterator.hasNext()) {
String key = keyIterator.next();
Integer value = map.get(key);
System.out.println(key + " : " + value);
}
System.out.println();
System.out.println("entrySet메서드로 값을 알아내는 경우");
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
Iterator<Map.Entry<String, Integer>> entryIterator = entrySet.iterator();
while(entryIterator.hasNext()) {
Map.Entry<String, Integer> entry = entryIterator.next();
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " : " + value);
}
System.out.println();
}
}
결과
map.get() 메서드로 값을 알아내는 경우
English : 85
Korean : 90
Math : 95
Physics : 90
keySet메서드로 값을 알아내는 경우
English : 85
Korean : 90
Math : 95
Physics : 90
entrySet메서드로 값을 알아내는 경우
English : 85
Korean : 90
Math : 95
Physics : 90그럼 이제 개발자가 정의한 클래스로 Key를 설정해서 HashMap을 다뤄보겠습니다. 이 경우, hashCode(), equals() 메서드를 오버라이딩해서 동등 객체를 인식할 조건을 만들어줘야 합니다.
위의 HashSet을 다룰 때, 두 메서드를 오버라이딩한 People class를 이용해 HashMap을 다뤄보겠습니다.
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
Map<Person, String> map = new HashMap<Person, String>();
map.put(new Person("zunky", "111111-1111111"), "Student");
map.put(new Person("zunky", "111111-1111111"), "Developer");
System.out.println("총 Entry 수 : " + map.size());
map.forEach((person, role)
-> System.out.println("person: " + person.name +", role: " + role));
}
}
결과
총 Entry 수 : 1
person: zunky, role: DeveloperPerson 객체의 필드값이 같아 동등 객체로 인식하여 하나만 저장된 것을 확인할 수 있습니다.
위 코드에서 Iterator을 사용하지 않고 forEach() 메서드를 사용해서 Entry에 접근한 것을 볼 수 있는데 개인적으로 Iterator를 이용하는 것보다 위 방법을 이용하는 것을 선호합니다.
3-2. HashTable
HathTable은 HashMap과 동일한 내부 구조를 가지고 있습니다. HashTable도 Key로 사용할 객체는 hashCode(), equals() 메서드를 오버라이딩해서 동등객체가 될 조건을 만들어줘야 합니다.
HashMap과의 차이점은 synchronized 메서드로 구성되어 있기 때문에 멀티스레드가 동시에 Hashtable의 메서드들을 실행할 수 없습니다. 그렇기 때문에 하나의 스레드가 실행을 완료해야 다른 스레드를 실행할 수 있습니다. 그러므로 멀티 스레드 환경에서 안전하게 객체를 추가, 삭제할 수 있습니다.
3-3. TreeMap
TreeMap의 경우, 데이터를 오름차순(ascending order)으로 정렬합니다.
3-4. LinkedHashMap
LinkedHashMap의 경우, 데이터가 입력된 순서대로 관리됩니다.
4. Stack, Queue
LIFO(Last In First Out)은 나중에 넣은 객체가 먼저 나오는 자료구조를 말합니다. Collection Framework에는 LIFO 자료구조를 제공하는 Stack 클래스를 제공합니다.
FIFO(First In First Out)은 먼저 넣은 객체가 먼저 빠져나가는 구조를 말합니다. Collection Framework에는 FIFO 자료구조를 제공하는 Queue 인터페이스를 제공합니다.
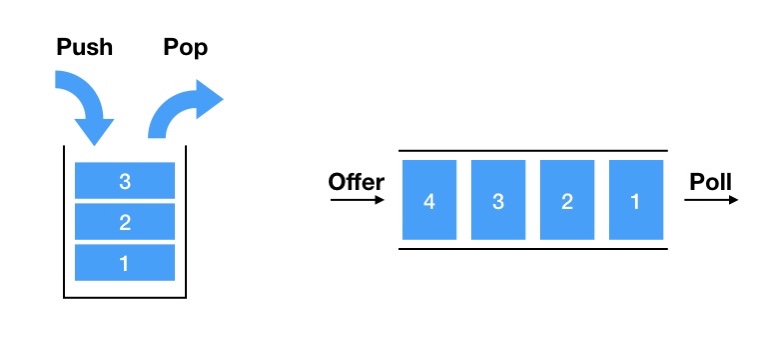
4-1. Stack
Stack 클래스의 주요 메서드는 다음과 같습니다.
| method | return Type | description |
|---|---|---|
| push(Item item) | Item | 주어진 객체를 스택에 넣습니다. |
| pop() | Item | 스택의 마지막 객체를 가져오며 해당 객체를 스택에서 제거합니다. |
| peek() | Item | 스택의 마지막 객체를 가져오며 해당 객체를 스택에서 제거하지 않습니다. |
4-2. Queue
Queue를 구현한 대표적인 클래스는 LinkedList입니다.
그러므로 Queue를 사용하고 싶다면 LinkedList를 사용하면 됩니다.
다음은 Queue의 주요 메서드입니다.
| method | return Type | description |
|---|---|---|
| offer(Item item) | boolean | 주어진 객체를 큐에 넣습니다. |
| poll() | Item | 큐의 첫번째 객체를 가져오며 해당 객체를 큐에서 제거합니다. |
| peek() | Item | 큐의 첫번째 객체를 가져오며 해당 객체를 큐에서 제거하지 않습니다. |
