서론
왜 oom 발생했는가?
- 프로젝트에서 서버가 아예 먹통이 된 경험을 했다...
- 일단 다운된 서버에 어플리케이션을 재 가동시켜 사용할 수 있게 만들긴 했지만 어디서 어떻게 터졌는지 몰랐기에 원인 파악부터 먼저 시작했다…
- 다운된 서버에 접속이 불가능한 상태여서 스프링 어플리케이션에 대한 로그를 확인하고 싶었는데 확인을 못했다..심지어 어떻게든 찍힌 로그를 확인하려고 서치하는 중에..다른 분이 서버를 재부팅해서 확인할 방법이 아예 없어졌다.😭😭
- 분명 로컬에서는 단위, 통합 테스트 모두 통과한 상태여서 문제가 생길 API가 존재하지 않을 것 같은데..심지어 검색을 통해 일부로 대용량 대용량 근태 데이터도 확인을 완료한 상태라 로컬과 서버에 어떤 차이가 있는지 확인을 해보았다.
- 이 당시에는 내가 이제 막 JVM Heap에 대해서 따로 공부하고 있던 시절이라 바로 메모리를 확인해봐야 된다는 생각은 못하게 되었다…
본론
조치 방법 (생각 나는 대로)
- 일단 나는 OOM이 터졌다는 가정을 하고 몇몇가지 가설을 두기 시작하였다.
- 대용량을 가져올 수 있는 API를 탐색을 하였고 해당 API에 대한 테스트를 진행해 볼 예정이다. 해당 API는 아래와 같다.
- 검색 API 통해 가져오는 대용량의 데이터가 OOM을 발생시키지 않았는가?
- Excel Download API에서 Spring Application 내에서 모든 작업이 처리 돼서 OOM을 발생시키지 않았는가?
- 위 두가지가 의심이 되는 API들이다.
- 테스트를 진행함에 따라 JVM Heap에 메모리가 어떻게 변하는지 확인하기 위해 모니터링 시스템을 붙였다.
JVM Heap 모니터링
- JVM Heap 모니터링 하기 위해 요즘 회사에서들 많이 사용하는 Grafana를 사용하고 싶었지만, 언제 서버가 또 다운될지 모르는 상태에서 Grafana처럼 학습 곡선이 깊은 툴보단 직관적으로 바로 확인하기 위해, VisualVM을 사용하기로 마음 먹었다.
- VisualVM에서 remote로 서버도 바로 확인이 가능하여 연결해두고 Heap Dump를 확인해보았다.
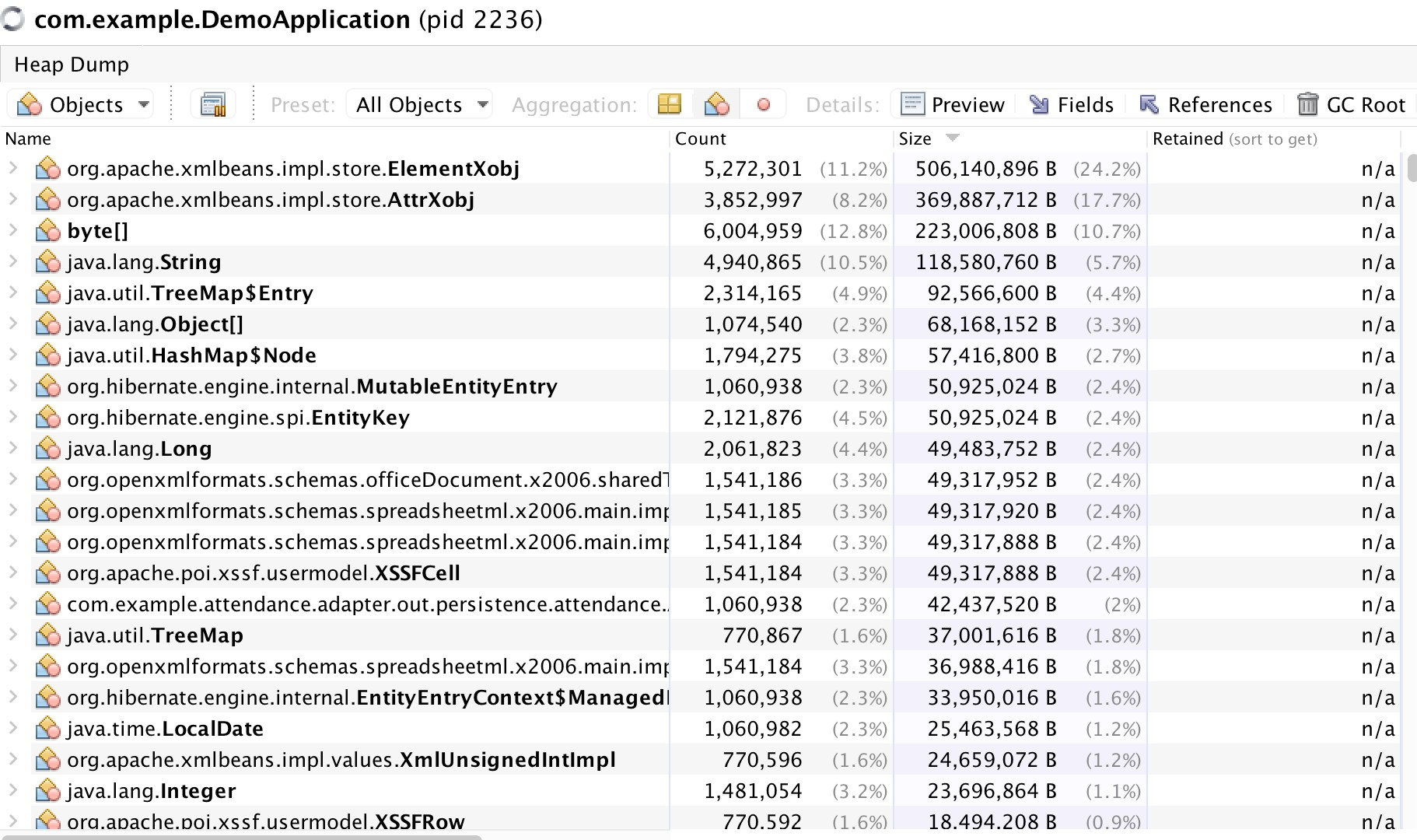
- JVM Heap Dump를 분석해보니 XmlBeans가 전체 메모리 중 40%를 차지하고 있었다.
- 아마 Byte와 String도 Excel을 만들 때 사용하기 때문에 거의 65% 정도를 사용있다고 봐야한다.
- 따라서 원인은 어느정도 측정이 되었지만, 혹시 모를 다른 원인도 찾아봐야하니 API Test를 진행 전 여러 가설들을 세우고 진행해 보도록하겠다.
API Test
- 원래는 성능 테스트로 개인적으로 공부한 Jmeter를 사용하여 하고 싶었지만..지금은 그럴 시간이 없어서 Postman으로 API에 대한 Test를 진행하였다.
- 검색 API로 20만건에 데이터를 가져오는 것을 5명이 동시에 요청해보았다.
- JVM Heap CPU, Memory 둘다 모두 정상적인 반응을 보인것으로 확인이 되었다.
- Excel Download API로 Row가 50만 건인 데이터를 5명이 동시에 요청해보았다.
- JVM Heap CPU 사용량이 97%가 되었고, GC가 발동하여 OOM 예외가 발생하였다…..
- 해당 API가 문제가 있어 그 즉시, 바로 Heap Dump를 생성해서 확인해보았다.
- Heap Dump를 아직 확실하게 파악하는 것은 아니지만, xmlBean이 많은양의 메모리를 차지하고 있는 것으로 파악이 되었다.
- xmlBean = XSSFWorkbook = xml 파일을 자바 클래스로 변환하는 기능을 제공하는 라이브러리
- 원인은 확실하게 찾았으니 이제 어떻게 수정해야하는지 파악해야한다.
문제 해결 방법
- XSSFWorkbook의 어떤 문제가 있어서 메모리를 많이 잡아먹는지 파악한다.
- 지금은 하나의 Spring Application에서 모든 것을 처리하는데 Storage를 따로 생성하여 Application에 메모리 부하를 줄이는 방법
- 서버의 램을 증가시킨다.
XSSFWorkbook 메모리 누수
- XSSFWorkbook은 찾아보니 아래와 같은 메모리 누수를 발생할 수 있는 원인들이 존재했다.
- 전체 데이터셋의 메모리 로딩
XSSFWorkbook는 처리하는 엑셀 파일의 전체 데이터를 메모리에 로드한다.- 큰 데이터셋을 다룰 경우, 이는 상당한 양의 메모리를 소비하며, 이는 서버의 메모리 용량에 따라 Out Of Memory (OOM) 에러를 발생시킬 수 있다.
- 메모리 효율성의 부족
XSSFWorkbook는 파일의 모든 부분을 메모리에 상주시키는 방식으로 구현되어 있다.- 이는 작은 파일에서는 문제가 되지 않지만, 수만 또는 수백만 행의 데이터를 포함하는 대용량 파일을 처리할 때 메모리 사용량이 급격히 증가한다.
- 가비지 컬렉션 부담
- 대용량 파일을 처리하는 동안,
XSSFWorkbook는 많은 수의 임시 객체를 생성할 수 있다. - 이는 가비지 컬렉터에 부담을 주며, 시스템의 전체 성능에 영향을 줄 수 있다.
- 대용량 파일을 처리하는 동안,
- 위와같은 문제점이 존재하여, 사내 서비스가 멈췄던 것 같다.
SXSSFWorkbook 사용하기
- XSSFWorkbook의 방식인 모든 데이터를 메모리에 로드해서 처리하는 방식이 아닌, SXSSFWorkbook의 방식인 스트리밍 방식을 채택하여 사용하였다.
- 스트리밍 방식의 장점으로는 아래와 같다.
- 엑셀 파일의 일부 데이터만 메모리에 유지하여 메모리의 효율성이 향상된다.
- 대용량 데이터를 처리하기 좋다.
ALL For One Spring Application
- 말은 장엄하게 써두었지만…그냥 Spring Application 안에 모든 서비스가 있다라는 뜻이다…
- 물론 Storage 같은 서비스도 없기에 지금은 하나의 서버 안에 파일 시스템에서 엑셀을 관리하고 있다…
옛날에 나야 눈 감아…
- 서버를 운영하다보니 계속해서 쌓여 서버의 메모리와 디스크 공간이 점점 압박을 느낄수 밖에 없는 구조였다.
- 이는 즉, JVM Heap에 메모리와 연관이 되는데 왜냐하면 지금은 10만, 20만 row를 가진 엑셀이지만 점점 더 커져서 100만이 됐을 경우는 어떻게 해결할 것 인가?
- 그 땐 코드상에서 처리하는 것도 한계가 있을 것이라고 파악이 된다.
- 따라서 JVM Heap Memory를 늘려줄 수 밖에 없는 상황에 놓여있는데, 엑셀 파일이 서버의 로컬 파일 시스템에 저장 되고 있어서 늘릴수도 없는 노릇이 될 것이다.
- 이런 사항을 미연에 방지하기 위해 파일 시스템을 때서 Storage 사용하기로 마음 먹었다.
- Storage는 S3 Bucket을 이용하였고, 해당 코드는 아래와 같다.
public class AwsS3Service { private final AmazonS3 amazonS3; @Value("${cloud.aws.s3.bucket}") private String bucket; private static final String EXCEL_URL_PREFIX = "https://s3-bucket-url"; public String uploadExcelToS3(SXSSFWorkbook workbook, String originalFilename) { String fileName = createFileName(originalFilename); String excelUrl = EXCEL_URL_PREFIX + fileName; try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) { workbook.write(outputStream); ByteArrayInputStream inputStream = new ByteArrayInputStream(outputStream.toByteArray()); ObjectMetadata metadata = new ObjectMetadata(); metadata.setContentLength(outputStream.size()); amazonS3.putObject(new PutObjectRequest(bucket, fileName, inputStream, metadata) .withCannedAcl(CannedAccessControlList.PublicRead)); return excelUrl; } catch (IOException e) { log.error("Error uploading file to S3", e); throw new RuntimeException("Error uploading file to S3", e); } } }- 처음 추가했을 땐, 위와 같이 사용을 하였는데 테스트를 진행함에 있어서 해당 코드는 메모리를 많이 잡아먹는 것으로 파악이 되었다.
- 메모리를 많이 잡아 먹는 코드
try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) { workbook.write(outputStream); ... }- 엑셀 파일 전체 데이터가
ByteArrayOutputStream메모리 버퍼에 저장된다.
ByteArrayInputStream inputStream = new ByteArrayInputStream(outputStream.toByteArray());outputStream.toByteArray()메서드를 호출하면,outputStream에 저장된 데이터(엑셀 파일의 내용)가 바이트 배열로 변환된다. 이 바이트 배열은 전체 파일 데이터를 메모리에 보유하게 된다.- 생성된 바이트 배열을 기반으로
ByteArrayInputStream이 초기화되며, 이 스트림은 S3 업로드에 사용된다.
- 엑셀 파일 전체 데이터가
- 따라서 엑셀 파일에 대한 전체 데이터가 메모리에 쌓이게 되는 것이다.
- 대용량 데이터 엑셀이라면 메모리에 다 담아두기에 OOM이 발생할 가능성이 크다.
- 그래서 해결책으로 2가지 방법을 생각해보았다.
- S3 Bucket에 엑셀 파일을 업로드시 스트리밍 방식을 사용하여 업로드한다.
- 엑셀 데이터 페이징 기법을 적용한다.
-
S3 Bucket 스트리밍 업로드
public void uploadExcelFileToS3(SXSSFWorkbook workbook, String fileName) throws IOException { // 파일을 디스크에 임시로 저장합니다. File tempFile = File.createTempFile("excel", ".xlsx"); workbook.write(new FileOutputStream(tempFile)); // TransferManager를 사용하여 파일을 스트리밍 방식으로 S3에 업로드합니다. TransferManager transferManager = TransferManagerBuilder.standard() .withS3Client(amazonS3) .build(); // S3에 업로드를 시작합니다. Upload upload = transferManager.upload(bucketName, fileName, tempFile); // 업로드가 완료될 때까지 기다립니다. upload.waitForCompletion(); // 임시 파일을 삭제합니다. tempFile.delete(); }- 스트리밍 업로드는 파일을 메모리에 전부 로드하지 않기 때문에, 메모리 사용량을 크게 줄일 수 있다.
- 대규모 데이터셋을 처리할 때 메모리 제약 없이 업로드할 수 있어 OOM 위험이 감소한.
- 대용량 데이터를 더 빠르고 효율적으로 처리할 수 있다.
-
엑셀 데이터 페이징 기법
public void uploadExcelFileToS3WithPaging(String fileName, List<Data> dataList, int pageSize) throws IOException { int totalSize = dataList.size(); int pageCount = (int) Math.ceil((double) totalSize / pageSize); for (int i = 0; i < pageCount; i++) { int startIndex = i * pageSize; int endIndex = Math.min(startIndex + pageSize, totalSize); // 페이지별 데이터를 추출합니다. List<Data> pageData = dataList.subList(startIndex, endIndex); // 페이지별 데이터로 엑셀 파일을 생성합니다. SXSSFWorkbook workbook = createWorkbookForPage(pageData); // 각 페이지를 S3에 업로드합니다. String pageFileName = fileName + "_part_" + i + ".xlsx"; uploadExcelFileToS3(workbook, pageFileName); // 위에서 설명한 스트리밍 업로드 메소드 사용 } }- 각 페이지는 작은 데이터셋으로 구성되므로 메모리 사용량을 효과적으로 관리할 수 있다.
- 사용자가 필요한 데이터 부분만 선택적으로 다운로드할 수 있다.
- 페이지별로 데이터를 처리하기 때문에 전체 데이터셋을 한 번에 처리하는 것보다 빠를 수 있다.
- 단, 위 방식은 다운로드 API를 탈 때 다시금 재 병합을 해줘야하는 로직이 불가피하며 메모리와 성능적 측면에서 부하를 줄수 있다.
- 따라서 나는 S3 Bucket에 스트리밍 업로드를 선택하였다.
서버의 램 증설
- 사실 이 방법이 가장 쉬운 방법이다.
- 우리의 서버가 OOM이 발생하게 된 가장 직관적인 이유는 메모리가 부족한 것이다.
- 실제 로컬 환경에서도 JVM Heap Memory가 4GB인데 서버에서는 2GB를 사용하고 있어서 문제가 있는 것이다.
- 사실 JVM Heap Memory를 늘려주는 것은 도커 이미지 파일 안에다 넣거나, 도커를 실행시킬 때 메모리 옵션을 두어 설정해둘 수 있다.
- 하지만 위 방법을 사용하지 않았던 것은 메모리가 부족할 때마다 계속 늘려줄 수도 없는 노릇이라 이참에 한정된 스펙 안에서 처리해보는 것을 경험하기로 결정했다.
물론..서버가 돌아가게 미리 만들어는 두어야하니..잠깐 늘렸다가 줄였다.
결론
위 조치로 어떤 결과가 나왔는가?
- 내가 진행한 것은 두가지로 XSSFWorkbook → SXSSFWorkbook로 변경한 것과 서버 로컬에 파일 시스템 → S3 Bucket으로 변경한 것이다.
- 위 두가지는 모두 메모리와 연관이 있었고, 위 작업을 마치고 다시금 테스트를 해보니 Jvm Heap Memory는 기존에는 OOM 에러가 발생했지만 지금은 250MB ~ 350MB 정도만을 사용하는 것으로 파악이 되었다.
- 1달동안 모니터링을 진행했는데 별 문제가 없어서 다행이라고 생각한다…
OOM이 발생시 대비
- 일단 내가 생각나는대로 적용해두긴 하였는데, 다른 여러방법들이 있을 것 같긴 하다.
- 내가 적용한 것은 아래와 같다.
- Slack에 WebHook을 이용하여 Error 발생시 Log Back 해두기
- APM(Spring Admin) 툴을 이용하여 CPU, Memory가 일정 수준 이상으로 올라가면 Slack에 알람가게 해두기
- JVM 옵션에서 OOM 발생시 heap dump를 자동으로 생성되게 해두기
- 위 방법들은 미연에 방지 + 서버 다운시 대처 방법으로 구성이 되어있다.
- 하나씩 간단하게 설명하자면 아래와 같다.
- Slack Error Monitoring
- Slack에 Web Hook을 이용하여 Springboot Application에서 Error가 발생할 시 Slack에 자동적으로 알람이 가게끔 설정해두었다.
- Spring Admin Notication
- Spring Admin에 Metrics를 이용하여 JVM에 CPU, Memory가 일정 수치를 넘겼을 경우 알람이 가게끔 설정해두었다.
- OOM 예외 발생시 자동으로 Heap Dump 생성하기
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dump/directory
- Slack Error Monitoring
이번 이슈를 토대로 앞으로 공부해볼 내용
- Spring Data JPA Stream
- JVM
- GC
- Memoey Manage

지나가는 개발자