
재귀를 이해하면 파일시스템 순회나 애너그램 생성 같은 새로운 알고리즘을 사용할 수 있게 된다.
13장에서는 코드를 훨씬 더 빠르게 실행시킬 수 있는 알고리즘에서도 재귀가 핵심 기술임을 배운다.
지금까지 살펴본 정렬에는 버블 정렬, 선택 정렬, 삽입 정렬이 있지만 실제로 배열을 정렬할 때 이러한 정렬 방법을 사용하지 않는다. 컴퓨터 언어는 대부분 내장 정렬 함수가 있어 사용자가 스스로 구현하는 데 드는 시간과 노력을 아낄 수 있도록 도와준다.
이 때 컴퓨터가 내부적으로 채택한 정렬 알고리즘이 퀵 정렬(Quick Sort)이다.
퀵 정렬(Quick Sort)이란?
찰스 앤터니 리처드 호어가 개발한 범용 정렬 알고리즘으로,
분할 정복(divide and conquer) 방법을 통해 리스트를 정하는 알고리즘
다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다.
분할 정복(divide and conquer)이란?
그대로 해결할 수 없는 문제를 작은 문제로 분할하여 문제를 해결하는 방법이나 알고리즘
컴퓨터 언어에 내장돼 있음에도 불구하고 퀵 정렬을 알아보는 이유는 퀵 정렬의 동작 방식을 학습함으로써 재귀를 사용해 어떻게 알고리즘의 속도를 크게 향상시키는지 배울 수 있으며, 실제 쓰이고 있는 다른 실용적 알고리즘에도 똑같이 적용할 수 있기 때문이다.
퀵 정렬은 매우 빠른 알고리즘으로 특히 평균 시나리오에서 효율적이다.
최악의 시나리오(역순)에서는 삽입 정렬이나 선택 정렬과 성능이 유사하지만 대부분의 경우 일어나는 평균 시나리오에서는 퀵 정렬이 훨씬 빠르다.
퀵 정렬은 분할(partitioning)이라는 개념에 기반하므로 분할을 먼저 알아보도록 하자.
13.1 분할
배열을 분할(partition)하는 것은 배열로부터 임의의 수(= 피벗, pivot)를 가져와 피벗보다 작은 모든 수는 피벗의 왼쪽에, 피벗보다 큰 모든 수는 피벗의 오른쪽에 두는 것이다.
| 0 | 5 | 2 | 1 | 6 | 3 |
|---|---|---|---|---|---|
| 👆🏽 | 👆 | ✅ |
위와 같은 배열이 있을 때, 가장 오른쪽에 있는 값(3)을 피벗이라고 가정해보자.
그리고 두 포인터를 사용해 하나는 배열 가장 왼쪽 값에, 다른 하나는 피벗을 제외한 가장 오른쪽 값에 할당한다.
그리고 다음 단계를 따라 실제로 분할할 수 있다.
- 왼쪽 포인터를 한 셀씩 오른쪽으로 옮기면서 피벗보다 크거나 같은 값에 도달하면 멈춘다.
- 이어서 오른쪽 포인터를 한 셀씩 왼쪽으로 옮기면서 피벗보다 작거나 같은 값에 도달하면 멈춘다.
또는 배열의 맨 앞에 도달하면 멈춘다.- 오른쪽 포인터가 멈춘 후에는, 둘 중 하나를 선택한다.
3-1. 왼쪽 포인터가 오른쪽 포인터에 도달하거나 넘어섰으면 4단계로 넘어간다.
3-2. 그렇지 않을 경우, 왼쪽 포인터와 오른쪽 포인터가 가리키고 있는 값을 교환한 후 1~3단계를 반복한다.- 왼쪽 포인터가 현재 가리키고 있는 값과 피벗을 교환한다.
위 과정이 끝나면 피벗 왼쪽에 있는 값은 모두 피벗보다 작고, 피벗 오른쪽에 있는 값은 모두 피벗보다 클 것이다.
또한 다른 값들은 아직 완전히 정렬되지 않았지만 피벗 자체는 배열 내에서 올바른 위치에 있게 된다.
예제 적용
| 0 | 5 | 2 | 1 | 6 | 3 |
|---|---|---|---|---|---|
| 👆🏽 | 👆 | ✅ |
- 왼쪽 포인터와 피벗을 비교한다.
왼쪽 포인터0은 피벗 값인3보다 작으므로 다음 단계에서 포인터를 옮긴다.
| 0 | 5 | 2 | 1 | 6 | 3 |
|---|---|---|---|---|---|
| 👆🏽 | 👆 | ✅ |
-
왼쪽 포인터를 한 셀 이동한다.
왼쪽 포인터5는 피벗 값인3보다 크므로 왼쪽 포인터를 멈추고 오른쪽 포인터 비교를 시작한다. -
오른쪽 포인터와 피벗을 비교한다.
오른쪽 포인터6은 피벗 값인3보다 크므로 다음 단계에서 포인터를 옮긴다.
| 0 | 5 | 2 | 1 | 6 | 3 |
|---|---|---|---|---|---|
| 👆🏽 | 👆 | ✅ |
- 오른쪽 포인터를 한 셀 이동한다.
오른쪽 포인터1은 피벗 값인3보다 작으므로 오른쪽 포인터를 멈춘다.
| 0 | 1 | 2 | 5 | 6 | 3 |
|---|---|---|---|---|---|
| 👆🏽 | 👆 | ✅ |
- 두 포인터가 모두 멈췄고, 왼쪽 포인터가 오른쪽 포인터를 넘어서지 않았으므로
두 포인터가 가리키고 있는 값을 교환한 후, 다시 1~3단계를 반복한다.
| 0 | 1 | 2 | 5 | 6 | 3 |
|---|---|---|---|---|---|
| 👆🏽 | 👆 | ✅ |
- 왼쪽 포인터를 이동한다.
왼쪽 포인터2는 피벗 값인3보다 작으므로 다음 단계에서 왼쪽 포인터를 이동한다.
| 0 | 1 | 2 | 5 | 6 | 3 |
|---|---|---|---|---|---|
| 👆🏽👆 | ✅ |
- 왼쪽 포인터를 이동한다. (두 포인터가 같은 값을 가리키게 된다)
왼쪽 포인터5는 피벗 값인3보다 크므로 왼쪽 포인터를 멈춘다.
그리고 왼쪽 포인터가 오른쪽 포인터에 도달했으므로 모든 포인터의 이동을 중지한다.
| 0 | 1 | 2 | 3 | 6 | 5 |
|---|---|---|---|---|---|
| 💯 |
- 왼쪽 포인터가 오른쪽 포인터에 도달했으므로, 왼쪽 포인터와 피벗을 교환한다.
배열이 완전하게 정렬되지는 않았지만 분할이 성공적으로 완료됐다.
즉, 피벗 값인 3보다 작은 수는 피벗 왼쪽에, 큰 수는 피벗 오른쪽에 있게 된다.
또한 3은 배열 내에서 올바른 위치에 있게 된다.
코드로 구현한다면: 분할
다음은 JavaScript로 구현한 SortableArray 클래스이다.
배열을 분할하는 partition 메서드를 포함한다.
기본 코드
class SortableArray {
constructor(array) {
this.array = array;
}
partition(leftPointer, rightPointer) {
let index = rightPointer;
let pivot = this.array[index];
rightPointer -= 1;
while (true) {
while (this.array[leftPointer] < pivot) {
leftPointer += 1;
}
while (this.array[rightPointer] > pivot) {
rightPointer -= 1;
}
if (leftPointer >= rightPointer) break;
else {
[this.array[leftPointer], this.array[rightPointer]] = [
this.array[rightPointer],
this.array[leftPointer]
];
leftPointer += 1;
}
}
[this.array[leftPointer], this.array[index]] = [
this.array[index],
this.array[leftPointer]
];
return leftPointer;
}
}해설
class SortableArray {
constructor(array) {
this.array = array;
}
// 배열을 분할하는 partition 메서드
// 왼쪽 포인터와 오른쪽 포인터의 시작점을 인자로 받는다.
partition(leftPointer, rightPointer) {
// 가장 오른쪽에 있는 값을 피벗으로 선택
// 나중에 사용할 수 있도록 피벗의 인덱스 저장
let index = rightPointer;
// 피벗 값 저장
let pivot = this.array[index];
// 피벗 바로 왼쪽에서 오른쪽 포인터 시작
rightPointer -= 1;
while (true) {
// 피벗보다 크거나 같을 때까지 왼쪽 포인터를 오른쪽으로 이동
while (this.array[leftPointer] < pivot) {
leftPointer += 1;
}
// 피벗보다 작거나 같을 때까지 오른쪽 포인터를 왼쪽으로 이동
while (this.array[rightPointer] > pivot) {
rightPointer -= 1;
}
// 왼쪽 포인터와 오른쪽 포인터가 이동을 멈추면
// 왼쪽 포인터가 오른쪽 포인터와 같거나 넘어섰는지 확인
// 만약 같거나 넘어섰다면 루프를 빠져나가 이후 코드에서 피벗 교환
if (leftPointer >= rightPointer) break;
// 왼쪽 포인터가 오른쪽 포인터보다 앞에 있으면
// 왼쪽 포인터와 오른쪽 포인터 값을 교환 후 왼쪽 포인터를 한 셀 이동
else {
[this.array[leftPointer], this.array[rightPointer]] = [
this.array[rightPointer],
this.array[leftPointer]
];
leftPointer += 1;
}
}
// 왼쪽 포인터와 피벗 값을 교환
[this.array[leftPointer], this.array[index]] = [
this.array[index],
this.array[leftPointer]
];
// 이어지는 예제에 나올 quickSort 메서드를 위해 leftPointer 반환
return leftPointer;
}
}배열에서 partition 메서드를 호출하면 두 포인터는 각각 배열의 왼쪽과 오른쪽 끝을 가리킨다.
하지만 퀵 정렬은 배열의 일부분에 대해서도 위 메서드를 호출하기 때문에,
즉 왼쪽 포인터와 오른쪽 포인터가 항상 배열의 양 끝을 가리키리라고 가정할 수 없기 때문에
partition 메서드에서 왼쪽과 오른쪽 포인터를 인수로 받게 된다.
partition 메서드에서 피벗은 배열의 가장 오른쪽 원소로 정한다.
그리고 피벗이 정해지면 rightPointer를 피벗의 바로 왼쪽 항목으로 이동한다.
leftPointer와 rightPointer가 만날 때까지 반복 루프를 실행하고,
루프 내에서 또 다른 루프를 통해 leftPointer가 피벗보다 크거나 같을 때까지 오른쪽으로 이동한다.
그리고 rightPointer도 피벗보다 작거나 같을 때까지 왼쪽으로 이동한다.
leftPointer와rightPointer가 이동을 멈추면 두 포인터가 마주쳤는지 확인한다.
마주쳤다면 루프를 종료 후 왼쪽 포인터와 피벗을 교환하고, 마주치지 않았다면 두 포인터의 값을 교환한다.
13.2 퀵 정렬
퀵 정렬 알고리즘은 '분할과 재귀'로 이뤄진다.
- 배열을 분할한다. 피벗이 올바른 위치에 있게 된다.
- 피벗의 왼쪽과 오른쪽에 있는 하위 배열을 각각 또 다른 배열로 보고, 1~2단계를 재귀적으로 반복한다.
즉, 각 하위 배열을 분할하고 각 하위 배열에 있는 피벗의 왼쪽과 오른쪽에서 더 작아진 하위 배열을 얻는다.
이러한 하위 배열을 다시 분할하는 과정을 반복한다.- 하위 배열이 원소를 0개 또는 1개 포함하면 기저 조건에 해당하므로 아무 것도 하지 않는다.
13.1-분할 예제로 돌아가면, 전체 배열 [0, 5, 2, 1, 6, 3]에 대해 한 번의 분할을 수행했다.
퀵 정렬은 분할로 시작하므로 이미 퀵 정렬 과정을 일부 수행한 것과 같다.
| 0 | 1 | 2 | 3 | 6 | 5 |
|---|---|---|---|---|---|
| ✅ |
위와 같이 3이 피벗 값이었고, 분할을 1번 수행한 이후 3은 배열 내에서 올바른 위치에 있게 된다.
그리고 피벗의 왼쪽과 오른쪽을 정렬해야 한다.
(*피벗 왼쪽은 이미 정렬되어 있지만 컴퓨터는 이 내용을 아직 모른다)
분할이 끝나면 피벗 왼쪽에 있는 값들을 하나의 배열로 보고 다시 분할한다.
(*배열의 오른쪽 부분은 지금 필요하지 않으므로 임시 취소선 처리)
| 0 | 1 | 2 | |||
|---|---|---|---|---|---|
| 👆🏽 | 👆 | ✅ |
하위 배열 [0, 1, 2] 에서 가장 오른쪽 원소를 피벗으로 정한다. (2)
그리고 왼쪽과 오른쪽 포인터를 설정하면, 하위 배열을 분할할 준비가 완료됐다.
이전에 중지했던 8단계 이후부터 살펴보도록 하자.
- 왼쪽 포인터와 피벗을 비교한다.
왼쪽 포인터0은 피벗 값인2보다 작으므로 왼쪽 포인터를 이동한다.
| 0 | 1 | 2 | |||
|---|---|---|---|---|---|
| 👆🏽👆 | ✅ |
- 왼쪽 포인터를 한 셀 이동한다. (두 포인터가 같은 값을 가리키게 된다)
왼쪽 포인터1는 피벗 값인2보다 작으므로 왼쪽 포인터를 이동한다.
| 0 | 1 | 2 | |||
|---|---|---|---|---|---|
| 👆 | 👆🏽✅ |
-
왼쪽 포인터를 한 셀 이동한다. (왼쪽 포인터가 피벗을 가리키게 된다)
왼쪽 포인터2와 피벗 값인2가 동일하므로 왼쪽 포인터를 멈춘다. -
오른쪽 포인터 비교를 시작한다.
오른쪽 포인터1은 피벗 값인2보다 작으므로 오른쪽 포인터를 멈춘다.
| 0 | 1 | 2 | |||
|---|---|---|---|---|---|
| ✅ |
- 왼쪽 포인터가 오른쪽 포인터를 지나쳤으므로, 왼쪽 포인터 값과 피벗을 교환한다.
하지만 같은 값을 가리키고 있으므로 아무런 변화는 생기지 않고, 피벗 값인2가 올바른 위치에 있게 된다.
이제 피벗 값 2의 왼쪽에는 하위 배열 [0, 1]이 존재하고, 오른쪽에는 어떠한 하위 배열도 없다.
다음 단계는 피벗 왼쪽의 하위 배열 [0, 1]을 재귀적으로 분할하는 것이다.
| 0 | 1 | ||||
|---|---|---|---|---|---|
| 👆🏽👆 | ✅ |
가장 오른쪽 값인 1을 피벗으로 설정하고, 왼쪽과 오른쪽 포인터를 설정한다.
값이 1개밖에 남지 않으므로 두 포인터가 함께 0을 가리킨다.
- 왼쪽 포인터
0과 피벗 값1을 비교한다.
0은1보다 작으므로 왼쪽 포인터를 이동한다.
| 0 | 1 | ||||
|---|---|---|---|---|---|
| 👆 | 👆🏽✅ |
-
왼쪽 포인터를 한 셀 이동한다. (피벗을 가리키게 된다)
왼쪽 포인터1은 피벗 값1과 같으므로 왼쪽 포인터를 멈춘다. -
오른쪽 포인터와 피벗을 비교한다.
오른쪽 포인터0은 피벗1보다 작아므로 오른쪽 포인터를 멈춘다.
| 0 | 1 | ||||
|---|---|---|---|---|---|
| ✅ |
- 왼쪽 포인터가 오른쪽 포인터를 지나쳤으므로 왼쪽 포인터와 피벗을 교환한다.
하지만 같은 값을 가리키고 있으므로 아무런 변화는 생기지 않고, 피벗 값인1이 올바른 위치에 있게 된다.
현재 피벗 1의 왼쪽 하위 배열에는 하나의 원소로 이루어진 [0]이다.
원소가 0개 또는 1개일 경우 기저 조건에 해당하므로 아무것도 하지 않고 자동으로 올바른 위치에 있다고 간주된다.
따라서 아래와 같이 체크된 원소들이 모두 올바른 위치에 있게 된다.
| 0 | 1 | 2 | 3 | ||
|---|---|---|---|---|---|
| 💯 | 💯 | 💯 | 💯 |
가장 처음 3을 피벗으로 선택하여 3의 왼쪽에 있는 하위 배열 [0, 1, 2]를 재귀적으로 분할했다.
이제 3의 오른쪽에 있는 하위 배열 [6, 5]를 재귀적으로 분할할 차례다.
(*배열의 왼쪽 부분은 지금 필요하지 않으므로 임시 취소선 처리)
| 6 | 5 | ||||
|---|---|---|---|---|---|
| 👆🏽👆 | ✅ |
배열에서 가장 오른쪽 값 5를 피벗으로 설정하고, 왼쪽과 오른쪽 포인터를 설장한다.
값이 1개밖에 남지 않으므로 두 포인터가 함께 6을 가리킨다.
-
왼쪽 포인터
6과 피벗 값5를 비교한다.
6은5보다 크므로 왼쪽 포인터를 멈춘다. -
오른쪽 포인터
6과 피벗 값5를 비교한다.
6은5보다 크므로 오른쪽 포인터를 멈춘다.
| 5 | 6 | ||||
|---|---|---|---|---|---|
| ✅ |
- 왼쪽 포인터와 오른쪽 포인터가 만났으므로 마지막 단계인 왼쪽 포인터와 피벗 값을 교환을 수행한다.
이제 피벗 값5가 올바른 위치에 있게 된다.
다음 하위 배열인 [6]은 원소가 1개이므로 기저 조건에 해당하고, 자동으로 올바른 위치에 있다고 간주된다.
| 0 | 1 | 2 | 3 | 5 | 6 |
|---|---|---|---|---|---|
| 💯 | 💯 | 💯 | 💯 | 💯 | 💯 |
이제 모든 값들이 올바른 위치에 존재한다!
코드로 구현한다면: 퀵 정렬
퀵 정렬을 성공적으로 끝내기 위해서는 SortableArray 클래스에 quickSort 메서드를 추가한다.
기본 코드
quickSort(leftIndex, rightIndex) {
if (rightIndex - leftIndex <= 0) return;
let pivotIndex = this.partition(leftIndex, rightIndex);
this.quickSort(leftIndex, pivotIndex - 1);
this.quickSort(pivotIndex + 1, rightIndex);
}해설
quickSort(leftIndex, rightIndex) {
// 기저조건 : 하위 배열에 원소가 0개 또는 1개 일 때
if (rightIndex - leftIndex <= 0) return;
// 범위 내 원소들을 분할하고 피벗 인덱스를 가져온다.
let pivotIndex = this.partition(leftIndex, rightIndex);
// 피벗의 왼쪽과 오른쪽에 대해 quickSort 메서드를 재귀 호출
this.quickSort(leftIndex, pivotIndex - 1);
this.quickSort(pivotIndex + 1, rightIndex);
}quickSort 메서드를 처음 호출할 때는 전체 배열에 대해 분할을 진행한다.
이어지는 호출에서는 원래 배열의 일부인 leftIndex, rightIndex 사이 원소를 분할한다.
이때 pivotIndex 변수에 할당하는 값은 partition 메서드가 반환하는 leftPointer 이다.
이어서 피벗의 왼쪽과 오른쪽 하위 배열에 대해 quickSort 를 재귀적으로 호출한다.
테스트
let arr = [0, 5, 2, 1, 6, 3];
const getSortedArray = new SortableArray(arr);
getSortedArray.quickSort(0, arr.length - 1);
console.log(getSortedArray.array);
// [0, 1, 2, 3, 5, 6]13.3 퀵 정렬의 효율성
퀵 정렬의 효율성을 알기 위해서는 한 번 분할할 때의 효율성을 밝혀야 한다.
분할에 필요한 단계를 분류하면 아래와 같이 두 종류이다.
- 비교 : 각 값과 피벗을 비교한다.
- 교환 : 적절한 때에 왼쪽과 오른쪽 포인터가 가리키고 있는 값을 교환한다.
각 분할마다 배열 내 원소를 피벗과 비교하므로 최소 번 비교가 진행된다.
분할을 한 번 할 때마다 왼쪽과 오른쪽 포인터가 서로 만날 때까지 매 셀을 이동하기 때문이다.
하지만 교환의 횟수는 데이터가 어떻게 정렬되어 있느냐에 따라 달라진다.
가능한 값을 모두 교환한다고 하더라도 한 번에 두 개의 값을 교환하므로 한 분할 내에서 최대 번 교환한다.
| 7 | 6 | 5 | 3 | 2 | 1 | 4 |
|---|---|---|---|---|---|---|
| 👆🏽 | 👆 | 👆🏻 | 👆🏻 | 👆 | 👆🏽 | ✅ |
대부분의 경우 매 단계마다 교환이 일어나는 게 아니라,
무작위로 정렬된 데이터가 있을 때 일반적으로 값의 반절 정도만 교환한다.
즉, 평균적으로 번의 교환을 한다.
따라서 평균적으로 번 비교, 번 교환한다. 원소가 개일 때 대략 단계가 수행된다.
빅 오 표기법에서는 상수를 무시하므로 시간에 분할을 실행한다고 볼 수 있다.
이것은 '한 번 분할할 때'의 효율성이다.
하지만 퀵 정렬은 여러 번 분할하므로 퀵 정렬의 효율성을 알아내기 위해서는 조금 더 분석이 필요하다.
한눈에 보는 퀵 정렬
시각적으로 쉽게 이해할 수 있도록 원소가 8개인 배열에 대해 그림으로 묘사해보자.
특히 그림 묘사는 얼마나 많은 원소에 대해 각 분할을 수행하는지 알 수 있다.
어떤 수를 정렬했느냐는 중요하지 않으므로 실제 수는 배열에서 제외했다.
그림 묘사에서 어둡게 표시하지 않은 셀 그룹이 정렬 중인 하위 배열이다.
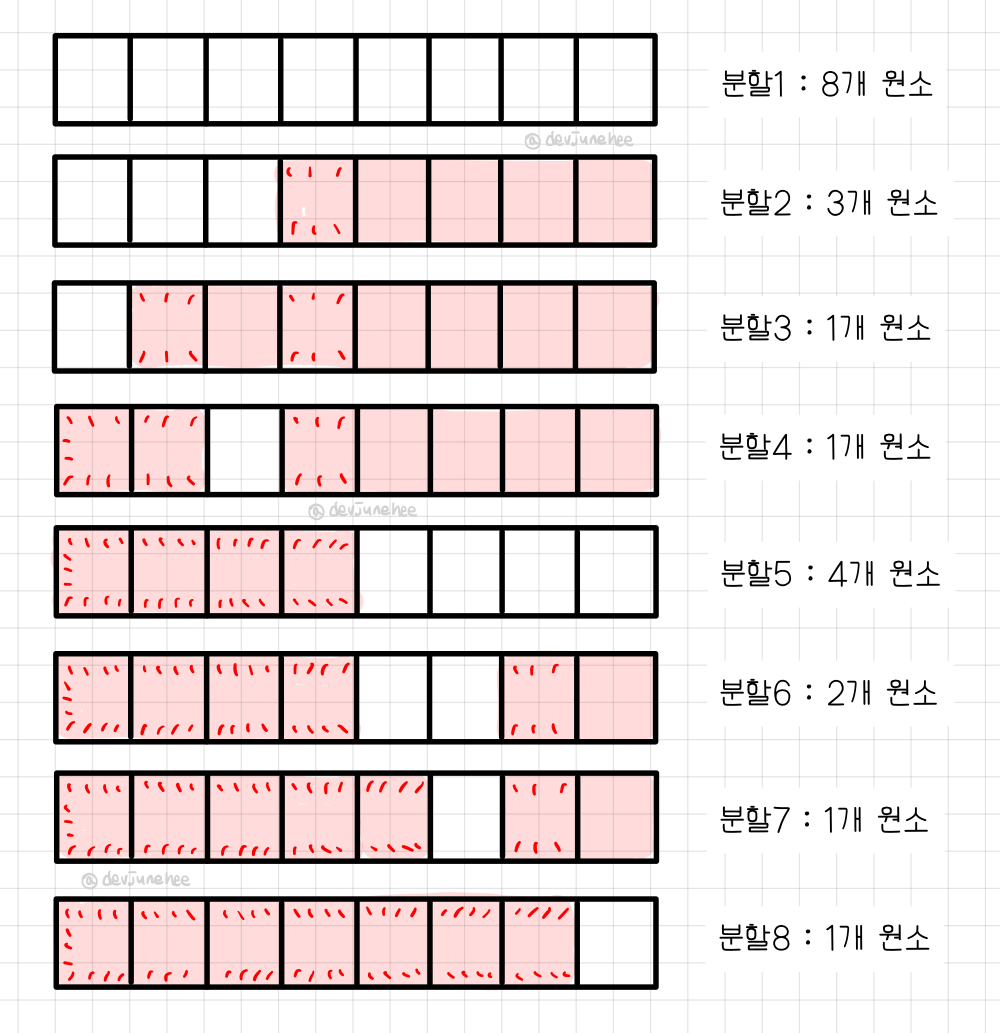
위 그림 묘사에서는 총 8번 분할을 하는데, 분할할 때마다 하위 배열의 크기가 다른 것을 알 수 있다.
원소가 8개인 원래 배열을 분할하고, 크기가 4와 3인 하위 배열을 분할하고, 크기가 1인 배열을 4번 분할한다.
퀵 정렬은 기본적으로 연이은 분할로 수행되는데 각 분할마다 하위 배열의 원소가 개일 때 약 단계가 걸린다.
결국 모든 하위 배열의 크기를 합하면 퀵 정렬에 걸리는 총 단계 수가 나온다.
- 원소
- 총 단계
원소가 8개일 때 약 21단계가 걸렸다.
이는 각 분할 후 피벗이 하위 배열의 중간 부근에 놓일 것이라는 최선 또는 평균 시나리오를 가정한 것이다.
| 퀵 정렬 단계 수 (근사치) | |
|---|---|
| 4 | 8 |
| 8 | 24 |
| 16 | 64 |
| 32 | 160 |
원소가 16개인 배열에 대해 퀵 정렬에 약 64단계가 걸리고, 원소가 21개인 배열에 대해 약 160단계가 걸린다.
예제에서는 21단계가 걸렸지만 표에서 24단계로 표기한 이유는 근사치이기 때문이다.
정확한 수치는 경우에 따라 다르고 21과 24 모두 타당한 근사치가 될 수 있다.
빅 오로 나타낸 퀵 정렬
🤔 빅 오 표기법 관점에서 퀵 정렬은 어떻게 분류하나요?
| 퀵 정렬 단계 수 (근사치) | |||
|---|---|---|---|
| 4 | 2 | 8 | 8 |
| 8 | 3 | 24 | 24 |
| 16 | 4 | 64 | 64 |
| 32 | 5 | 160 | 160 |
배열의 원소가 개일 때, 퀵 정렬에 필요한 단계 수는 약 이다.
실제로 퀵 정렬의 효율성을 위 표처럼 표현한다. 퀵 정렬은 의 알고리즘이다.
퀵 정렬의 단계 수가 에 부합하는 것은 우연이 아니다.
배열을 분할할 때마다 하위 배열 두 개로 나눈다.
평균적으로 배열 중간 어디쯤을 피벗이라고 가정하면, 이 두 하위 배열은 크기가 거의 비슷하다.
👩🏫 크기가 1이 될 때까지 각 하위 배열을 반으로 나누려면, 배열을 몇 번 나눠야 할까요?
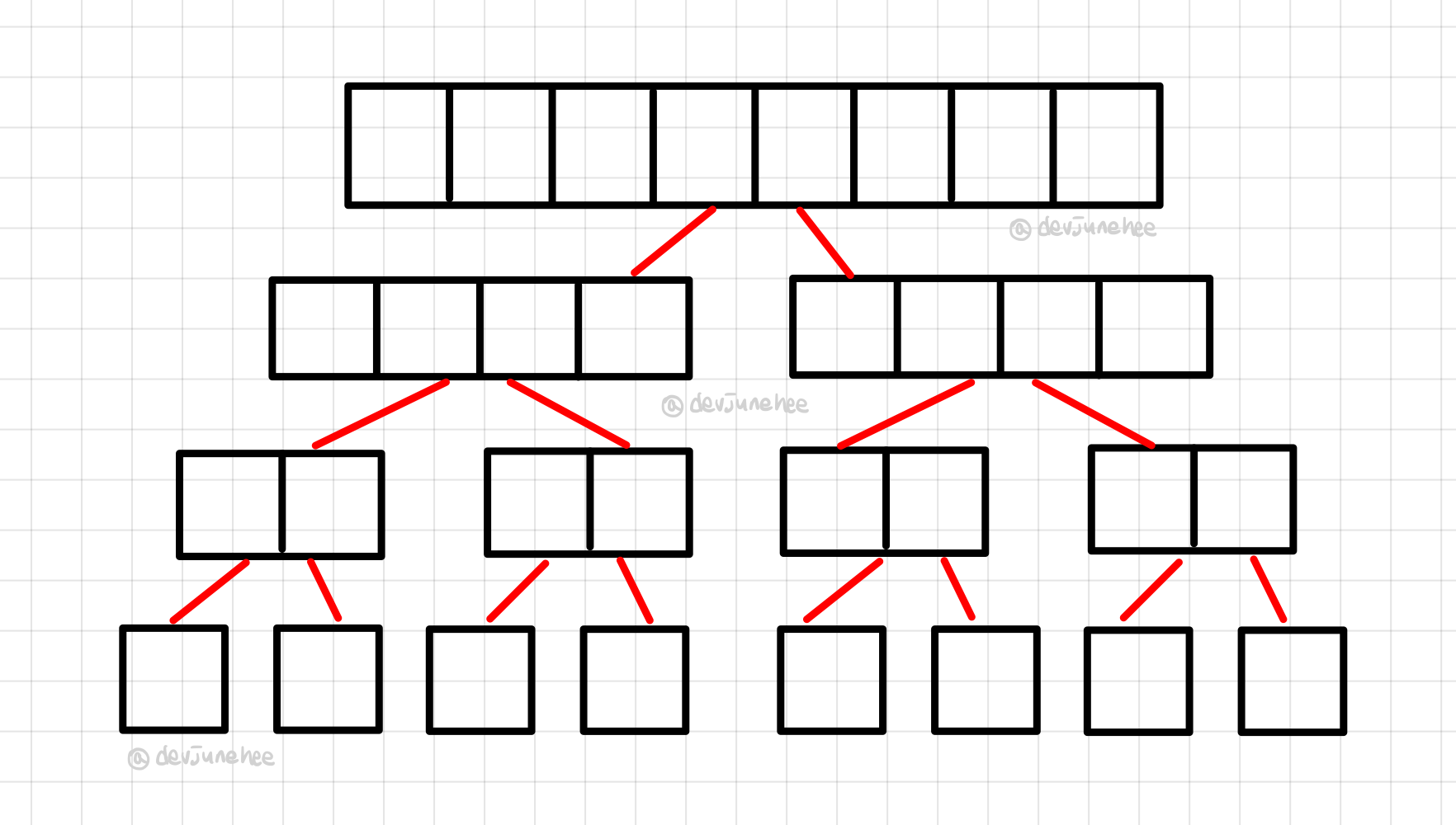
크기가 인 배열에 대해 번 나눠야 합니다.
그기가 8인 배열은 각 원소로 나뉠 때까지 '반으로' 3번 나누고, 이 값은 이며
1이 될 때까지 반으로 나누는 횟수를 뜻하는 의 정의에 정확히 부합한다.
따라서 퀵 정렬은 단계가 걸린다.
번 반으로 나누고, 나눌 때 마다 모든 하위 배열에 대해 분할을 수행하는데 하위 배열의 원소 수를 합하면 이다.
은 근사치라는 것을 잊지 말자. 실제로는 원래 배열에 대해 번 더 분할된다.
그리고 피벗은 반으로 나누기가 아니므로 배열이 깔끔하게 반으로 나뉘지도 않는다.
13.4 퀵 정렬의 최악의 시나리오
지금까지 본 많은 알고리즘에서 최선의 경우는 배열이 이미 정렬된 경우였다.
하지만 퀵 정렬에서 최선의 시나리오는 분할 후 피벗이 하위 배열 한 가운데 있을 때다.
이러한 경우는 흥미롭게도 배열의 값이 상당히 잘 섞여있을 때 일어난다.
퀵 정렬에서 최악의 시나리오는 피벗이 항상 하위 배열의 한쪽 끝에 있을 때다.
배열이 완전히 오름차순이거나 내림차순일 때 일어날 수 있다.
퀵 정렬 vs 삽입 정렬
| 최선 | 평균 | 최악 | |
|---|---|---|---|
| 삽입 정렬 | |||
| 퀵 정렬 |
퀵 정렬와 삽입 정렬을 비교해보면,
최악의 시나리오에서는 동일하고 최선의 시나리오에서는 삽입 정렬이 더 빠르다.
하지만 퀵 정렬이 삽입 정렬보다 훨씬 우수한 까닭은 평균 시나리오, 즉 대부분의 경우 때문이다.
평균적인 경우 삽입 정렬은 이 걸리는 반면, 퀵 정렬은 이다.
평균적인 상황에서 퀵 정렬이 우수하므로 내부적으로 퀵 정렬을 사용해 내장 정렬 함수를 구현하는 언어가 많다.
따라서 퀵 정렬을 직접 구현할 일은 거의 없지만, 퀵 셀렉트라 불리는 유사한 알고리즘이 실용적으로 쓸모 있다.
13.5 퀵 셀렉트
무작위로 정렬된 배열이 있을 때,
정렬은 안 해도 되지만 배열에서 몇 번째로 작은 값이나 큰 값을 알고 싶다고 가정하자.
전체 배열을 정렬한 후 적절한 인덱스를 찾으면 이 문제를 풀 수 있다.
하지만 퀵 정렬처럼 빠른 정렬 알고리즘을 사용해도 이 알고리즘에는 최소/평균적으로 이 걸린다.
이 점을 퀵 셀렉트(Quick Select)를 이용해 훨씬 더 나은 성능을 낼 수 있다.
퀵 셀렉트 또한 분할에 기반하며, 퀵 정렬과 이진 검색의 하이브리드 정도로 생각할 수 있다.
분할이 끝나면 피벗 값은 배열 내 올바른 위치에 있게 된다. 퀵 셀렉트도 이 정보를 활용한다.
(e.g.) 값이 8개인 배열이 있을 때, 이 배열 내에서 두 번째로 작은 값을 찾고싶다.
| ? | ? | ? | ? | ? | ? | ? | ? |
|---|---|---|---|---|---|---|---|
| ✅ |
먼저 전체 배열을 분할하고, 분할 후에 피벗은 배열의 중간 부분에 있을 것이다. (5번째라고 가정)
이제 피벗은 올바른 위치에 있게 되고, 5번째 셀에 있으므로 어떤 값이 배열에서 다섯 번째로 작은지 알게 됐다.
예제는 두 번째로 작은 값을 찾고 싶으므로, 이 값이 피벗의 왼쪽 어딘가에 위치한다는 것을 알 수 있다.
그러므로 이후로는 피벗에 오른쪽을 무시하고, 왼쪽 하위 배열에 대해서만 집중할 수 있다.
이러한 점이 퀵 셀렉트와 이진 검색이 유사한 점이다.
즉, 배열을 계속 반으로 나누되 찾는 값이 있는 쪽에만 집중한다.
| ? | ? | ? | ? | ❌ | ❌ | ❌ | ❌ |
|---|---|---|---|---|---|---|---|
| ✅ |
이제 하위 배열의 새 피벗을 세 번째 셀로 가정해보자. (중간 부분 가정)
그럼 이 피벗은 배열 내 올바른 위치에 있게 되고 배열에서 세 번째로 작은 값임을 알았다.
두 번째로 작은 값은 이 피벗의 왼쪽 어딘가에 있으므로, 하위 배열을 다시 분할한다.
| ? | ? | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
|---|---|---|---|---|---|---|---|
| ✅ |
분할이 끝나면 가장 작은 값과, 두 번째로 작은 값이 배열 내 올바른 위치에 있기 된다.
이제 두 번째 셀에 있는 값을 배열에서 두 번째로 작은 값이라고 찾아낼 수 있다.
퀵 셀렉트의 훌륭한 점 중 하나는 전체 배열을 정렬하지 않고 올바른 값을 찾을 수 있다는 것이다.
퀵 정렬은 배열을 반으로 나눌 때마다 원래 배열의 모든 셀(하위 배열)을 다시 분할해야 했지만, (= )
퀵 셀렉트는 배열을 반으로 나눌 때마다 필요한 반쪽 만 분할하면 된다.
퀵 셀렉트의 효율성
퀵 셀렉트를 분석해보면 평균 시나리오에서 이다.
🤓 왜 그런가요?
원소가 8개인 경우, 하위 배열에 대해 총 3번의 분할이 일어난다.
- 원소가 8개인 배열
- 원소가 4개인 배열
- 원소가 2개인 배열
분할이 일어날 때마다 분할 중인 하위 배열에 대해 단계가 소요된다.
따라서 3번 분할할 때, 단계가 걸린다.
즉, 원소가 8개인 배열에는 14단계가 소요된다.
원소가 64개라면, 단계가 소요된다.
원소가 128개라면 단계일 것이다.
원소가 256개라면, 단계일 것이다.
원소가 개인 배열에 대해 약 단계가 걸리는 것을 알 수 있다.
(공식적으로 표현하면 원소가 개 일 때, 단계이다.)
빅 오에서는 상수를 무시하기 때문에 퀵 셀렉트의 효율성은 이다.
코드로 구현한다면: 퀵 셀렉트
다음은 SortableArray 클래스 안에 넣을 수 있는 quickSelect 메서드 구현 코드이다.
기본 코드
quickSelect(kthLowestValue, leftIndex, rightIndex) {
if (rightIndex - leftIndex <= 0) {
return this.array[leftIndex];
}
let pivotIndex = this.partition(leftIndex, rightIndex);
if (kthLowestValue < pivotIndex) {
this.quickSelect(kthLowestValue, leftIndex, pivotIndex - 1);
} else if (kthLowestValue > pivotIndex) {
this.quickSelect(kthLowestValue, pivotIndex + 1, rightIndex);
} else {
this.array[pivotIndex];
}
}해설
quickSelect(kthLowestValue, leftIndex, rightIndex) {
// 기저 조건 : 하위 배열에 셀이 하나면 찾던 값을 찾았으므로 리턴
if (rightIndex - leftIndex <= 0) {
return this.array[leftIndex];
}
// 배열을 분할하고 피벗 값의 위치 찾기
let pivotIndex = this.partition(leftIndex, rightIndex);
// 찾는 값이 피벗 왼쪽에 있으면, 왼쪽 하위 배열에 대해 재귀 퀵 셀렉트 호출
// 찾는 값이 피벗 오른쪽에 있으면, 오른쪽 하위 배열에 대해 재귀 퀵 셀렉트 호출
// 피벗과 k번째 작은 값이 같으면 해당 값을 리턴
if (kthLowestValue < pivotIndex) {
this.quickSelect(kthLowestValue, leftIndex, pivotIndex - 1);
} else if (kthLowestValue > pivotIndex) {
this.quickSelect(kthLowestValue, pivotIndex + 1, rightIndex);
} else {
return this.array[pivotIndex];
}
}테스트
let arr = [0, 50, 20, 10, 60, 30];
const getSortedArray2 = new SortableArray(arr);
getSortedArray2.quickSelect(1, 0, arr.length - 1);
console.log(getSortedArray2.array);
//13.6 다른 알고리즘의 핵심 역할을 하는 정렬
현재까지 알려진 가장 빠른 정렬 알고리즘의 속도는 이다.
퀵 정렬이 가장 유명하지만 다른 알고리즘도 많다.
병합 정렬(Merge Sort) 역시 잘 알려진 알고리즘이다.
여기서 중요한 점은 가장 빠른 정렬 알고리즘이 이라는 것인데,
이 속도가 다른 알고리즘에 영향을 미치기 때문이다.
어떤 알고리즘은 더 큰 프로세스의 한 컴포넌트로서 정렬을 사용한다.
